面向RISC-V处理器的GCC移植与优化
2021-09-15唐俊龙禹智文刘远治肖仕勋邹望辉
唐俊龙 禹智文 刘远治 肖仕勋 邹望辉
1(长沙理工大学物理与电子科学学院 湖南 长沙 410114)
2(柔性电子材料基因工程湖南省重点实验室 湖南 长沙 410114)
0 引 言
GCC(GNU Compiler Collection)是由 GNU 工程开发的编译器,支持C/C++、Java、Fortran等多种前端编程语言和x86、i386、MIPS等后端体系结构,决定了源程序翻译为目标代码的翻译效率与质量,直接影响了处理器系统的整体性能[1]。编译器是一种应用服务,应用不同要求的功能不一样,每次重新设计一套编译器非常耗时,而利用GCC前后端可扩展的特点,复用前端代码与移植GCC后端到特定体系结构的目标平台是一种省时、有效的方法。因此,GCC的移植与优化是嵌入式交叉开发的热点[2-4]。
加州大学伯克利分校开发的精简、开放、模块化开源指令集架构RISC-V,与CISC指令集相比,更适用于微型嵌入式系统。GCC为RISC-V提供后端接口,但在目标平台上运行需要针对新体系特点做相应的后端移植。机器描述是主要的后端移植方法,一种是参照与目标体系相近的体系结构,修改GCC源码得到目标机器描述文件,开发周期短但需熟知各种体系结构,要求较高[5];另一种是从零开始逐层编写机器描述,逐步递进式地移植,便于修改和调试[6]。GCC移植成功后,直接编译源码生成的可执行目标代码体积大而质量低,微型嵌入式系统内存资源有限需要高效的目标代码[7],需要优化GCC。目前广泛应用的编译优化技术有寄存器分配[8]、公共子表达式删除[9]和窥孔优化[10]。公共子表达式删除常用于前端优化,RISC-V处理器的内存访问指令简洁,使用专用的load/store指令访问内存,寄存器操作类指令的使用频率较低,窥孔优化能更大地提升RISC-V处理器的编译器性能。窥孔优化主要有冗余指令删除、指令替换、强度削弱和利用特殊指令四种方式[11-13]。文献[14]中移位替换乘法的指令替换方法减少编译运行时间10%,未优化移位操作自身空间。文献[15]的冗余指令删除方法删除重复使用的load/store指令,降低了编译运行的功耗约13%,而RISC-V处理器具有简洁的load/store访存指令,冗余指令少。文献[16]利用乘加指令的特殊指令方法提高了指令并行化程度,编译运行时间减少,而目前RISC-V处理器暂未设计乘加单元。文献[14-16] 使用静态窥孔方法,未优化编译生成目标代码体积,算法效率有待提升。
本文利用宿主机-虚拟机的模式,在Linux系统虚拟机环境下进行嵌入式交叉开发,使用机器描述的后端移植方法,参照ARM体系结构,修改GCC源码得到目标机器描述文件,移植GCC到RISC-V处理器平台,正确生成riscv-none-embed-gcc编译器。采用强度削弱的窥孔优化方法对riscv-none-embed-gcc进行优化,解决中间代码生成过程中寄存器低效使用而造成CPU计算代价高的问题,缩小目标代码体积,提高了目标代码质量。
1 GCC后端移植机制的建立
GCC包括语言前端、语言和机器无关的中间语言及机器相关的后端代码三部分,GCC基本结构如图1所示,语言与平台的加入相对独立,具有很强的可移植性。语言前端是GCC处理每种编程语言的代码,主要完成词法与语法分析、抽象语法树(AST)生成及语法树规范化(Generic),以AST为前端接口支持不用考虑机器信息的各种编程语言。中间语言(GIMPILE)是AST的中间表示形式。后端的生成器(gen)参考机器描述文件(MD)生成独立于编程语言的各种体系结构汇编代码,支持不同目标平台。GIMPILE与MD-RTL表达的机器描述都是RTL语言,高级语言到目标语言的转换过程更平缓。GCC灵活的结构能够移植到新目标平台,它的后端移植核心思想是目标机器描述及引导中间代码生成和优化机制,本文建立的后端移植机制如图2所示。MD中提取出目标机器的特点引导指令模板与GIMPILE的生成,确保GCC正确翻译。GIMPILE解析出的指令序列insn1...n与指令模板进行匹配,匹配成功的序列确定为指令输出,所有序列匹配完成后,提取指令输出生成汇编代码。描述处理器的数据和指令信息的MD文件设计是RISC-V处理器进行GCC后端移植的关键。GCC源码中,数据信息以应用二进制接口(ABI)的形式表示,指令信息以RTL模板的形式描述。修改GCC源码,描述RISC-V与其他体系结构不同的数据和指令特点,解决传统GCC源码生成的编译器编译得到的可执行程序不能在RISC-V处理器上运行的问题。
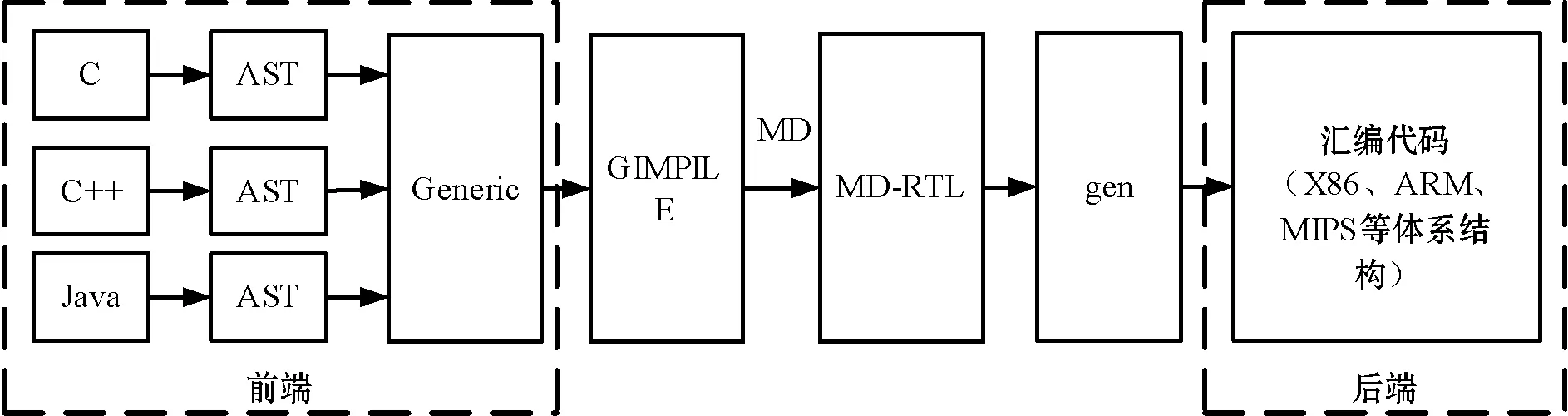
图1 GCC基本结构图
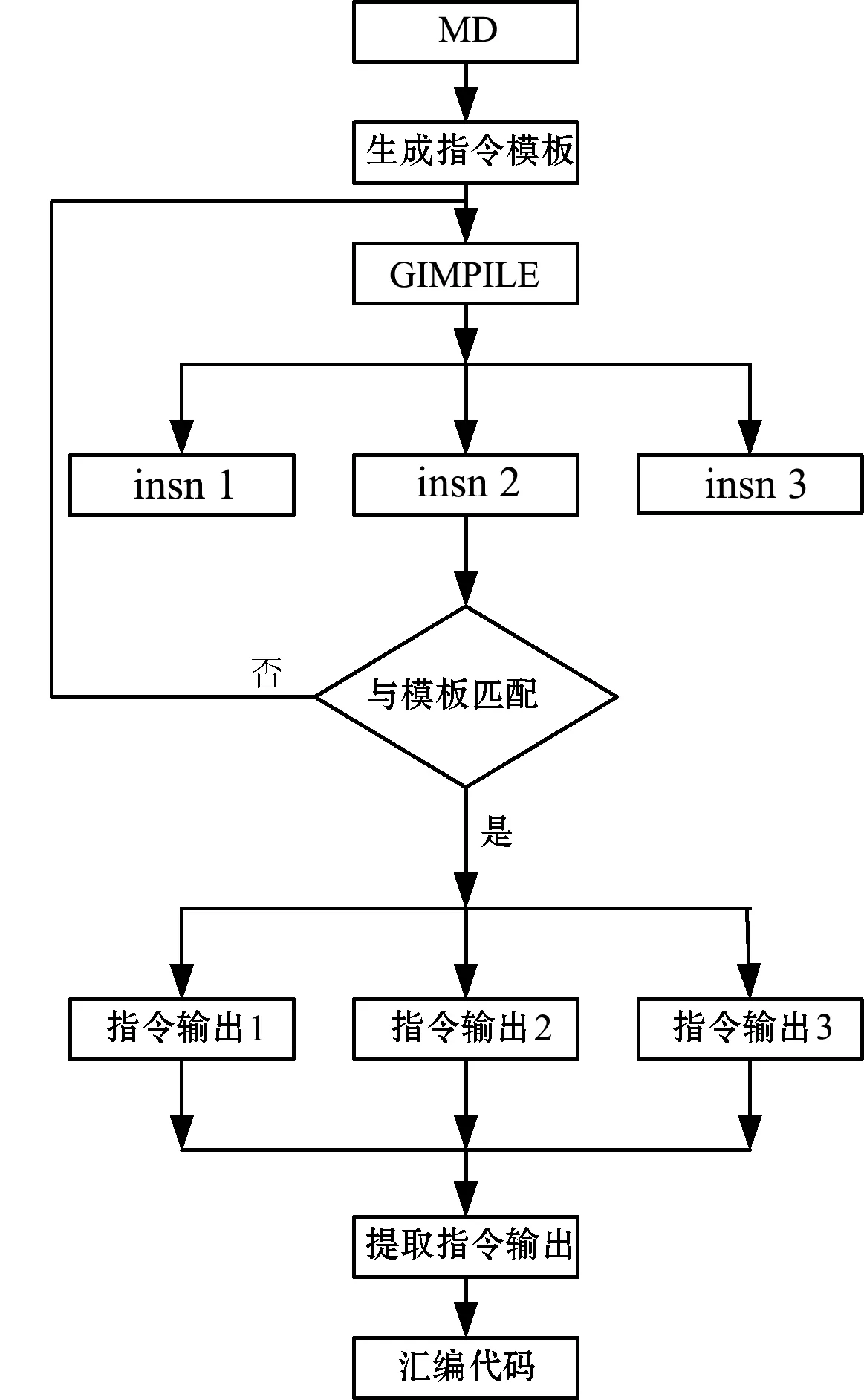
图2 GCC后端移植机制
2 GCC后端移植的实现
根据图2后端代码生成机制,以C宏和RTL语言分别描述RISC-V的ABI和指令信息特点,编写机器描述文件,在Linux系统环境下配置GCC的编译选项生成riscv-none-embed-gcc编译器,实现GCC后端移植。
2.1 机器描述文件的设计
设计机器描述文件是描述RISC-V处理器平台数据和指令信息的过程,本文定义数据存储布局、设计寄存器用法与函数栈帧和RTL指令模板,分别在riscv.h、riscv.c和riscv.md文件中实现ABI的宏定义、宏相关的函数和指令信息。
ABI包括数据的存储布局和寄存器用法与堆栈,数据的存储布局定义目标平台的存储格式、数据类型大小和对齐处理,寄存器用法与函数栈帧确定数据在栈帧空间的存储位置。
(1) 存储格式定义。通用体系结构的GCC规定值0、1分别表示小端、大端存储格式,RISC-V指令仅支持小端格式,位、字节和字大小数据的小端格式都用后缀_BIG _ ENDIAN表示,定义BITS_BIG_ENDIAN、BYTES _BIG_ ENDIAN和WORDS_BIG_ENDIAN宏值为0。
(2) 数据类型定义。本文移植的编译器为C编译器,RISC-V 基本指令集的C程序数据类型特点如表1所示。编译器移植的首要工作是根据表1在GCC源码中定义数据类型及大小,例如:短整型宏定义为#define SHORT_ TYPE_ SIZE 16;指针型宏定义为#define POINTER_SIZE(riscv_abi>=ABI_LP64 ? 64:32)。
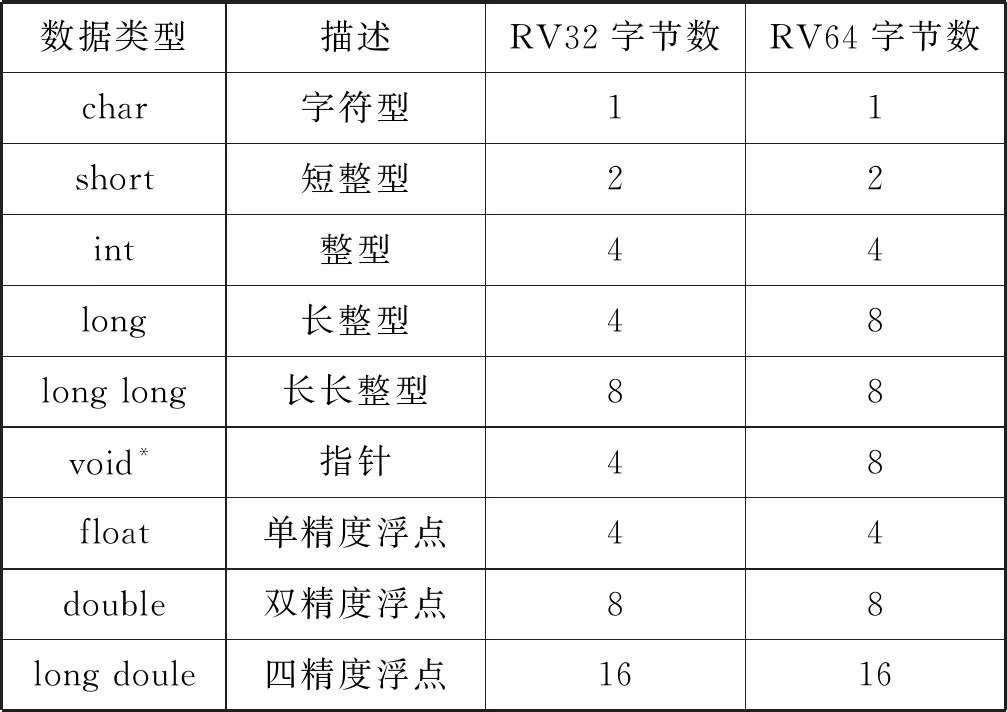
表1 RISC-V的C程序数据类型
(3) 对齐处理。数据对齐处理可以减少内存浪费,RISC-V指令中函数参数在堆栈中对齐位数应与单字的字节数保持一致,函数入口地址对齐位数中C扩展指令集为16位,其他为32位。表1中最大数据类型long double位宽为128,定义最大对齐位数为128,以防止内存对齐溢出。在riscv.h头文件中,函数参数对齐位数的宏定义为#define BYTES_PER_WORD(TARGET_RVC ? 4 : 8)和#define PARM_ BOUN DARY BITS_ PER_ WORD,函数入口地址的宏定义为#define FUNCTION_ BOUNDARY(TARGET_ RVC ? 16:32),最大对齐位数的宏定义为#define BIGGEST_ALIGNMENT 128。
(4) 寄存器用法与函数栈帧的设计。RISC-V的66个物理寄存器中有19个临时寄存器t0-t6和ft0-ft11、12个整数寄存器s0-s11及12个浮点寄存器fs0-fs11。在寄存器间传输数据能提高RISC-V处理器运算能力,寄存器用法直接关系到GCC编译器的功能正确性。RISC-V临时寄存器在调用过程中会破坏,整数寄存器和浮点寄存器在调用后保持不变,本文设计将t0-t6和ft0-ft11寄存器的值保存在调用者的栈帧中,s0-s11和fs0-fs11寄存器的值保存在被调用者的栈帧中,以保证寄存器后续的存储使用,函数栈帧布局如图3所示。栈帧指针指向栈底,硬件栈帧指针指向被调用函数开始的地址,帧指针指向栈顶,各指针的初始化值根据图3的布局位置确定,定义栈指针、硬件栈帧指针和帧指针的宏STACK_POINTER_REGNUM、HARD_FRAME_POINTER_ REGNUM和 FRAME _POINTER_REGNUM的值分别为2、8和65。栈帧空间创建、寄存器保存操作在riscv.c文件中分别由riscv_compute_frame_info()、riscv_save_restore _fn()函数实现,函数栈帧的设计流程如图4所示。

图3 RISC-V函数栈帧布局
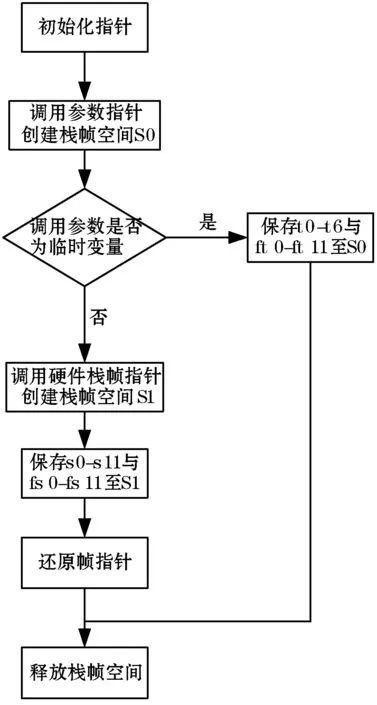
图4 函数栈帧设计流程
指令信息包括指令的机器模式、指令名称、属性、常量和约束,不同体系结构的指令信息差异较大,本文根据目标平台的指令信息,在MD文件中使用RTL语言设计加法、乘法、除法、逻辑和跳转等指令模板。图5为指令模板中的加法指令模板,表示操作数1与操作数2相加,计算结果保存在操作数0所在寄存器中,“register_operand”类型的操作数1与“arith”类型的操作数2满足64位目标机器条件,按照RTL模板汇编输出“add%i2w %0,%1,%2”,否则输出“add%i2 %0,%1,%2”。其中:“addsi3”为指令名称;“SI”为机器模式;“match_opeand”用于描述该操作数的匹配条件;“register_operand”和“arith_operand”表示操作类型。
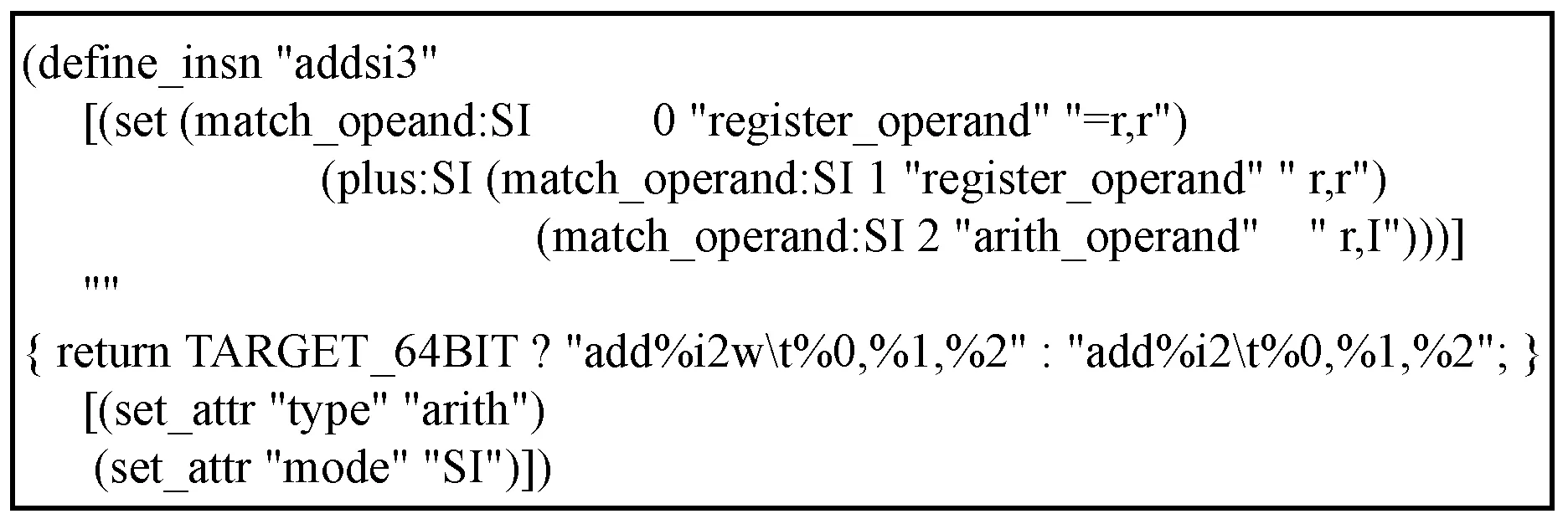
图5 RISC-V加法指令模板
2.2 riscv-none-embed-gcc编译器的生成
RISC-V指令集包括基本I整数集以及A、M、F、D、C等扩展指令集,本文根据所移植编译器为32位版本的需求,选择M、A、D、F指令集,确定参数组合RV32IMADF。机器描述文件建立后,加入RISC-V处理器的CPU类型(cpu_type=riscv)至config.sub文件中的riscv*)模块,添加机器型号(Basic _machine=riscv)至config.gcc文件作为GCC的识别端口。在Linux系统下配置abi和arch的编译参数选项分别为ilp32 和rv32imadf,编译安装移植后的GCC源码,生成riscv-none-embed-gcc编译器。
3 强度削弱的窥孔优化实现
许多数据密集型应用程序中广泛使用乘法和数据移位操作,计算量大且直接编译生成的目标代码体积大。部分乘法操作可以用移位的方式替代,同时移位操作自身也存在优化的可能。本文基于RISC-V处理器简洁的内存读写和跳转指令的特点,采用强度削弱的窥孔优化方法对数据密集型应用程序进行强度削弱,挖掘移位操作的优化空间,以移位化简的方式简化RTL中间代码级的指令,利用计算代价较小的指令替换代价较大的指令,减少指令执行时间和寄存器资源占用,优化编译器,减小目标代码体积,节省处理器存储空间。
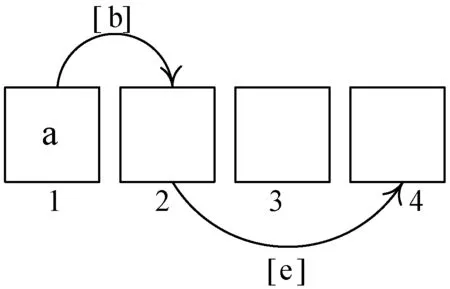
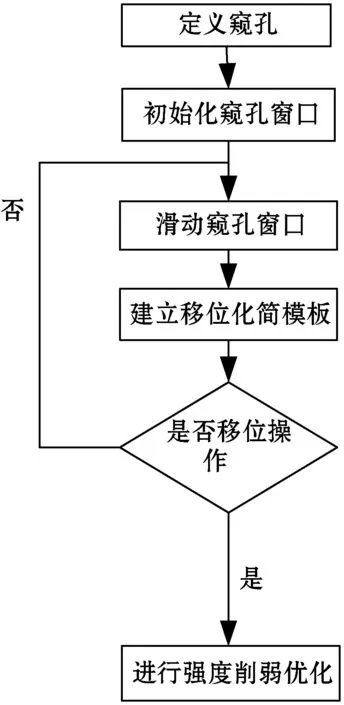
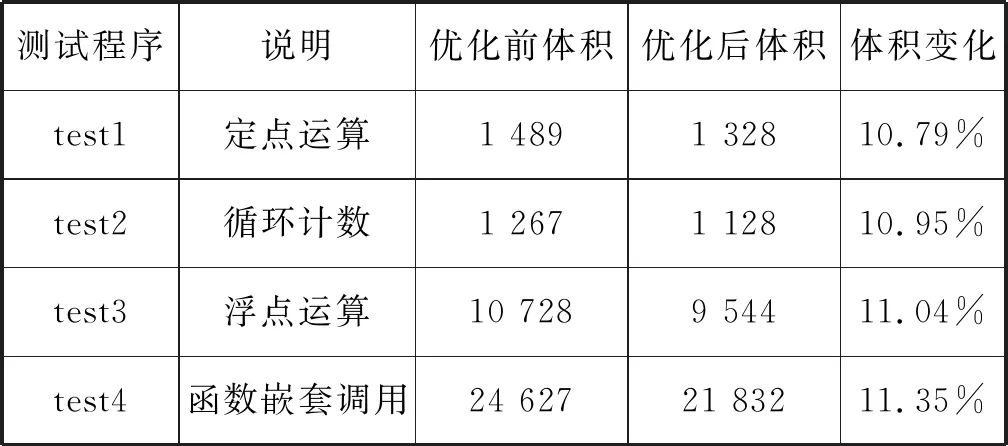
图6、图7是优化前后操作数a左移常数位(a< 图6 优化前移位操作 图7 强度削弱的窥孔优化设计 图6为ARM体系结构中操作数a经三次移位实现左移const位的一个过程。CPU先从内存中读取操作数a,写入寄存器1。运算单元依次从寄存器1、2、3读写数据并移动[b]、[c]、[d] 位,结果写入寄存器4,读寄存器4中的值写回内存,完成操作数a左移const位的操作。CPU进行了一次内存读和写,三次寄存器读和写操作,占用4个寄存器资源,使用5条指令,计算代价为10。图7为本文实现强度削弱的窥孔优化设计,确保移位数为正数 [e]=[c]-[d]([c]>[d]),保证GCC中寄存器3与寄存器4的识别标号(REGNO)一致,运算单元依次从寄存器1、2读写数据并移动[b]、[e]位,结果写入寄存器4。强度削弱后三次移位操作简化为两次移位操作,减少了一次寄存器读写、一个寄存器和一条指令,计算代价减少2。图8为强度削弱程序设计流程,代码实现中以define_ peep hole2定义窥孔优化。 图8 强度削弱程序设计流程 由于语言前端的多样性和目标平台结构的特殊性,国内外目前尚无标准、系统、通用的编译器测试方法。C语言具有自身的属性,C编译器的正确性测试主要是C语言中语法、语义的符合性的宽度测试与语法、语义间任意复杂的组合性的深度测试。宽度测试确保编译器对源程序中各类语法和语义都无遗漏地进行测试;深度测试保证编译器能正确处理语法和语义的嵌套、组合问题[18]。本文在PC机Win10 64位系统(宿主机)和Ubuntu16.04 64位系统(虚拟机)实验环境下结合设计的宽度测试用例、深度测试用例和完整的C程序验证编译器功能的正确性,并采用GCC内专用测试程序验证编译器功能的通用性;利用GCC内定点运算、浮点运算、循环计数和函数嵌套四种程序测试编译器的优化效果。 C89标准的语义约束繁多,本文宽度测试仅以下标数组和结构体语义约束为例,下标数组约束中数组的一个表达式类型应为指向对象的指针类型;结构体约束中结构体的“—>”算符的第一操作数类型应为指向限定或非限定结构的指针。测试用例如表2所示,每种约束设计一组正确和错误用例进行对比,数组和结构体测试的错误用例中,数组元素类型为常整型,“—>”算符的第一操作数p的类型是指向int型变量的指针,都不符合语义约束。编译器能通过正确用例,不能通过错误用例,但能产生正确的出错警告。表3为宽度测试结果,编译器功能正确。 表2 宽度测试用例 表3 宽度测试结果 深度测试结果如图9所示,L3段通过jmp指令跳转至L4段,对应源程序中最外层循环进入第二层循环;L4段通过jle指令跳转至L6段,对应源程序中第二层循环进入最内层循环;L6段中三次je指令跳转至L5段,对应源程序中if条件判断语句在三层循环中的访问;L2段执行完后以leave指令结束,对应源程序中printf输出函数执行完后跳出循环体。循环嵌套的深度测试验证了编译器翻译出汇编代码的正确性,无出错警告。 C源程序循环部分代码: for(hund=1;hund<5;hund++) { for(ten=1;ten<5;ten++) {for(single=1;single<5;single++) {if(hund!=ten&&hund!=single&&single!=ten) {printf("%d,%d,%d
",hund,ten,single); } } } }编译生成的部分汇编代码:.LFB0: ........ jmp .L3.L6: movl -8(%rbp), %eax cmpl -4(%rbp), %eax je .L5 movl -8(%rbp), %eax cmpl -12(%rbp), %eax je .L5 movl -12(%rbp), %eax cmpl -4(%rbp), %eax je .L5.L5: addl 1, -12(%rbp).L4: cmpl 4, -12(%rbp) jle .L6 addl 1, -4(%rbp).L3: movl 5, -4(%rbp) movl 1, -12(%rbp) jmp .L4.L2: movl 0, %eax leave .cfi_def_cfa 7, 8 图9 深度测试结果 利用objdump[19]反汇编工具查看C程序编译后生成的汇编代码是否满足汇编语法规则,是否具有C源程序的功能,如图10所示。对比C程序与汇编代码,编译器成功按照RTL模板逐条翻译出目标代码,编译器功能正确。 C程序:#include 图10 移位程序编译结果 利用DejaGnu[20]工具对i386、ia64等平台中24 538个专用测试程序进行了编译,测试结果预期通过数expected passes为24 538,预期失败数unexpected failures为0,未测试例程untested testcases为5,移植后的GCC编译器成功翻译所有专用测试程序,具有预处理、错误警告等通用功能。 编译生成的汇编代码体积是衡量编译器性能的重要指标之一。本文采用DejaGnu开源测试工具,关闭宿主机上虚拟机以外的服务进程,保证riscv-none-embed-gcc优化前后的测试环境一致,排除PC主机进程对实验结果的影响。利用优化前后的riscv-none-embed-gcc测试GCC源码内四种移位运算程序test1- 4,记录各自生成的汇编代码体积,并统计体积变化。riscv-none-embed-gcc在强度削弱窥孔优化前后,生成的汇编代码体积(字节为单位)如表4所示,四种目标代码体积缩小约11%;浮点运算程序存储内存较大,优化程度好于定点运算程序;多次调用窥孔优化后函数嵌套调用程序效果突出。 表4 汇编代码体积测试 嵌入式微处理器采用开源可扩展的RISC-V指令集,设计灵活简洁。处理器、交叉编译器和操作系统构成嵌入式交叉开发完整体系,不同的处理构需要不同的交叉编译器。最大化RISC-V处理器在Linux系统下的性能,传统的GCC需要移植与优化。本文分析了GCC的基本结构,建立了机器描述引导目标代码生成的GCC后端移植机制,完成了RISC-V体系结构数据与指令信息的机器描述,实现了GCC的移植,生成了riscv-none-embed-gcc编译器并进行优化。利用objdump反汇编工具验证了riscv-none-embed-gcc的正确性与通用功能。选用GCC源码内四种数据密集型应用程序,利用DejaGnu工具测试了优化效果,汇编代码体积缩小约11%。文中编译器的移植与优化方法节省了微型嵌入式系统的资源,适用于RISC-V处理器面向数据密集型的应用和RISC-V编译工具链的开发与设计。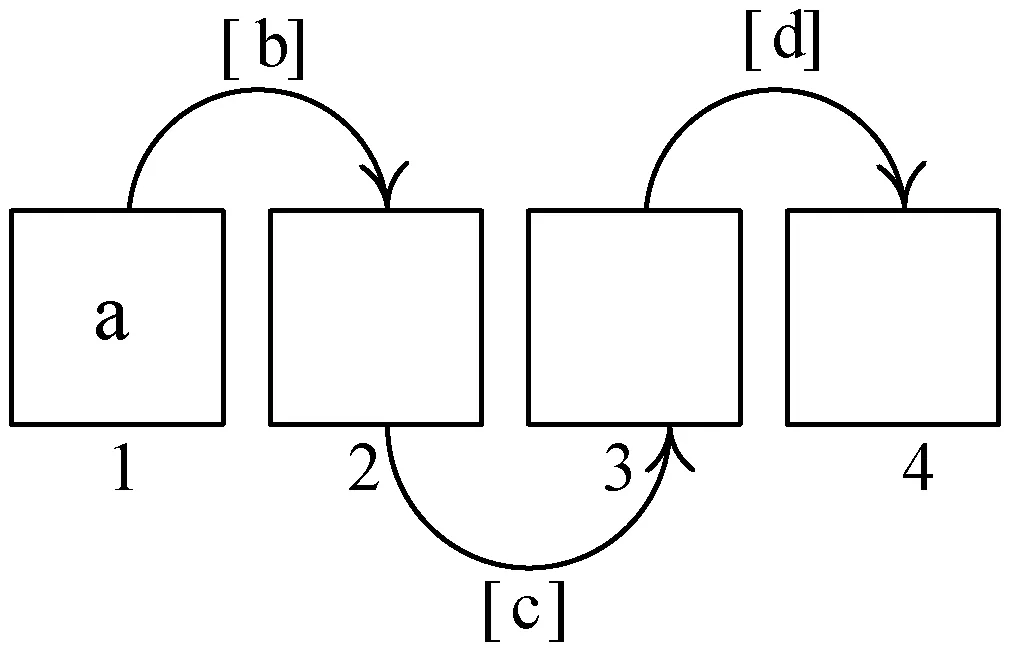
4 移植验证与优化测试
4.1 编译器功能的验证




4.2 窥孔优化效果的测试
5 结 语
