基于分布式并行计算的铁路电子支付平台对账业务数据处理方案研究
2021-09-11郝雅青甘人才
王 宁,郝雅青,甘人才
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
铁路电子支付平台(简称:支付平台)承载着铁路客、货运输的电子支付和对账结算业务。自2010年投入运行以来,随着客、货运业务量的增长和业务种类的增多,交易量从最初日均100万笔提升至日均千万笔,对账处理效率较低的问题日渐凸显。同时,随着二维码扫码支付、铁路e卡通等多种新型支付的增加,对账业务和资金核算逻辑更为复杂,对支付平台对账业务与资金核算的灵活性和扩展性也提出更高要求。
为此,研究提出基于分布式并行计算架构的对账业务数据处理方案,对支付平台的对账与资金核算业务数据处理过程进行技术升级改造,将各接入渠道业务系统、支付机构、支付平台三方与对账相关的数据均汇集到Hadoop平台中,采用Spark、Kafka等组件搭建分布式并行计算环境,用于完成对账和资金核算的数据处理任务;通过敏捷查询引擎(AQE,Agile Query Engine),Hadoop数据可以通过JDBC和REST等多种方式,提供给电子支付管理平台,支持后续的交易查询、报表统计、偏差处理等业务;并在实验室搭建测试环境,对该数据处理方案进行测试验证。
1 铁路电子支付平台对账业务及数据处理要求
1.1 对账和资金核算业务流程
支付平台对账和资金核算功能主要完成各类交易信息的汇总、核对、差异处理、资金报表生成等业务处理[1],主要业务流程如图1所示。
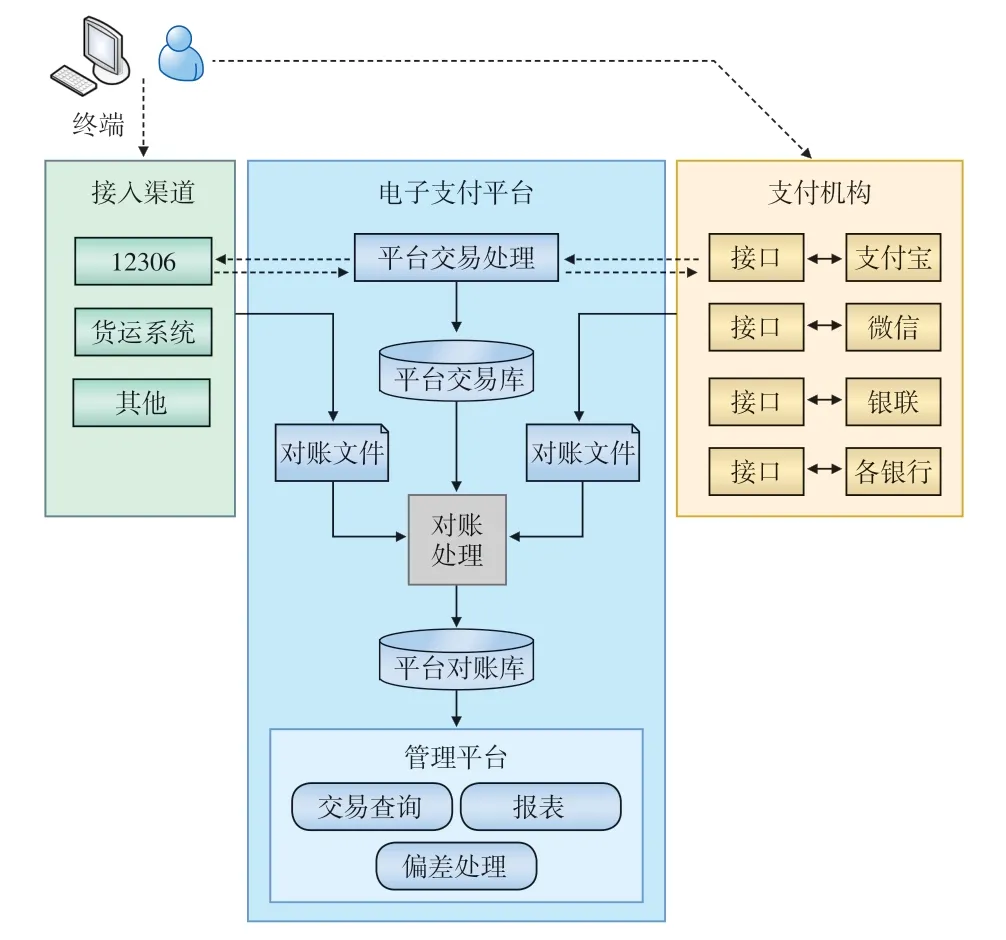
图1 支付平台对账与资金核算业务流程示意
1.1.1 接入渠道
接入渠道是指为铁路客户提供客货业务服务的各类业务系统,如铁路12306互联网售票系统(简称:12306)、铁路货运电子商务系统(简称:货运系统);各接入渠道业务系统在执行交易时,可通过接口将交易信息发送至支付平台。
1.1.2 支付机构
铁路客户在办理铁路客、货运业务时,可选用不同支付机构的支付服务,各个支付机构通过接口向支付平台提供交易接入服务。
1.1.3 支付平台
支付平台主要完成交易处理、对账、交易查询、偏差处理、报表统计等功能,对账业务主要流程如下:
(1)对账文件入库:各接入渠道业务系统在约定的时间将固定格式的对账文件传输至支付平台的文件服务器,文件服务器上的程序自动检查对账文件格式和数据的正确性,将正确的对账文件数据写入数据库;若有对账文件存在异常,则给出提示,以转由相关业务人员进行人工处理;
(2)对账处理:支付平台每日自动执行对账处理,按照设定的规则,将各接入渠道业务系统的数据与支付平台的数据、各支付机构的数据与支付平台的数据,分别进行逐笔交易两两对比核查;核对的数据项主要包括交易流水号、交易金额、交易状态、交易时间等;
(3)对账结果处理:对账结果分为对账成功、单边交易账、金额不一致等类型;对于单边交易账和金额不一致的交易数据,按系统设置的审核规则进行数据偏差审核,判定是否需要给客户退款;对于无法自动完成审核的交易数据,由业务人员手工处理[2];
(4)资金核算:资金核算处理程序每月对各接入渠道业务系统的当月结账资金、支付平台记录的当月资金、支付机构的当月资金进行核对,资金核算结果包括月切交易数据、单边交易数据、交易类型对比核查;通过资金核对,找出存在资金差异的交易数不一致数据、金额不一致数据等类型;业务人员将依据资金核算结果,进行欠款追款、调账等多种处理;
(5)报表统计与资金上缴:根据交易处理、对账、资金核算分类处理,支付平台统计生成业务数据汇总、银行数据汇总、平台数据汇总、电子支付日报、资金差异明细表等多种业务报表和资金报表,业务人员依据相关报表进行资金上缴[3]。
1.2 对账业务数据处理要求
(1)数据处理量及性能要求
支付平台需要对账的交易数据来自多个接入渠道业务系统和10多家支付机构。对账业务处理是逐日滚动执行的,考虑到接入支付平台的不同来源交易数据可能存在一定时间延迟,为保证每日数据核对的有效性,每日执行对账处理时一般对连续5天(即T-2、T-1、T、T+1、T+2)的交易数据进行核对;目前,每日对账处理的交易数据记录约为2亿条,对账处理全流程耗时应少于2 h。
(2)可扩展性
随着支付平台可支持的支付方式日益多样化,以及所接入的支付机构和各接入渠道业务系统的不断增加,对账处理应能快速、灵活地适应数据源增加和接口类型增多。
2 基于分布式并行计算架构的对账业务数据处理方案
基于分布式并行计算架构的对账业务数据处理方案的逻辑框架如图2所示。
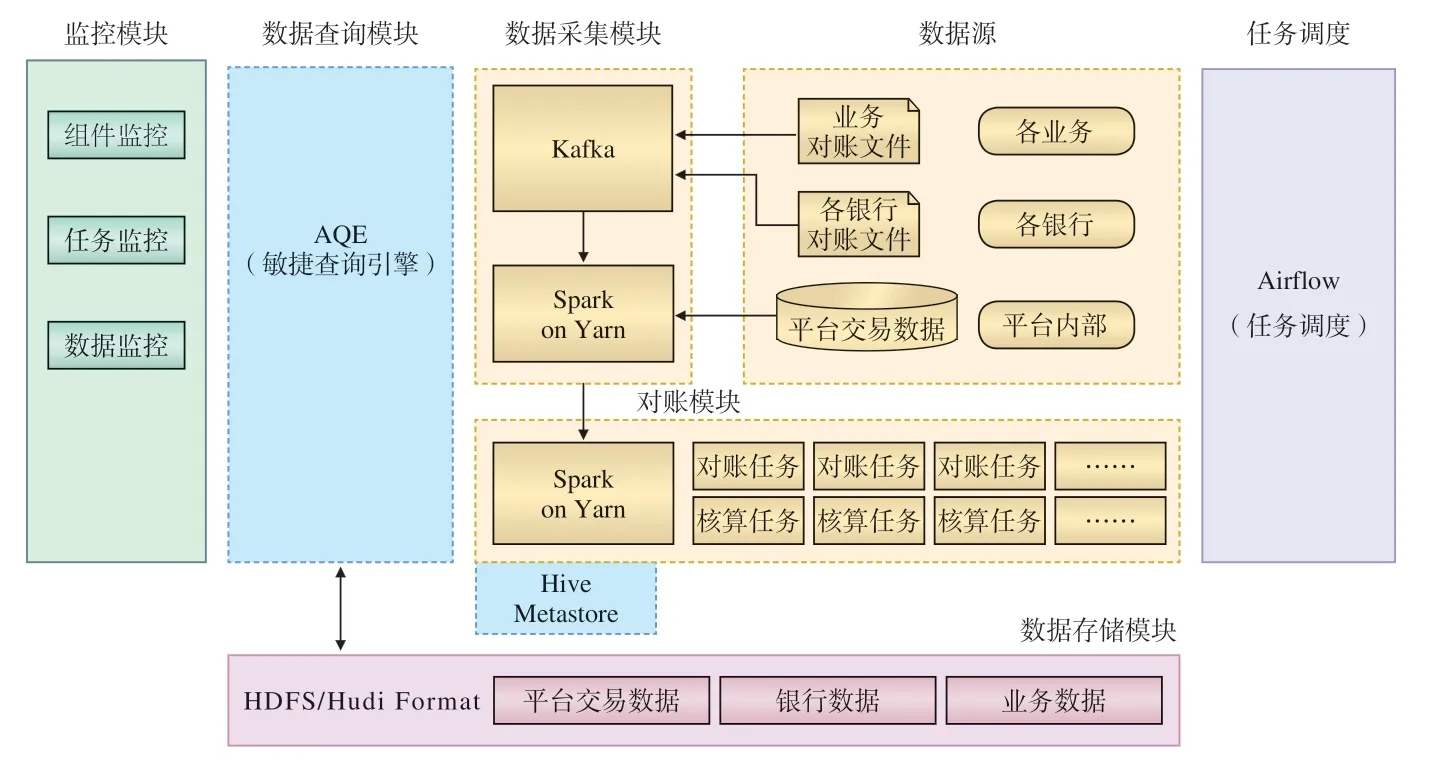
图2 对账业务数据处理方案的逻辑框架示意
支付平台对账业务的数据处理主要包括:数据采集模块、对账模块、数据存储模块、数据查询模块等功能模块,以及运行监控和任务调度等辅助管理模块。
2.1 数据采集模块
各接入渠道业务系统的对账文件,经解析代码处理为结构化数据,并存储到高性能消息中间件Kafka;采用Spark Streaming组件定期从Kafka拉取数据,然后存储在分布式文件系统HDFS中,这些数据为待对账数据;增量数据采用Hudi组件,实现数据增量更新、数据版本管理和数据痕迹追踪。
2.2 数据存储模块
待对账数据和对账结果数据均存储在分布式文件系统HDFS中,采用Hudi组件可构建和管理PB级数据,为各类业务提供高效和低延迟的数据连接,支持文件级、记录级的插入、删除、更新操作,可按时间版本查询数据,有效地改善存储管理和查询性能。
对账业务数据处理按日进行,各接入渠道业务数据、支付平台交易数据、各支付机构数据均按日期分区存储,并进行数据分片。
2.3 对账模块
对账逻辑程序采用Spark 批处理完成,Spark 运行在Hadoop Yarn上,由Yarn管理Spark集群,负责资源统一管理,任务调度与监控。
为充分利用Spark的并行计算能力,按照处理数据分片规则,将当天对账数据进行分类后,再行执行对账逻辑计算,可显著提高计算效率。
2.4 数据查询模块
AQE作为数据查询核心组件,将存储在HDFS中的数据暴露为JDBC接口或者REST接口,为其它业务系统提供数据查询服务。
2.5 任务调度
为了便于日常运行维护,采用Airflow平台完成任务调度和监控;每日定时运行对账处理逻辑代码,可查看任务执行历史,对任务执行异常进行提示与警告。
2.6 监控模块
监控模块主要有3类监控对象:服务器和组件、对账任务、对账数据。
(1)服务器和组件:实时监控虚拟机的CPU、内存等使用情况;采集服务器级别的告警信息;实时监控Kafka、Spark、Hadoop、Airflow 等组件的运行情况。
(2)对账任务监控:监控Kafka写入Hadoop的实时流任务和对账任务的运行情况;监控定时任务是否成功执行。
(3)对账数据监控:监控Kafka写入Hadoop的数据量、监控所采集的数据量;监控当日各接入渠道数据同步的完成情况;监控对账处理完成情况、对账相符数据量、对账差异数据量、退款对账数据量等业务数据。
3 关键技术
3.1 分布式数据计算
分布式通用数据计算引擎Spark是专为大规模数据快速处理而设计的通用计算引擎[4],基于类Hadoop MapReduce的开源通用并行框架,但不同于MapReduce的是,计算任务的中间结果可保存于内存中,无需读写HDFS。Spark能够提供交互式数据处理,还可以优化迭代工作负载,适用于数据挖掘与机器学习等需要迭代的MapReduce算法,常用于构建大型的低延迟数据处理应用[5]。
支付平台对账处理采用Spark计算框架,将对账数据加载到内存中,并采用Spark分片和多任务并行计算方式,能够极大地提升对账处理效率。
3.2 分布式文件系统HDFS
分布式文件系统HDFS基于流数据模式,可运行于廉价服务器[6],具有高容错、高可靠性、高可扩展性、高可用性、高吞吐率等特性[7],且安装和维护简单。采用分布式文件系统HDFS存储和管理海量结构化分析型数据,能够以较低的成本实现安全、可靠的数据存储,并保证数据存储规模具有良好的持续扩展性。
采用分布式文件系统HDFS存储支付平台的对账业务数据,解决了关系型数据库因读写磁盘速率低造成的数据读写速度慢的问题,提高了数据处理吞吐率。HDFS提供的数据分片存储方式,也为支持未来业务数据量的持续增长提供保障。
3.3 分布式消息中间件
Kafka是一种高吞吐量的分布式发布订阅消息系统,可提供高吞吐、低延迟的实时数据处理平台[8]。其持久化层是一个按照分布式事务架构的大规模发布/订阅消息队列,常作为企业消息总线、实时数据管道,主要起到削峰填谷、系统解耦以及冗余的作用。
采用Kafka消息中间件实现支付平台对账业务的数据采集,提升了数据采集环节的效率和弹性,可为数据处理提供缓冲池,以避免对账业务数据处理程中各环节间互相影响。
3.4 分布式查询引擎
AQE是基于Apache Arrows内存列式存储的大数据查询引擎,采用MPP技术,能接入HDFS、Hive、Kafka、RDBMS等多种外部数据源,支持JDBC、ODBC、Rest的查询接口和基于Arrow Flight的查询API接口,支持异构数据源的混合查询计算[9]。AQE使用物化视图和SQL重写技术,实现查询性能优化和提升。
采用AQE查询引擎实现支付平台对账业务数据处理的查询功能,可将多种数据源的访问进行统一封装和优化,为前端业务功能提供统一、高效的查询接口。
4 测试及验证
4.1 测试环境
为验证基于分布式并行计算架构的对账业务数据处理方案的有效性,在实验室搭建对账业务数据处理的测试环境,如图3所示。
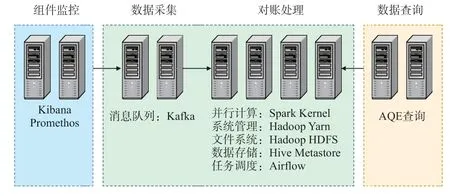
图3 对账业务数据处理的测试环境构成示意
组件监控:由2台服务器部署相应监控程序组成,负责监控测试环境中相关资源的运行情况。
数据采集和对账处理:消息队列Kafka功能相对独立,由2台服务器组成;并行计算Spark、系统管理Yarn、文件系统Hadoop、数据存储Hive、任务调度Airflow 等组件部署在4台服务器上,构成对账数据处理运行环境。
数据查询:AQE部署在2台服务器上,通过外部接口调用数据存储完成数据查询。
4.2 主要测试项目
(1)对账数据采集:将现有数据转储至大数据平台中,包括各接入渠道、支付机构和支付平台的交易数据,为后续对账处理准备好测试数据集。
(2)对账处理:采用Spark多任务并行计算进行对账处理,将对账结果存放在Hive库中。
(3)对账结果查询:通过AQE提供的JDBC接口和REST接口,按多种条件快速、灵活的查询对账数据。
4.3 测试结果比对
采用分布式并行计算架构后,相较于原来基于Oracle关系型数据库存储的运行环境,技术升级改造前后对账业务数据处理测试项目指标对比见表1。

表1 技术升级改造前后测试项目指标对比
(1)数据采集:采用Spark和Kafka相结合的数据采集处理方式,速度提高近4.5倍。此外,相对于现有系统完全基于数据库的处理方式,采用Spark和Kafka组件采集数据,还能减轻数据库负载,测试过程中数据库服务器CPU监测指标表明,可释放出约30%资源能力。
(2)对账计算:采用Spark并行任务进行基于内存的分布式计算,数据处理速度提升达十倍量级。
(3)对账结果查询:在现有Oracle关系型数据库中,采用按时间分区存储方案,查询跨分区数据时,需进行全表扫描,数据读取耗时较长,一般查询响应时间约15 s。基于AQE进行查询时,可自动根据分区条件确定数据查询范围,无需全表扫描,平均查询响应时间约300 ms;且数据量越大,查询速度差距越明显。另外,Oracle关系型数据库仅提供基于JDBC接口的SQL查询方式,而AQE查询可提供多种类型的数据源访问接口,还可提供REST接口,能够支持更为灵活的查询需求。
5 结束语
针对铁路电子支付平台对账处理面临的问题,分析现有对账业务数据处理流程及性能要求,研究分布式并行计算相关的关键技术,提出基于Hadoop、Spark等技术的分布式并行计算方案;设计了数据采集、对账、数据查询等业务处理模块,以及数据存储、任务调度和运行监控等辅助管理模块;在实验室搭建测试环境,对测试数据集进行处理。测试表明:该方案可显著提高对账核算业务处理效率,增强支付平台对业务需求灵活支撑的能力。
该方案中所使用的相关组件多为开源技术,若要投入实际运用,如何有效确保其稳定可靠运行,需要尽一步开展深入研究。
