一致性哈希算法的对比研究
2021-09-14潘子浩
潘子浩


摘要:分布式存储系统中为了实现高可用、高性能和高扩展性,系统内数据布局和负载均衡是关键的技术问题。一致性哈希算法是解决此类问题行之有效的方法。将对比研究几种一致性哈希算法,包括基本和带虚拟节点的一致性哈希,微信存储系统中应用的一致性哈希和谷歌跳跃一致性哈希。对微信存储应用的一致性哈希进行了改进。
关键词:一致性哈希;虚拟节点;跳跃一致性哈希
Abstract: In order to achieve high availability, high performance, and high scalability in distributed storage systems, data layout and load balancing in the system are key technical issues. The consistent hashing algorithm is an effective way to solve such problems. Several consistent hashing algorithms will be studied and compared, including basic consistent hashing, consistent hashing with virtual nodes, consistent hashing used in WeChat storage systems and Google jump consistent hashing. The consistent hashing used in WeChat is improved.
Keywords: Consistent hashing; Virtual node; Jump consistent hashing
分布式存储系统发展过程中,遇到了多个方面的挑战,其一是数据分散存储在系统中,当系统面对海量读写请求时,如何保障系统的负载均衡避免出现数据倾斜。第二为应对系统流量的增长和萎缩,集群系统需要能够动态添加和删除节点,在保持负载均衡的同时实现数据的最小化迁移。一致性哈希算法因为具有良好的均衡性和一致性,在分布式存储系统中受到广泛的应用。
基本一致性哈希算法在Kager于1997年论文[1]中提出并其后应用于Danamo和Switf等系统后,衍生了多种优化改进的算法,包括带虚拟节点的一致性哈希,微信核心业务存储系统使用的一致性哈希,谷歌跳跃一致性哈希,maglev一致性哈希,负载有界一致性哈希,以及其他改进的一致性哈希算法等。对上述的部分一致性哈希算法,论文将从均衡性和一致性两个方面进行对比研究,并对微信存储系统使用的一致性哈希进行了优化。其中均衡性是指数据经过哈希后能尽可能分散到所有服务器节点中,每个服务器处理的数据相当,均衡的算法能最大化系统利用率。一致性是指系统增加节点需要对数据key进行重新映射,数据key只能保留在原有节点或者移动到新节点上,不能移动到其他的节点上。
1算法对比
1.1基本一致性哈希和带虚拟节点的一致性哈希
基本的一致性哈希算法原理如图1,算法过程如下:
(1)设置一个地址空间范围为0~(232-1)的哈希环;
(2)使用节点的特征值(一般使用节点ip地址)计算哈希值,映射到哈希环上的一点。如图1所示节点S1,其ip地址经过哈希后落入哈希环上一点。对每个节点都使用同样的方法映射到哈希环上;
(3)对存取数据key使用相同的哈希函数计算哈希值映射到哈希环上,以此位置顺时针查找第一个落入到哈希环的节点。图1中key3经过哈希后顺时针找到了S2节点。
基本一致性哈希算法并不均衡[2],在哈希环上复制虚拟节点的方法可以改善此算法的均衡度[3],其思想是将一个节点(也称为实际节点或者实节点)在哈希环的不同位置上放置多个拷贝(称为虚拟节点),并调整上述算法的第二步,使用实节点对应虚拟节点的特征计算哈希值映射到哈希环(比如使用“192.168.1.100#1”作为192.168.1.100实节点编号为1的虚拟节点的特征),对每个实节点设置一定数量的虚拟节点映射到哈希环上,而要查找数据key对应的实节点,是先通过其哈希值顺时针找到虚拟节点再找到对应的实节点。
显然,新添加一个节点映射到哈希环上时,只有这个节点的哈希值(或者其对应虚拟节点的哈希值)与逆时针方向的前一个哈希值之间的数据key会被重新映射到新的节点,其他数据key继续保留在原有节点,两种算法都满足一致性的要求。
关于均衡性,从图1可以看到,落入节点的数据key的数量,与每个节点在哈希环中负责的地址空间密切相关,一致性哈希算法的均衡度,可由节点在哈希环负责的地址空间的差异来度量。在实际应用中,分布式系统一般是由相同配置的服务器节点构成,为了提高节点利用率和减少运营成本,要求选用均衡度较好的一致性哈希算法,另外按照木桶理论,分布式系统最大处理能力由最先进入过载的节点决定,也就是负载最高的节点决定了集群整体的性能,而在不考虑热点数据情况下,节点的负载与其负责的地址空间成正比例关系。因此论文用三个与地址空间有关的指标来衡量算法的均衡度:集群中最大地址空间与最小地址空间的比值R1,地址空间值与平均值相差10%、2%以内的节点数量在总节点数的比例R2和R3。
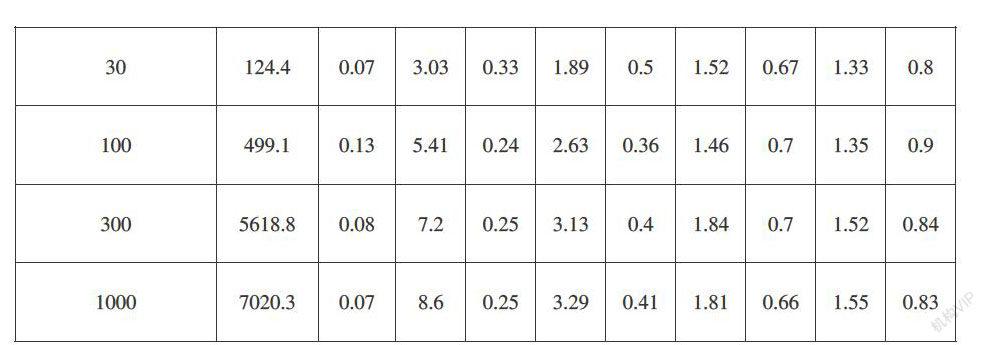
表1展示了使用md5+fnv1_32函數对节点或虚拟节点特征值进行哈希,通过程序统计得到两种算法在不同节点数配置下系统的R1和R2。ip地址和哈希函数的不同对统计结果会产生一些变化,但不会影响整体的结论。
基本一致性哈希算法的一般趋势是R1值随着节点数的增加而急速增加,此外R2值都比较低,意味着使用此算法的系统,其节点间的负载是非常不均衡的。比如30节点下,R1已超过了100,系统节点间会出现负载差异百倍的情况。带虚拟节点的一致性哈希算法均衡度得到了明显的改善,如30个实节点每个配置30个虚拟节点,R1已经降低到了2以下,远低于基本一致性哈希中的R1。此外在实节点数确定时,虚拟节点数的增加可以降低R1和提高R2,提高节点间均衡度;但虚拟节点数确定时,系统增加实节点时则会升高R1和降低R2,降低节点间均衡度。但考虑系统的复杂性,虚拟节点数并不会无限制的提高,实际应用中每个实节点配置100个虚拟节点是一个常用的配置。在此配置下,系统并非完全均衡,比如超过30个实节点的集群,R1超过了1.5,R2低于0.7,意味着系统会出现高负载是低负载1.5倍的情况,并且超过30%的机器负载偏离了平均负载的10%。