一种轻量级的卷积神经网络的行人检测方法
2021-09-15熊寿禹陶青川戴亚峰
熊寿禹 陶青川 戴亚峰
(四川大学电子信息学院 四川 成都 610065)
0 引 言
社会的快速发展和城市的高度建设,给社会、城市的安全管理带来了难题。传统的视频监控系统将前端视频信息实时传送至中心端,呈现在显示屏上,再通过人工来对视频进行内容分析、监控警报。由于城市的建设,安防监控区域的不断扩大、摄像头的数目日益增长,通过人工进行视频监管成本急剧升高,导致实时监控报警得到不到保障。因此采用智能分析系统对监控视频进行实时、有效、稳定的监控具有重大意义[1]。
行人检测是视频智能监控的关键应用领域之一。由于人体各部分有极高的自由度,做出不同动作时,人体姿态会发生较大变化。其次,由于行人身上所穿衣物款式、颜色以及帽子、挎包等装饰品的不同,使人体目标的外观有着极大的差异。针对这些问题,前人做出了不同的尝试:在特征提取方面,提出了Haar-like特征[2]、梯度直方图(Histogram of Oriented Gradient,HOG)[3]特征等;在分类器选择方面,具有代表性的有支持向量机(Support Vector Machine,SVM)[4]、随机森林(Random Forest,RF)[5]等。但这些方法均存在着泛化能力差、需要手工设计提取特征等缺点,在实际应用中效果较差[6]。
如今,人工智能发展迅速,在机器视觉、语音识别以及自然语言处理等方面获得了显著效果。深度学习作为人工智能的重要分支之一,在计算机视觉中的目标检测方面有着重大突破[7]。深度学习使用卷积神经网络来对目标进行特征提取,再利用提取的特征信息,对图像中的目标进行定位与分类[8]。卷积神经网络模型的准确率与模型堆叠的层数以及每一层网络的宽度成正比。由于卷积神经网络复杂度过大,导致卷积神经网络在前端部署时受到嵌入式设备计算速度、计算能力、内存空间诸多方面的限制。
本文将前端嵌入式与人工智能相结合,将智能分析系统由中心端移至前端“边缘”设备中,极大减小了中心端对多路视频信号的计算压力;使用深度学习方法来对行人进行检测定位,代替传统方法所使用的HOG特征提取器加SVM分类器所结合的方法,改善了在行人在较大形变,与背景较为复杂的环境下准确率低、稳定性差的问题;提出一种轻量级目标检测网络框架,减少大量的神经网络参数个数,降低了卷积神经网络对前端嵌入式设备计算能力、内存空间的需求[9]。
1 相关知识
1.1 基于卷积神经网络的目标检测方法
文献[10]提出了YOLO网络结构,该网络结构将物体检测作为一个回归问题进行求解,输入图像经过一次处理,便能得到图像中所有对象的位置和其所属类别及相应的置信度,检测速度可达到45帧/s,使得实时检测成为可能。但YOLO的mAP仅有63.4%[10],存在着检测精度较低以及小目标检测效果较差的问题。
文献[11]提出SSD网络结构,该网络结合了YOLO的回归思想以及Faster RCNN的anchor机制。与YOLO算法不同,SSD算法没有使用完整的特征图的信息来回归所有位置信息,而是使用了大量的3×3卷积核计算小区域特征来回归各个检测框的坐标信息,提高了定位的准确性。SSD使用了5个大小不同的卷积层来对尺寸不同的物体进行检测,在不同的特征图上使用长宽比不同的anchor,以适应特征图不同的分辨率,最终达到了72.1%的mAP和58帧/s的速度[11]。但是SSD网络框架的参数个数依旧较多,将其移植进前端嵌入式设备还存在较大差距。
文献[12]针对移动端和嵌入式深度学习网络提出一类称为MobileNets的高效模型。MobileNets模型基于深度可分解的卷积,它可以将标准卷积分解成一个深度卷积和一个点卷积(1×1卷积核),这种分解可以有效减少参数量,降低计算量[12]。SSD结合深度可分解卷积得到Mobile-SSD,该网络在SSD的基础上将网络权值减小了90%,计算速度也大大提升。但在条件较为苛刻的嵌入式前端,该网络依旧很难达到实时检测的效果。
1.2 深度残差网络
对于简单堆叠的卷积神经网络,由于网络的不断加深,梯度消失问题会越来越严重,导致网络很难收敛甚至无法收敛。针对这一问题文献[13]提出深度残差网络(Deep Residual Network, Resnet),该模型更容易优化,且性能提升明显[14]。
深度残差网络的基本结构由图1(a)表示,设最优映射为H(x)=x,而残差网络的映射关系为H(x)=F(x)+x,残差网络将拟合目标由H(x)=x转化为F(x)=0[7]。为了进一步减少网络参数以及加快训练的收敛速度,本文提出一种瓶颈残差块的结构块来代替常规的残差块。如图1(b)所示:先通过1×1的卷积来巧妙地缩减feature map(特征图)维度从而使得3×3卷积计算量降低,再通过1×1的卷积将维度提升到与输入一致。
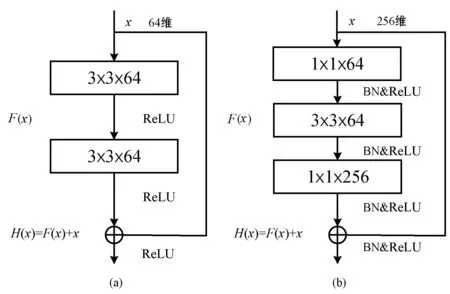
图1 残差网络结构
1.3 SSD目标检测框架
如图2所示,SSD算法特征提出采用VGG16框架,并将VGG16的fc6、fc7层使用两个卷积层来代替。SSD采用了特征金字塔结构进行检测,即检测时利用了多个大小不同的特征图,在多个特征图上沿用Faster RCNN中的anchor机制,大量使用先验框来提升识别准确率,后续通过Softmax进行目标分类和先验框回归获得真实目标的位置。
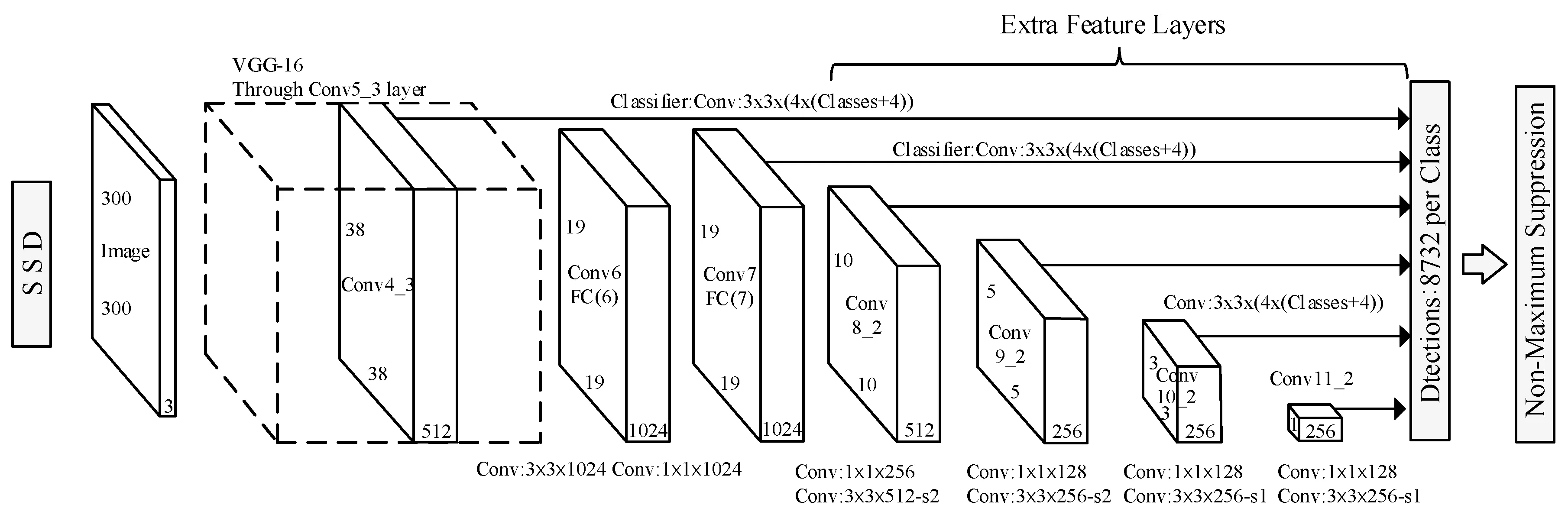
图2 SSD网络结构

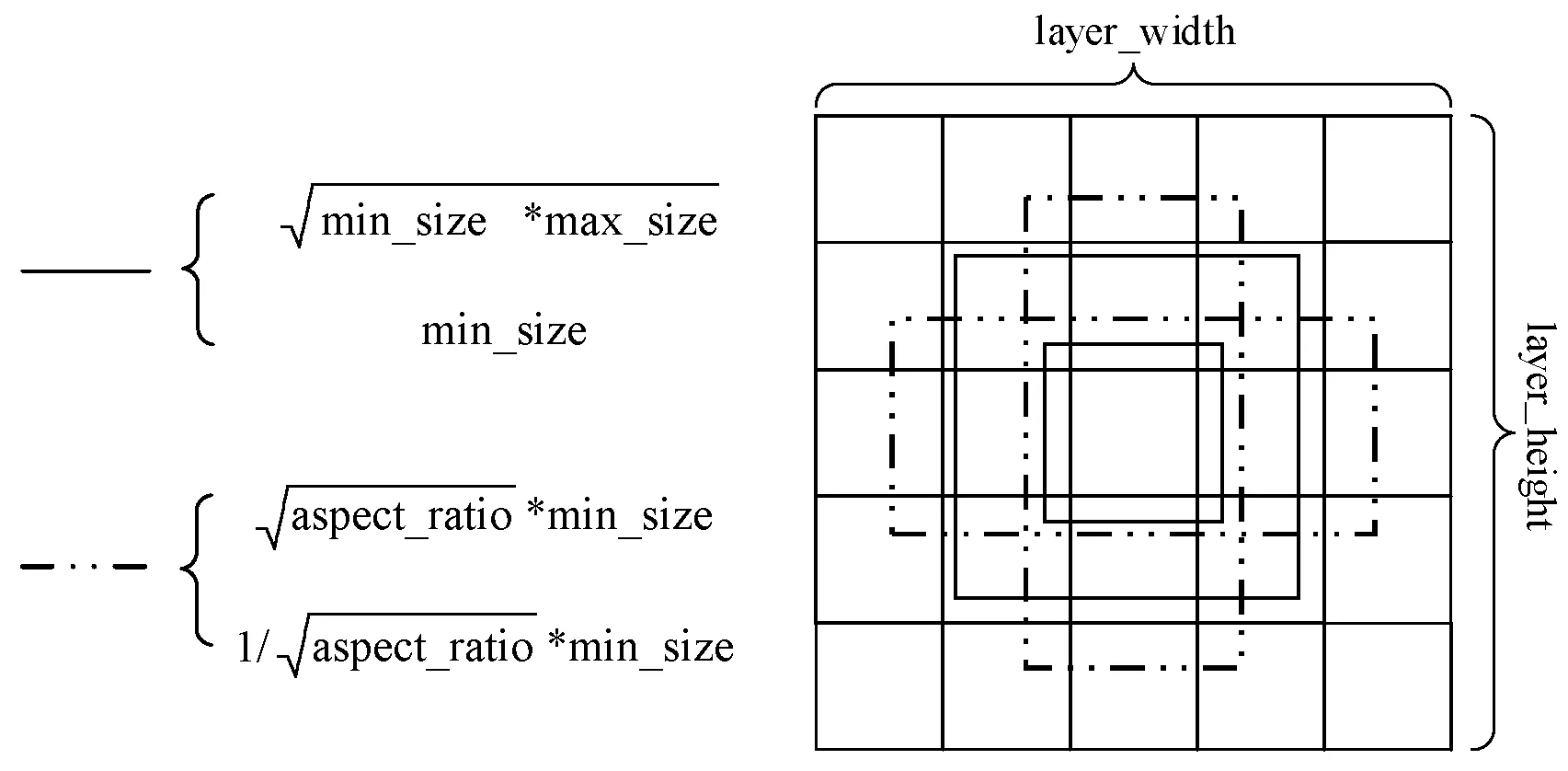
图3 SSD候选框选取
2 轻量级卷积神经网络行人检测算法
正如上述所讨论的:传统HOG+SVM算法准确率较低、稳定性不高;基于深度学习的YOLO算法,准确率较低、计算量过大、权值参数过多,不适用于前端嵌入式设备的移植;SSD目标检测方法,也存在着计算量过大、权值参数过多的问题;Mobile-SSD虽然将权值进一步的缩减,但对于前端视频监控设备所能接受的性能指标依旧有着较大差距。因此本文提出一种可移植至前端嵌入式的轻量级网络,该网络在较低的准确率变化范围内,提高16~132倍不等的检测速度,并降低了93%以上的存储空间,能更好地结合人工智能与前端嵌入式设备。
2.1 预测层与候选框尺寸的选取
本文沿用SSD多尺度检测以及使用不同形状候选框来以针对目标长宽比例的不确定性的思想。SSD中预测层数与候选框个数的选取是通过经验值进行人为选取,针对行人检测问题,本文提取PASCAL VOC数据集中所有行人样本共6 095幅图片,包含13 256个行人样本,并对行人长宽比例以及行人所占图片比例进行统计。由图4可知,行人目标宽长比集中分布在0.2~0.5范围内,则本文每个预测层aspect_ratio参数设置为0.3、0.4,并取消宽大于长的anchor,最终选取6 920个候选框。具体结构如图5所示。
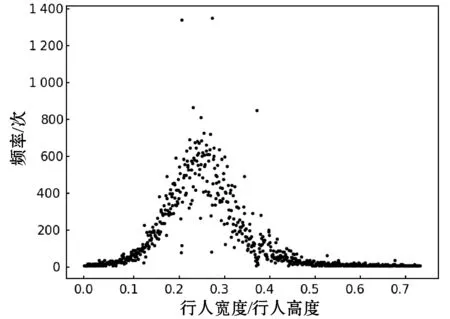
图4 行人长宽比例分布
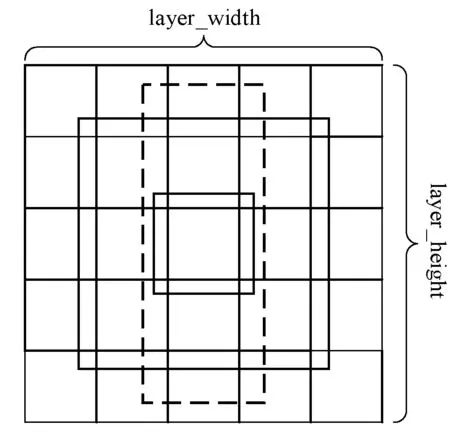
图5 本文网络候选框选取
由图6可知,行人所占原始图像比例集中分布在0~0.1范围内。特征图的大小决定了每个特征点的感受野范围,也影响了目标检测能检测目标的大小的能力。因此,本文分别将38×38、19×19、10×10、5×5四种不同尺寸特征图作为目标检测与识别分支网络的输入,计算目标的位置信息与类别信息。
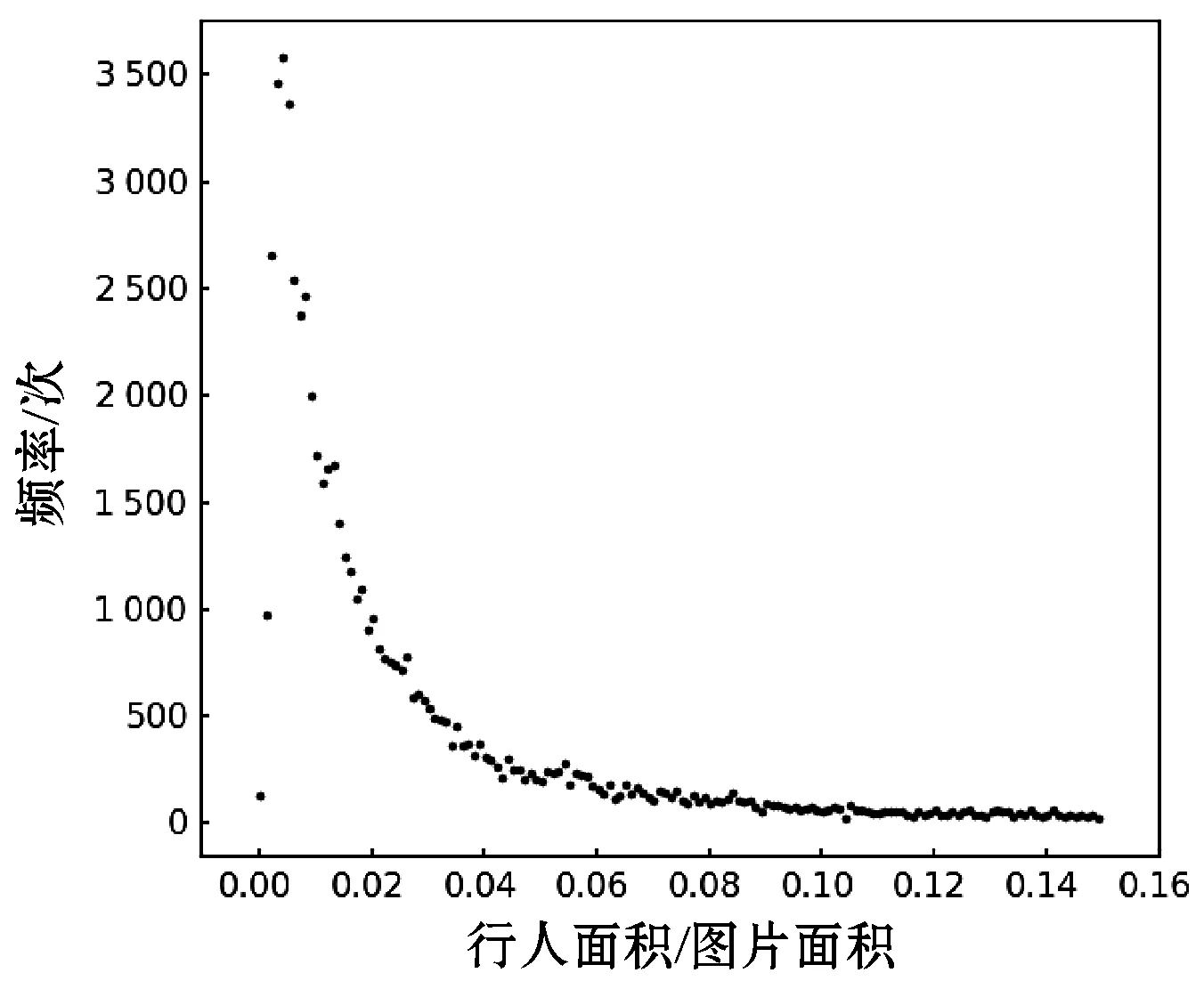
图6 行人占图片大小比例分布
2.2 网络结构的设计
SSD与Mobile-SSD目标检测网络框架中特征提取框架权值占总共权值比例较大。由于这类目标检测算法大多用于自然场景下的多目标检测,故特征提取器中使用的卷积核个数较多。但对于行人检测单类目标检测的特征提取,该特征提取器过于冗余复杂。对于特征提取器后半部分,SSD与Mobile-SSD均采用直筒形卷积,即先使用1×1卷积进行降维再使用3×3卷积进行计算,减少了3×3卷积的计算量。本文采用瓶颈残差网络代替其特征提取部分,将卷积核通道数进行了相应的裁剪,将直筒形结构替换为残差结构。通过减小卷积核个数以达到加快计算速度的目的。在原始的瓶颈残差块的基础上,本文在主干网络中额外添加一层3×3的卷积层,如图7中ResnetBlock2的conv3所示。通过增加卷积层的个数,一定程度上改善了网络宽度减小带来的检测精度下降的问题。本文在ResnetBlock2中conv3层步长设置为2,替换原始网络中通过池化进行下采样的效果。将步长设置为2能够一定程度上减少计算量,但这也带来了残差网络两路分支的输出特征图大小不匹配的问题。为了解决这一问题,本文将残差网络分支中加入了池化操作,将输入特征图进行下采样,保证了最终叠加的特征图大小一致。具体结构设计如图7所示。

图7 本文网络结构
2.3 损失函数的定义
本文网络通过端到端训练实现行人检测,不仅需要预测行人的位置信息,还需要预测候选框中行人的置信度。模型的损失函数分为置信度损失Loss(conf)与定位损失Loss(loc)两部分,损失函数L(x,c,l,g)可表示为:
(1)
式中:N为默认候选框个数,本文网络为6 920;α为概率损失与位置损失比例因子,本文网络设置为1。位置损失定义为:
(2)
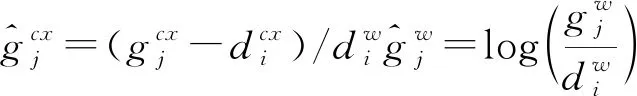
(3)
(4)

置信度损失可表示为:
(5)
(6)
(7)

2.4 BN(Batch Normalization)层的合并
在深度神经网络训练过程中,一般会在卷积层后添加BN层,BN层将数据归一化之后,能够有效地防止梯度消失和梯度爆炸的问题,并且能够加速网络的收敛,很好地控制过拟合现象[14]。BN层输出如下:
(8)
式中:conv为卷积层输出;mean为均值;var为方差;γ为缩放因子;β为偏移。mean、var、y、β均为训练参数,在前向推理时为常数。
但BN操作在进行前向推理时,会带来额外的计算量,对前向传播速度有一定的影响。本文网络中采用了大量的BN操作,在进行前向推理前,将BN层与卷积层进行合并,使得前向推理时不需要再进行BN层的计算,提高了前向推理的速度。卷积层输出如式(9),x为输入特征图,w为权值,b为偏移量。将式(8)代入式(9)中得到式(10),由式(10)与式(8)对比可得合并BN层之后的卷积权值wnew与偏移bnew为:
conv=x×w+b
(9)
(10)
(11)
3 方法验证与实验对比
3.1 实验环境
本实验所使用的平台包括本地计算机以及实际应用的前端嵌入式开发板,其基本配置如下:
本地计算机:处理器为英特尔酷睿 I5-7400;CPU频率为 3.0 GHz;内存8 GB;GPU为 NVIDIA GeForce GTX1080 Ti,显存11 GB;操作系统为ubuntu16.04。
嵌入式开发板:主板AIO-3399J;芯片RK3399;处理器为ARM Cortex-A72(双核)及Cortex-A53(四核)主频2.0 GHz,内存2 GB;操作系统为ubuntu16.04。
3.2 行人检测模型评价方法
本文使用误检率(Miss Rate,MR)与平均漏检率(False Positive Per Image,FPPI)作为评判指标,来对行人检测网络框架的有效性进行对比验证。MR、FPPI越低,表明网络框架性能更优,漏检率和平均误检率计算方法分别如下:
式中:FN(False Negative) 表示实际为行人,被判定非行人的个数;TP(True Positive) 表示实际为行人,被判定行人的个数;FP(False Positive) 表示实际非行人,被判定行人的个数;Ntest_data表示测试集图片张数。
PASCAL VOC数据集作为知名目标数据集[16],共有33 043幅图片,其中包括20种目标。本文从中挑选出所有包含行人的样本图片共8 102幅,并对图片中目标进行标注。INRIA行人数据集是目前被应用最多的公开数据集[3],其场景种类多样;TUD行人数据库包含手持摄像机与车载摄像机拍摄行人,具有很好的场景特征;ETH行人数据库作为基于双目视觉的行人数据库[17],能够有效地代表以行人角度的视角。本文使用样本数较多的VOC数据集进行特征提取网络的预训练,将预训练得到的权值进行迁移学习。由于公开的行人数据集对于行人遮挡以及非站立姿势的目标均未进行标注,本文重新对行人样本进行标注。如图8所示,左边为原有的数据集标注结果,右边是本文将小目标、遮挡目标、非站立目标添加后进行标注的结果。在此基础上,使用不同的行人检测样本集进行再次的训练,并与其他行人检测算法进行准确率的对比。本文将算法移植至瑞芯微公司旗下的RK3399核心开发板中进行速度测试,对算法在嵌入式开发板中的实际应用效果进行对比分析。

图8 原始样本与重新标注后样本
3.3 实验结果与分析
训练的实验参数设置如下:批大小设置为64,最大迭代步数设置为150 000。识别部分的学习率为0.01,权重衰减设置为0.001。采用开源深度学习框架caffe作为网络的训练平台。如图9所示,网络经过20 000次迭代,损失趋于稳定,根据验证集选取第29 800次迭代作为最终权重模型。
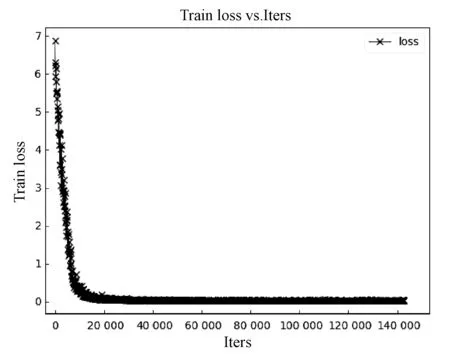
图9 网络训练损失图
为了验证本文网络的准确率与实时性,本文在INRIA、TUD、ETH三种公开行人检测数据集上,分别从MR、FPPI、参数量、计算量、计算速度5种评判标准对比了HOG+SVM 、YOLO、SSD、Mobile-SSD以及本文网络的优劣性。具体实验结果如表1-表2所示。

表1 行人算法检测速度对比

表2 行人算法检测率对比(%)
本文将算法统一移植至AIO-3399J嵌入式开发平台进行检测速度测试。由表1可看出:本文相较于YOLO、SSD、Mobile-SSD参数分别减少了99.4%、98.6%、93.8%;在嵌入式开发平台上,本文所搭建的网络框架的检测速度达到每幅图片67 ms;将网络中的BN层进行合并后,速度进一步提升,达到62 ms/幅。相较于以往基于神经网络的行人检测算法,速度提升了16~132倍不等。由表1可以看出:由于本文在训练样本中添加了大量的小目标与遮挡目标,导致HOG+SVM算法MR、FPPI较高,也证明HOG+SVM算法在实际应用中存在着鲁棒性差、不可靠等问题;由于YOLO对于小目标检测的效果不佳,使得该算法的MR也略高于其他算法;本文网络继承SSD中使用多尺度特征图做目标检测的思想,对于多尺度行人的检测明显优于YOLO与HOG+SVM;本文网络MR、FPPI略高于SSD、Mobile-SSD。由于本文主要工作是基于嵌入式平台进行算法开发,考虑到嵌入式平台与算法相结合,本文算法具有更大的优势,能够在准确率下降不明显的情况下,提升算法的计算速度,大大降低了对嵌入式开发板内存空间,计算能力的要求。
4 结 语
行人检测在前端智能设备监控中有巨大的应用价值,本文提出一种能够部署于嵌入式设备中的轻量级神经网络行人检测方法。本文通过聚类分析得到行人目标长宽比例,以此重新设计候选框尺寸比例,加强了对行人定位的效果,也一定程度上减少了神经网络的参数与计算量;另外,本文提出一种轻量级神经网络框架,该框架参数量小、计算量小,使基于深度学的目标检测算法在嵌入式设备计算速度大大提升。实验结果表明:通过在不同的样本集中测试,本文算法MR、FPPI指标均低于HOG+SVM与YOLO算法,略高于SSD与Mobile-SSD算法,但单幅图片检测速度有16~132倍不等的提升。综合考虑,本文算法在基于嵌入式设备行人检测中有着良好的综合性能。本文对网络结构的设计还在初始阶段,如何保证在计算量不变或者减少的情况下,进一步提升算法的准确性是下一步工作的研究方向。
