一种基于控制流解耦的可重构阵列动态调度方法
2021-09-11景乃锋
尹 琛,彭 飞,景乃锋
(1.上海交通大学 电子信息与电气工程学院,上海 200240;2.上海航天电子技术研究所,上海 201109)
0 引言
粗粒度可 重构阵列(Coarse-Grained Reconfigurable Array,CGRA)由于兼具通用计算的灵活性和专用计算的高效性,被广泛运用在特定领域中。整个阵列由大量执行单元(Processing Element,PE)以数据流驱动的模式执行操作。PE 之间通过软流水的执行模式实现操作,一旦输入数据有效,PE 便可以并行执行,这种计算方式极大地提高了阵列的计算吞吐率。
随着可重构阵列的应用范围扩大,当采用传统的直接调度方案,将整个数据流图(Data Flow Graph,DFG)同时映射时,会因控制流的非一致性导致处于不同控制体的数据流无法同时并行执行,进而引起阵列计算单元利用率下降的问题。常见的非一致性控制流有非完美循环、分支以及循环依赖等。针对非完美循环,可以通过循环交换和循环展开,对内层循环体和外层循环体进行重新组织,但并没有解决执行外层循环PE 利用率低的问题[1-4];针对分支,通过将不同分支上的指令合并映射到同一PE 上以提高PE 利用率,但这种方法不适用于路径长度差异较大的非平衡分支[5-6];针对循环依赖,通过利用线程间通信挖掘细粒度的数据并行,但是会引入额外的硬件开销[7-8]。此外,现有的数据流调度方法都只针对其中某一种非一致性控制流进行调度优化,无法同时支持上述3 种情形。
针对上述问题,本文提出了一种基于控制流解耦的可重构阵列映射方法。如图1 所示,通过将原始DFG 中的数据流按照不同的控制流边界解耦成若干个相互独立的数据流子图(Sub-DFG),各个解耦后的子图可以独立执行,因此,可以通过循环完全展开的方式尽可能地利用计算资源。同时通过交替执行不同的子图,以完成整个应用的操作。借助这种控制流解耦的调度方法,在阵列总面积开销相同的条件下,相比于静态调度的CGRA[9]和完全指令驱动的CGRA[10],本方法可以分别提高35%和18%的执行性能,同时提升27%和45%的计算能效比。

图1 控制流解耦调度方法的基本示意图Fig.1 Basic schematic diagram of the control flow decoupling and scheduling method
1 非一致性控制流分析
本章如图2 所示,将对3 种常见的非一致性控制流的执行特点进行分析,并阐述这种非一致性在软流水执行模式下对阵列性能的影响。
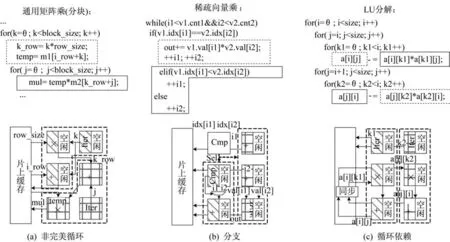
图2 3 种典型的非一致性控制流Fig.2 Three typical inconsistent control flows
图2(a)以通用矩阵乘该应用为例,对非完美循环进行阐述。图2(a)上方代码,内层循环体(实线框所示)每执行block_size次,外层循环体(虚线框所示)才执行一次;由于非完美循环中内外层循环的触发频率不同,导致执行外层循环的PE(斜线阴影所示)大部分时间处于空闲状态,因此,会降低PE 利用率。
图2(b)以稀疏向量乘该应用为例,对分支执行进行阐述。图2(b)上方代码,if 分支和else 分支会根据分支的判断条件选择性执行,不会同时执行。图2(b)下图,执行if 分支的PE(斜线阴影所示)和执行else 分支的PE(格子阴影所示)在任意时刻都必定有一方处于空闲状态。因此,同样会降低PE 利用率。
图2(c)以LU 分解为例,对循环依赖进行阐述。图2(c)上方代码,具有数据依赖的执行体(虚线框和实线框所示)无法同时并行执行。图2(c)下图,执行这2 块区域的PE(斜线阴影和格子阴影)会交替处于空闲状态,进而会降低PE 的利用率。
以上3 种非一致性控制流都会将原始的DFG分割成具有不同控制语义的区域。在软流水的执行模式下,这些区域内的数据流无法并行执行,因此,会显著降低阵列中计算单元的利用效率,进而影响阵列的执行性能。
2 基于控制流解耦的调度方案及硬件架构设计
针对以上问题,本文提出了一种基于控制流解耦的调度方案。在软件调度上,将原始的DFG按照不同的控制流边界分割成若干个相互独立的子图,子图间可以并行展开执行。在硬件结构上,本文提出了一种动态子图调度器,可以根据数据流的执行情况,切换阵列当前所执行的子图配置。同时,本文在传统的PE 内部增加了一个配置切换单元,以支持软流水执行模式下子图配置的动态切换。
2.1 基于子图分割的控制流解耦
调度方法的整体示意图如图1 所示,相比于现有的调度方法,将程序中所有的控制流区域同时映射在整个阵列上,将不同的控制流区域解耦成若干个子图,并将每个子图经过充分循环展开后独立映射在整个阵列上。通过交替执行所有的子图,以实现子图间的解耦调度,消除子图间由于非一致性控制流造成的性能损失。如图3 所示,将对图1 中的3 个例子分别进行详细阐述。
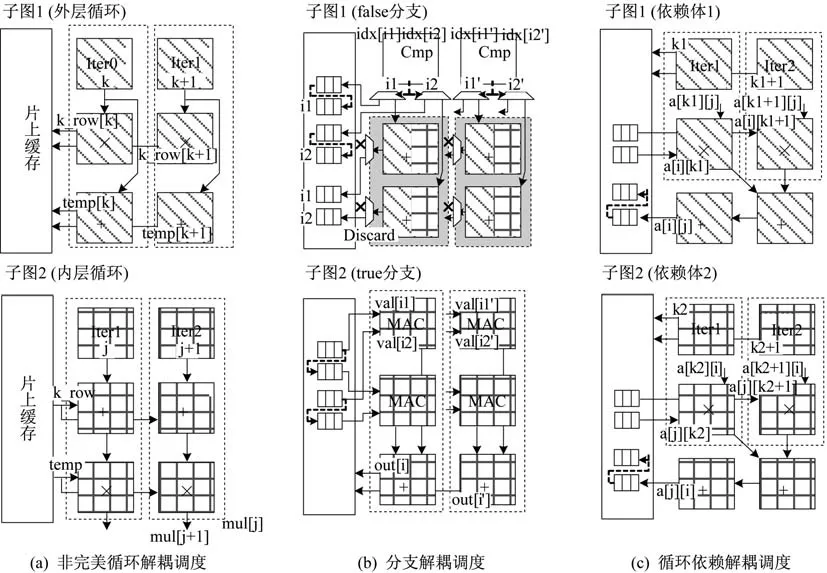
图3 基于控制流解耦的调度方法Fig.3 Mapping with control flow decoupling
图3(a)阐述的是针对非完美循环的控制流解耦调度。首先,将外层循环(子图1)在整个阵列上循环展开2 次并行执行,如图3(a)两个虚线框所示,并将中间数据k_row[]和temp[]存入片上缓存的相应区域。当片上缓存的相应区域存满之后,再切换阵列配置执行内层循环(子图2),并从缓存中读出之前存入的中间数据k_row[]和temp[]。通过交替执行子图1 和子图2,实现控制流解耦。
图3(b)阐述的是针对分支的控制流解耦调度。首先,执行所有的分支判断条件,将执行false 分支的中间变量(i1,i2)和执行true 分支的中间变量(i1,i2)分别存在片上缓存的相应区域。之后将false 分支(子图1)在阵列上并行展开2 次同时执行,如图3(b)中2 个虚线框所示;当false 分支全部执行完后,或片上缓存中存放false 分支中间数据的相应区域满后,再切换阵列配置执行true 分支(子图2)。同样,2 个子图交替执行,实现控制流解耦。
图3(c)阐述的是循环依赖解耦调度。与上述2种解耦类似,通过分别执行具有数据依赖关系的2 个子图,实现控制流解耦。同样,在执行单个子图时,对其进行充分的循环展开以尽可能利用片上资源。
2.2 子图动态调度器
为支持上述子图间的动态调度,本文设计了一个子图调度器,如图4 所示。由于每个子图执行所需要的数据和产生的中间数据都存放在片上缓存相应的子存储器(bank)内。因此,如果当前子图已经消耗完对应bank 中所有的数据或者产生的中间数据已经将对应bank 放满,则需要结束当前子图,切换为下一个子图。此时,子图调度器会根据当前存储器中bank 的状态,通过子图检测电路判断出当前每个子图的状态,然后,通过优先编码器从已经准备就绪的子图中,动态选出一个作为接下来要执行的子图,并将该子图的ID 绑定在数据流上,发送给阵列。
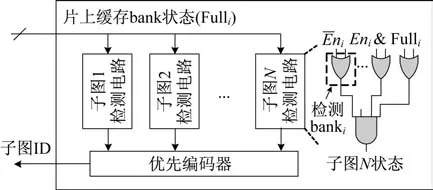
图4 子图动态调度器硬件结构Fig.4 Structure of the dynamical scheduler of a subgraph
2.3 支持子图切换的PE 单元设计
为支持上述子图配置的动态切换,在现有的PE结构中增加一个配置切换单元,如图5 所示。配置切换单元中会记录当前子图ID,并同时监测每个周期携带在输入数据上的子图ID。当输入数据上的子图ID 和记录的子图ID 不同时,将触发配置切换,同时更新当前记录的子图ID。配置单元会根据新子图ID 从配置缓存器中读出相应的一个新配置,并通过配置更新电路逐级改变PE 的配置信息,其中包括输入数据选择器(Mux)、输出数据选择器(Demux)和算术逻辑单元(Arithmetic and Logic Unit,ALU)配置。

图5 支持子图切换的PE 内部结构Fig.5 Inner structure of PE with subgraph switching
按上述方式,PE 内部的配置信息可以随数据流逐级切换。对于PE 内部的某一流水级而言,在当前周期完成子图配置更新后,在下一周期即可执行更新后的子图所对应的数据流。因此,可以避免现有的动态配置切换技术中,由于在流水线中引入气泡所导致的流水线停顿现象[11]。
3 实验结果与分析
3.1 实验设置
从3 种专用加速器领域广泛使用的测试集中选择了多个含非一致性控制流的代表性应用,见表1。

表1 用于进行评估对比的测试应用Tab.1 Workloads for evaluation
为了对比分析,本文选用了2 种典型的CGRA结构,2 种结构分别是完全静态配置的Plasticine[9]和指令调度的TIA[10]。为了公平比较,本文将通过对3 种架构设定不同的阵列大小,使其具有相同的阵列面积,其中,3 种架构的具体配置参数见表2。
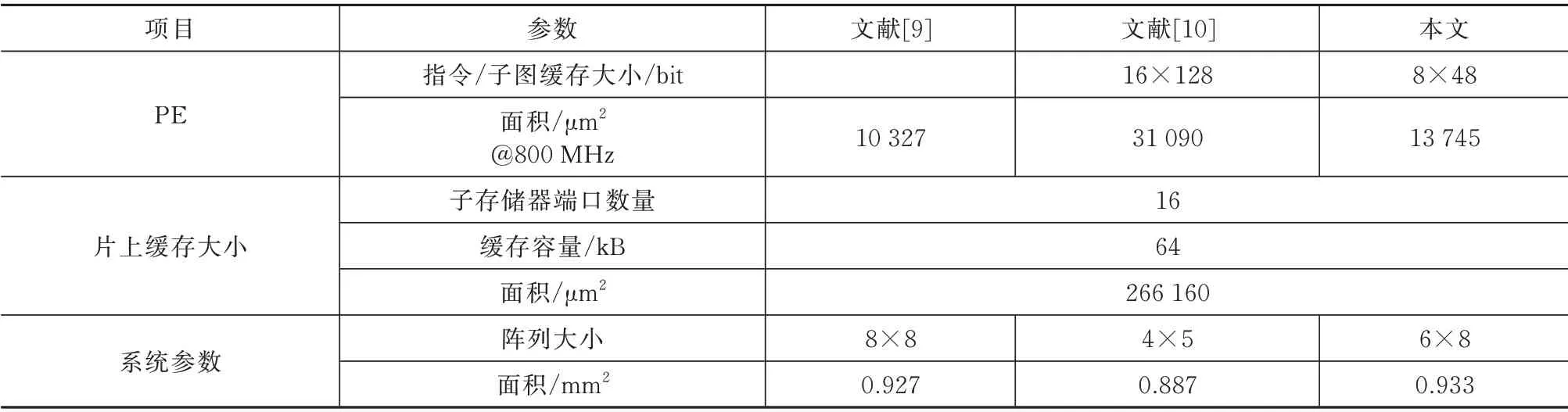
表2 架构参数设定Tab.2 Architecture parameter setting
性能评估方面,采用的试验平台是基于C++编写的系统级模拟器。模拟器含周期精确的PE 阵列和64 kB 片上缓存,同时使用了周期精确的DRAMSim2 仿真器[15]对内存延迟和带宽进行评估。对于Plasticine[9]和TIA[10]2 种结构,通过提供的开源实例进行了行为级建模。此外,选用了一种灵活的片上存储模型Buffets[16]作为3 种架构的片上访存接口。面积评估方面,本文通过Synopsys 的Design Compiler 在40 nm 工艺库下对3 种架构的硬件实现进行综合,设定时钟约束都为800 MHz。同时,通过Synopsys PrimeTime 对3 种架构的功耗进行评估。
3.2 性能和PE 利用率评估
3 种架构的性能和PE 利用率如图6 所示。其中,当子图个数为m,第i个子图执行的周期数为Ti,有效映射PE 数量为Ni,周期t时刻处于激活状态的PE 数量为nt时,PE 利用率为

图6 3 种架构间PE 利用率(散点图)和性能加速比(柱状图)的对比(以文献[9]为基准)Fig.6 Comparison of PE utilization ratio(in marker)and performance acceleration ratio(in bar)among three architectures normalized to Plasticine[9]
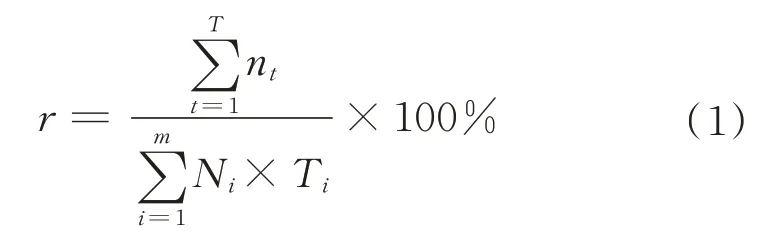
式中:r为PE 利用率。
对于包含非完美循环的应用,如GEMM 通用矩阵乘、Viterbi 动态规划和Gesummv 而言,外层循环所占比例和内层循环相当,完全静态调度的Plasticine 中几乎有50%的PE 处于闲置状态。TIA 和本文提出的设计可以分别通过灵活的指令和子图级别的调度,将PE 利用率提升到80%左右。本文的设计相比Plasticine 取得了约为1.3 倍的加速比,而TIA 由于指令缓存的面积消耗,因此,阵列规模要小得多,平均性能只有Plasticine 的0.8 倍。
对于包含分支的应用,如Sort 排序算法、FFT傅里叶变换和HotSpot 检测算法,由于有大量的elseif分支,因 此,Plasticine中的PE 利用率大大降低。而TIA 通过位于不同分支路径的指令合并映射到同一个PE 上,因此,提高了PE 利用率,并相比Plasticine 性能上取得了1.2 倍的加速比。而本文的设计通过控制流解耦,取得了1.3 倍的加速比。
对于存在循环依赖的应用,如LU 分解、GE 高斯消元和Cholesky 分解,Plasticine 中显式的数据同步降低PE 利用率到约45%左右。而TIA 和本文的设计通过指令和子图级的调度方式,取得了75%的PE 利用率。
3.3 执行能效评估
上述3 种架构的执行能效比如图7 所示。

图7 3 种架构间的执行能效对比[9]Fig.7 Comparison of energy efficiency among three architectures normalized to Plasticine[9]
图中,尽管TIA 取得了相对较高的PE 利用率和性能,但是细粒度的指令调度显著增大了执行的能耗。因此,对于大部分应用,其在能效比方面均要低于Plasticine。而本文的设计,通过高效的子图粒度的解耦和重调度,在大多数应用中取得了较高的能效比。而对于HotSpot 检测和CFD 流体动力学这类应用,由于频繁的子图切换,各个子图执行过程中的中间数据需要暂存在片上缓存中,因此,会增加片上缓存的访问次数,进而导致额外的能耗增加。
4 结束语
针对应用中出现的非一致性控制流,本文提出了一种基于控制流解耦的调度方案。通过将处于不同控制流边界下的数据流解耦成多个可独立执行的子图,每个子图可以在阵列上充分展开以提高阵列的计算利用率。实验结果表明:相比于传统的直接映射方法,本方案可以通过在典型的PE 内部增加轻量化的调度单元,进而提高可重构阵列的资源利用率和执行性能。
