基于网络新闻评论的四度用户影响力分析模型
2021-09-16欧阳纯萍陈湘龙刘永彬
欧阳纯萍,陈湘龙,刘永彬
(南华大学 计算机学院,湖南 衡阳 421001)
0 引 言
网络新闻因其具有及时性、全面性等特点越来越受广大网民的关注,国内外发生的重大事件,大部分都是第一时间通过网络新闻平台发布,并引发了社会剧烈的反响和激烈的辩论。因此,在引导社会舆论的方面,网络新闻平台的大量言论发挥着难以估量的作用,为能正确引导网络舆情的导向,在舆情监控过程中需要对某些具有较高影响力的网络新闻评论用户采取特别措施。
近年来用户影响力分析受到了大量的研究者的关注,许多影响力计算的方法相继被提出,Cha等[1]通过从用户的转发数、评论数、粉丝数等静态属性排名来分析Twitter社交网络中的用户影响力,但是该方法在静态属性选择上面存在局限性,并且没有考虑用户在社交网络中的关系。Weng等[2]根据用户之间的粉丝联系形成的网络关系,通过PageRank算法计算用户的影响力排名,该方法实现简单、效果较好,但是仅使用粉丝作为影响力的评价指标并不是很全面。吴慧等[3]使用用户的活跃度和用户所发微博质量作为综合指标得到影响力权重,并结合网络拓扑结构计算用户在社交网络中的影响力,该方法虽然关注用户所发内容的质量,但是却没有关注内容的情感倾向性。
在用户影响力分析的研究中,采用静态属性排名的方法具有更加全面的特点,但属性的构建在很大程度上依赖构建者的主观意识。传统的基于网络拓扑结构的用户影响力分析方法大部分是利用遍历网络结构去分析用户之间的影响力,而用户节点本身的属性信息较少考虑。由于表征用户影响力的因素具有多样性,但是针对不同的用户评价对象,有效的特征又不尽相同。因此,本文针对新闻评论网络的特点,提取考虑表征网络新闻评论网络用户影响力的4种主要因素,提出了面向新闻评论网络用户的四度影响力分析模型FDRank(four-degree influence rank),与国内外前沿方法TwitterRank、PageRank、Brank、MDIR和RBrank比较,本文提出的方法能够更准确找出具有较高影响力的用户。
1 相关工作
从20世纪初到现在,影响力分析的研究受到了各个领域学者的研究和关注,上世纪50年代,Roshwalb等[4]发现在平时具有影响力的人,在工作、生活或政治选举是都存在很大的优势。之后Triplett[5]通过研究动力因素发现,当一个人受到更多的关注时,他会表现的更为突出。近年来,随着微博、腾讯新闻、Twitter等网络社交媒体的兴起,对用户影响力的研究也随之增多,主要集中在以下3个方面:
(1)基于社交网络拓扑结构的度量。主要通过节点的出入度以及度的方向来度量用户的影响力值。度的大小表明该节点受他人的影响程度或是受欢迎程度,而度的方向则表示信息传递的方向,这类方法的典型代表就是Page-Rank 算法[6],之后许多研究者在PageRank算法上进行了深入研究,改进。王鹏等[7]结合PageRank算法和社交网络用户的行为数据和质量数据,如利用网络中用户发布信息的转发率、评论率以及用户是否认证情况等行为因素,综合用户自身质量与追随者质量等,最终计算得到社交网络中的用户影响力。刘威等[8]借鉴PageRank算法思想,综合考虑用户话题信息传播能力以及用户与背景话题间关联性对微博用户影响力进行排序。单纯依靠网络结构分析来进行影响力分析的方法虽然模型简单,计算资源耗费较低,但是忽略了节点的属性信息以及节点之间的互动关系,这些能对用户影响力有一定表征能力的因素。
(2)基于用户行为的度量。通过分析在线社交用户的行为轨迹数据(包括浏览/发布/转发信息、点赞、话题评论和建立好友关系等),能够评估用户在社交网络平台上的影响力。Xiang等[9]利用社交网络用户之间的交互信息和话题相似性和信息交互情况,提出了一种潜在变分模型用以来评估计算用户之间的影响强度。SAITO等[10]将用户影响力模型转化成一种最大似然问题,并且利用期望最大化算法进行求解。YANG等[11]基于影响力函数和信息的谈论次数建立了一种线性影响力模型对用户的影响力进行度量。魏杰明等[12]从用户行为方式和互动规律的角度出发,系统研究了社交网络中用户行为和贴文特征。再采用PCA主成分分析法,将各组成因素进行相关性研究,得到最终的用户影响力。上述方法均是从用户本身的属性和行为特征出发来分析其影响力,并没有考虑用户所发布内容的情感极性,用户发布的新闻评论内容是否具有情感倾向对于内容的传播有一定的影响。
(3)结合网络拓扑结构和用户的度量。单纯从网络结构来分析用户的影响力,容易丢失一些用户本身的特征,而单纯从用户特征来分析用户的影响力,又不能充分利用用户所处社交网络的结构信息。因此,还有一些学者把网络拓扑结构和用户自身特征进行结合来度量用户的影响力。学者们最初尝试综合使用网络拓扑结构、用户特征和用户行为数据预测当前时刻的用户影响力[13,14]。后续,学者们又对融合方法进行了细粒度研究。王新胜等[15]首先对用户的自身因素和用户传播能力进行计算,得到用户直接影响力。然后再计算基于用户网络拓扑结构的用户间接影响力,最后综合用户直接影响力和间接影响力,从而分析得到用户的最终用户影响力。罗芳等[16]把用户基本属性、交互行为和微博内容3个维度因素融入PageRank算法中,基于网络结构设计了一种多维度微博用户影响力度量算法。上述研究成果为用户影响力分析提供了可行的新思路,融合用户自身特征与网络结构分析算法可以更好地综合评价用户的影响力。
鉴于当前研究的可改进之处以及新闻评论数据的特点,本文提出一种融合用户行为特征、评论内容与问题的相关性、评论的情感倾向性、网络结构的四度新闻评论用户影响力分析算法。考虑用户评论内容与新闻文章的相似程度,避免不相关内容的干扰;计算评论内容的情感倾向性,通过分析数据发现当所发内容具有较强的情感极性时,更容易获得大家的关注;分析用户的行为(包含评论和点赞两种),当用户获得越多的评论和点赞数,表明该用户所发表的评论具有较强的说服力;分析用户的网络拓扑结构,表征用户在社交网络中与其他用户的联系强度,更全面地反映用户的影响力;最后利用加权线性融合方法得到最终的新闻评论网络的用户影响力。
2 四度用户影响力分析模型
网络新闻用户可以通过评论发表自身的观点,通过点赞、关注和回复他人评论与其他用户进行互动。本文通过分析用户自身质量、用户网络结构、用户发布评论内容及评论情感值4个方面对用户影响力进行分析,提出了四度用户影响力分析算法,如图1所示。
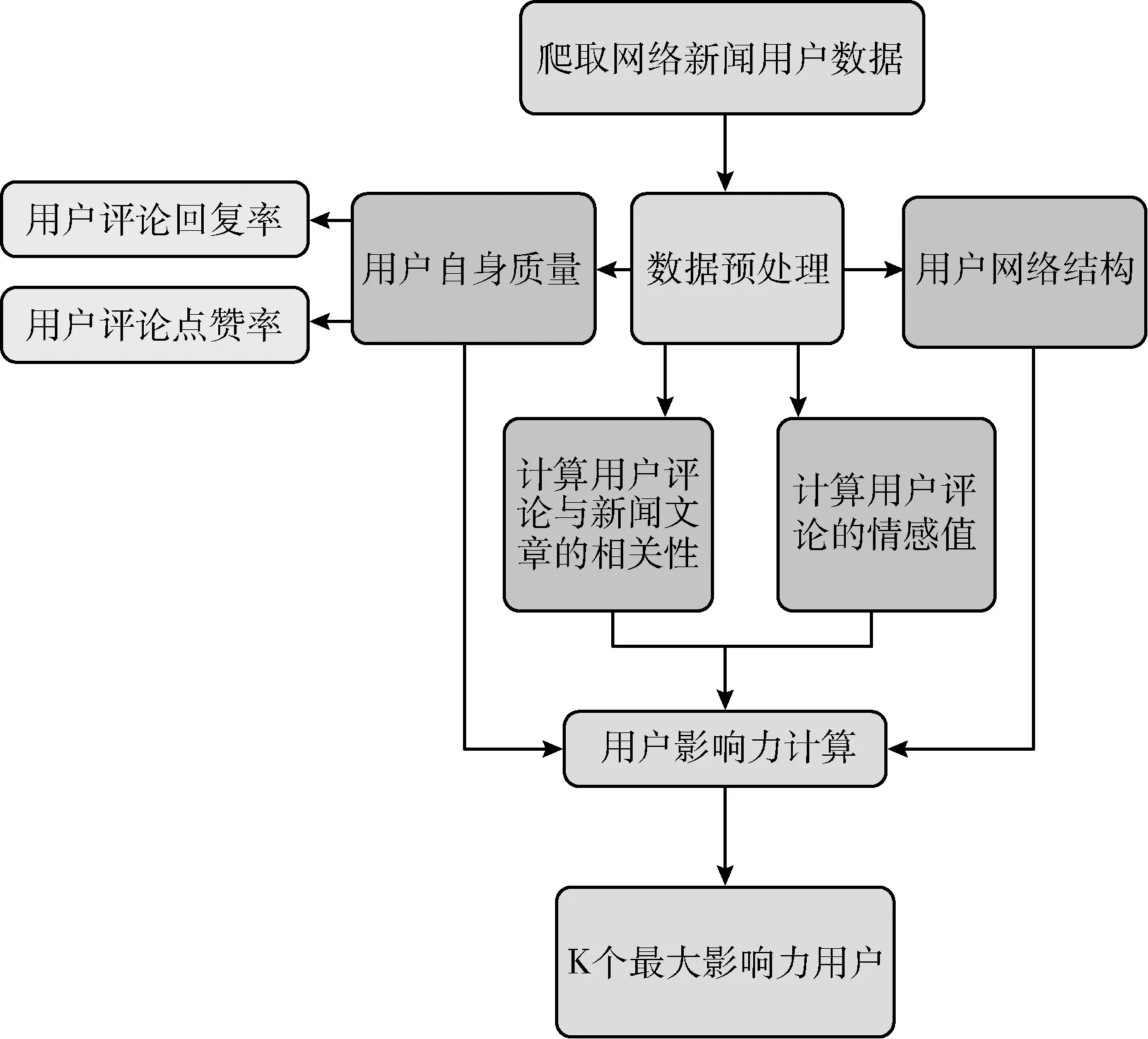
图1 四度用户影响力分析算法流程
2.1 评论内容影响力计算
用户可以通过PC端、手机移动端等发布关于一篇新闻文章的评论,每个评论基本是由几句话组成。当评论内容与新闻文章的相关程度低,则很有可能是一些垃圾评论,影响力较低。而评论内容与新闻内容相关程度较高的,则可能存在更大的影响力,并且通过内容相关性计算,还能够排除一些信息量低的评论的影响。
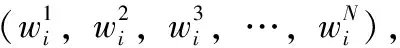
(1)
式中:tfki表示Vk在nai中出现的次数,dfk表示文本集NA中含有Vk的文本总数。对于文本的相似度,本文利用余弦相似度来计算评论与新闻文章之间的相似,并使用其结果作为评论内容影响力CI
CI=Sim(comment,article)=
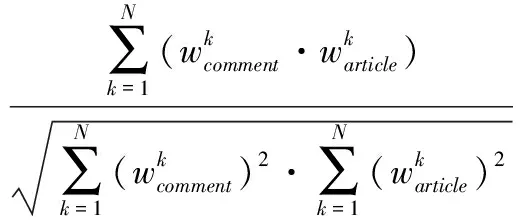
(2)
2.2 评论内容情感极性值计算
根据新闻传播规律,通常用户如果发表的评论不带任何情感色彩,这类新闻文本传播范围很有限。所以新闻评论文本的情感极性对于文本传播有较强的影响,而文本传播率又是评价用户影响力的重要指标。因此,在分析用户影响力时有必要先分析评论内容的情感极性。本文提出一个融合多个深度学习算法的模型来计算新闻评论的3类情感倾向性,即负面、中立、正面,模型如图2所示。首先将文本通过word2vec转换为向量表示,然后使用BIGRU和Attention机制增强上下文语义信息并获取初步特征,再通过CNN获取更深层次的特征,最后通过SoftMax进行回归最终获得对应情感的分类概率P=(P正,P中,P负)。
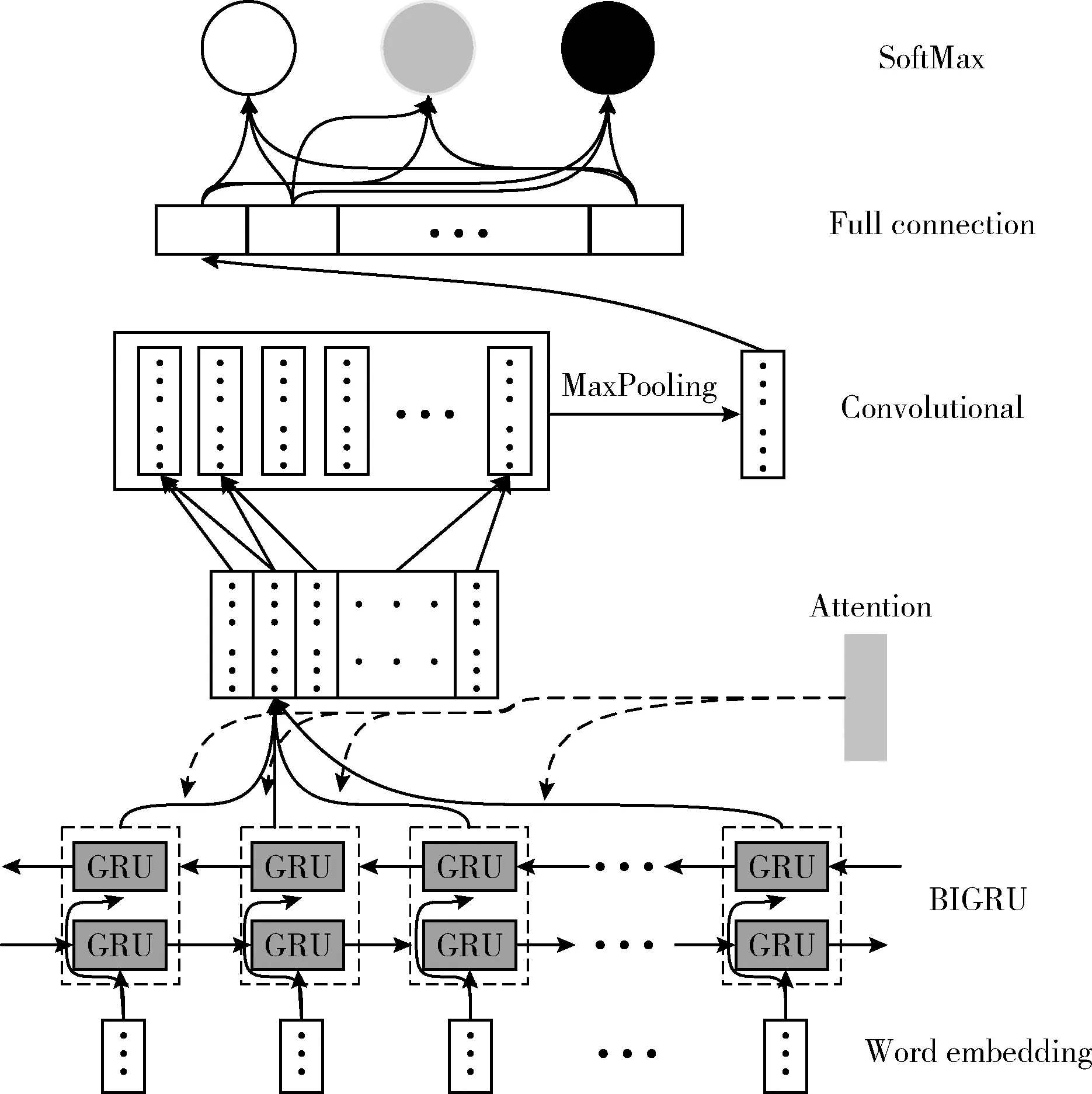
图2 基于多模型融合的情感分类模型
对最终获得的分类概率,选取最大概率值所对应的情感,作为情感分类的最终结果,并且通过之前的研究发现,对于某一情感分类的概率值越大则证明该文本的情感倾向性越强即情感特征比较明显,本研究采用情感分类的概率值作为情感值的结果,提出情感值的度量SI公式如下
Pi=max(P正,P中,P负)
(3)
(4)
2.3 用户自身质量评价
在新闻评论用户中,表征用户自身质量的两类因素包括用户评论的回复率以及用户评论的点赞率。因此,我们结合这两大因素来计算新闻评论用户的自身质量。
(1)用户评论的回复率
首先计算用户评论的平均回复数,即用户每条评论的回复总数除以用户发布评论的总数;然后再用用户评论的平均回复数除以总的用户数计算得到用户评论的回复率。用户评论的回复率表示每一位新闻评论用户在发布评论后平均被回复的数量,对体现用户所发布信息的传播能力具有较好的表征作用。本文使用Reply(z)表示用户评论的回复率,具体定义如下
(5)
式中:z表示用户,Sum(m)表示新闻评论用户z发布评论被回复的总数,Sum(a)表示用户z发布评论的总数,Sum(u)表示总用户数。
(2)用户评论的点赞率
在计算方法上,用户评论的点赞率与用户评论的回复率基本相同。首先计算用户评论的平均点赞数,即用户发布评论获得的总点赞数除以用户发布评论的总数,再使用用户评论的平均点赞数除以总用户数。本文使用Support(z)表示用户z所发布评论的点赞率,具体定义如下
(6)
式中:Sum(s)表示用户z发布的所有评论获得的总点赞数,其余符号与式(5)中的意义相同。由于用户评论的回复率和用户评论的点赞率对于表征用户自身质量的权重有所区别,因此,本文使用线性回归模型将用户评论的回复率以及点赞率结合起来计算用户自身质量评价值。定义如下,其中α,β分别表示两种用户行为所占的权重
Uquality(z)=α·Reply(z)+β·Support(z)
(7)
2.4 用户的网络结构影响力计算
用户在社交网络中与其他用户的联系,也是反映用户影响力的一个重要因素。PageRank算法是用来比较不同网页的重要性的算法,而在社交网络中用户的关系模型和网页的链接模型十分相似,用户的粉丝数相当于网络中用户节点的入度,用户的关注数相当于网络中用户节点的出度,所以可以利用PageRank算法来计算新闻评论网络中的不同用户之间的网络结构影响力,算法定义如下
PI(ui)=PageRank(ui)=
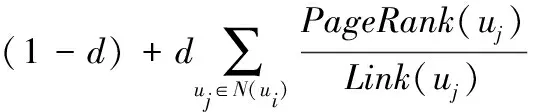
(8)
式中:ui和uj分别表示两个不同的用户,PageRank(ui)和PageRank(uj)则表示ui和uj所对应的Rank值,N(ui)是指链入ui的用户集合,Link(uj)是用户uj所有链接出去的边数量,即网络节点出度,d=0.85表示阻尼系数。
2.5 四度用户影响力分析模型构建
在前述已构建的用户评论内容影响力计算、用户评论内容的情感极性计算、用户自身质量评价和用户的网络结构影响力计算4个维度的结果基础上,最终的四度用户影响力分析模型定义如下
UI(z)=ω·(CI(z)+SI(z)+Uquality(z))+θ·PI(z)
(9)
式中:UI(z)表示用户z的影响力,CI(z),SI(z),Uquality(z),PI(z)分别表示用户z评论内容的影响力、评论的情感值、用户自身质量以及网络结构的影响力大小,ω,θ表示评价影响力各指标的权重。
3 实验结果及分析
3.1 实验数据集和评价方式
3.1.1 实验数据集
本文以腾讯新闻作为数据源,抓取了2019年5月至2019年6月两个月内发布的新闻及评论作为研究数据。由于爬取到的信息过于冗余,本文过滤粉丝数少于10的用户、点赞数少于10的用户,经过筛选之后的数据统计见表1。
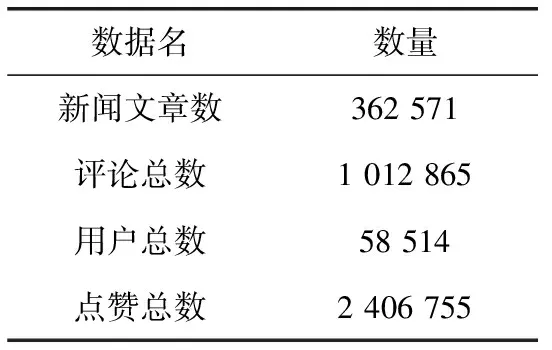
表1 腾讯新闻相关数据
3.1.2 实验评价方式
为了验证本文提出方法的有效性,实验选取目前较为流行或是经典的用户影响力分析算法作为对比,具体方法如下。
(1)经典的PageRank算法;
(2)Weng等[2]提出的TwitterRank算法;
(3)Brank[10]算法:基于PageRank算法进行的改进,从跟随者和追随者的角度双向交互,通过转发强度、评论强度、体积密度等方面来衡量用户影响力;
(4)RBrank[15]:该方法通过将用户活动添加到Page-Rank 中获得改进的算法;
(5)MDIR[17]算法:该方法通过融合用户基本属性、用户交互行为、用户博文内容多个维度来计算用户影响力。
实验利用N折交叉验证方法,即最后的参考标准结果由多种算法投票结果确定。例如给定5个算法A,B,C,D,E计算得到Top-K个高影响力用户集合分别为IA,IB,IC,ID,IE。此时取N=2,即2种算法都投票正确的结果为参考的正确结果,用I2表示,如下所示
I2=(IA∩IB)∪(IA∩IC)∪(IA∩ID)∪(IA∩IE)∪
(IB∩IC)∪(IB∩ID)∪(IB∩IE)∪(IC∩ID)∪
(IC∩IE)∪(ID∩IE)
(10)
对于算法A准确率PA的计算公式如式(11)所示
(11)
算法A的召回率RA计算公式如式(12)所示
(12)
算法A的F1值FA计算公式如式(13)所示
(13)
3.2 实验结果分析
本文初始化参数α,β,ω,θ分别为0.6、0.4、0.8、0.2,具体的参数选择实验会在3.2.2节中进行分析。实验分别在N=2,3,4,5时验证各个算法的准确率和召回率,当N=6时,由于参考的正确结果集合为6种算法结果的交集,从而导致所有算法均具有相同的准确率和召回率,所以N=6的实验不具备讨论价值。因此,在本文中只针对N=2,3,4,5的4种情况,对6种算法分别计算Top-K(K取值为50,100,200,400,800,1600)影响力用户的准确率、召回率进行比较。
3.2.1 算法准确率与召回率验证
如图3所示的实验结果可知,本文提出的FDRank算法在4组用户规模为Top-K的情况下准确率均取得了较优的结果,但由于N折交叉验证所取参考标准的值不同,实验效果也有所不同。由于参考标准值N设置过小(N=2),参考标准集合I2中元素数目过多,各算法与I2交集较为一致,导致准确率相差不大;当标准值N设置过大(N=5)时,参考标准集合中I5存在的元素较少,各算法结果与标准集的交集相差较大,故准确率整体偏低;参考标准值N设置为3,4时,各个算法的准确率区分度较大,能体现各个算法准确性的优劣。
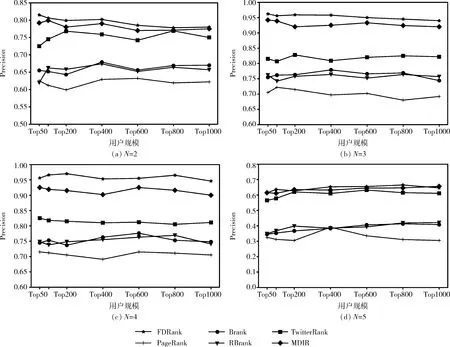
图3 在交叉验证中各算法的准确率
实验同样对比了6种算法在不同用户规模下,使用N折交叉验证的召回率。由图4所示,4组对比实验中,随着参考标准值N的增加,所有算法的召回率也呈现上升趋势,这是因为参考标准值N的增加,导致多个参考标准的交集元素减少,从而使得整体召回率上升。同时在实验结果中FDRank的召回率均优于其它算法,并且在参考标准值N设置为3,4时,召回率的区分度较大。可见,在N=3,4时,能够更好表征不同算法之间的优劣,因此,在后续的实验中,我们对N均取值为3和4。
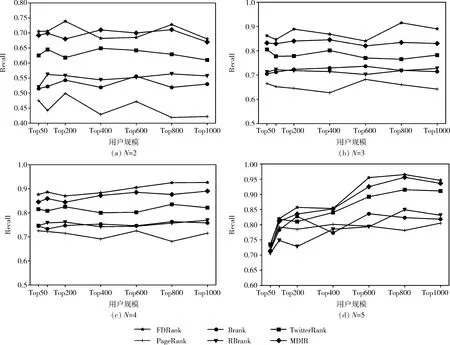
图4 在交叉验证中各算法的召回率
3.2.2 参数对比分析
本文提出方法中,有4个待确定的参数分别是α,β,ω,θ,通过赋予这些参数不同的数值,组成权值组,采用7组不同的权值组进行对比,并分别采用3折和4折交叉验证,得到各权值组的准确率和召回率。从图5和图6中可以看出,对于不同的权值组所得到的FDRank算法准确率和召回率是不同的,总体准确率在0.865~0.97之间,召回率在0.811~0.926之间,其中权值组参数α,β,ω,θ分别为0.6、0.5、0.8、0.2时,FDRank算法能取得最优结果。从权值组参数实验结果可以发现,网络拓扑结构对用户影响力分析结果的影响小于用户自身质量和评论内容,并且对于用户自身质量来说,用户评论回复率的影响程度高于用户评论点赞率。
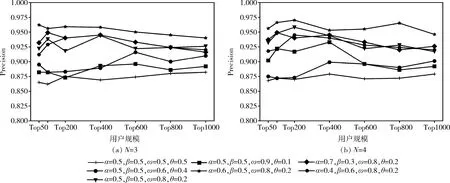
图5 各权值组准确率比较

图6 各权值组召回率比较
3.3 四度因素比较分析
为了更进一步验证本文提出方法的有效性,通过将FDRank算法的模块进行拆分,分别设计几种不同的组合进行实验:
组合1:FDRank1为单独使用网络结构影响力进行分析;
组合2:FDRank2由网络结构影响力和评论内容影响力组成;
组合3:FDRank3由网络结构影响力、评论内容影响力以及评论的情感值组成。
将4种FDRank组合算法分别与3.1.2节中提及的5种对比算法进行4折交叉验证,得到每种FDRank组合算法的F值,见表2。
表2 FDRank组合算法F值的比较结果
从表中可以发现,FDRank3在不同Top-K用户集获得的F值比FDRank2平均高了0.035,而FDRank3相较于FDRank2添加了评论的情感值作为一个影响因素,这也验证在计算用户影响力时,通过分析用户所发布评论的情感倾向有助于计算用户的影响力。同时从表中可以发现,在增加用户自身质量后,F值提升最为明显,说明用户自身质量是用户影响力计算中非常关键的因素。
4 结束语
本文从新闻评论内容的影响力、评论的情感值、用户自身质量以及用户的网络结构4方面考虑,提出FDRank算法。将评论内容的情感值作为用户影响力分析的特征,实验结果表明,用户评论内容的情感极性是分析用户影响力的有效特征。在与多个算法的对比实验中,FDRank算法均取得最优结果,准确率和召回率最高为97%和92.5%,相较于排名第二的MDIR算法,在不同的Top-K下准确率和召回率平均提升了4.3%和2.9%。本文在参数对比分析实验中考虑的参数权值组合有限,未能更有效定位最优参数,下一步的工作考虑自动化参数学习方式,探索采用Attention机制实现对模型参数的自动学习。
