基于块分类的深度图运动估计及其并行实现
2021-09-16谢晓燕王安琪胡传瞻杜卓林
谢晓燕,王安琪+,朱 筠,胡传瞻,杜卓林
(1.西安邮电大学 计算机学院,陕西 西安 710121;2.西安邮电大学 电子工程学院,陕西 西安 710121)
0 引 言
3D-HEVC标准[1]采用了多视点加深度(multi-view plus depth,MVD)的编码格式。MVD包含纹理图序列和相对应的深度图序列。纹理图具有丰富的细节信息和少部分较为平坦的纹理区域,而深度图的平坦区域占比高达85%[2],只有在物体的边界处有着陡峭的边缘。因此纹理图编码需要侧重于每个像素点的细节信息,而深度图只需要重点保护图像中各对象的边缘信息[3]。
针对如何利用深度图独有的内容特性,降低在帧间预测部分的编码复杂度,专家提出了一些有效的解决方案。文献[4]针对深度图平坦块在运动估计时采用了复杂度较高的全搜索(full search,FS)算法或者TZSearch算法进行块匹配,而导致了不必要计算量的问题,提出使用轻量级的菱形搜索(diamond search,DS)算法进行块匹配,但是忽略了深度图的边缘区域更难预测这一问题。文献[5]在文献[4]的基础上提出对深度图进行分类,对不同区域采用不同的搜索算法,有效降低了运动估计搜索点数。以上算法都是利用深度图的特性,从软件算法层面减少深度图的编码时间,但是无法满足实时视频编码的需求。因此,多媒体工程师尝试把视频算法向FPGA、ASIC上移植[6],文献[7]、文献[8]分别基于FS、DS算法设计了专用硬件架构。
综上,针对深度图特性的算法优化和硬件加速是改善3D-HEVC运动估计模块计算量和编码效率的有效手段,但是现有文献还未提出一种易于在硬件上实现且利用深度图特性的运动估计算法。本文利用深度图的特性,在运动估计前增加预处理模块对编码块进行分类,为边缘和平坦区域选择不同的搜索算法,在保证编码质量的前提下,降低平坦块的计算量;同时对优化后的算法基于阵列处理器并行实现,加快运动估计的计算速度,达到算法效率、编码质量和硬件实现的良好折中。
1 深度图的帧间运动估计
在3D-HEVC的深度图帧间编码过程中,延用了HEVC纹理图的运动估计技术。如图1所示,对需要编码的当前帧,以块为单位在参考帧的特定区域内进行搜索,并按照一定的块匹配准则寻找到最佳匹配块。当前块与最佳匹配块之间的相对位移就是运动矢量。
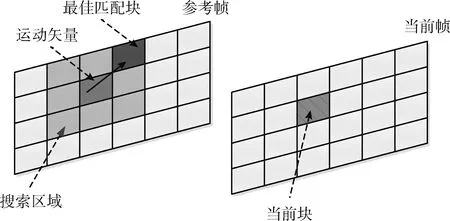
图1 深度图运动估计原理
通常采用绝对差值和(sum of absolute difference,SAD)准则来判断当前块与参考块之间的匹配程度,SAD值越低,则两个编码块的匹配程度越高。SAD的计算方法如式(1)所示
(1)
式中:对于大小为M×N的编码块,fi(m,n)表示第i帧中坐标为(m,n)处的像素值,fi-1(m+x,n+y)表示第i-1帧中坐标为(m+x,n+y)处的像素值,(x,y)表示运动矢量。
在3D-HEVC标准测试软件中,推荐了FS和TZSearch两种搜索最佳匹配块的算法。FS算法需要将搜索窗中所有位移的参考块逐一地与当前块进行比较,寻找SAD值最小的最佳匹配块。TZSearch算法结合了DS算法和光栅搜索,能够极大减少运动搜索点数同时保持编码性能。但是这两种搜索算法是针对变化复杂的纹理图属性设计的,当被用于平坦区域为主要特征的深度图时,会导致较多的运动搜索点数,使得计算时间增加。在3D-HEVC深度图编码中,运动估计模块的计算量占深度图编码总计算量的19.74%[4]。因此如果引入轻量级的搜索算法将会大大降低运动估计模块的计算开销。
2 基于块分类的深度图运动估计优化方法
2.1 运动矢量的中心偏置特性分析
在运动图像中,中心偏置特性反映了视频图像帧间运动的强烈程度。当帧间运动较小时运动矢量总会高度聚集在搜索窗口的中心位置,通常是两个像素为半径的范围。该特性通常用以减少搜索点数,提高搜索效率。本文对平坦区域和边缘区域编码块运动矢量的分布进行了研究,发现平坦区域运动矢量的中心偏置特性非常明显,如图2所示。图2对深度图测试序列Balloons中编码块的SAD值进行了统计。其中,图2(a)、图2(b)分别为第45帧和第46帧的部分区域。图2(b)所示标号为1,2的部分为第46帧的两个16×16的编码块。可以看出标号为1的编码块位于边缘区域,标号为2的编码块位于平坦区域,它们在第45帧中的同位块和搜索窗位置如图2(a)所示。图2(c)、图2(d)分别给出了对第46帧编码块1和编码块2在第45帧对应搜索窗中应用FS算法获得的SAD值分布。从图2(c)可以看出,边缘区域编码块的SAD值变化复杂,且较低的SAD值距离搜索区域中心点(40,40)较远,所以运动矢量没有表现出较为明显的中心偏置分布特性;而图2(d)中平坦区域编码块的SAD值变化平缓,且最佳的SAD值高度集中分布在搜索区域中心点的附近位置,其运动矢量更具有中心偏置分布特性。

图2 边缘、平坦区域SAD值分布
因此,边缘区域的运动矢量过于分散,必须选取精细型的搜索算法,才能在搜索窗中找到最佳的SAD值;而对平坦区域则可以利用其运动矢量的中心偏置分布特性,使用轻量级的快速搜索算法,减少搜索次数,提高收敛速度。
若要在硬件上实现深度图运动估计算法,则选取的搜索算法模板不仅要适合深度图的SAD值分布还要具有较天然的操作可并行性。TZSearch算法可以达到和FS算法相差不多的编码质量并且降低了运动搜索点数,但是TZSearch算法在搜索时采用了多个搜索模板,使得搜索路径不确定且数据读取不规则,因而不利于算法的并行实现;考虑到FS算法计算结构简单且易于并行处理,本文对深度图中的边缘区域采用了FS算法。此外,考虑到DS算法能够充分利用运动矢量的中心偏置分布特性,优先计算搜索窗口的中心点,对于小运动的视频序列有较好的预测结果[9],非常契合深度图大范围平坦区域的特点,本文选择DS算法处理深度图的平坦区域。
2.2 算法切换的阈值判定
如果要对不同类型区域编码块使用不同的搜索算法,就需要增加预处理模块,对编码块是平坦或者边缘进行判定。常用的深度图像边缘检测方法有两大类,一类是利用边缘检测算子提取图像的边缘,该方法在计算过程中采取了大量的卷积操作,使得计算量增加,且边缘检测算子对图像噪声敏感。另一类是通过统计分析的方法得到区分边缘和平坦区域的经验阈值,文献[4]采用编码块4个角的最大差值对深度图进行分类,若最大差值大于阈值则判定为边缘块,反之则判定为平坦块,大大降低了计算开销,但是会对边缘位于编码块内部的情况会产生误判。因此本文针对该问题在文献[4]的基础上引入差异程度Pmax对深度图进行分类,该方法计算开销较小同时也可以解决文献[4]存在的误判问题。
以测试序列Balloons第一帧的深度图像为例,如图3所示。其中编号1-4为平坦区域编码块,其像素值均无变化,编号5-8为边缘区域编码块,其像素值有明显的边界变化。本文选用一个编码块4个角的像素值作为基准像素值,对编码块内部的所有像素值分别与4个基准像素值作差求得绝对差值和,选用其中最大的绝对差值和作为差异程度Pmax。对一个大小为M×N的编码块,其差异程度Pmax可以通过式(2)获得

图3 Balloons序列深度图
(2)
式中:f(m,n)表示坐标为(m,n)处的像素值,Pi表示第i个角的基准像素值。
为了挖掘编码块像素值分布特征和差异程度Pmax之间的关系,本文利用3D-HEVC帧内预测的模式选择结果来对深度图编码块的差异程度进行分类。由于在3D-HEVC帧内预测中,除了常规的35种帧内预测模式,还专门针对边缘区域新增了深度建模模式(depth model modeling,DMM)。因此若某编码块选取常规帧内预测模式作为最佳预测模式,即该编码块更大概率为平坦区域,而选取DMM作为最佳预测模式时,该编码块为边缘区域的可能性更大。它们所对应的Pmax就可以被用来作为编码块特征的判定依据。
为此,本文在3D-HEVC测试平台HTM16.0上对测试序列进行了预测模式数据统计。在通用测试条件(common test condition,CTC)配置下,使用Kendo和Poznan_Street两组测试序列,计算了8×8,16×16,32×32等不同大小编码单元(coding unit,CU)的Pmax以及该CU选取的帧内预测模式,并统计了Pmax在各个区间的概率密度。图4(a)~图4(c)分别给出了8×8、16×16、32×32CU的Pmax概率密度分布曲线。在图4(a)中可以看出当Pmax小于800时,8×8CU选取常规的帧内预测模式概率很大;当Pmax大于800时,8×8CU选取DMM的概率很大。因此本文将Pmax等于800作为区分8×8CU为平坦区域或者边缘区域的阈值TH8×8。同理可以得到16×16CU和32×32CU的阈值。由于尺寸较大的CU包含的像素多,所以16×16CU和32×32CU的阈值会更高一些。

图4 Pmax概率密度分布曲线
采用2.1节和2.2节的优化思路,本文提出了一种基于块分类的深度图运动估计算法,其流程如图5所示。
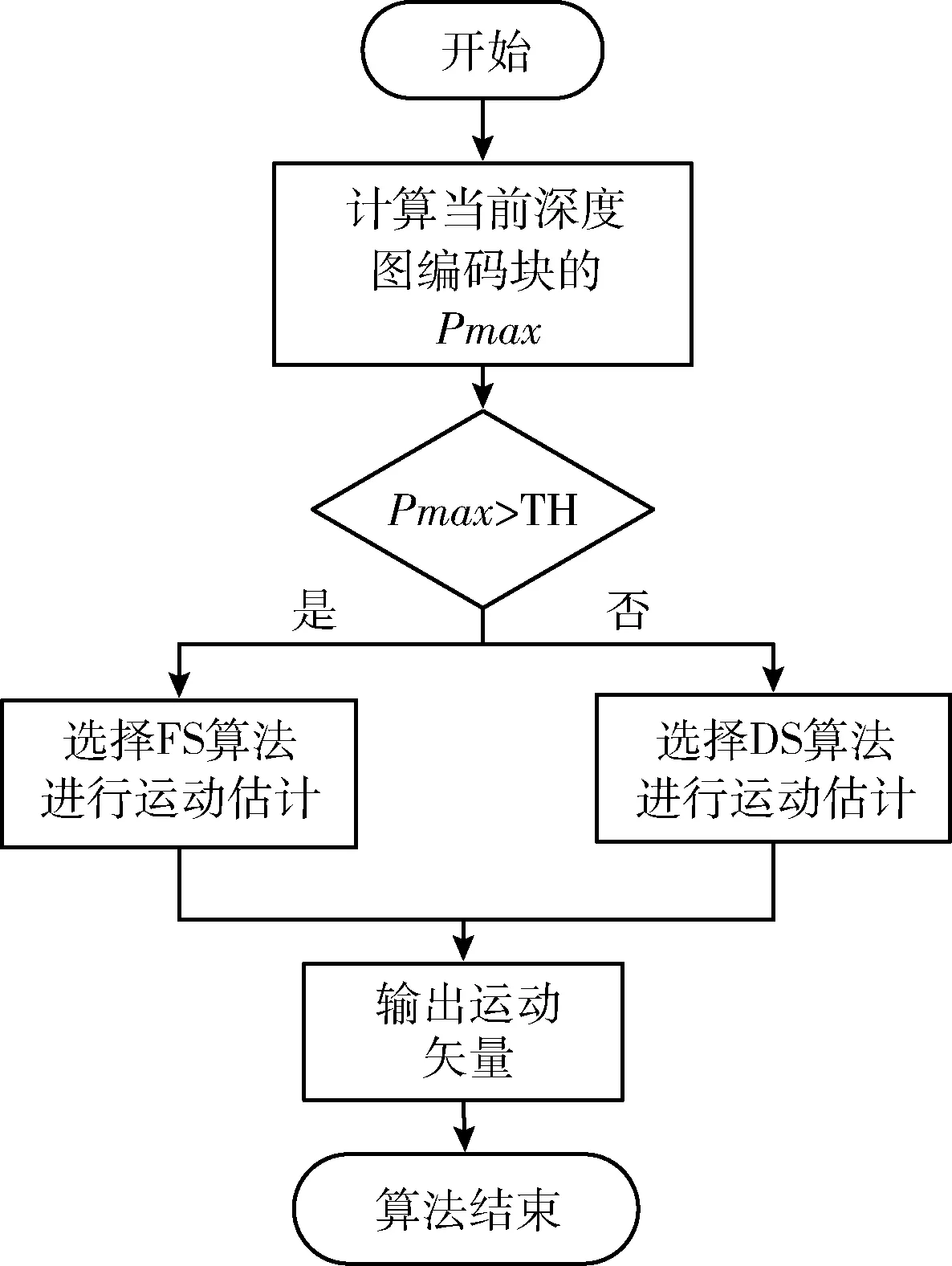
图5 基于块分类的深度图运动估计算法流程
3 优化后算法的并行化实现
3.1 视频阵列处理器结构
本文所使用的视频阵列处理器[10]是由项目组自主研发的一种可重构视频阵列处理器,支持H.264/AVC,MVC,H.265/HEVC等多种视频编解码标准。该处理器从逻辑上将阵列划分成处理元簇(process elements group,PEG),每个PEG由4×4的处理元(process element,PE)阵列构成。每个PE不仅可以访问自身的存储器和寄存器,还可以通过邻接互连和共享存储的通信方式访问同一PEG内其它PE的数据。由于视频算法中的数据处理大部分都是以N×N的矩形块进行的,所以这种专用体系结构相比其它结构能更有效应对视频算法的并行化设计。
通过对运动估计算法分析发现,每一个编码块依据其原始像素值、参考像素值及相应的搜索算法进行块匹配,获得该编码块的最佳匹配块。下一个编码块进行块匹配时所需要的数据并不依赖于上一个编码块的计算结果,所以不同编码块在块匹配计算时没有数据相关性。因此,可以对多个编码块的计算使用并行操作以减少编码时间。
3.2 参考像素的数据复用
本文利用视频阵列处理器的天然并行结构,以8×8大小的编码块为对象,对搜索窗为16×16的深度图运动估计进行并行化设计。如果同时对多个不同的编码块并行进行块匹配,可以大幅度减少运动估计算法的周期数,但是却增加了电路面积和功耗。因此,合理的选择并行计算编码块的个数,才能达到充分利用资源和缩减编码时间的效果。
本文从最大化复用最先被读取的编码块参考像素的角度,来选取并行计算的编码块。根据运动估计算法,上下左右4个相邻编码块的搜索窗之间存在大量参考像素的重合,编码块1搜索窗第9列到第16列的参考像素为编码块2搜索窗的第1列到第8列如图6(a)所示,编码块1搜索窗第9行到第16行的参考像素为编码块3搜索窗的第1行到第8行如图6(b)所示,编码块1搜索窗的第9行第9列、第9行第16列、第16行第9列、第16行第16列所围成8×8搜索区域是编码块4搜索窗的第1行第1列、第1行第8列、第8行第1列、第8行第8列所围成区域的参考像素如图6(c)所示,编码块2~编码块4的参考像素和编码块1搜索窗重合的总像素数为196个。如果为4个编码块分别从片外存储加载搜索窗,将会有大量的参考像素被重复的读取,增加了计算的总周期数。但是如果将编码块1本地存储的参考像素复用到编码块2~编码块4的参考像素中,对编码块1参考像素的数据复用可以达到75%,从而有效地减少访问片外存储器的次数,缩减运动估计算法的时间。综上所述,本文选择同时对4个8×8编码块并行计算。
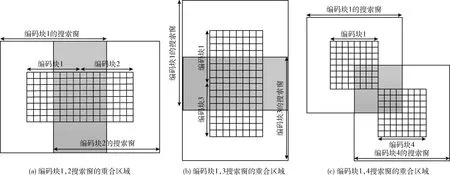
图6 编码块1搜索窗的数据复用
3.3 基于块分类的深度图运动估计算法并行映射
本文采用一个PEG结合3.2节提出的参考像素的数据更新方法,对4个8×8的编码块并行地进行第2节所提优化算法的阈值计算和块匹配。算法的映射图如图7所示,数据输入存储器(data input memory,DIM)、数据输出存储器(data output memory,DOM)均为片外存储器,分别缓存原始视频序列和参考视频序列,PE00、PE10分别为原始像素和参考像素加载模块;PE01、PE02、PE03和PE13为Pmax计算模块;PE11、PE12、PE20和PE21为采用FS算法计算SAD值模块,PE22、PE23、PE30和PE31为采用DS算法计算SAD值模块;PE32为数据输出模块。具体操作步骤如下:

图7 优化后运动估计算法映射
步骤1 原始数据的加载。PE00访问DIM,读取一个16×16的编码块,并将编码块1、2、3、4的原始像素值分别下发给PE01、PE02、PE03和PE13;
步骤2 参考数据的加载。PE10访问DOM,按照上述参考像素复用的方式,将编码块1、2、3、4的参考像素值分别下发给PE11、PE12、PE20和PE21;
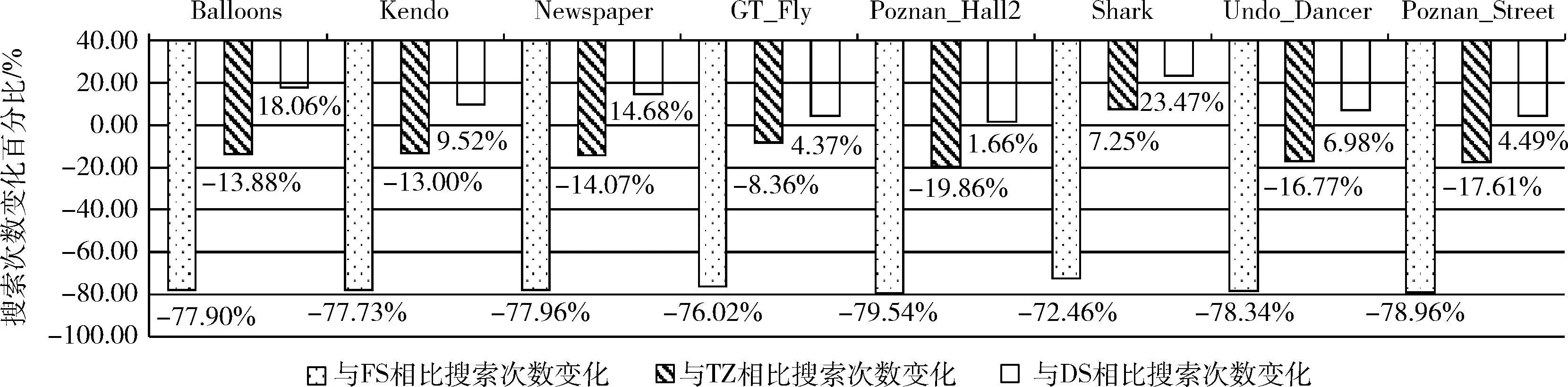
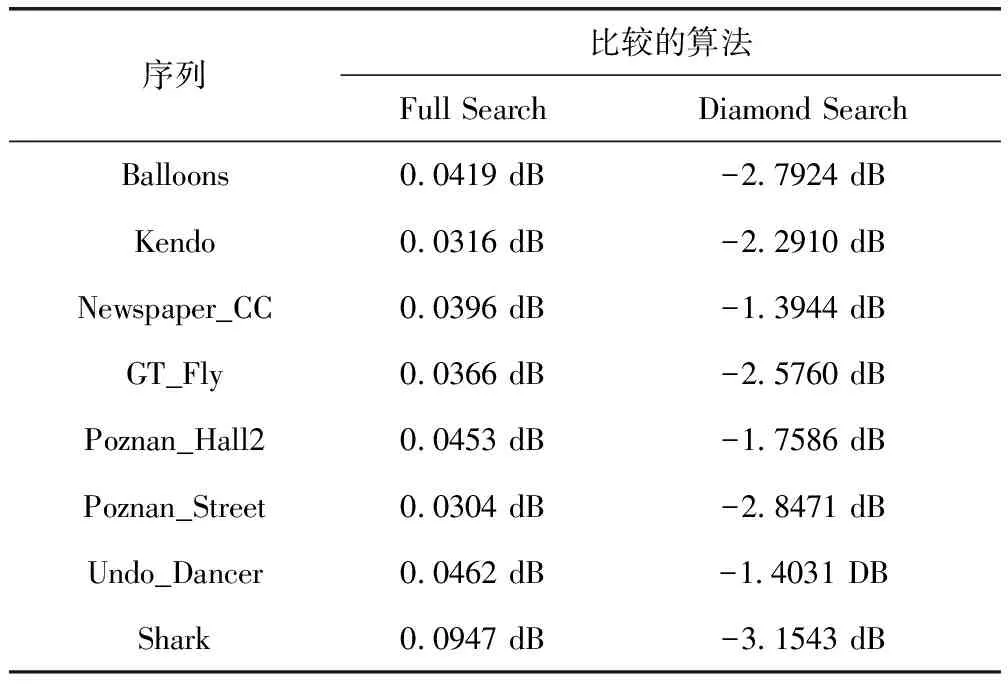
步骤3 4个PE并行为4个编码块计算Pmax。根据4个PE计算Pmax的不同,4个编码块根据不同的搜索算法进行SAD值的计算,如果Pmax>TH8×8则跳转至步骤4;如果Pmax 步骤4 PE11、PE12、PE20和PE21根据FS算法为当前编码块进行块匹配操作。计算得到最佳SAD值后,将最佳SAD值对应参考块的运动矢量存储到PE32中。 步骤5 PE22、PE23、PE30和PE31根据DS算法为当前编码块进行块匹配操作。计算得到最佳SAD值后,将最佳SAD值对应的运动矢量存储到PE32中。 步骤6 PE32收到编码块1、2、3、4的运动矢量之后,将其输出。 为了比较基于块分类的深度图运动估计算法的效果,本文使用了包含不同分辨率和不同运动情况的8组公共测试序列的1-50帧,在MATLAB平台上通过统计运动搜索次数,用于衡量算法的计算量;统计图像的PSNR用于衡量算法的性能。并基于视频阵列处理器验证上述基于块分类的深度图运动估计算法并行实现的可行性,通过加速比和硬件架构资源分析来衡量在视频阵列处理器上进行并行化的性能。 在运动估计中,运动搜索的次数可以反应运动估计算法的计算量。图8给出了本文提出的搜索算法与FS算法、DS算法和TZSearch算法相比较搜索次数改变的百分比,计算公式如式(3)所示 (3) 式中:Ptprop代表本文搜索算法的搜索点数,Ptcompare代表FS算法、DS算法或者TZSearch算法的搜索点数,从图8中可以看出与FS算法相比,本文提出的搜索算法可以大幅度地减少搜索点数,所有测试序列的搜索点数平均减少77.32%;相比于TZSearch算法,所有测试序列的搜索点数平均减少12.04%,极大降低了运动估计算法的计算量。相比于DS算法,所有测试序列的搜索点数平均增加10.40%。其中Shark序列相比于FS算法搜索点数减少的幅度较小,相比于TZSearch算法是唯一一个搜索点数增加的测试序列,相比于DS算法搜索点数增加的幅度最大,是因为该序列的前景和背景区域存在着较多的运动对象且运动幅度较大,导致图像边缘区域增多。Poznan_Hall2序列相比于FS算法和TZSearch算法搜索点数减少幅度较大,相比于DS算法搜索点数幅度增加最少,是因为该序列的平坦区域占比更高,且物体的运动幅度较小。 图8 本文搜索算法减少的搜索点数 PSNR是一种衡量图像质量的指标,表1为本文算法与FS算法、DS算法相比图像的PSNR损耗。从表1可以看出,与FS算法相比,本文算法的平均PSNR损耗为0.0870 dB,在运动搜索次数大幅度降低的情况下,可以达到和FS算法相差不多的PSNR。相比于DS算法,在运动搜索次数小幅度增加的情况下,本文算法的平均PSNR损耗为-2.2771 dB。在折中考虑运动搜索次数和图像质量的情况下,本文所提出的算法在达到和FS算法相差不多的PSNR的情况下,相比于TZSearch算法可以减少12.04%的运动搜索次数,所以本文提出的改进方法比TZSearch算法性能略佳。 表1 优化后算法的PSNR损耗 本文在视频阵列处理器上验证基于块分类的深度图运动估计算法并行实现的可行性。首先将测试序列转换成阵列可以识别的二进制序列,然后将原始帧和参考帧分别存储在片外存储DIM和DOM中,其次将并行方案的指令初始化到对应PE的指令存储中,最后在QuestaSim上进行仿真验证。本文用单PE的串行执行时间作为串行处理时间。8组公共视频测试序列的平均串行执行时间为1.308 s,并行执行时间为0.452 s,平均加速比可以达到2.894,减少了65%的执行时间。采用Xilinx公司的ISE14.7开发环境进行综合,综合结果见表2,可看出仅需要11 722个LUTs,33 641个Registers的硬件资源,最高工作频率可达到122 MHz。文献[7]是在DS算法的基础上提出的改进算法和硬件架构,可以同时计算一个预测单元内所有的搜索点数,但是是以消耗了大量的硬件资源为代价的,所使用的硬件资源为本文的8.75倍。文献[8]是在FS算法的基础上设计的硬件架构,在频率和本文相当的情况下,硬件资源是本文设计的1.2倍。 表2 硬件资源结果对比 本文针对深度图的运动估计,提出了一种结合算法和并行设计的优化方法。首先针对深度图的特点,优化了运动估计搜索算法。实验结果表明,与FS算法相比,8组测试序列的平均PSNR值损耗仅为0.0870 dB;与TZSearch算法相比,运动搜索次数平均减少了12.04%,在折中考虑运动搜索次数和编码质量的情况下,该方法获得了略优于TZSearch算法的性能。然后,基于视频阵列处理器对提出的改进方法进行了并行化设计,又从最大化复用参考数据的角度选取了并行计算编码块的个数,进一步减少了硬件资源的消耗。本文提出的基于块分类的深度图运动估计及其并行实现方案,在编码质量、计算效率和资源消耗方面均得到了不同程度的改善。4 实验结果与分析
4.1 算法的运动搜索次数分析
4.2 算法的性能
4.3 硬件综合对比结果

5 结束语
