基于PAM概率主题模型的赌博网站检测方法
2021-09-15李国静尹天阳张兴睿
李国静 尹天阳 张兴睿
(北京锐驰信安技术有限公司 北京 100192)
0 引 言
互联网技术的快速发展带给人们便利生活的同时,也导致很多不法行为借助互联网平台的肆意传播,赌博网站便是其中之一。赌博网站由于其传播范围广、传播速度快,已成为危害正常网站秩序、破坏良好网络环境的罪魁祸首之一。赌博网站甚至逐渐演变成网络诈骗、病毒传播等其他网络犯罪的重要推手。因此,有效打击赌博网站,已成为打击网络犯罪与网络黑色产业的重要一环,是维护风朗气清的网络环境关键一步。
目前,针对赌博网站等违法网站的检测与识别主要分为静态检测和动态检测。静态检测主要通过获取网站的静态数据、URL、关键词等静态信息,并结合机器学习等算法,实现对赌博网站的检测。但是由于受网站静态数据所限,该方法面对未知的赌博网站检测效果不佳。动态检测则是通过与网站之间的通信,获取网站相关的网络行为并进行分析,通过是否存在恶意行为来判断是否为违法网站。由于赌博网站没有明显的网络恶意行为,动态检测方法针对赌博网站也很难奏效。因此,本文提出了一种基于Pachinko Allocation Model(PAM)概率主题模型的赌博网站检测方法,通过分析网站内容所描述的主题信息,来判断是否为赌博网站。
1 相关工作
针对赌博网站等违法网站的检测方法,国内外涌现了大量的研究成果。张瀚珑等[1]从HTTP POST中提取特征,通过聚类算法对此类特征进行聚类分析,从中提取赌博网站等违法网站的模板,该模板则可用来检测相关违法网站。凡友荣等[2]采用Fast Unfolding算法进行网站聚类并抽取赌博网站等违法网站的URL特征,利用特定特征作为违法网站的检测特征,从而对于未知网站,判断其是否具有URL违法特征进行检测。黄华军等[3]通过分析钓鱼网站等违法网站的URL地址的结构和词汇特征,提出一种基于异常特征的钓鱼网站识别方法,根据URL地址的特征向量,利用支持向量机进行训练和分类,达到了较高的钓鱼网站识别率。Eshete等[4]通过分析恶意网站所使用的工具集,提出一种利用相关工具集的流量信息来检测恶意URL的方法,该方法通过机器学习算法来捕获恶意URL所使用工具集的流量特征,从而检测相关URL是否采用此类工具集实施网络恶意行为。Bilge等[5]对DNS请示进行分析,设计了一种用于实时检测恶意域名的系统(EXPOSURE),该系统利用其获取的4个类别的15个特征,能够实时、有效地对恶意域名进行检测。臧小东等[6]提出一种分类与聚类相结合的思路,检测由域名生成算法生成的同类或相似的恶意域名。Kim等[7]提出一种自动、低交互的恶意网页检测系统(WebMon),该系统通过追踪URL链接检测潜在的恶意代码,从而判断是否为恶意网站。同时,该方法还能够抽取恶意网站的传播路径。
虽然赌博网站的域名变换迅速、网站伪装程度高,但不管赌博网站如何伪装或者隐蔽,其网站的赌博内容很难变化。为有效打击日益泛滥的赌博网站,故本文从网站内容主题挖掘的角度出发对赌博网站的检测。
2 方法设计
2.1 PAM模型概述
PAM是一种基于有向无环图结构(DAG)的概率主题模型[8],该主题模型的结构十分灵活,如图1所示,它既可以是基本的“文本—超主题—子主题—单词”的多层结构,也可以是各层之间任意嵌套的结构。PAM模型中,根节点代表文本,叶子节点表示单词,中间节点代表子主题或超主题,图中每个节点在其孩子节点上均服从Dirichlet分布。

图1 4L-PAM结构示意图
以图1中四层结构PAM(4L-PAM)为例,对于每篇文档d的产生过程描述如下:
(1) 根据4L-PAM中文档节点在超主题上的Dirichlet分布αr,采样其对应超主题的多项分布θr;
(2) 对于每个超主题ti所服从的Dirichlet分布αi,采样其对应子主题的多项分布θi;
(3) 针对形成文档d的每个单词w,根据超主题的多项分布θr采样一个超主题zi,根据zi上对应子主题的多项分布θi采样一个子主题zj,最后根据zj在单词上的多项分布φj采样一个单词。
在4L-PAM中,除文档及超主题在其孩子节点上服务Dirichlet分布以外,子主题zj在所有单词上服务固定的多项分布φj。因此,文档d形成的概率可表示为:

(1)
在概率主题模型中,每篇文档均被看作是由若干隐含主题所构成,而每个主题都由特定单词所体现。因此,不同单词的分布被看作是不同的隐含主题,而每个文档则是这些主题在特定比例下的组合。针对赌博网站检测问题,本文将网站也看作是一个特定的文档,通过抽取网站的HTML、脚本语言等信息,形成网站的文本信息。由于网站所呈现的主题由网站内容所决定,因此通过抽取网站文本信息的主题,可以有效地对网站进行主题分类,从而针对“赌博”性质的网站实施检测。
2.2 赌博网站的特征提取
PAM模型能够从大量文档中学习隐含主题,并且能够描述主题与词,主题与主题之间的关联性[9]。然而,PAM模型对文档主题的学习由文档内容所决定,从赌博网站检测的问题出发,如何利用PAM模型学习“赌博”相关的主题,并利用该模型对网站是否为赌博网站进行判断,是实现赌博网站检测的重要一步。
由于单纯利用特定关键词,如“下注”“博彩”“筹码”等作为表达“赌博”主题的关键词,并不能有效地实现对赌博网站的检测,还有可能产生误判。因为非赌博网站也有可能频繁出现此类关键词,从而导致检测结果产生较大误差。
通过对赌博网站的分析,本文发现大多数赌博网站都是封闭的,即网站的相关链接均指向赌博网站的其他内容或者相关赌博信息;相反,一般正常的网站则相对开放,网站链接会在不同主题的网站之间跳转。因此,根据这个特性,本文对所需要进行检测的网站随机采样多个页面内容,通过对这些关联页面进行主题提取,若多个页面均是关于“赌博”主题的,则在很大概率上说明此类网站是赌博网站;相反,不同页面的主题差异较大,则说明此类网站是赌博网站的概率就低。
同时,HTML是一种结构化的标记语言,网站不同位置所显示的文本信息,有着不同的含义和价值,如在HTML中“”标签所显示的内容往往是该网站的标题或者核心内容[10-11]。而PAM则采用词袋模型来描述文本内容,忽略文本的序列或者结构信息。针对赌博网站检测的问题,如果单纯地抽取网站的文本内容而忽略了其结构上的信息,往往会丢失很多重要的信息,不利于赌博网站的检测。因此,为了体现网站的结构信息,本文在词袋模型中加入能够体现网站结构信息的特征,并对此类特征赋予一定的权值,从而在PAM模型进行主题挖掘时能够考虑网站的结构特征,更有利于对网站的主题进行挖掘。
因此,在PAM的词袋模型中,对从网站上抽取的文本信息附上其在HTML的标签。例如:HTML文本中“”,分词后加入词袋模型的单词为:“t澳门、t新葡京、t官网”,其中“t”表示单词在HTML的标签为“title”。为了避免标签区分得过细,导致词袋模型中的单词在主题上的分布过于稀疏,本文只选取HTML中三个主要的标签,即“title”“head”“body”,在各个标签下的单词分别附加上相应的标识,以做区分。通过针对不同标签下的单词对于网站主题的影响,设置不同的权重,从而实现对网站结构信息的利用,挖掘网站的主题。
2.3 基于赌博网站特征的PAM训练与推理
Gibbs采样是一种基于条件分布的迭代采样算法[12],通过总体分布的条件分布簇来构建一个以该总体分布为平衡分布的马尔可夫链,从而对PAM模型的相关参数进行估计,并利用PAM模型对新的网站进行主题的推理。本文所采用的PAM模型是4L-PAM模型。
1) PAM参数训练。在4L-PAM模型中,每个单词均包含一个子主题z和一个超主题z′,只需对每个单词w采样其子主题和超主题,从而获得在这些主题下单词w的联合概率:
(2)

概率主题模型中仅通过词频作为模型参数训练的依据,为了引入网站结构信息的相关特性,本文将处于不同网站标签内的单词赋予不同的权重。而在词袋模型中,则表现为对相应标签的单词放大其在词袋模型中的出现的频率,从而提高网站特定标签单词对网站主题挖掘的影响。PAM参数训练算法的过程描述如算法1所示,PAM模型的训练实质是对参数α和β的训练,相关参数直接由所训练的文本所决定。因此,在模型训练时,可随机设置相关参数,在Gibbs采样过程收敛之后,取后续n个迭代结果的平均值作参数估计。
算法1PAM Training
1. 随机初始化。针对整个文档集中,每个文档的每个单词w,随机对其设置一个子主题和一个超主题,得到初始的马尔可夫链。
2. 重新扫描整个文档集。对每个单词,按照Gibbs采样公式重新采样它的相关主题,并进行更新。
3. 重复步骤2直到Gibbs采样过程收敛。
4. 统计整个文档集中超主题与子主题,子主题与单词之间的共现频率矩阵,计算相关参数α和β。
2) 网站主题推理。在获得针对网站主题挖掘的PAM模型之后,就可以对新的网站进行主题挖掘,从而检测其是否为赌博网站。利用PAM模型对新网站进行主题推理的过程与上述PAM参数训练的过程基本一致[13]。在网站主题推理过程中,只需保持式(2)中αij和βk这两个参数不变。因为这两个参数分别表示超主题在子主题上的Dirichlet分布和子主题在所有单词上的多项分布,它们是由训练文档集所决定的,接下来只需要估计文档在超主题上分布,就能够推理出该网站的相关主题。PAM主题推理算法的过程如算法2所示。
算法2PAM Topic Inference
1. 随机初始化。对新文档的每个词随机赋予一个超主题和一个子主题。
2. 重新扫描当前文档,对每个单词,按照Gibbs采样公式仅采样当前文档的超主题分布信息,并进行更新。
3. 重复步骤2直到Gibbs采样过程收敛。
4. 统计当前文档的超主题分布,该分布就反映了当前文档的主题信息。
经PAM模型推理出的网站主题通常是关于一系列主题的分布,一般取概率最高的主题作为该网站所描述的主题。
2.4 赌博网站检测系统框架
赌博检测检测系统实现了针对相关网站进行自动检测并识别是否为赌博网站的功能。该系统的构架如图2所示,主要分为网站文本及结构信息采集模块、网站主题挖掘模块、赌博网站检测模块。

图2 赌博网站检测系统工作流程图
1) 网站文本及结构信息采集模块。该模块主要承担了网站文本信息、网站结构化信息的采集等工作,用于进一步根据其网站主要内容进行网站主题的挖掘。从对赌博网站的特征进行分析,本文发现赌博网站相对比较封闭,其网站上链接的指向往往是赌博网站的其他页面。而传统网站的链接则可能跳转到其他不同类型的网站。因此,在进行网站主题挖掘之前,本文首先采样被检测网站的相关链接,获得多个与之关联的网页,将所有网页分别进行主题挖掘,从而比较各网页主题的分布。如果多数网页在大概率情况下,均倾向于“赌博”主题,则说明被检测网站为赌博网站。
同时,结合网页结构化信息,将位于网页不同位置的文本赋予不同的权重,即提高相应HTML标签下文本内容在词袋模型中出现的频率,从而充分利用网站的结构化信息,使得在进行网站主题挖掘时的准确性更高。
2) 网站主题挖掘模块。在获取被检测网站及关联网页的文本信息后,需要对其文本内容进行主题挖掘,进而获得该网页内容所描述的相关主题。该模块通过4L-PAM模型对网页文本内容进行主题挖掘,从而形成各个网页上的主题分布。通常,将高概率的主题作为描述该网页主要内容的主题。
3) 赌博网站检测模块。在获得了各个网页主题分布之后,计算所有网页在“赌博”主题上概率的平均值,作为评估被检测网站是否为赌博网站的指标,如式(3)所示。假设当前共有n个网页,pi表示第i个网页所挖掘的主要分布中“赌博”主题所占的概率,λi表示第i个网页对应的权重(默认情况下,λi=1)。为避免因“赌博”主题在某些网页所占比例较小而影响平均概率,因此,对于“赌博”主题所占比例小于30%的网页,本文在计算赌博网站检测指标pg时,设置此类网页对应的“赌博”主题的概率和相应的网页权重均为0,从而忽略其对“赌博”主题的判断。
(3)
最后,根据pg的数值可以判断被检测网站为赌博网站的概率。一般,当pg>0.5时,本文就认为被检测网站为赌博相关的网站。
3 实 验
3.1 实验数据与模型训练
实验爬取了各类主题的网站(包含赌博网站),共获得了2 000个网页,其中赌博网站相关的页面100个。对上述所有网页抽取其网页文本内容,并根据相关文本在网站的位置赋予不同的权重,从而形成了用于PAM模型训练的文档集合。
首先设置PAM模型的超主题个数为20,子主题个数为40,相关参数α为1.0(文档在超主题,超主题在子主题上的Dirichlet分布参数),β为0.01(子主题在单词上的分布参数)。通过算法1描述的PAM训练方法,可以得到在这些文档集上所训练的PAM模型。从赌博网站检测的问题出发,本文只关注由PAM模型训练出的关于“赌博”的相关主题。
表1列举了由PAM模型所训练出的关于“赌博”的超主题,以及该主题下部分子主题和部分高频词的分布。可以看出,在对新的网站进行主题挖掘时,该主题在该网站的超主题分布中所占比例越高,说明该网站为赌博网站的概率就越高。
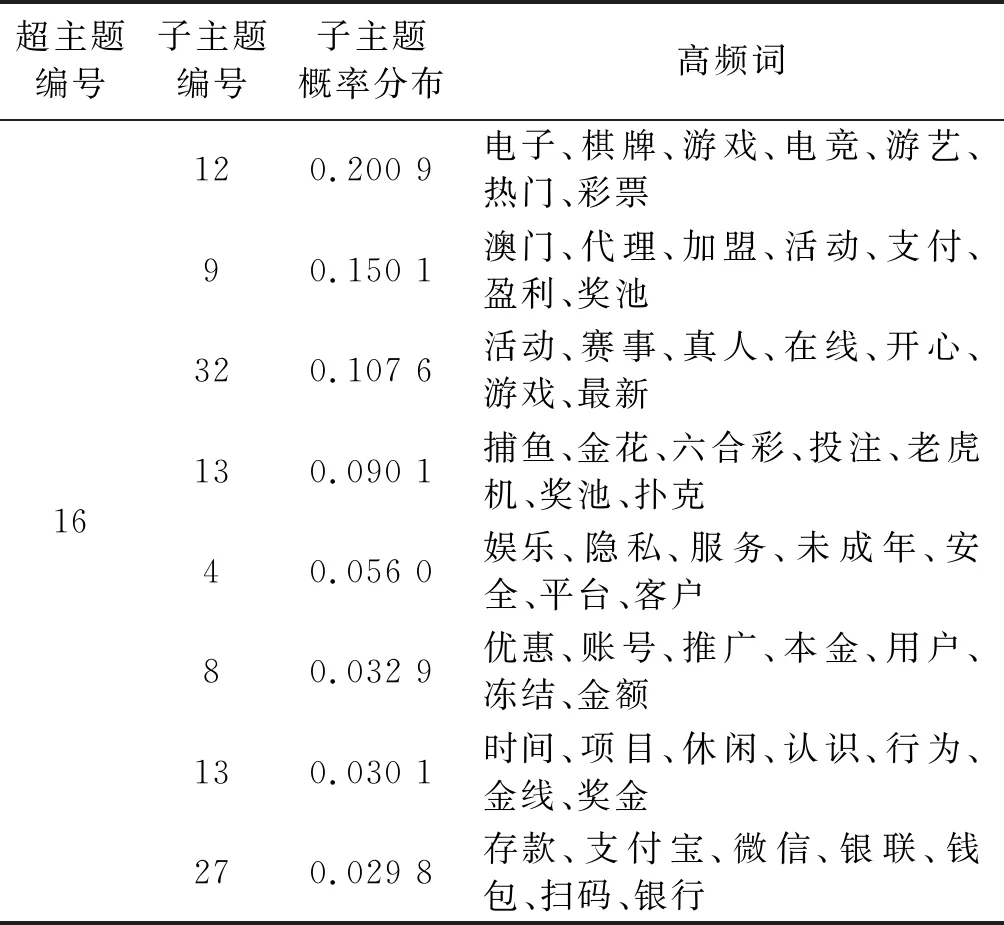
表1 “赌博”主题及其高频词分布
3.2 赌博网站检测评估
针对赌博网站检测的评估,实验重新爬取了非赌博网站和赌博网站各100个网页,对本文利用PAM模型检测赌博网站的方法进行评估。实验通过准确率P、召回率R及综合评价指标F1对本文在赌博网站检测方法进行进行评估。实验用t_b表示被正确识别的赌博网站数量,f_b表示非赌博网站被错误识别的数量,f_w表示赌博网站没有被正确识别的数量,各评估指标的具体计算方法如下:
(4)
(5)
(6)
实验将本文方法(PAM)与基于网站模板的检测方法(Template)[1]、基于URL的赌博网站检测方法(URL)[2]进行对比实验,对比结果如表2所示。

表2 实验数据对比
基于URL的赌博网站检测方法在仅利用URL等相关信息的情况下,对于赌博网站的URL有明显特征的情况下,其检测效果较好,但是考虑到很多赌博网络频繁更换URL,有些赌博网站的URL不带有明显的特征,因此此类方法很难有效、准确地对赌博网站进行检测。基于模板的赌博网站检测方法则从HTTP POST提出网站的特征来获取赌博网站的模板,进而利用该模板对赌博网站进行检测,由于赌博网站形式多变,单一模板很难涵盖大部分的赌博网站,面对新的赌博网站类型,该方法检测效果可能有所下降。本文方法基于PAM模型,通过对网站内容进行主题挖掘,抽取网站内容所描述的相关主题来作为判断是否为赌博网站的依据,因此本文方法的适用性更广,面对复杂网络环境时的检测效果更好。
Template方法通过对赌博网站的网站特征进行聚类分析,以此获得相应的赌博网站模板,从而根据该模板检测赌博网站。URL方法则通过抽取赌博网站的URL特征并以该特征对赌博网站进行检测。但当前赌博网站逐渐从传统博彩向多样化的网站赌博转变,如借助网页游戏进行赌博。同时,赌博网站架构、网站域名等相关信息的规范化程度逐渐提高,使得此类赌博网站与游戏网站在网站特征、URL等方面的相似度很高,仅通过此类信息进行检测,效率可能会有所下降。而本文从网站内容的角度出发,通过抽取网站内容所描述的主题对赌博网站进行检测。因赌博网站网页内容所描述的信息难以脱离赌博等相关主题,因此针对网站描述内容进行赌博网站的检测,会大大提高对赌博网站的识别率。
考虑到PAM模型所训练的主题及其分布对赌博网站的识别至关重要,本文针对PAM模型所设置的超主题、子主题的个数对实验结果的影响进行了分析。因为本文仅面向赌博网站进行主题挖掘与检测,因此除“赌博”主题外,其他所挖掘的超主题类型均不在本文的考虑范围内。首先,在保持超主题个数不变的情况下,动态调整子主题个数来评估PAM模型对赌博网站检测的影响。如图3所示,子主题个数分别从10变化至90。在不同的子主题个数影响下,训练所得PAM模型在赌博网站检测上的准确率和召回率也随之变化。从图中所得数据可知,针对当前训练文档集和赌博网站检测的问题,在子主题设置个数为40时,训练所得PAM模型在该问题上的检测效果最优。而当子主题规模继续扩大时,子主题过于分散,则会导致超主题在子主题上的分布过于稀疏,从而影响对网站主题的判断。

图3 子主题个数对实验结果的影响
基于上述结论,保持子主题个数为40,动态调整超主题个数来评估其对赌博网站检测的影响。如图4所示,随着超主题个数的增加,本文方法对赌博网站的检测结果呈上升趋势。超主题个数在达到18个之后,实验的准确率趋于平衡,但是随着超主题的个数持续增加,召回率则有下降趋势。实验结果说明,针对本文的训练文档集,超主题个数控制在18至20个为最佳。过多的超主题会削弱超主题在子主题上的统计分析,可能导致更多无关主题被关联到“赌博”主题上,从而使检测过程中的误报率上升。

图4 超主题个数对实验结果的影响
4 结 语
本文针对赌博网站检测的问题,提出了一种基于PAM概率主题模型的检测方法。该方法通过分析网站及相关网页的内容,挖掘网页所描述的主题,根据网页主题来判断网站是否为赌博网站。为提高赌博网站检测与识别的准确度,本文将网站文本的结构特征引入PAM模型中,并给予了不同的权重,从而有效利用网站结构信息对网站主题的影响,提高网站主题挖掘的准确性。同时,利用赌博网站的封闭性,将被检测网站的关联网页一同进行主题挖掘,综合判断当前网站的类型,大大提高了赌博网站的识别率。
