基于网络爬虫的单词翻译器设计与研究
2021-09-13周游宇孙洪波梅良才
周游宇 孙洪波 梅良才
摘 要:该文基于机器学习中的网络爬虫技术提出了一种单词翻译器的设计与研究流程。首先,该文对Iciba网站进行爬虫,经过前期url分析,编写定向页面requests爬虫,得到单词释义和例句。其次,通过一个查询单词的通用程序框架,编写requests定向爬虫,实时获得最新的词语解释和例句。最后,该文设计了一个GUI窗体界面,用于展示相关结果,具有较好的实用性和有效性。该文提出的研究方法是机器学习相关研究领域的一个扩充,且该研究结果给教育相关领域提供了一个有效的应用产品。
关键词:requests框架 网络爬虫 GUI界面编程 Python
中图分类号:TP391 文献标识码:A文章编号:1672-3791(2021)06(a)-0004-03
Design and Research of Word Translator Based on Web Crawler
ZHOU Youyu SUN Hongbo MEI Liangcai*
(Beijing Institute of Technology, Zhuhai, Zhuhai, Guangdong Province, 519088 China)
Absrtact: This paper presents the design and research flow of a word translator based on the web crawler technology in machine learning. Firstly, this paper crawled Iciba website, compiled directional page requests crawler through early url analysis, compiled the directed page requests crawler, got the word definition and example sentences. Secondly, through a general program framework for querying words, write requests directional crawler to obtain the latest word interpretation and example sentences in real time. Finally, a GUI form interface is designed to show the relevant results, which has good practicability and effectiveness. The research method proposed in this paper is an extension of the research field related to machine learning, and the research results provide an effective application product for the field related to education.
Key Words: Requests framework; Web crawler; GUI interface programming; Python
网络爬虫是从互联网搜集数据的一种工具,众多学者利用网络爬虫获取研究数据[1]。机器学习是一种从现有数据中找到数据特征之间变化规律的一门科学,学者们在翻译器设计、数据预测等多种交叉领域都用到了机器学习方法[2-4]。另外,市场上大多数查询单词App的桌面版功能都不够方便快捷,基于此现状,该文主要基于以下任务来设计单词查询App。
(1)对于网页架构的前期url分析,找到相应的单词释义和例句。
(2)对于html框架中的具体label中的内容进行编程设计爬取。
(3)设计GUI界面进行单词释义和例句的展示。
1 包的安装与描述
因为要GUI界面编程和网络爬虫,因此需要下列包。
from PyQt5 import QtCore, QtGui, QtWidgets
from bs4 import BeautifulSoup
from PyQt5.QtCore import QRect
import requests
from PyQt5.QtWidgets.
import QApplication,QWidget
import sys
import trans
2 爬虫解决过程
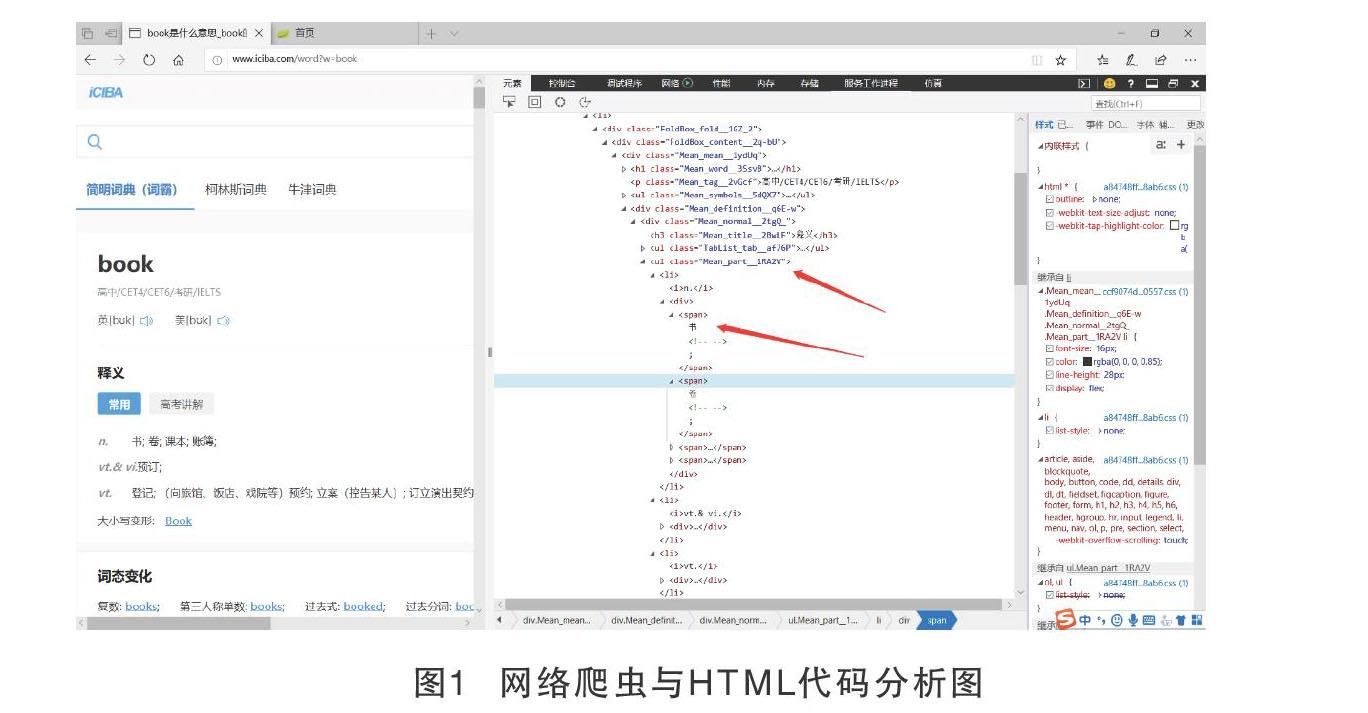
Iciba的域名为http://www.iciba.com/,在域名后加word?w=,再加入所要搜索的单词,如book。显示出如下网址:http://www.iciba.com/word?w=book,即可完成搜索,url见图1。
由图1可知,单词释义都在class=Mean_part_1RA2V的ul标签下,每一个li标签里带有一行释义;li标签下的i标签带有此行释义的词性,span标签为汉语解释。同理,例句在 class = NormalSentence_sentence_3q5Wk的div標签下。三个p标签分别为英语例句、汉语翻译、出处。
至此,筆者写出爬虫的主要框架具体如下所示。
r = requests.get(url)
try:
soup = BeautifulSoup(r.text,'html.parser')
meaning = soup.find('ul',class_='Mean_part_1RA2V').children
for li in meaning:
text += li.i.string
text+=' '
for span in li.div.children:
text+=span.text
text+=' '
text+='\n'
text+='\n例句:\n'
for div in soup.findAll('div',class_='NormalSentence_sentence_3q5Wk')[:9]:
ps = div.children
i=0
for p in ps:
if i == 2:
break
text += p.text
text+='\n'
i+=1
text+='\n'
self.label.setText(text)
except:
self.label.setText('搜索失败')
利用try-except语句用一些乱七八糟搜索的过滤。
3 GUI界面解决过程
GUI界面能很直观地展示搜集结果,是展示网络爬虫数据的好工具[5-6]。利用类的定义和使用的方法,笔者根据官网例子写出的GUI如下所示。
from PyQt5 import QtCore, QtGui, QtWidgets
from bs4 import BeautifulSoup
from PyQt5.QtCore import QRect
import requests
class Ui_Form(object):
def setupUi(self, Form):
Form.setObjectName("Form")
Form.resize(412, 800)
self.Buttons = QtWidgets.QPushButton(Form)
self.Buttons.setGeometry(QtCore.QRect(300, 10, 93, 28))
self.Buttons.setObjectName("Buttons")
self.lineEdit = QtWidgets.QLineEdit(Form)
self.lineEdit.setGeometry(QtCore.QRect(10, 10, 271, 31))
self.lineEdit.setObjectName("lineEdit")
self.label = QtWidgets.QLabel(Form)
self.label.setGeometry(QtCore.QRect(10, 50, 381, 711))
self.label.setText("")
self.label.setObjectName("label")
self.label.setGeometry(QRect(10, 50, 381, 711))
self.label.setWordWrap(True)
self.label.setAlignment(QtCore.Qt.AlignTop)
self.Buttons.clicked.connect(self.sOnClicked)
self.retranslateUi(Form)
QtCore.QMetaObject.connectSlotsByName(Form)
def sOnClicked(self):
text = '释义:\n'
url_root = 'http://www.iciba.com/word?w='
url = url_root+self.lineEdit.text()
r = requests.get(url)
try:
soup = BeautifulSoup(r.text,'html.parser')
meaning = soup.find('ul',class_='Mean_part_1RA2V').children
for li in meaning:
text += li.i.string
text+=' '
for span in li.div.children:
text+=span.text
text+=' '
text+='\n'
text+='\n例句:\n'
for div in soup.findAll('div',class_='NormalSentence_sentence_3q5Wk')[:9]:
ps = div.children
i=0
for p in ps:
if i == 2:
break
text += p.text
text+='\n'
i+=1
text+='\n'
self.label.setText(text)
except:
self.label.setText('搜索失敗')
def retranslateUi(self, Form):
_translate = QtCore.QCoreApplication.translate
Form.setWindowTitle(_translate("Form", "Form"))
self.Buttons.setText(_translate("Form", "搜词"))
4 总结与评价
(1)创新点。运用的GUI界面编程,程序有了界面可以和用户互动;根据网络爬虫可快速制作出编译器,无需自己的词典库;界面自适应,长出界面的词句会自动换行;词性、释义、例句,一应俱全。
(2)不足和改进。查询需要联网,没有自己的数据备份。
该款App可以用于日常英语学习,随时查询,没有多余功能,程序小巧,查询到的释义例句齐全。
参考文献
[1] 朱策,徐宏,林新,等.基于网络爬虫的能源政策监测[J].科技创新导报,2019,16(35):141-142.
[2] 杨浩波.神经机器翻译关键技术研究与应用[D].成都:电子科技大学,2020.
[3] 梁娟.英语翻译器语音识别系统的设计及功能实现[J].微型电脑应用,2018,34(12):46-48.
[4] 季春元,熊泽金,侯艳芳,等.基于人机交互的网络化智能翻译系统设计[J].自动化与仪器仪表,2019(8):25-28.
[5] 刘江,刘国玺,张雁,等.基于多线程和翻译的网络爬虫鸟类音频数据采集系统设计与实现[J].现代计算机,2018(30):85-88,92.
[6] 明日科技.Python从入门到精通[M].北京:清华大学出版社,2018.
