基于共词网络的雾霾事件下微博关注话题差异性
——以中国北方雾霾严重地区典型城市为例
2021-09-14逯海玥芮小平李润奎
逯海玥,芮小平,李润奎
(1.河海大学水文水资源学院,南京 211100;2.河海大学地球科学与工程学院,南京 211100;3.中国科学院大学资源与环境学院,北京 100049)
雾霾是一种由于空气中存在的灰尘、水分、烟雾、水蒸气而造成空气水平能见度小于10 km的天气现象[1-2],其产生根源于PM2.5,是空气中动力学当量直径小于等于2.5 μm的颗粒物[3]。目前,雾霾较往年虽出现好转,但在北方地区仍时有发生,对社会生活、经济发展,尤其是对人们的身心健康产生了极其严重的威胁。有研究表明,在空气污染物浓度尤其是PM2.5浓度过高的情况下,生活在这种污染空气中的人们,会因此而产生急性的健康风险,进而诱发心血管等疾病[4-5];此外,空气污染不仅与人类的多种疾病有关,还对人类的心理也有较为明显的影响,Ho等[6]通过研究证实,即使是短期雾霾也会造成心理压力,使人产生心理障碍,Gu 等[7]利用多种计量经济学方法分析空气污染对于心理健康的影响,发现PM2.5浓度越高,人类的紧张、抑郁、无力、烦躁四种负面情绪会更突出。
互联网时代,人们越来越倾向于在社交平台上发表看法、表达情感、探索自己感兴趣的新闻。微博作为一种社交平台,具有内容简短、传播迅速、实时性强等特点,在一定程度上改变了人们获取、交流、表达信息的方式[8]。微博公开化的特点使得其具有多源用户,以及多主题的内容,各年龄阶层、各社会性质的人们都可以根据自己的需要发布不同主题的内容,比如新闻、事件评论、情感表达等,因此微博数据是开展各种舆情研究的良好数据源[9]。当雾霾污染严重时,人们会在微博平台发布、转发、评论相关微博,这些微博内容包含了许多围绕雾霾污染所产生的观点信息,而不同城市受雾霾的影响程度不同,人们对雾霾的态度也因此而异,以北方受雾霾污染严重的典型城市为例,采集、分析微博数据,挖掘其中蕴含的话题信息,旨在为城市网络舆论引导、环保政策制定等提供理论指引。
当前,中外有大量研究利用微博数据对雾霾发生时网民的关注点进行探讨、分析。曾子明等[10]根据微博数据和以往的研究定义了微博影响力特征变量和用户可信度,采用LDA(latent dirichlet allocation)主题模型,对2016年微博中与雾霾有关的谣言进行精准识别,降低了用户的信息焦虑;Yang等[11]应用框架理论对微博进行文本分析,发现中国官方媒体对于雾霾的关注点集中于政府关注、舆论劝阻管理、舆论影响因素、社会雾霾相关新闻及外部雾霾相关新闻5个层面;Zhang等[12]利用微博数据,分析人们对雾霾感知的季节性差异,发现春夏秋冬人们的关注点分别侧重于雾霾成因、积极情绪、防治措施及健康影响4个方面;Wang等[13]对微博内容进行文本分析,以哈尔滨市微博数据为例,发现雾霾期间用户的关注内容分为三大类:情感表达与观点阐述、信息提示、个体情境感知;Lin[14]对新加坡雾霾危机期间的微博数据进行网络分析,发现当环境危机发生时,传统媒体和新媒体在报道相关新闻、应对重大事件、向公众发布信息等方面采取不同的方式。
目前现有研究大多是对同一地区进行相关分析,很少有研究涉及不同地区雾霾舆情关注点的空间差异性研究,基于此,考虑空间差异,将不同地区纳入研究范围,利用共词网络法首次探索雾霾情形下微博网民的舆情响应,及不同城市对雾霾关注程度的差异性。首先,抓取以“雾霾”为主的微博数据,根据TF-IDF(term frequency-inverse document frequency)算法提取出每条微博的关键词汇,利用微博关键词的共现关系构建共现三元组,进而构建共词网络,然后,通过社区探测算法挖掘出话题社区,以此为基础,对比不同城市地区舆情话题的差异及差异程度,从舆情发展的角度为城市应对雾霾提供差异化理论指引,如针对大众情绪异常现象,政府应作出及时、恰当的情绪引导,避免不良行为的发生;对于雾霾所造成的负面影响,如健康威胁、交通影响,应采取相应措施减轻损害,提升生活幸福感;针对其他不同的关注点,采取相应策略,促进城市可持续发展。
1 相关方法
目前,话题挖掘方法主要分为三大类。第一类方法是文本聚类法,以聚类假设作为理论依据,依据文本词元素之间的相似度,选取某种相似性规则进行聚类。路荣等[15]对微博文本进行聚类识别出了新闻话题;又如杨波等[16]提出了基于词向量和增量聚类的短文本聚类算法(improved single-pass algorithm based on word embedding, ISWE),聚类准确率明显提高;再如何诺等[17]改进了K均值聚类算法,成功克服K均值初始聚类中心比较敏感的问题。聚类方法会出现数据稀疏、维度爆炸的现象,无法保证聚类结果与主题的相关性。
第二类方法是主题模型法,主要有三种:PLSA(probabilistic latent semantic analysis)、LDA(latent dirichlet allocation)和改进的LDA模型。PLSA主题提取的过程就是高维空间到低维空间的降维过程[18],但PLSA不能直观理解主题信息。Blei等[19]提出了LDA主题模型,解决了此难题。LDA由文档层、主题层及主题词语层构成,可用来生成文档主题[20],但传统LDA模型不适用于短文本,因此许多学者考虑多种特征,提出了基于LDA的改进模型,以更好地应用于微博短文本的分析。如吴楠[21]提出LDA-SP(latent dirichlet allocation-single pass)混合模型,基于单通道算法(single-pass,SP)进行语义相似度聚类。微博等社交媒体中的数据种类丰富、长短不一,多数微博具有共性内容,此种情况下,主题模型适应性较差,无法全面地提取主题信息。
第三类方法是基于社区的共词分析法,考虑社交媒体的网络化特性,利用关键词节点构建共词网络,含有相同关键词越多的微博社区连接越紧密,所以共词网络可以表示成“网络-社区、主题-节点、边”的形式[22],话题提取取决于对包含不同词汇的微博社区的划分,且微博社区间的模块度[23]决定了微博社区划分的精确度,即同一微博社区内部要含有尽可能多的相同关键词,而不同微博社区间要含有尽可能少的相同关键词。例如,丁晟春等[24]考虑微博在传播过程中的微博特征和用户行为,发现了魏则西事件的潜在主题;方兴林[25]采用共词分析法,得到微博上中国政务研究领域的热点信息;李磊等[26]改进了传统的共现分析法,结合社会网络分析识别出社交媒体舆情信息中的主要话题;王艳东等[27]利用共词网络法在网络舆情文本数据中挖掘话题社区,探测出灾情发展阶段及态势。这类方法可自动识别话题数目,以网络社区为话题基本单位,将现实社会网络映射到虚拟网络空间中,符合微博内容具有小社团聚集性的特点,在话题挖掘领域具有很大的优势;因此选择共词分析法,进行雾霾情形下,不同城市中人们对雾霾关注点的差异以及差异程度的研究。
2 基于社区的共词网络法
2.1 研究思路
围绕“雾霾”一词采集微博数据,对数据进行去噪、分词、去停用词等预处理操作,通过TI-IDF法提取关键词、进而构建关键词共现三元组,再利用Gephi软件构建共词网络,最后,通过Louvain社区发现法来探测雾霾事件下的话题社区,结合节点Pagerank属性分析不同区域对雾霾事件关注点的差异及差异程度。论文方法流程图如图1所示。

图1 方法流程图
2.2 关键词提取
关键词是文本中起关键作用的、反映主题思想、可以代表中心概念的内容,通常以词语或词组的方式呈现。其不仅要体现文本中的主题相关性,还需要将词语的重要性反映出来[28],因此需要运用一定的关键词抽取技术筛选出对构建共词网络贡献度大的关键特征词。在关键词提取技术中,比较经典的一种关键词提取方法为TF-IDF算法[29-30],TF-IDF是一种常用于信息检索和文本挖掘领域的加权方法,主要思想是:若一个词语在一篇文档中出现的频率高,同时在其他文档中出现较少,则该词语具有良好的区分类别的能力,可用于文本分类、提取核心词(即关键词)、计算文档间的相似程度、检索排序等[31],其所代表的权重表示某一文档中一个词语相对其他词语而言的重要程度[32],TF-IDF算法中TF(term frequency)指词频,IDF(inverse document frequency)指逆向文档频率,TF-IDF实际上指TF×IDF,意味着一个词语的重要程度与该词语在文本中出现的次数成正比,与该词语在整个文本集合中出现的频率成反比,这种计算词语重要程度的方式可以有效减少常用词对关键词产生的影响,提高了关键词与其所在文章间的相关程度。TF值体现了词语对某文本的重要性,IDF体现了词语对文本集合的重要性,若词语在文本中TF值高(在该文本中出现次数多),IDF值高(在其他文本中出现次数少),则说明该词语能够代表其所在文本的中心内容。TF-IDF值具体计算公式为
(1)

2.3 共词网络的构建
共词网络的构建取决于关键词共现矩阵的形成,根据关键词共现的频率建立共现矩阵,是后续统计分析的基础[33];共词网络是用以描述关键词及共现关系的数学图模型G=(V,E),其中V是一个非空集合,为关键词构成的节点(node),E也是一个非空集合,为关键词间的共现关系组建的边(edge),eij(G)为图G中的节点Vi和节点Vj之间的共现边,ωij为权重,是关键词节点Vi和节点Vj之间的共现次数[34-35]。共词网络结构如图2所示。

图2 共词网络结构示意图
共词分析最重要的一步即将构建出来的共词网络可视化,直观呈现网络结构,常用的共词网络分析工具有Gephi、NetDraw、Pajek、Ucinet等,选取Gephi将关键词共词网络可视化。
2.4 Louvain社区探测算法
共词网络的结构通常不是杂乱无序,而会呈现一定的规律,一般来说,网络中部分节点会聚集在一起成为小团体,团体连接越紧密,包含相同的关键词越多,蕴含的话题会越相似[22]。这种小团体结构也叫社区,是常见于社会网络中的一种介于宏观与微观之间的网络结构特征,在真实网络中,同一个社区内的节点往往具有相似功能或性质,比如引文网络是具有论文引用关系的一些论文集,这些论文集倾向于研究相似的学科主题[36]。通过研究社区的结构,可以对网络的结构与功能间的关系具有更深刻的理解,因此对共词网络中话题的发现与描述就可以转化为对话题社区的发现,社区包含的词语就代表了话题的内容。目前,常见社区发现算法有谱二分法、Kernighan-Lin算法、层次聚类算法等[37],但这些算法仅适用于小规模网络,而不适用于节点较多的大型网络,Louvain算法[23]对大规模网络具有适用性,因此本文研究使用此算法来进行共词网络的社区发现。Louvain算法具有很好的社区划分效果及效率,是社区发现算法中性能最好的算法之一[38],其基于模块度[39]进行最优化、启发式计算,具有计算结果解释性强、支持大规模网络的特点,模块度定义为
(2)
式(2)中:m为图中边的总数;ki为所有指向节点i的连边权重之和,kj为所有指向节点j的连边权重之和;Ai,j为节点i,j之间的连边权重;Ci和Cj分别表示节点i、j所属社区,当i和j同属一个社区,δ=1,否则,不同属一个社区,δ=0。通过对模块度不断进行优化,可以划分出具有不同话题内容的社区,且各社区内部具有尽可能多的相同关键词,社区与社区之间具有尽可能少的相同关键词[16],可以清晰区别出不同话题社区。
3 实验与结果分析
3.1 数据采集及预处理
主要采用两种数据:空气质量数据和微博数据。城市空气质量数据来源于世界空气质量指数网站(https://aqicn.org/map/china/cn/),收集范围包含中国受雾霾污染最严重的华北地区典型城市,包括北京市、天津市、石家庄市、太原市、呼和浩特市,以及雾霾相对严重的东北地区城市沈阳市、华东地区城市济南市,数据收集时间为冬季,包括12月、1月、2月,此季节相对于其他季节,雾霾最严重,相关微博数据较丰富,更具代表性及研究价值,数据内容包括城市、日期、PM2.5、PM10、一氧化碳、二氧化氮和二氧化硫含量,由于PM2.5是雾霾污染产生的主要原因,现采用PM2.5含量来说明雾霾污染的程度;微博数据通过后裔采集器抓取,以“雾霾”“空气”等为搜索关键词,抓取7个城市2017年冬季的相关微博数据,每条微博的抓取内容包括用户ID、微博博文、时间范围、点赞数及评论数等,最终共搜集到34 373条相关微博数据,其中,北京市数据11 790条、济南市数据6 140条、沈阳市数据2 388条、石家庄市数据6 860条、太原市数据2 459条、天津市数据4 736条、呼和浩特市数据730条。
上述通过采集器获取的微博原始内容属于非结构化的数据,存在许多噪声,如重复数据、商业广告、特殊符号等,计算机无法直接进行处理,为了提高话题挖掘的准确性和效率,需要进行数据清洗、文本分词以及过滤停用词的预处理操作。本文利用Python语言编程剔除表情符号、标签、网页链接等内容以实现数据清洗,调用Python中的jieba库对清洗过的数据分词,然后,加载哈工大停用词表过滤“我、的、了”等停用词,最终将原始微博数据转为由若干词语组成的结构化数据,以便后续分析,数据预处理结果如表1所示。

表1 微博文本预处理示例
3.2 TF-IDF关键词提取及共现矩阵构建
对于预处理后的微博文本,利用Python实现jieba库中的TF-IDF算法,计算每个词语的TF-IDF值也即该词语的重要性值,经排序得到排名靠前的若干词语,即可得到每条微博的关键特征词,本文设定提取每条微博TF-IDF权重最大的前70个关键词,词性范围包括n(名词)、nr(人名)、ns(地名)、f(方位词)、a(形容词)、v(动词)、z(状态词),以便构建出内容清晰、规模适中的共词网络;同样,利用Python编程统计关键词节点之间的关系频数构建共现矩阵,借助字典数据结构将共现矩阵转换为共现三元组,便于存储,共现三元组示例如表2所示。

表2 关键词共现三元组示例
3.3 基于社区的共词网络主题挖掘
Gephi软件基于Java虚拟机,跨平台、开源,可用于分析各种复杂网络[40]。首先,将共现三元组导入Gephi软件中,统计得到网络的节点个数与边条数,计算节点重要性——Pagerank大小,并根据节点Pagerank值、边与节点间的权重设置节点与边的外观;其次,为使网络清晰可观,根据边拓扑中的度范围系数对边进行过滤,降低网络复杂度,同时保留重要节点;最后,调整网络布局,采用软件内置的力引导布局算法,将节点模拟为原子,利用原子间的引力和斥力做迭代运动,调整每个节点的位置,使网络具有最平衡的结构,本文选择社区探测效果最明显的Fruchterman Reingold算法,分别得到7个城市包含子话题社区的共词网络,如图3所示。

图3 包含子话题社区的共词网络
3.4 不同城市关注话题差异性分析
3.4.1 宏观层面
运行Gephi软件的统计分析模块,得到各城市微博宏观层面的网络概况,如表3所示。各网络参数定义如下。

表3 城市微博共词网络概况
平均度:表示图中每个节点所连接边的平均数,衡量网络节点的活跃度,值越小代表节点间连接越少。
图密度:表示网络节点间连接的疏密程度,值越大代表节点连接密集。
模块化指数:表示网络的模块化程度,值越大代表模块化程度越高。
平均聚类系数:表示节点抱团或聚类的总体迹象,值越大代表节点关联越紧密;和平均路径长度一起,反映网络的小世界特性。
平均路径长度:表示任意两个节点之间距离的平均值,反映网络中节点间的分离程度,值越小代表节点关联越紧密。
综合考虑各网络参数,对7个城市共词网络参数值进行比较,观察得节点数与边条数同向变化,将两者合并为网络规模,得如表4度量排序情况。
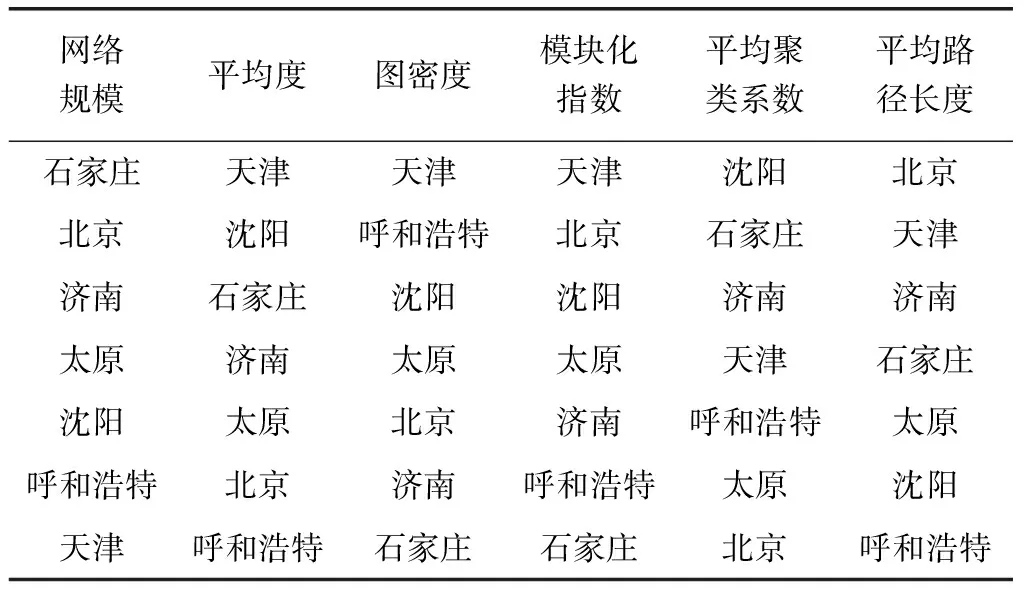
表4 城市共词网络度量排序表(降序)
分析表3及表4可知,7个城市的微博共词网络规模各异,但观察发现,规模大的网络中,模块化程度不一定高,节点间的联系不一定紧密,因此,仅依靠网络的宏观概况难以看出网络中各社区的细微差异,因此需结合社区内部节点的属性来深入分析不同城市共词网络在话题社区方面的差异。
3.4.2 微观层面
共词网络图中,节点颜色决定话题社区内容,节点大小决定话题社区大小,结合图3中不同颜色的节点内容及Gephi中节点属性可以得到表5所示的话题社区情况,进而定量分析在雾霾事件下,7个城市人民舆情关注点的差异。

表5 北京市共词网络话题社区示例
由于篇幅限制,没有展示剩余话题社区详情,利用同样的分析方法可得到表6所示的话题社区简表。
分析表6可知,雾霾发生时,按照对话题的关注程度,北京市关注话题依次为探讨原因、雾霾治理、乐观态度、直观感受、旅行娱乐,济南市关注话题依次为直观感受、旅行娱乐、交通影响、风景名胜、应对措施,沈阳市关注话题依次为直观感受、呼吁倡导、航班取消、乐观态度、放假休息,石家庄市关注话题依次为直观感受、负面情绪、雾霾治理、健康威胁、交通影响,太原市关注话题依次为直观感受、雾霾治理、乐观态度、交通管制、航班取消,天津市关注话题依次为直观感受、专家解释、健康威胁、呼吁倡导、日常生活,呼和浩特市关注话题依次为官方发声、雾霾治理、政府整治、直观感受。

表6 各市共词网络话题社区一览表
同时,各市关注点有交叉部分,在对雾霾直观感受方面,每个城市人民在雾霾发生时都会对此描述所见所想,但程度有深有浅,由深及浅依次为石家庄市、济南市、沈阳市、太原市、天津市、北京市、呼和浩特市;在对雾霾治理的讨论方面,有4个城市对其有所关注,按关注程度依次为北京市、太原市、呼和浩特市、石家庄市;呼吁倡导方面,按讨论程度,沈阳市优于天津市;旅行娱乐方面,北京市和济南市关注程度相当;乐观态度方面,按程度依次为北京市、太原市、沈阳市;在雾霾对交通影响的讨论方面,按程度为济南市、石家庄市;对于航班取消的关注,按程度为济南市、太原市;在雾霾对健康造成威胁的关注上,依次为天津市、石家庄市。
除共同关注话题外,每个城市有其独有的关注点,北京市人民侧重于对造成雾霾的原因进行探讨,济南市人民会具体讨论应对雾霾的措施,沈阳市人民在雾霾天气下较关注放假休息,石家庄市人民对雾霾的耐受性可能不如其他几个城市,太原市人民对于交通管制给予更多的关注,天津市人民较关注专家对雾霾现象的解释说明,而呼和浩特市较重视官方媒体所作出的回应以及政府对雾霾污染进行整治,在7个城市中,呼和浩特市空气质量最好,在一定程度上得益于对雾霾的及时关注与积极应对。
4 结论
利用基于社区的共词网络法探究雾霾污染时,不同城市的人们在微博中关注点的差异性,以华北地区、华东地区、东北地区7个典型城市为研究地区,得出如下结论。
(1)虽然每个城市对雾霾的关注点有细微差异,但发生雾霾污染时,各城市人民都会对其有及时感知,并会讨论雾霾所带来的各方面影响。
(2)出于对健康生活的需要,各城市人民对雾霾治理都有不同程度的关注,如雾霾治理、呼吁倡导、应对措施等关注内容。
(3)同时,多数城市对雾霾事件的态度以乐观为主,少数城市会出现情绪异常,如石家庄市共词网络中的难受、无奈、抑郁等关键词。
研究结果对城市健康发展可起到一定的理论指导作用,如针对大众情绪异常,采取措施实现提前心理干预,降低不良行为的发生概率;针对雾霾污染对身体健康造成的负面影响,增设相关医疗部门,调配医疗资源以满足健康需求;针对雾霾天气导致的道路交通安全问题,相关部门可加强安全提示、增加路面巡逻管控来减少交通事故的发生,为居民出行营造良好的交通安全环境;管理人员可根据不同雾霾舆情关注点,制定差异化应对策略,实现对症管理,提高管理效率。
利用关键词间的共现关系构建共词网络,以Louvain社区探测算法发现话题社区,以此为基础单元研究关注点的差异性。其中,关键词提取基于TF-IDF算法,会过滤掉某些重要词语,影响话题社区探测的准确性;其次,本文话题挖掘基于静态时间段,随着时间发展,人们的关注点会发生变化,本文未在此方面做详细研究,因此,改进关键词提取算法以及雾霾舆情动态话题演化将是下一步研究的重点。
