基于宏微观因素的概率级别的车辆事故预测
2021-09-13张力天孔嘉漪樊一航范灵俊包尔固德
张力天 孔嘉漪 樊一航 范灵俊 包尔固德
1(北京交通大学软件学院 北京 100044) 2(中国科学院计算技术研究所信息技术战略研究中心 北京 100190) 3(贵阳市大数据产业集团有限公司 贵阳 550081)
现阶段,驾车出行已经变成人们日常生活中的一部分.车辆给人们的生活带来了很多便利,但也带来了很多交通安全隐患.根据美国国家公路交通安全管理局(National Highway Traffic Safety Admini-stration,NHTSA)发布的《机动车碰撞概述》,美国每分钟大约发生10起车辆事故,每3分钟就有1人因车辆事故而丧生[1].根据世界卫生组织2018年发表的《全球道路安全状况报告》,全球有超过135万人死于道路车辆事故.车辆事故问题已经变成世界关注的焦点问题.预防车辆事故的方法有很多,政策方面包括提高驾驶员的安全意识、加大处罚力度和更新交通系统设备,而技术方面主要是在事故发生前预测事故并通知警示驾驶员.
在事故预测中,获取车辆事故数据是很重要的环节.在以往的研究中,这些数据集包含宏观因素[2-4]或微观因素[5-8].宏观因素包括地理情况(如公路和街道)、环境情况(如湿度和能见度)和交通情况(如交通速度和密度).这些包含宏观因素的数据集通常是从当地交通部门收集到的,例如RCP(part of the Ministry of Justice and Public Order of the Republic of Cyprus),CIAIR(Center for Integrated Acoustic Information Research),SPD(Seattle Police Department)数据集[9-11].微观因素包括事故发生前的车辆行为(如速度和加速度)和驾驶员行为(如眼动和手势).这些数据集通常使用驾驶模拟器收集,例如STSIM,SCANeR,VANET数据集[7,9].在以往的研究中,大部分数据集只包含宏观或微观其中一种因素.究其原因,是宏观因素和微观因素难以同时收集.然而,车辆事故往往是两者共同作用的结果[1].虽然Gite和Agrawal使用了2类因素的数据进行事故预测,但数据集包含的特征数量非常少[5].
事故预测的另一重要环节是用算法处理数据,而当前有很多种预测车辆事故的方法.在深度学习出现之前,人们通常使用神经网络[10,12-14]或统计方法,如条件logistic模型等[15-18].目前,很多研究者使用LSTM处理时间序列事故数据[5],或使用CNN和DNN处理非时间序列数据[2,4,19],来预测驾驶员的危险行为或者预测出事故发生的时间和地点.因为收集到的数据中没有可以用于预测的事故发生概率标签,以往的研究通常只是计算出一个0/1二分类预测结果,即仅仅判断事故能否发生,但这样的结果不够实用,驾驶员更希望得到的是不同级别的危险预警信号[20].如果可以预测出事故概率值,就能更好地满足驾驶员的需求.
2019年发布的事故宏观因素数据集OSU(Ohio State University)与宏观因素数据集FARS(fatality analysis reporting system)和微观因素数据集SHRP2(strategic highway research program 2)都具有一些相同的特征,为它们的融合提供了机遇[21-22].因此在本研究中,我们首先得到了一个同时包含宏观和微观因素的数据集.对于正样本数据,我们融合了包含宏观因素的OSU和FARS数据集,以及包含微观因素且与SHRP2分布相同的Sim-SHRP2(simulated strategic highway research program 2)数据集.而负样本数据,则是在美国加利福尼亚州和华盛顿州自行驾驶汽车收集而来的.此外,融合后的数据集只包含事故是否发生的0/1标签而不包含事故发生的概率标签,所以我们还设计了一个深度学习框架来预测车辆事故发生的准确概率值.该框架参考了Zhang等人[23]提出的算法,是一个无监督的深度学习框架,但是它可以使用迭代的方式为数据集生成准确的概率标签,并使用这些概率标签来进行训练.由于时间和资金的限制,负样本数据量约为正样本数据量的1/5,所以在该框架中,我们使用了deep-SVDD算法,该算法能够很好地解决数据不均衡的问题[24].
综上所述,本文的贡献主要在实际应用上,解决了2个问题:1)车辆事故是宏观因素和微观因素共同作用的结果[1],但是因为宏微观因素难以同时收集,所以以往的大部分车辆事故数据集只包含宏观或微观其中一种因素.针对这一问题,我们融合了2019年发布的事故宏观因素数据集OSU与宏观因素数据集FARS和微观因素数据集SHRP2,得到了包括宏微观因素的数据集.2)不同层级的事故发生概率的预警可以有效地避免交通事故,并且也符合驾驶员的需求[20],但是因为收集的数据集中没有可以用于预测事故发生概率的标签,所以以往的大部分研究只得到事故是否发生的二分类结果.针对这一问题,我们设计了一个概率级别的无监督深度学习框架,使用迭代的方式为数据集生成准确的概率标签,并使用这些概率标签来进行训练,从而可以预测出准确的事故发生概率值.
1 方法和数据
1.1 总体介绍
为了得到完整而足量的训练数据,我们首先融合了3个包含正样本的车辆事故数据集,然后将它们与一个包含负样本的安全驾驶数据集相结合,最终获得了可用于训练的完整数据集.正样本的3个数据集分别是OSU,FARS,Sim-SHRP2,其中前2个数据集包含事故的宏观因素,后一个包含事故的微观因素.OSU数据集是从俄亥俄州立大学收集的涵盖美国49个州的全国性车辆事故集合,其中包含车辆事故的地理情况和环境情况相关特征.FARS数据集是在美国进行的全国性年度事故普查的数据,其中包含交通情况相关特征.Sim-SHRP2数据集也是美国的全国性事故统计,其中包含车辆事故中的车辆行为和驾驶员行为相关特征.负样本数据集则是我们与腾讯自动驾驶组人员合作,驾驶配备有各类传感器的汽车在加利福尼亚州和华盛顿州收集到的.数据融合过程如图1所示:
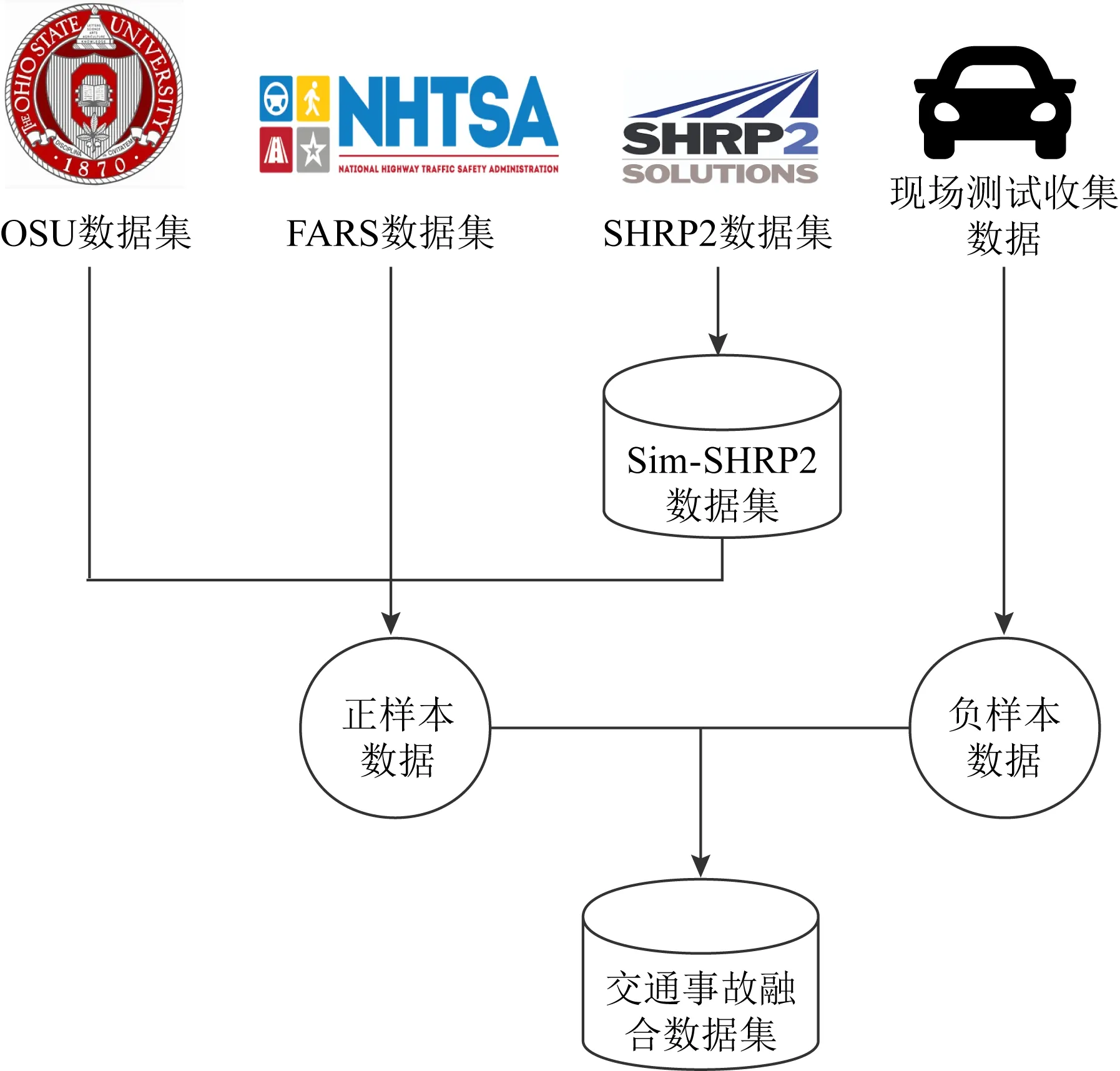
Fig.1 Illustration of data fusion process图1 数据融合流程示意图
在构建好包含正负样本的具有多个特征的数据集后,我们将数据输入深度学习框架中,首先通过无监督算法生成粗糙概率标签,然后使用粗糙的标签迭代地训练深度学习算法,得到更准确的标签,再用所得到的标签进行训练.框架主要分为3步:
1)使用无监督的机器学习算法对数据进行预处理,生成粗略的概率标签;
2)使用有粗糙概率标签的数据训练有监督的深度学习算法;
3)使用训练后的深度学习算法进一步处理数据,使生成的概率标签更准确.
步骤2)和步骤3)不断迭代进行,直到深度学习算法得到充分训练为止.
因为训练数据只包含事故发生的0/1标签,并不包含我们所需要的概率标签,所以我们以迭代的方式逐渐得到准确的概率标签.在本文中,选择的无监督机器学习算法是k-means聚类算法和autoencoder自编码器,而有监督的深度学习算法是一种修改的deep-SVDD算法.原始的deep-SVDD算法为无监督算法,但是可以通过修改损失函数,改为有监督算法.我们选用无监督deep-SVDD算法并把它修改为监督学习算法,主要是因为训练数据的正负样本不均衡,而deep-SVDD算法可以很好地处理这样的数据.尽管训练数据可以通过多次迭代逐渐获得准确的概率标签,但是在迭代初期的概率标签比较粗略,也比较适合修改为监督算法的无监督学习,而不是一般的监督算法.整体框架如图2所示.值得说明的是,尽管该框架为训练数据生成了概率标签,并且使用修改的deep-SVDD算法进行了监督学习,但是它使用的训练数据与k-means,autoencoder和原始的deep-SVDD算法一样,都是没有概率标签的数据,所以是概率级别的无监督学习框架.

Fig.2 Illustration of the deep learning framework process图2 深度学习框架流程示意图
1.2 事故预测数据收集与融合
1.2.1 正样本数据融合
OSU数据集由事故发生的地理情况(如“经纬度”和“所在州”)、时间、环境情况(如“降雨量”和“能见度”)等相关特征构成;FARS数据集由地理情况、时间、事故严重程度、环境情况、交通情况(如“周边是否有校车”和“周边是否有行人”)等相关特征构成;SHRP2数据集由地理情况、时间、事故严重程度、车辆行为(如“是否超速”和“是否变道”)、驾驶员行为(如“是否系安全带”和“是否打瞌睡”)等相关特征构成.尽管FARS数据集也包含少量驾驶员行为相关特征,但是远不如SHRP2数据集全面.我们运行程序来融合OSU,FARS,Sim-SHRP2数据集,该程序包括融合数据集和剔除无效数据项等功能.首先,我们根据不同数据集的相同特征来融合数据集.OSU和FARS数据集的融合方式为,如果2个事故分别来自于OSU和FARS数据集,并且它们的经纬度距离之差小于500 m,时间之差小于30 min,那么我们就将其视为同一起事故,合并相应的数据项.OSU和Sim-SHRP2数据集的融合方式为,如果2个事故分别来自于OSU和Sim-SHRP2数据集,并且它们的州、其他地理情况(如“是否靠近学校”和“是否靠近交叉路口”等)、时间和事故严重程度完全相同,那么我们就将其视为同一起事故,合并相应的数据项.之后,我们根据相关和相似特征来剔除无效数据项,这些相关和相似特征如OSU数据集中的“降雨量”特征和FARS数据集中的“地面湿度”特征,以及FARS数据集中的“事故前驾驶员行为”特征和Sim-SHRP2数据集中的“驾驶员是否分心”特征等.如果某一合并数据项的相关和相似特征不一致,我们就将其视为无效数据并加以剔除.这些不一致一般是因为数据记录时的偏差引起的.其中,对于Sim-SHRP2数据集,原始SHRP2数据集无法免费下载,但是官方网站提供了所有特征的概率分布,所以我们根据其提供的概率分布模拟了Sim-SHRP2数据集.融合后的数据集包含约850 000个具有97个特征的数据项,这些特征分为5个不同类别,分别是:地理情况、环境情况、交通情况、车辆行为和驾驶员行为.
1.2.2 负样本数据收集
为了收集负样本数据,我们使用行车记录仪(Garmin VIRB Ultra 30)、车辆传感器(iVICAR)和视频记录仪(iPhone 11),驾驶汽车(Toyota RAV4)在加利福尼亚州、华盛顿州和周边的多个场景下采集负样本数据.这些场景互不相同,覆盖了特征的多种组合.行车记录仪记录地理情况、环境情况和交通情况,而视频记录仪记录驾驶员行为,采集到的视频通过手动分析来进一步提取特征.车辆传感器则可以自动记录车辆行为特征,其截图如图3所示.由于时间和资金的限制,收集的负样本数据集包含约170 000个样本,约占正样本数据集的1/5.

Fig.3 Snapshot of the car sensor图3 车辆传感器截图
1.3 基于k-means和autoencoder粗略概率标签生成
我们使用无监督机器学习方法来为训练数据集计算粗略的概率标签.根据Zhang等人[23]所述,这里应当使用至少2种无监督机器学习方法来保证结果的准确度,所以本项目同时使用了k-means算法和autoencoder.k-means算法可以将样本划分为k个聚类,使得彼此接近的样本分到同一聚类之中.在本项目中,k-means算法会使训练数据集聚集为2个类:聚类1主要包含正样本数据,聚类0则主要包含剩余的负样本数据.在得到这2个聚类后,需要把每个样本到聚类中心的余弦距离归一化到[0,1]之间,然后可以求得样本i的粗略概率标签
其中di是归一化后的距离.也就是说,对于正样本,距离聚类中心的距离越近,发生车辆事故的概率越大;而对于负样本,距离聚类中心的距离越近,发生车辆事故的概率越小.autoencoder是一种可以学习无标签训练样本编解码过程的神经网络.本项目中,autoencoder使用正样本进行训练,这样当输入正样本时,输出的解码数据与原数据差别较小,而输入为负样本时,输出的解码数据与原数据差别较大,就可以对正负样本加以区分[25].每个样本与其解码样本余弦距离的归一化值取负加1,即是它粗略的概率标签.无论是k-means算法还是autoencoder算法,都难以直接求得准确的概率标签,所以如Zhang等人[23]所述,我们对k-means算法和autoencoder算法的结果和原始0/1标签求平均值,这样所得的结果更加准确,可以取得更好的训练效果.
1.4 用于监督学习的修改的deep-SVDD算法
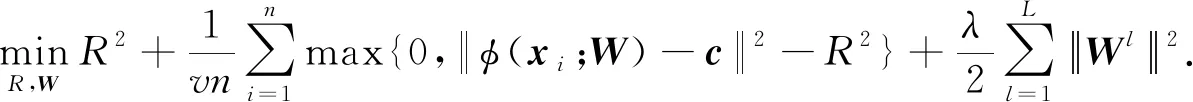
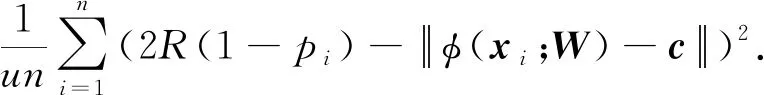
1.5 修改deep-SVDD算法的迭代训练
1.4节介绍了对原始deep-SVDD算法的修改,而本节介绍对修改deep-SVDD算法的迭代训练过程.我们使用得到的粗略标签训练修改的deep-SVDD算法.由于标签较为粗糙,损失函数项的超参数u需要设置为较大值.修改的deep-SVDD算法的训练过程与原始deep-SVDD算法一样,首先固定超球面半径R,使用随机梯度下降法优化网络权重W,然后再固定W,使用线性搜索优化R,这一过程反复进行多次,直到收敛为止.修改的deep-SVDD算法在训练之后,就可以为训练数据计算新的概率标签,而这些新的概率标签与先前计算的粗略概率标签融合,就可以得到具有更准确概率标签训练数据集(如1.3节所述).
接下来,我们使用这些更准确的概率标签,再次训练修改的deep-SVDD算法.由于标签比之前更准确,损失函数项的超参数u需要适当调小.经过训练的deep-SVDD算法再次为训练数据集计算概率标签,并将结果与先前计算的概率标签进行融合.这个过程持续进行多次,用于训练的概率标签会越来越准确,deep-SVDD算法也会被训练得越来越充分,进而算法的预测准确度也会越来越高.
1.6 框架参数设置
对于autoencoder,我们为编码设置了3个隐藏层,分别包含128,74,32个节点,为解码设置了3个隐藏层,分别包含32,74,128个节点,并让它以30期(epoch),256批次(batch)进行训练.deep-SVDD算法具有10层的CNN,每层包含128个节点,以4期256批次反复迭代训练,学习率为0.000 5.
2 实验设置和结果
2.1 实验设置
为了评测本项目所提出框架的性能,我们首先将整体的事故数据集分为2部分:训练数据集和测试数据集.训练数据集的数据量占整个数据集的80%,而测试数据集是舍弃额外正样本数据而剩下的正负样本平衡数据,占整个数据集的20%.首先,我们测试了不同参数下该框架的性能表现,包括网络层数(1~20)、迭代次数(1~8)和学习率(0.000 01~0.001)参数.该实验可以验证1.6节所述参数设置的可行性.此外,我们还测试了不同迭代次数下(1~8)训练数据标签生成结果的准确性.该实验可以证明该框架可以得到准确的训练数据标签,进而得到高质量的训练结果.此外,该框架是概率级别的无监督学习框架,但是在0/1级别上使用了原始的0/1标签是监督学习框架,并且训练数据集的正负样本不平衡,所以我们将该框架的性能与监督的不平衡二分类算法CCNN(cost-sensitive CNN)和CDNN(cost-sensitive DNN)进行了比较[26].同时,该框架对原始的deep-SVDD算法做了修改,所以我们也和原始deep-SVDD算法进行了比较.为得到概率级别的结果,CCNN算法和CDNN算法直接使用输出层的分类概率,而deep-SVDD算法计算样本到超球面中心的余弦距离并进行归一化.该实验可以证明该框架优于现有算法.实验在具有4个GPU节点、67 000个CUDA内核和128 GB内存的高性能计算集群上部署进行,所有算法都使用Python和Tensorflow1.12.0深度学习框架实现.
2.2 评测指标
我们分别在0/1级别和概率级别对本项目所提出框架进行了评测.
对于0/1级别,我们将预测概率值<0.5的值算作0,≥0.5的值算作1,然后将它们与测试数据集中的0/1标签进行比较.因此,评测指标为:
1)真阳性样本量(TP).TP是正确预测的正样本数,即算法预测发生且实际也发生的事故数量.
2)假阳性样本量(FP).FP是错误预测的正样本数,即算法预测发生但实际未发生的事故数量.
3)真阴性样本量(TN).TN是正确预测的负样本数,即算法预测未发生且实际未发生的事故数量.
4)假阴性样本量(FN).FN是错误预测的负样本数,即算法预测未发生但实际发生的事故数量.
5)召回率(Recall).Recall=TP/(TP+FN).
6)精确率(Precision).Precision=TP/(TP+FP).
7)准确率(Accuracy).Accuracy=(TP+TN)/(TP+FP+TN+FN).
8)F值(F-score).F-score=2Recall×Precision/(Recall+Precision).
对于概率级别的数值,我们应该将预测概率值(或生成的训练数据标签)与实际概率值进行比较,但是数据集中没有任何概率标签.因此,将该框架预测概率值(或生成的训练数据标签)与k-means算法、autoencoder进行比较,相同结果越多,表明该框架的召回率和准确率越高,评测指标为:
1)IK是与k-means算法相同的结果数量;
2)IA是与autoencoder相同的结果数量;
3)IB是与k-means算法和autoencoder都相同的结果数量.
2.3 不同参数实验结果
2.3.1 不同隐藏层数的比较
表1给出了不同隐藏层数时,本项目所提出框架在0/1级别上的结果.当隐藏层数小于10时,该框架具有相对较小的召回率;而当数目增加到10以上时,该框架具有相对较高且稳定的召回率、精确率和准确率.
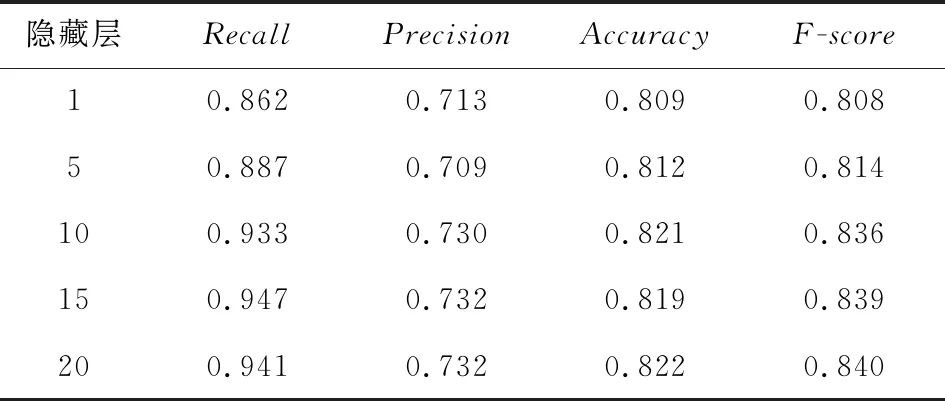
Table 1 0/1-Level Results with Various Numbers of Hidden Layers表1 不同数量隐藏层的0/1级别结果
表2给出了不同隐藏层数时,本项目所提出框架在概率级别上的结果.类似地,当隐藏层数小于10时,该框架具有相对较小的IK,IA,IB值;而当数目增加到10及以上时,该框架具有较高且较平稳的IK,IA,IB值.因此,如1.6节所述,隐藏层的数量为10是一个合理的参数选择.
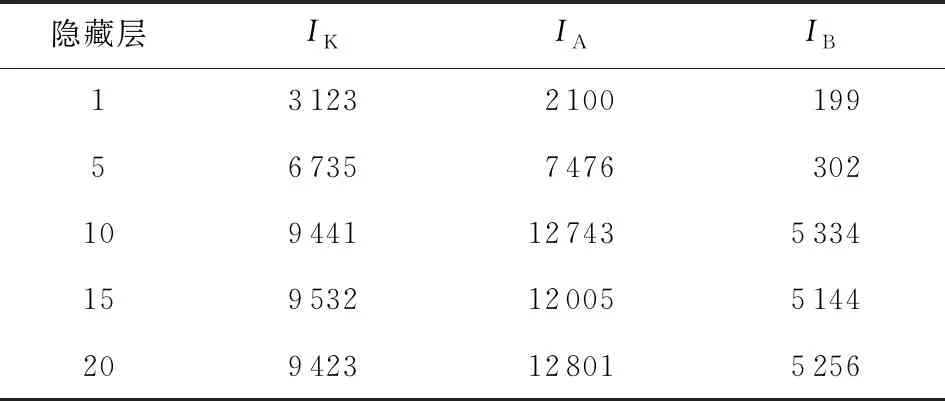
Table 2 Probability-Level Results with Various Numbers of Hidden Layers表2 不同数量隐藏层的概率级别结果
2.3.2 不同迭代次数的比较
表3给出了在不同迭代次数下,本项目所提出框架在概率级别上的结果.在迭代次数低于4时,该框架具有相对较小的IK,IA,IB值,而当迭代次数增加到4及以上时,该框架具有较高且较平稳的IK,IA,IB值.因此,如1.6节所述,迭代次数为4是一个合理的参数选择.
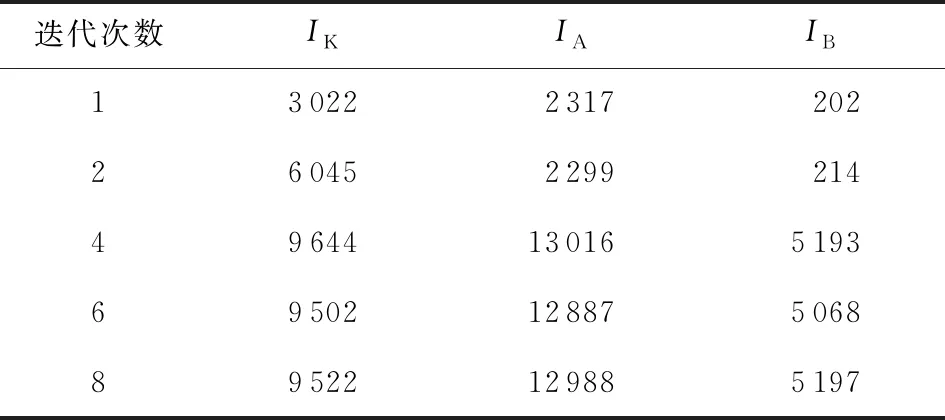
Table 3 Probability-Level Results with Various Numbers of Iterations 表3 不同迭代次数的概率级别结果
因为在不同迭代次数下,本项目所提出框架在0/1级别上的结果与其他算法相比没有太大差异,所以没有直接给出.这表明在训练时,该框架在0/1级别收敛时,可能并没有在概率级别收敛,所以概率级别的研究是非常有必要的.
2.3.3 不同学习率的比较
除了0/1级别和概率级别的结果外,图4给出了在不同学习率下,损失函数数值随着训练批次增加的变化趋势.当学习率低于0.000 5时,损失函数值下降缓慢;当学习率增加到0.000 5以上后,损失函数值下降迅速,但是较高的学习率会导致损失函数值的频繁波动.因此,如1.6节所述,学习率为0.000 5是一个可行的相对最优参数.
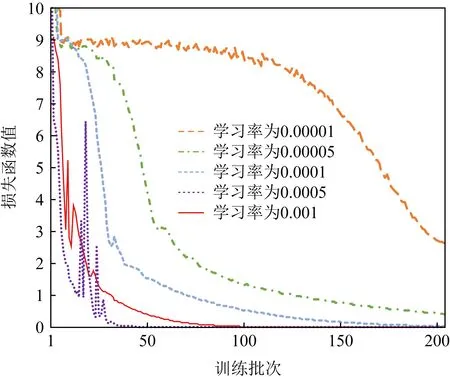
Fig.4 Decrease of loss with various learning rates图4 不同学习率的损失值下降情况
2.3.4 训练数据标签生成结果
不同迭代次数下训练数据的标签生成结果与2.3.2节相似.在迭代次数低于4时,该框架具有相对较小的IK,IA,IB值;而当迭代次数增加到4及以上时,该框架具有较高且较平稳的IK,IA,IB值.第8次循环后,IK,IA,IB值分别可达9 522,12 988,5 197.因此,该框架可以得到准确的训练数据标签,进而得到高质量的训练结果.
2.4 算法比较实验结果
表4给出了本项目所提出框架与CDNN算法、CCNN算法和原始deep-SVDD算法的0/1级别的结果.这些方法都具有较高的真阳性样本量,但是相比CDNN算法,CCNN算法、deep-SVDD算法和该框架具有更高的真阴性样本量和更低的假阳性样本量.除此之外,这些方法都具有相近的召回率,但是CCNN算法、deep-SVDD算法和该框架都具有更高的精确率、准确率和F值.图5给出了CDNN算法、CCNN算法、原始的deep-SVDD算法和本项目所提出框架的ROC曲线.CCNN算法、deep-SVDD算法和该框架的AUC值高于CDNN算法.

Table 4 0/1-Lvel Comparison Results to Different Methods表4 不同方法的0/1级别结果
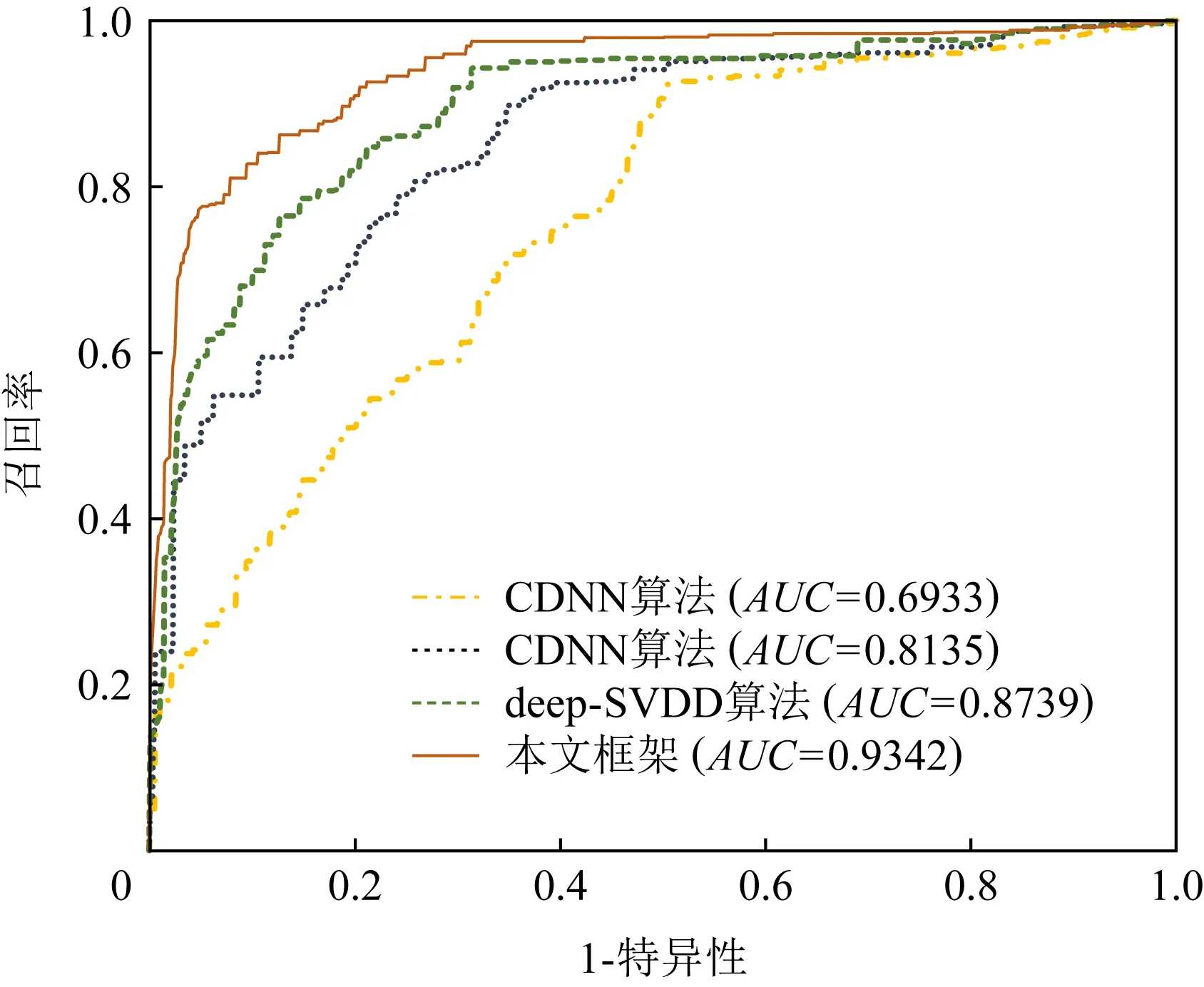
Fig.5 ROC curves of the different methods图5 不同方法的ROC曲线
图6用韦恩图给出了本文所提出框架与CDNN算法、CCNN算法和原始deep-SVDD算法概率级别的结果.与其他算法相比,该框架与k-means算法和autoencoder都具有更多相同的概率值.也就是说,该框架可以计算出更准确的概率值.特别地,尽管CCNN算法、deep-SVDD算法和该框架在0/1类级别上的性能相似,但是该框架在概率级别上要优于CCNN算法和deep-SVDD算法.
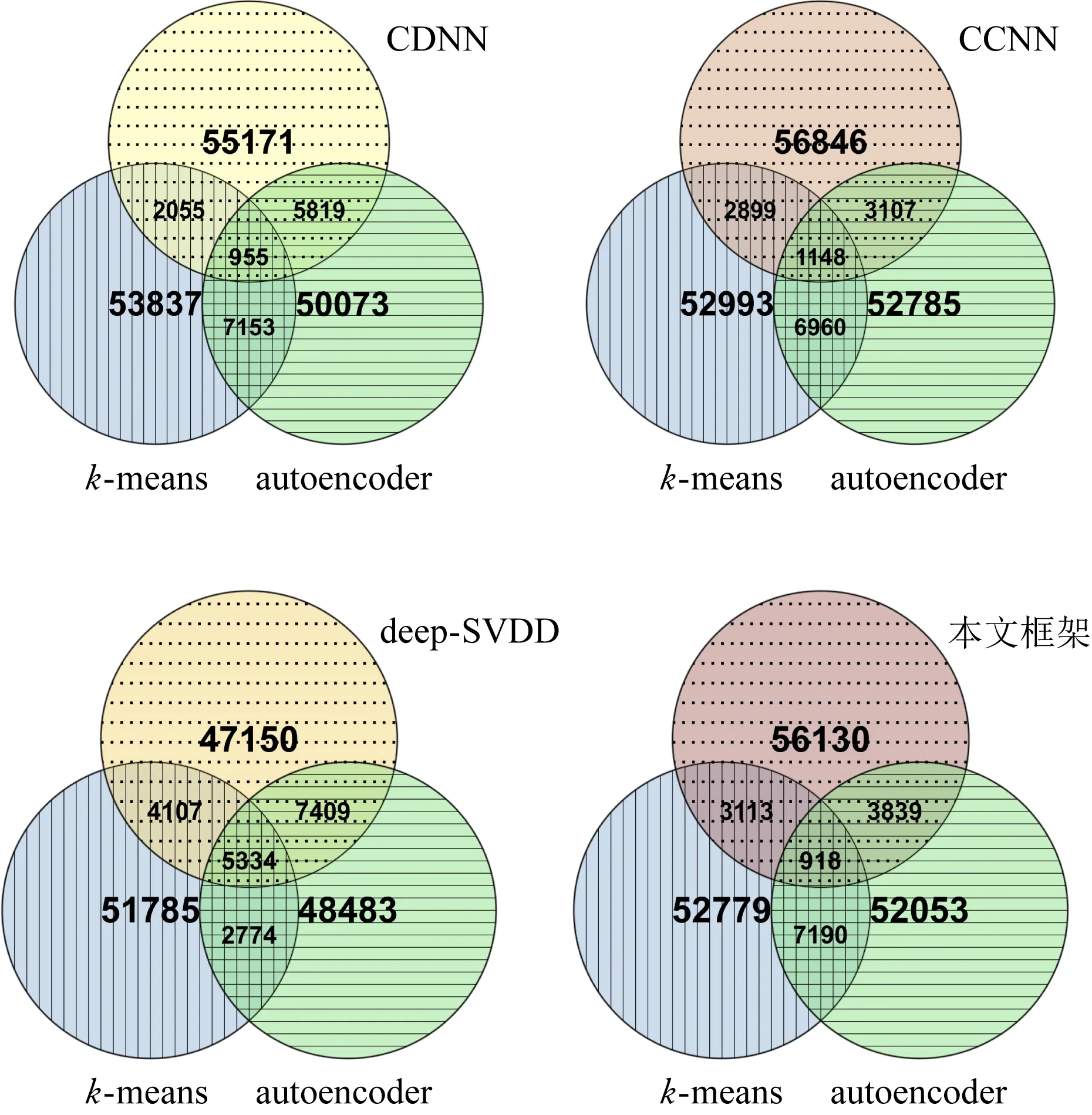
Fig.6 Venn diagrams of prediction results among the different algorithms图6 不同算法的预测结果韦恩图
3 总结与展望
本文首先通过融合OSU,FARS数据集,SHRP2数据集分布相同的Sim-SHRP2,以及自己驾驶汽车,得到了一个完整的车辆事故数据集.此外,我们还设计了一个概率级别的无监督深度学习框架来预测事故发生的准确概率值.该框架使用迭代的方式为数据集生成准确的概率标签,并使用这些概率标签来进行训练.我们分别在事故发生的0/1级别和概率级别上对该框架进行了评测,实验结果表明,该框架可以使用所得到的数据集来灵敏而准确地预测车辆事故.以该框架为基础,可以构建为车辆驾驶员提供不同级别事故预警的软件.
之后,我们将把这项工作与目标检测的识别方法相结合,使得车内设备可以自动、实时地获取交通标志[27]、地理情况、环境情况、交通情况和驾驶员行为等特征,进而构建最终的事故预警软件.
