鲁棒的数字语音取证算法
2021-09-16师春灵
师春灵,钱 清
(1.信阳学院 大数据与人工智能学院,河南 信阳 464000;2.贵州财经大学 信息学院,贵州 贵阳 550025)
0 引 言
数字音频内容真实性和完整性取证问题已成为当前多媒体信息安全领域的研究热点[1]。用于取证的水印技术发展至今已取得了丰硕的研究成果[2-6]。文献[7]提出了一种精确篡改定位的数字语音取证算法。文中定义了一种保密的语音特征——能量比,并给出了基于能量比的水印嵌入的理论依据,进一步通过实验分析了该特征的鲁棒性和水印的抗信号处理能力。然而随着应用的深入,对语音信号处理的方式趋于多样化,文献[7]的算法对于传统信号处理具有一定的鲁棒性,然而对于其它信号处理,比如添加回声等操作,则鲁棒性不能满足实际需求。对于另外一部分采用公开特征进行水印嵌入的算法[8,9],由于特征易被攻击者获取,导致嵌入的水印存在安全隐患。
5G的大带宽使高清信号的实时传输成为可能,必将带来语音信号采样频率的提高。对于采样频率较高的语音信号而言,采用传统的水印技术来进行取证,或多或少地存在一些针对性不强的问题[10-12]。从实际需求出发,以数字语音信号为载体,提出了一种鲁棒的水印取证算法。定义了语音信号FDCR(frequency domain coefficient residuals)特征,并分析了此特征对信号处理的鲁棒性以及对恶意攻击的脆弱性。本文将语音信号分帧,将各帧帧号映射为二进制的水印序列。然后,将各帧分段,并提取各段信号的FDCR特征。依据嵌入信息的不同来量化FDCR特征,进一步通过修改对应的DCT系数来完成水印的嵌入。提取端,通过提取二进制水印信息,并将其转换成帧号来进行内容取证,以及必要时候的篡改定位。最后实验分析了本算法的综合性能,表明本文所提算法具有较好的不可听性,对信号处理操作具有较好的鲁棒性,同时提高了水印系统的安全性,以及对恶意攻击的篡改定位能力。
1 特征提取
1.1 FDCR特征的定义
对于含有N个样本的音频信号A={an|1≤n≤N},由式(1)计算其DCT系数,记为C={cn|1≤n≤N}
(1)
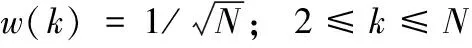
从DCT系数C中选低频和中频系数(长度均为M),分别记为Clow和Cmed。由式(2)计算低频系数Clow的对数和Dlow
(2)
式中:α>0,λ>max(|Clow|,|Cmed|),α和λ作为本文水印系统的密钥。同样,计算中频系数Cmed的对数和Dmed。由式(3)计算信号A的FDCR特征
R=|Dlow-Dmed|
(3)
对音频信号而言,一方面,高频部分更多表征信号的细节部分,而能量主要集中在低频和中频部分。另一方面,不同内容的信号,低频和中频之间的关系存在差异;而对于表达内容相同的信号(如经过一定信号处理前后的信号),低频和中频之间的关系具有一定的稳定性。基于此,本文提出了如式(3)所示的音频信号FDCR特征。下面测试FDCR特征在信号处理后的改变程度。
1.2 鲁棒性分析
随机选取一段长为L,采样频率为44.1 kHz的语音信号,记为A,如图1所示。下面实验分析FDCR在信号处理后的改变程度。

图1 原始语音信号
(1)将A分为P帧,第i帧记为Ai,每帧长为N。
(2)对Ai进行DCT,计算其FDCR特征,记为Ri。
(3)对语音信号A进行信号处理操作,包括压缩率为64 kbps的MP3压缩、由44.1 kHz采样频率下降到22.05 kHz的重采样、截至频率为8 kHz的低通滤波操作。图2给出了语音信号进行信号处理前后各帧的FDCR特征。
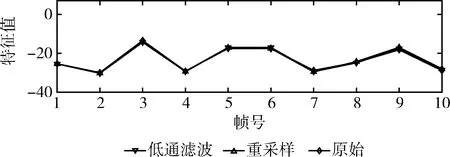
图2 语音信号进行处理前后各帧的FDCR特征
(4)对语音信号A进行恶意攻击(从其它信号中选取一段内容,对A进行替换攻击),攻击后的信号如图3所示。图4给出了原始信号A各帧的FDCR特征和替换攻击后各帧的FDCR特征。
图3 替换攻击后的语音信号
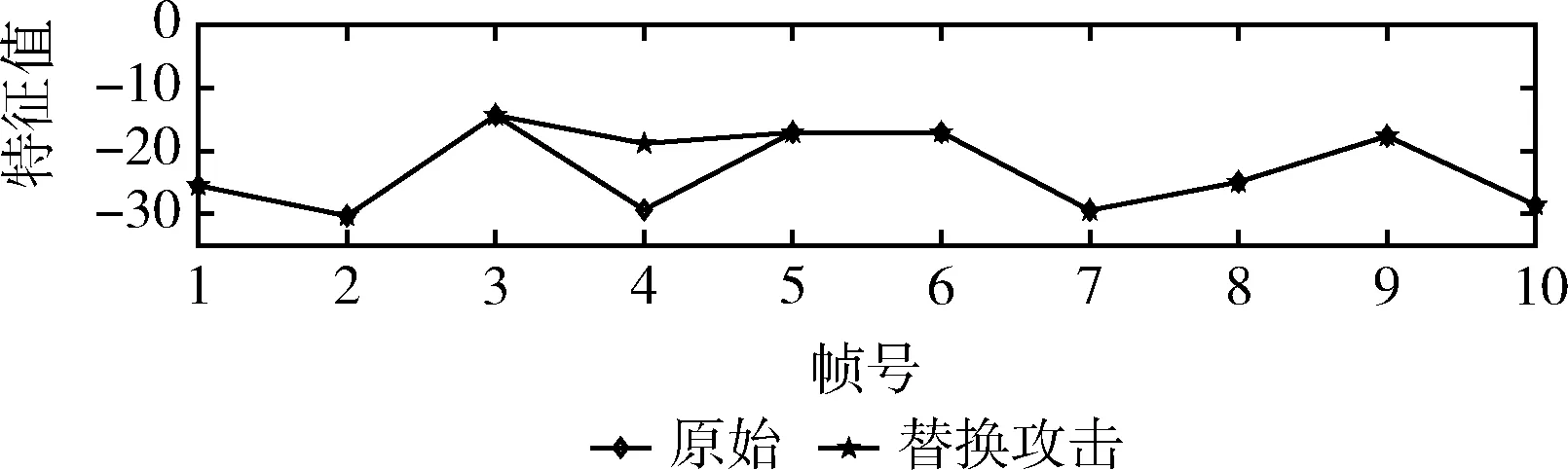
图4 替换攻击前后语音信号的FDCR特征
为了测试不同类型信号FDCR特征对信号处理的鲁棒性,从样本库随机选取200段不同类型的语音信号,包括男声和女声,录制环境有安静的室内、讨论会现场、空旷的野外。然后对选取的测试信号进行信号处理操作(64 kbps的MP3压缩、由44.1 kHz采样频率下降到22.05 kHz的重采样、截至频率为8 kHz的低通滤波)。将原信号和信号处理后的信号分帧(这里等分为40帧),分别计算200段信号处理前后各帧的FDCR特征统计均值,如图5所示。由测试结果可得不同类型语音信号FDCR特征信号处理前后几乎保持不变,具有较好的鲁棒性。若采用量化FDCR特征的方法来嵌入水印,可以保证含水印信号在信号处理后,以较高的概率正确地提取嵌入的信息。
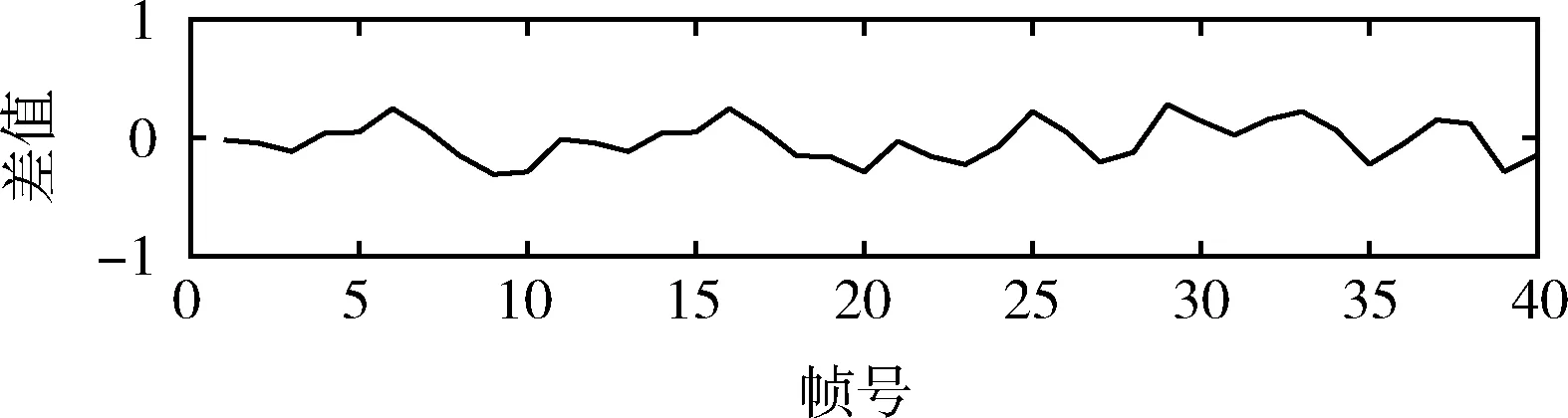
图5 200段不同类型的语音信号处理前后FDCR特征变化统计均值
从以上测试结果表明,本文提出的FDCR特征对信号处理具有一定的鲁棒性,对恶意攻击(改变音频表达内容)具有一定的脆弱性。下面我们分析FDCR特征和DCT系数之间的关系,为将FDCR特征作为嵌入域的水印嵌入提供量化方法。
1.3 DCT系数和FDCR特征之间的关系
由语音信号DCT系数构造了FDCR特征,实验验证了FDCR特征对信号处理的鲁棒性和恶意攻击的脆弱性。基于FDCR特征的性质,本文将FDCR作为嵌入域来嵌入水印信息。下面给出DCT系数和FDCR特征之间的关系,为本文通过量化DCT系数来修改FDCR特征值,实现水印的嵌入提供依据。假设Dlow>Dmed(对于Dlow≤Dmed的情况类似),且通过修改低频系数Clow来量化FDCR特征。R和R′分别表示量化前后的FDCR特征,Clow和C′low分别表示量化前后的DCT低频系数。式(4)给出了量化前后的DCT低频系数之间的关系,表明本文嵌入水印可以采用式(4)的方法来量化DCT低频系数完成水印的嵌入。其中c′n∈C′low
(4)
2 水印方案
本文提出的取证水印算法,首先将语音信号分帧,记录各帧帧号,并将帧号映射为水印信息,嵌入在对应的语音帧中。当含水印信号被恶意攻击后,被攻击语音帧中的水印将很难被准确地提取。然而,却能够从攻击语音帧前后相邻的没有被攻击的帧中提取准确的水印信息。将提取的水印信息映射为帧号,前后帧号中不连续的部分即为被攻击的内容,以此来取证并进行篡改定位,详细的水印方案如下。
2.1 水印嵌入
取语音信号A={al|1≤l≤L},al表示第l个样本点,L表示信号A的长度。
(1)将语音信号A等分为P帧,第i帧记为Ai,每帧长为N,N=L/P。
(2)由式(5)将Ai的帧号i映射为二进制序列Bi={bt|1≤t≤T}
i=b1×2T-1+b2×2T-2+…+bT-1×2+bT
(5)
(3)将Ai等分为2T段,第t段记为Ai,t,1≤t≤2T,将Bi分别嵌入Ai的前后两段中。对Ai,t进行DCT,并取DCT系数的低频和中频系数,由式(2)和式(3)计算Ai,t的FDCR特征,记为Ri,t。
(4)根据bt来量化Ri,t,如式(6),其中Δ表示量化步长,R′i,t表示量化后的FDCR特征
(6)
(5)根据量化前后的FDCR特征Ri,t和R′i,t,由式(4)对第i帧第t段的DCT低频系数幅值进行量化,然后逆DCT生成含水印的第i帧第t段的信号。
重复上述方法,完成各帧水印的嵌入,得到的含水印信号记为A′i。嵌入过程如图6所示。
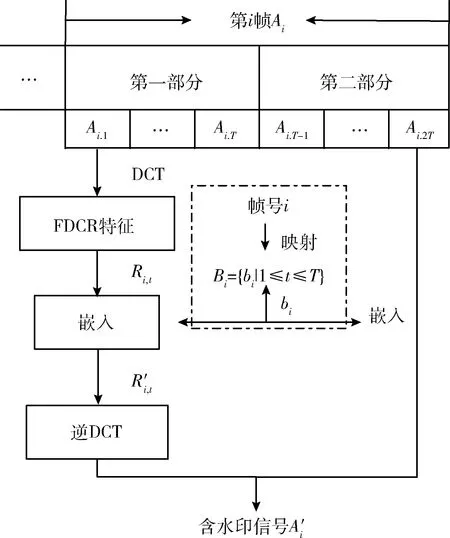
图6 水印嵌入过程框架
2.2 水印提取
将含水印信号记为A*,长度为L*,水印提取和内容取证过程如下:
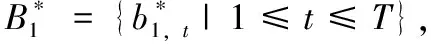
(7)
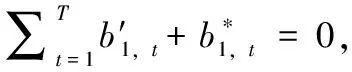
(5)若检测到第1帧的内容是真实的,则将第1帧后面的样本依照上述方法进行分帧并验证其真实性;若检测到第1帧的内容是被攻击的,移动样本重新分帧,检测新的分帧内容的真实性,直到检测到内容真实的语音帧为止。不能被准确提取的语音帧的帧号(缺失的帧号)即为篡改定位的结果。水印提取和内容的取证流程如图7所示。

图7 水印提取和内容取证过程框架
值得一提的是,水印提取端一般情况下并不了解待提取信号是经历了何种攻击(如剪切、替换等),部分攻击会导致含水印信号的长度和原始信号有所不同。此种情况下,若将含水印信号等分为P帧,存在分帧长度和原始信号相差较大的情况(如远大于或小于N)。为了避免此类问题的出现,也为了提高水印提取的正确率,从含水印信号起始位置,以和N接近的长度进行分帧(如90%×N、N、110%×N),以能够通过验证为目的。下面,我们通过实验来测试本文算法的综合性能。
3 性能分析与测试
为了测试本文算法对不同类型信号的综合性能,选取300段语音信号作为测试样本库,包括150段不同环境下的男声语音信号(安静的办公室、讨论会现场、火车站候车大厅各50段),150段相同环境下的女声语音信号。测试信号采样频率为44.1 kHz,16位量化的单声道语音信号。在Window10操作系统,Matlab2018a的软件环境下,根据本文算法,生成300段含水印的语音信号,其中所用参数为L=441 000,N=4410,P=10,α=0.001,T=5,λ=11。然后结合GoldWave工具对含水印信号进行信号处理操作,以及恶意攻击操作,综合实验结果如下。
3.1 不可听性
通常水印的嵌入会对原始音频信号造成改变,如果改变程度较大,会影响原始信号的听觉质量。水印嵌入对原始音频信号改变程度可用水印不可听性来衡量,主要有主观和客观两种评价方式。主观评价方法常见的为主观区分度(subjective difference grades,SDG),客观评价方法常见的为信噪比(signal to noise ratio,SNR)。主观区分度是将原始信号和含水印信号给听众现场试听,并依据主观区分度评价标准来打分,打分的平均值作为SDG值。主观区分度评价标准见表1。客观评价方法信噪比,是将嵌入的水印看作在原始信号中添加的噪声,其计算方法如式(8)所示,其中a(l)和a′(l)分别表示原始信号和含水印信号的第l个样本点。通常来讲,SDG和SNR值越大,说明含水印信号的听觉质量越好

表1 SDG值和ODG值的评分标准
(8)
本文对300段测试信号分别计算SDG值和SNR值。SDG值由15位听众打分所得;SNR值由式(8)计算所得。表2给出了SDG值和SNR值的最大值、最小值,以及300段测试信号的平均值。由表2所示结果可得,SDG值和SNR值均大于评价系统所要求的最小值(SDG>-1,SNR>20),表明本所提算法满足水印不可听性的要求。
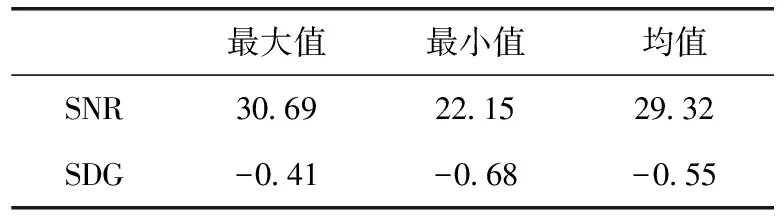
表2 含水印信号的SNR值和SDG值
对于音频信号而言,攻击类型可以简单地分为两种,第一种为不改变表达内容的攻击(信号处理操作),如格式转换、压缩等;第二种为改变表达含义的恶意攻击,如删除、替换攻击。由于信号处理操作不改变原信号的表达含义,信号处理后的信号本文将其视为真实的信号。对于恶意攻击,本文将对其进行检测,并篡改定位。下面首先测试本文算法的鲁棒性,然后给出对恶意攻击的取证以及篡改定位结果。
3.2 鲁棒性
这里采用误码率(BER)来测试水印提取的准确率。BER值率越小,说明提取水印的错误率越低,正确率越高,算法鲁棒性越强。BER的定义如式(9)所示
(9)
式中:2T×P表示嵌入水印的长度,b(t)和b*(t)分别表示原始水印信息和提取的水印信息,⊕表示异或操作。
为了测试算法的鲁棒性,本文将测试样本进行MP3压缩、添加回声、低通滤波等信号处理,然后提取信号处理后信号中的水印信息,并依据式(9)计算水印提取的BER值。表3给出了300段测试信号BER值的平均值。
表3所列结果表明,本文算法在经过128 kbps的MP3压缩后,可以从压缩信号中完整无误地提取水印信息。经过压缩率为64 kbps的MP3压缩之后,BER值相比压缩率为128 kbps的情况有所增加,但增加的幅度非常小,水印提取准确率也达到了99%。不可否认文献[7]也有不错的抗MP3压缩的能力,不过本文水印提取准确率更好,表明具有更好的鲁棒性。对于回声(40%)和高斯噪声(20 dB)而言,本文算法同样具有比较高的水印提取准确率。尤其是对于截至频率为8 kHz的低通滤波而言,本文算法能够以99%准确率提取水印信息。通常而言,8 kHz采样频率的语音信号已能满足通信和交流的需要。于是和音频信号(如歌曲)相比,8 kHz的低通滤波处理更为常见。从测试结果来看,和文献[7]相比,对于8 kHz的低通滤波处理本文水印提取正确率提高的最多。表明本文算法相比文献[7]算法具有更强的容忍信号处理的能力,为高清音频低通滤波后水印的提取提供保障。
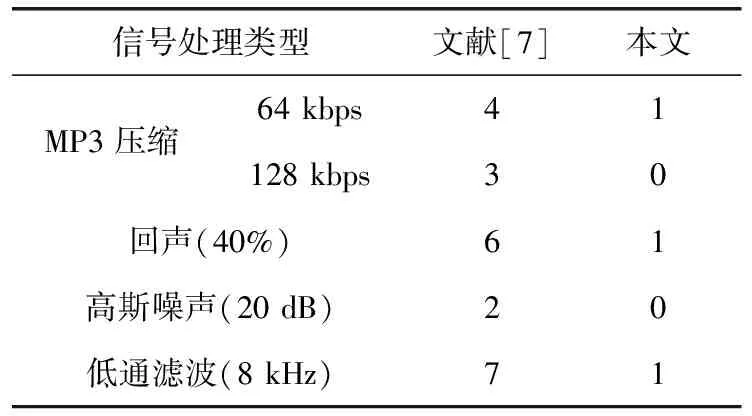
表3 本文算法和文献[7]算法在不同信号处理后水印提取的BER(%)值
3.3 恶意攻击的篡改定位
对语音信号的恶意攻击能够改变原信号的表达含义。若被攻击的内容被认为是真实的,则会对说话人以及听众带来难以估量的损失。对语音信号进行取证,并给出篡改定位结果,能够给听众以警示,减少由于语音内容被攻击而带来的损失。下面从样本库中随机选取一段语音信号(如图8所示),对该信号进行删除、插入和替换攻击,并给出相应的篡改定位结果。
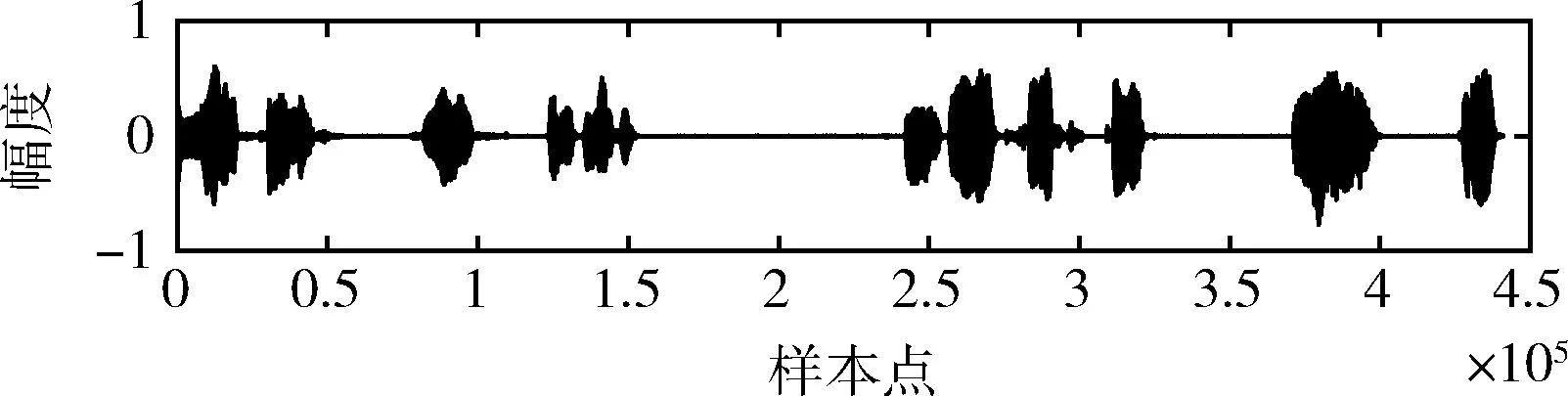
图8 含水印语音信号
(1)删除攻击
本文提到的删除攻击指的是,选择部分含水印的音频信号样本进行删除,来改变原含水印信号的表达含义,达到攻击者希望达到的目的。为了测试本文算法对删除攻击的检测能力,我们选择如图8所示的含水印信号,删除其中的部分样本实施删除攻击(这里选择含水印语音信号第110 001到第154 100个样本点之间的内容)。删除攻击的信号如图9所示。

图9 删除攻击的含水印语音信号
依据本文提出的取证算法对图9所示的经过删除攻击的音频信号进行篡改检测,步骤简述为:
步骤1 对图9所示的音频信号从第一个样本开始,取长为N的样本,作为第一帧的音频内容。
步骤2 将第一帧的内容分为2T段,计算各段的FDCR特征,并由式(7)得到每段提取的二进制水印信息。
步骤3 将提取的2T比特的水印信息分为前后两部分。①若前、后两部分的T比特的水印信息相同,则认为该帧是真实的,并由T比特的水印重构帧号;②若前、后两部分的T比特的水印信息不相同,则表明该帧的内容是被攻击的部分。对于被攻击的音频帧,由于前、后两部分T比特的水印信息不同,依据算法,该帧的帧号不能重构。所以,能重构帧号的音频帧被认为是真实的内容,不能被重构帧号的音频帧将被检测为存在攻击的内容。
根据上述步骤,对图9所示的音频信号各帧帧号重构结果如图10所示,其中TL=1对应的帧表示帧号能够被重构,TL=0的帧表示帧号不能能够被重构(TL的含义适用于插入和替换攻击的检测结果)。于是,对于删除攻击的信号,第3、第4帧的内容是被攻击的部分。
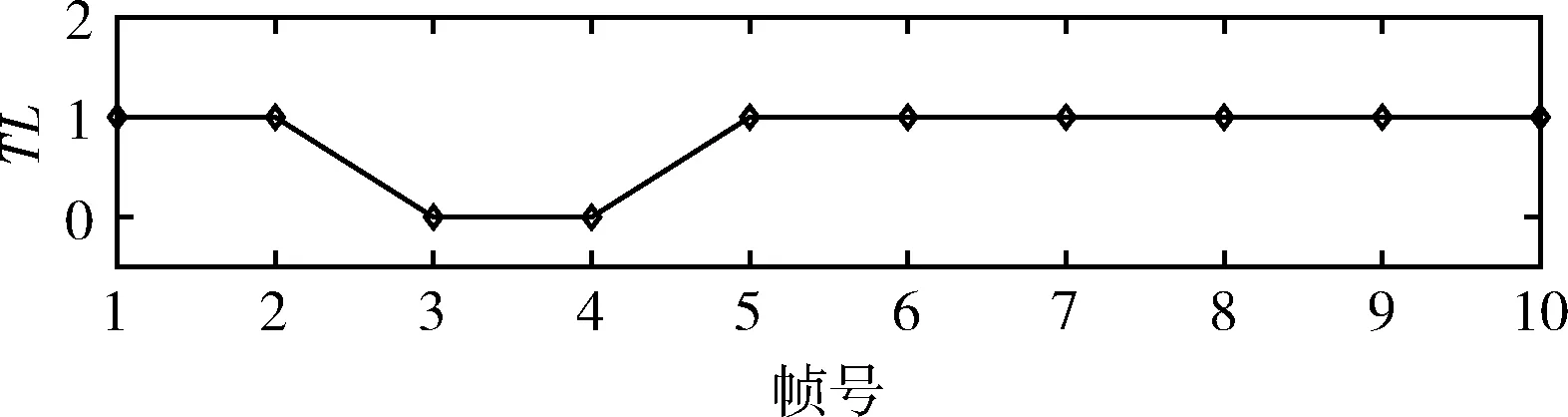
图10 对删除攻击的篡改定位结果
(2)插入攻击
本文提到的插入攻击指的是,在音频信号中插入部分样本点,来改变音频信号的表达含义,达到攻击的目的。为了测试本文算法对插入攻击的检测能力,我们选择如图8所示的含水印信号进行攻击,选取其它语音内容插入到如图8含水印信号的第270 000个样本的位置。攻击后的信号如图11所示。
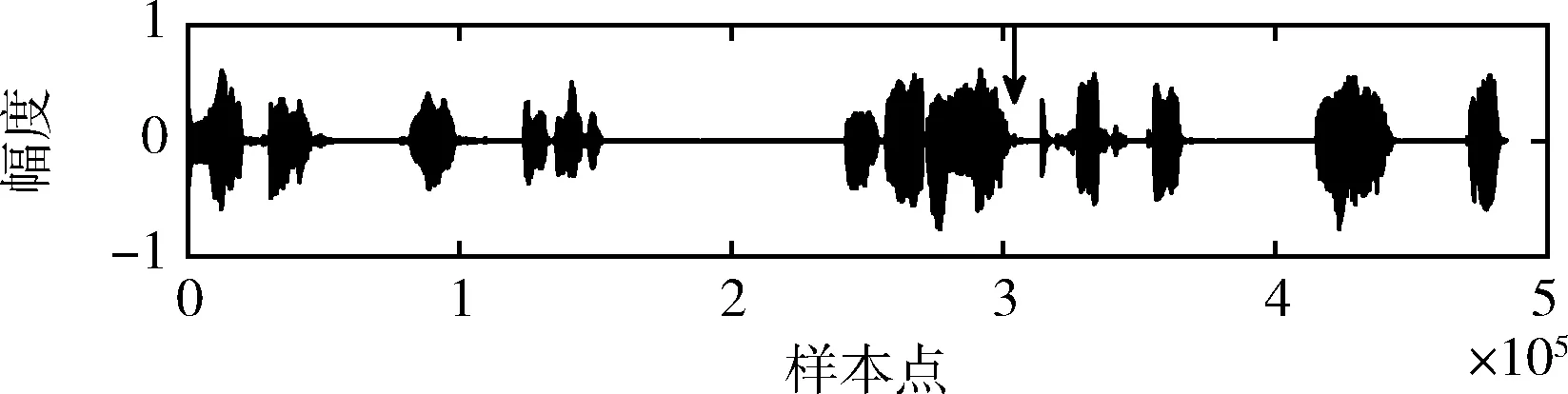
图11 插入攻击的含水印语音信号
采用和删除攻击相似的方法,对插入攻击的音频信号进行篡改检测。依据本算法,能重构帧号的音频帧为真实的内容,不能被重构帧号的内容为被攻击的部分。帧号重构结果(即篡改检测结果)如图12所示。由图12所示结果易得,图11所示的含水印信号第7、第8帧的内容是被攻击的部分。
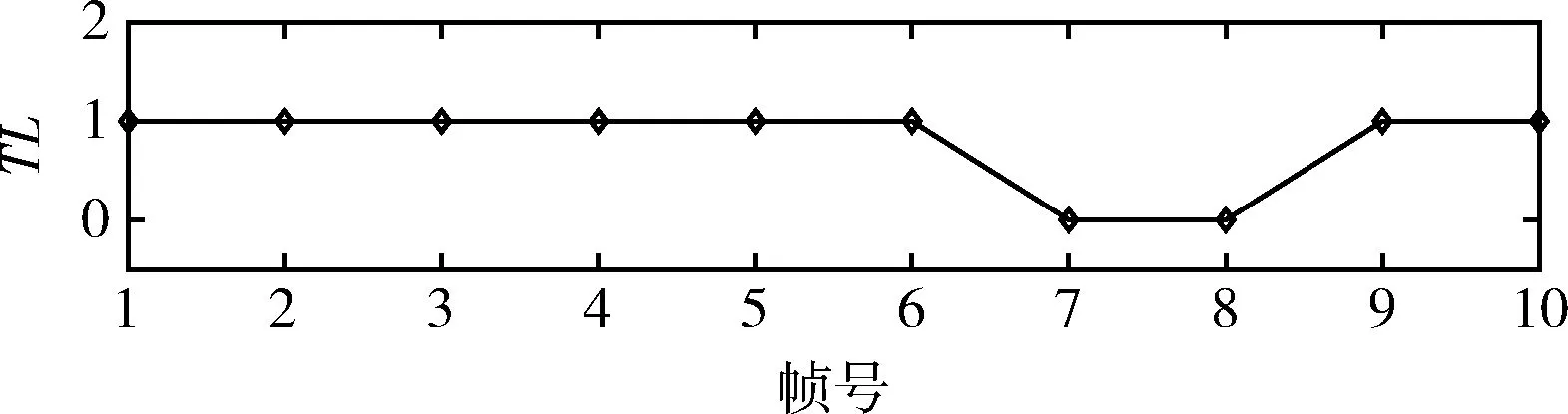
图12 对插入攻击的篡改定位结果
(3)替换攻击
本文提到的替换攻击指的是,选择要攻击的音频样本,用表达含义不同的样本来替换要攻击的内容。为了测试本文算法对替换攻击的检测能力,相似地选择如图8所示的含水印信号进行攻击,选取其它语音内容替换含水印信号第220 501个样本到第264 601个样本之间的内容。替换攻击后的内容如图13所示。
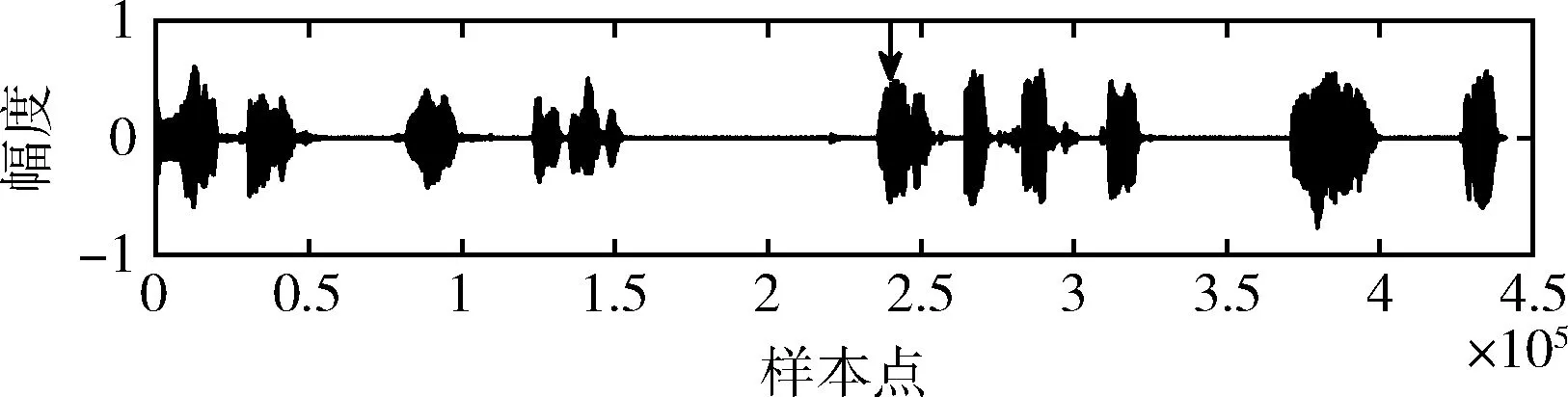
图13 替换攻击的含水印语音信号
和删除、插入攻击类似,采用相似的方法对替换攻击的音频信号进行篡改检测。能重构帧号的音频帧为真实的内容,不能被重构音频帧的内容为被攻击的部分。帧号重构结果(即篡改检测结果)如图14所示。由图14所示结果可得,第6帧的帧号不能被重构(依据TL=0的含义),故第6帧为检测到的被攻击的内容。
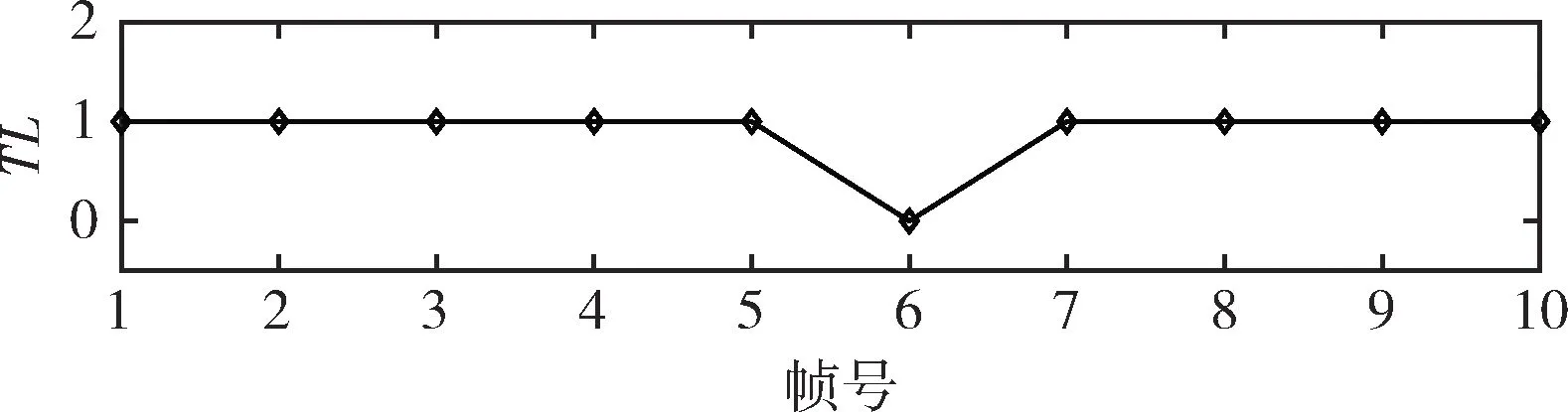
图14 对替换攻击的篡改定位结果
以上对不同攻击的取证结果可以看出,篡改定位结果和实际被攻击的位置一致。表明对于含水印的语音信号,本文算法能够验证其真伪,在此基础上,对于恶意攻击内容,文本算法能够较为精确地定位被攻击的语音帧。
3.4 安全性
对于水印系统而言,若用来嵌入水印的特征是公开的(可以轻易地被攻击者获取),则该水印系统会存在较大的安全隐患。比如,攻击者可以计算嵌入水印的特征,搜索找到表达含义不同而对应的特征和该水印段特征相同的音频段,并替换含水印的内容。因为替换后内容的特征和替换前相同,验证端可以从被攻击内容中提取准确的水印信息,致使该攻击能够逃过验证段的检测。下面用一实例来详细给出此类攻击的攻击方法,这里假设嵌入水印的特征为信号的能量。
(1)水印嵌入
假设原始音频信号为A,Ai为对A分帧后第i帧的内容,wi为要嵌入到Ai中的水印信息。常用的嵌入方法如下:
步骤1 计算信号Ai的能量,如式(10)所示
(10)
式中:Ei为计算所得能量,Ai(l)为第i段信号的第l个样本点。
步骤2 依据wi的不同,来量化能量Ei,量化后的能量记为E′i,方法如下
wi=0时
(11)
wi=1时
(12)
其中,Δ为嵌入水印选择的量化步长。
步骤3 依据能量特征和音频信号样本点的线性关系,通过缩放样本值的方法来得到含水印的信号,记为A′i,方法如式(13)所示,其中A′i(l)表示含水印第i段信号的第l个样本点
(13)
(2)攻击方法
一般情况下,含水印信号是通过公共网络传播,含水印信号A′i对攻击者而言是已知的,下面给出对A′i的攻击方法。
步骤1 攻击者由式(10)从A′i中提取能量E′i。

步骤3 攻击者选取其它的长度和A′i相同的音频段Bi,计算其能量EBi,并根据式(11)和式(12)的方法量化EBi为EB′i,然后将水印wi嵌入到音频段Bi中,得到含水印的音频段B′i。用B′i替换原含水印信号第i段A′i的内容。
由于从B′i中提取的水印和A′i中提取的水印相同,所以验证端很难发现攻击的存在。以上分析表明,基于公开特征的水印嵌入方法[8,9]存在安全隐患。
(3)本文算法抗替换攻击的能力
本文算法提出的FDCR特征,在特征获取时首先需要密钥α、λ和K。在密钥不确定的情况下,很难直接提取信号特征。文中首先将音频信号分帧,每帧分为2T段。通过量化各段的FDCR特征,将长为T的水印信息分别嵌入到前后T段信号中。提取端用同样的方法对含水印信号分帧、分段,计算水印信号各段的FDCR特征,提取每帧的长为2T的水印信息。将提取的水印信息分为两段,判断前后两段水印信息的异同来验证该帧内容的真实性。
依据水印嵌入方案,若随机选取其它内容的音频信号来攻击一帧含水印的信号,则攻击成功的可能性为1/2T。于是,本文算法抵抗替换攻击的能力R可由式(14)得到
R=1-1/2T
(14)
表4列出了本文算法和部分常见的水印嵌入方法[5,8,9]抵抗替换攻击能力的对比,其中Y表示能够抵抗替换攻击,N表示不具有抵抗替换攻击的能力。

表4 本文算法与部分水印算法安全性对比
综上实验分析结果,本文算法水印的嵌入不影响原始信号的听觉质量,具有一定的容忍信号处理的能力,对于恶意攻击能够定位被攻击的内容,同时提高了整个水印系统的安全性。
4 结束语
为了提高数字语音信号的可信度和认可度,提出了一种鲁棒的数字语音取证算法。给出了语音信号FDCR特征,实验分析了该特征对部分信号处理操作的鲁棒性和恶意攻击的脆弱性。将载体信号分帧,帧号映射为水印序列,采用量化FDCR特征的方法将水印进行嵌入。提取端通过对帧号的提取进行取证以及必要的篡改定位。实验结果验证了本文算法具有良好的不可听性,对信号处理的鲁棒性,以及对恶意攻击的篡改定位能力,提高了水印系统的安全性,为新时代数字语音信号的安全性提供了一定的技术支持。
