异构计算并行编程模型综述
2021-09-11邬江兴祁晓峰高彦钊
邬江兴,祁晓峰,高彦钊
(中国人民解放军战略支援部队信息工程大学信息技术研究所,河南郑州 450000)
0 引言
科研工程等领域的应用对计算能力(简称算力)的需求越来越大。例如在深度学习模型中,计算系统处理的计算任务呈现出网络规模庞大、问题复杂、需求多样等特征。回顾微处理器发展历史,如图1 所示,在20 世纪80 年代,通过指令集、编译优化、超标量、多级缓存推动了计算性能的提升;90 年代,通过提高时钟频率,使计算系统的单线程性能提升,但功耗随之增加;21 世纪以来,对多核并行计算的研究逐渐增多,直至当前,摩尔定律逐渐失效。JOHN 等[1]在ISCA 2018 中指出,单核处理器性能提升的幅度已经缩小至每年只增加3%,高性能计算需要计算体系结构的创新。

图1 48 年微处理器发展趋势[2]Fig.1 48 years of microprocessor trend data[2]
计算体系结构创新的内涵有两个方面:其一是规模,即由单核转向多核并行计算。传统的高性能计算研究聚焦在单核性能上,当前则是依靠多核集群,集中分布式算力,通过规模化效应提升算力。其二是架构,如中央处理器(Center Process Unit,CPU)、图像处理器(Graph Process Unit,GPU)和可编程门阵列(Field Program Gate Array,FPGA)等计算器件均有各自擅长的处理领域,按照一定组织方式组成多核异构的系统。每种计算器件有各自计算存储模型,不同计算器件的组合使得系统具有异构性。目前,混合两种及两种以上计算器件的多核异构芯片、系统、集群都已经出现。研究人员试图组合不同的计算器件,从性能、功耗等方面的需求出发,通过新型计算体系架构将硬件性能发挥到极致。
异构计算器件组合可以满足多样化的计算任务需求。但是,器件集成在同一系统并不意味着算力相加。如图2 所示异构系统中,包含不同计算器件,但是各个计算器件的计算、存储和连接等均有独立标准,异构器件之间的任务划分、调度、通信、存储、同步等机制的不同为系统管理带来新的问题。若不解决这些问题,异构系统难以发挥其理论上的性能和能耗优势,异构特征反而会成为系统负担。
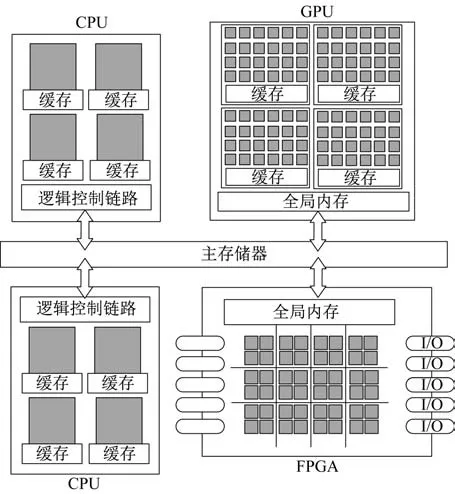
图2 异构计算系统抽象表示Fig.2 Abstraction architecture of heterogeneous computing system
解决该问题的难度体现在开发者既要具备丰富的硬件架构知识,又要熟悉各种软件优化方法。对开发者而言,易用的软硬件协同编程工具和自动优化功能是异构计算编程追求的目标。因此,对异构并行编程模型及运行优化的研究是异构并行系统研究的重要内容。本文回顾和梳理异构系统并行编程最新成果,介绍了代表性异构编程模型,研究了异构编程模型优化方法,讨论了异构并行计算的关键问题,最后对异构计算体系架构的研究方向进行总结。
1 异构并行编程模型
异构并行编程模型把底层硬件抽象表示,提供统一编程接口,解决异构系统并行计算、存储、通信等一系列问题。文献[3]介绍了主流的异构并行编程模型,例如,OpenCL[4]、CUDA[5]等。早期编程模型接口相对低级,开发者需大量手工操作实现细节优化,这不仅增加编程难度导致较低开发效率,也会导致适用性差、易出错等问题。文献[6]总结了各种异构系统编程模型的接口分类,补充许多实验室异构编程模型项目,例如,Merge[7]、C++AMP[8]、Lime[9]、Copperhead[10]、Grag[11]等。这些编程模型的出现一定程度上克服了CUDA、OpenCL等编程模型的缺点。
分析现有异构并行编程模型优化研究,可分为两种:一种从硬件底层优化出发,针对特定异构架构设计编程模型;另一种是基于现有编程框架改进或扩展,通过封装编程接口降低编程难度,提高现有异构编程框架的可用性。
1.1 显式异构编程模型
多数异构编程模型针对特定架构,例如CPU+GPGPU 的架构。异构系统处理任务划分、调度、通信、同步等问题,对应大量的编程接口。异构编程模型以显式编程形式实现异构系统优化,代表性的编程模型有OpenCL、CUDA。它们采用Host/Device 的分工形式,Host运行CPU的控制代码,Device 运行加速设备的代码,如图3 和图4所示。

图3 OpenCL 编程模型Fig.3 OpenCL programming model

图4 CUDA 编程模型Fig.4 CUDA programming model
CUDA 和OpenCL 的编程接口偏底层,因此,其对开发能力要求高,并且对并行程序的分析和验证比较困难。因此,对显式编程模型的优化研究是将复杂的编程接口简化,构建结构化的编程框架。例如,文献[12]使用脚本语言和OpenCL设计结构化的并行编程框架,通过脚本调用OpenCL 接口控制任务。文献[13]提出一种结合OpenCL 和CUDA 的接口库HCLOOC,解决计算核心和多核通用CPU 之间通信链路有限带宽的约束问题。HCLOOC 库包含调用各类计算硬件的基本模块,支持OpenCL 命令队列、任务卸载、复制和执行CUDA 流等功能。
1.2 制导式编程模型
制导式编程模型(pragma)方法在源代码上以注释的形式,告诉编译器并行代码区域的位置,如何在代码的不同部分访问变量以及如何在同步点执行。编译器根据制导语句生成代码、执行代码段、传输数据和执行同步操作。生成代码通过调用运行时系统管理硬件资源以及跨不同内存层级传输数据。代表性的制导式异构编程模型包括OpenACC[14]、OpenMP[15]、OpenHMPP[16]等。
对制导式异构编程模型研究主要是基于内存的优化。例如,文献[17]提出了一个基于OpenMP开发的工具包HyCOMP,工具包模拟分布式CPU和GPU 上的虚拟共享内存空间,分布式共享内存系统可以有效防止GPU 在处理主机到设备内存拷贝过程中,因大量页错误而导致的性能下降。制导式异构编程模型简化了异构并行编程的难度,并对优化异构系统性能起到显著作用。
2 异构编程模型的优化
2.1 异构编程中间表示
在生成执行机器码过程中,运行时系统优化代码操作能够有效提高系统性能,即中间表示(Intermediate Representation,IR)技术。HAS[18]、ROCm[19]、CUDAPTX[5]、SPIR[20]等都是专门为异构体系结构设计的IR。
HSA 是由HSA 基金会开发的异构体系结构规范,HSA 定义了中间语言HSAIL(HSA Intermediate Language),包括对异常、虚拟函数和系统的调用。AMD 基于HSA 和HSAIL 开发了ROCm,针对OpenCL 和CUDA程序进行编译。CUDA PTX 是NVIDIA 为CUDA 程序开发的中间表示。CUDA编译器将CUDA 代码转换为PTX IR,但仅适用于NVIDIA 系列的GPU。SPIR 是一种基于LLVMIR 的二进制中间语言,用于图形计算和内核计算。LLVM 可以作为多种语言编译器的后台来使用,将代码编译成多种不同硬件架构的指令集。
2.2 异构编程语言接口
开发者希望使用易于理解的高级语言实现抽象编程语言到底层框架的映射,多数研究以此为目标优化异构编程框架。异构编程语言可分为非托管式的和托管式的。
非托管编程语言指可以直接处理内存的编程语言。并行编程框架采用非托管式语言,因为它能为系统提供更高性能。文献[21-25]使用类C 语言,设计高层级统一的并行编程架构。通过源到源的编译器,将类C 语言转成CUDA 或OpenCL 代码,实现不同规模的异构底层映射。使用非托管式编程语言的特点是所有规则、语法、执行模型和内存模型都是能够通过编程语言定义。但是非托管语言的抽象级别相对较低,需要程序员具备更多的软硬件开发专业知识。
托管式编程语言是指内存可由运行时系统自动管理的编程语言。托管式编程语言实现内存自动管理,依赖于高效的语言虚拟机、解释器和编译器执行。文献[26-28]基于Java 语言设计异构并行计算编程架构,以高级抽象的方式管理硬件资源,并在内部运行时系统进行中间优化操作。文献[14]提供Python 封装接口,使用PyOpenCL 调用接口。文献[29]设计高级语言Occanpi,用于异构粗粒度硬件构建、编译和生成机器码,解决异构可重构平台的可访问性问题。尽管托管编程语言简化了开发过程,但抽象程度越高,平台性能优化越困难。例如在Java 中,所有数组都从Java 端复制到JNI(Java Native Interface)端。JNI 需要为所有数组创建额外副本。因此,应用程序的性能将低于用非托管语言实现的应用程序性能。
2.3 融合的并行编程模型
异构计算的规模不仅限于芯片,还扩展到异构计算集群。大规模异构计算集群对计算节点的并行性能要求增加,系统往往具有更为复杂的并行层次和内存层级。文献[30]使用多核控制器管理异构设备,可跨不同计算硬件类型移植通用内核,简化数据分区和映射。运行时系统自动为每个设备选择和部署合适的内核,管理数据移动并隐藏启动细节。
高度并行异构系统需要处理好粗粒度并行和细粒度并行。混合粗粒度和细粒度并行的编程框架,通常为MPI+X 的多层结构。文献[31]设计一种通用、混合和优化稀疏的工具包,按照MPI+X 的范式,为多核计算器件提供内核和资源管理。文献[32-35]均采用MPI+OpenMP+CUDA(MOC)混合并行编程模型,通过基于节点间(粗粒度)和节点内(细粒度)的并行处理架构实现CPU 和GPU 协作的大规模异构并行计算。文献[36-37]则是提出MPI+OpenMP+OpenCL 的并行化方法,增强异构系统的数据可移植性。
2.4 虚拟化异构编程模型
尽管MOC 范式的融合异构并行编程框架具有良好的性能和能效,但是其编程复杂度较高。文献[38]提出了一种基于异构集群的分布式虚拟机。虚拟机实际是一个分布式系统,将混合的CPU 和GPU 看作单一的大规模GPU 集群,只需要使用CUDA 开发应用程序,而不需要将MPI 和多线程API 结合起来。以虚拟化的方式消除异构系统开发、设备内存空间和线程配置的复杂性,可以实现自动化处理异构处理器间负载均衡、设备内存和线程的配置约束问题。
2.5 小结
本章详细介绍了异构并行编程优化的最新研究成果,优化目标从编程难度、计算性能、并行规模3 个维度出发,对异构架构并行编程的技术挑战提出部分解决方案。实际上,一个异构并行编程框架难以同时具备编程难度低、计算性能高和异构规模大这3 个特点,只能满足三取其二。这种特征构成了异构并行编程优化的“不可能三角”,如图5所示。
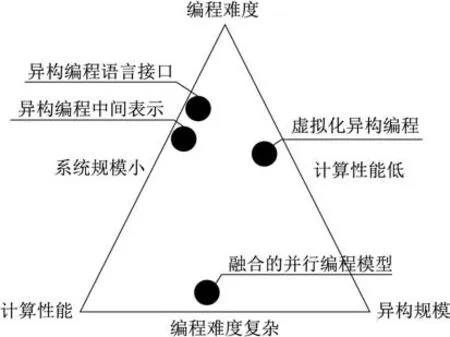
图5 异构并行系统“不可能三角”Fig.5 Impossible trinity of heterogeneous parallel system
这个“不可能三角”的3 个顶点分别是编程难度低、计算性能高、并行规模大,即异构并行编程模型优化的3 个目标。然而这3 个目标最多只能做到2 个。例如,如果追求编程模型易上手,通过少量代码或指令实现异构编程,同时保证系统具有高度并行和计算能力。这种情况下就需要高度封装的编程语言接口或者中间表示优化,从而牺牲编程灵活性,因此,难以在大规模异构系统上实现。另外两种情况也类似。如果想要计算性能高,同时异构规模大,那就需要多层级存储和混合颗粒度的并行编程框架,这将增加系统编程的复杂度;如果想要编程难度低,并且异构规模大,那么目前的方法就是采用虚拟化的方式,牺牲一定系统性能,从而实现大规模异构计算资源的统一管理。因此,在进行异构编程模型优化时,核心是两个方面:
1)对开发者来说,只有异构编程模型的编程复杂度是可控的,因此,开发或优化新型异构编程模型应由实际需求驱动。
2)在当前研究框架下,由于优化目标相互限制,还未出现完美的异构编程框架,理想的研究方向应是如何避免这个三元悖论或者将3 个优化目标进行折解。
3 异构并行计算关键问题
提高资源利用率和减少通信开销是异构计算研究的关键问题。为充分提高资源利用率,需要考虑并行任务使用哪些硬件计算资源;在不同的计算器件上,任务处理速度和效率不同,系统性能很大程度上受调度方案的影响,合理的负载均衡策略、服务质量管理都可以提高资源利用率。异构系统各类计算器件的传输、存储方式不同,合理的数据存储结构能够节省大量的数据读取时间;数据传输时可以通过叠加或流水等方式将计算或存储操作隐藏。此外,对系统性能的评估也需要灵活的评估方法和工具,综合考虑系统通信、能耗、可靠性以及其他技术指标的平衡。下面分别介绍异构系统任务调度映射、负载均衡、服务质量、存储优化、传输优化、通信隐藏、性能评估等方面的最新研究成果。
3.1 提高资源利用率
3.1.1 调度映射
同一计算任务在不同的硬件节点中执行,在性能功耗等方面各有所长,因此,异构系统需要将任务分配给合适的计算设备。
调度映射方式可分为静态和动态。静态调度方法利用系统约束和任务属性,将问题转化为多约束条件下的求最优解问题。求解方法分为线性规划方法和启发式方法。规划求解策略根据系统的多约束条件通过线性规划等方式求最优解。例如,文献[39]用线性规划方法,根据处理器类型和时间表约束进行任务调度,最小化通信延迟和能耗。启发式方法的核心是评价函数,以评价函数为标准通过不断迭代找到最优解。例如,文献[40]提出了混合双目标并行遗传算法,采用加权求和的方法,根据用户的偏好平衡能耗和执行时间。文献[41]基于搜索的调度算法,通过剪枝技术缩小搜索空间,通过启发式函数指导最优解搜索。文献[42]使用混合的元启发式集合方法,寻找异构系统的最优帕累托映射方案,同时优化执行时间和能耗。
动态调度方法通过感知系统能耗,动态实时调度子任务。文献[43]把能耗感知作为大规模异构计算环境中并行调度策略的重要参考依据,将不同并行层级任务映射到目标计算平台。文献[44-45]将动态电压频率标度和动态功率管理等系统参数量化,基于多目标全局优化元启发式算法,研究能耗感知和融合能效感知的调度模型。文献[46-47]在异构系统中,采用启发式的电源感知和能效调度算法,近似求解最小化动态能耗开销的调度策略。
3.1.2 负载均衡
负载均衡主要用于工作负载分配,通常以能耗感知的方式调整计算资源的使用,平衡计算能耗。
1)将特定异构模型和任务调度联合优化。文献[48-49]基于CPU 和Intel-MIC 结构提出工作负载分配方法,解决计算器件间的负载平衡问题。文献[50]采用聚合计算,改善CPU 和加速器之间的负载平衡。文献[51-52]通过基于贪婪策略的异构动态调度器实现负载均衡。文献[53]设计了双层工作负载分配方案,为每个计算节点分配最合适的工作负载,并在每个节点内合理划分CPU 和GPU 之间的工作负载。文献[54]采用基于FPM 的异构分解方法在异构处理设备之间分配工作负载。
2)依据系统能耗的动态反馈结果实现运行时的负载均衡。例如,文献[55]通过工作负载划分算法确定负载分布,最小化应用并行执行的能耗。文献[56]将性能和能耗作为工作负载函数的参数,评估并行平台的资源竞争,返回任务划分的帕累托最优解。文献[57]使用CMT-bone 工具进行异构架构的负载均衡,平衡优化性能和能耗。
此外,针对大规模异构集群,文献[58]研究了MOC 结构异构环境下,生成可执行程序时自动分配计算负载的方法。
3.1.3 服务质量
由于并行任务在线程同步、数据共享和并行化模式的多样性,管理执行性能要求不同的并行任务是一个复杂的问题。在资源有限的异构计算系统上并行执行任务,为不同任务定义不同的优先级,对异构系统的任务映射和资源管理具有重要意义。文献[59]研究异构系统上的并行任务服务质量管理方式,通过分析一系列任务映射策略对应用程序性能的影响,认为在异构硬件上的有效的服务质量管理策略能提高任务映射策略的性能,同时保持了系统优化目标的平衡。
3.2 减少通信开销
3.2.1 数据存储
异构体系结构中的共享末级缓存(Last Level Cache,LLC)对系统的整体性能至关重要,当与CPU 应用程序协同运行时,GPU 应用程序很容易占据LLC 的大部分,使得CPU 资源严重匮乏,针对异构体系共享LLC 的设计和管理,文献[60]将传统的SRAM 与新的存储器技术STT-RAM 相结合来扩展共享LLC,并通过综合管理策略减少计算器件间的资源争用。
3.2.2 数据传输
异构系统计算器件上的数据需要频繁交互。一方面,主节点与设备节点进行同步,会对系统带来额外的开销。文献[61]提出优化消息传递模型MEMPHA 减少异构器件之间的拥塞,缩短总通信量。文献[62-63]设计并行算法,通过GPU 排序队列减少通信开销。另一方面,数据传输过程的接口协议需要相互转换。针对数据转换,文献[64]提出一种动态二进制转换任务迁移方法,减少因数据转换造成的开销。
3.2.3 通信隐藏
异构规模的增加使通信延迟成为性能瓶颈。为减少通信延迟,文献[65]采用空间域分解和射线并行相结合的方法进行异构并行计算,使MPI 通信时间与GPU 上的传输扫描时间重叠,隐藏GPU 与CPU 之间的通信和数据传输时间。文献[66]通过性能分析模型识别性能影响因素,实现数据计算与数据传递操作相互重叠。文献[67]提出流水线混合并行的优化方法,加速GPU 之间的流水线混合并行,减少通信延迟和内存使用频率。
3.3 性能评估
异构系统还包括对计算和通信行为的性能评估模型的研究。文献[68-69]设计形式化的通信性能的表达方式,用于评估通信代价、最小化通信开销。文献[70]提出一种精确通信成本评估函数,用于在执行数据并行应用程序的过程中,评估混合平台中计算存储数据移动的通信时间。异构系统优化的另一个目标是准确估计不同计算器件的能耗。文献[71]采用系统级功率测量表估计应用组件级能耗。对于安全性要求高的并行应用,必须满足可靠性目标的同时最小化成本。文献[72]针对异构嵌入式系统上并行计算的资源消耗成本最小化问题,将应用程序的可靠性目标转化为每个任务的可靠性目标并分配给处理器,以启发式的方法最小化能耗。
3.4 小结
本章详细介绍了异构并行计算在提高资源利用率,减少通信开销以及系统性能评估等方面的最新研究成果。相比于传统并行编程模型的计算方法,异构模型增加了系统的计算复杂度,这种计算复杂度主要体现在三个方面:
1)任务的编译不仅面向CPU,还要映射到GPU、FPGA 等含有局部存储结构的加速器件上。编译过程增加了任务划分、映射、负载和执行优先级等工作,直接增加系统计算负担。
2)异构器件的存储和传输成为新的性能瓶颈,根据计算任务不同,系统应支持以灵活的方式改变存储结构及通信传输方式实现性能优化。
3)异构特性使系统在评估性能时的可选指标更加多元化,因此,应支持根据实际需求或应用场景的变化,可灵活定义异构系统内部结构及其评价标准。
从以上特点可以看出,当前异构并行计算优化方法主要继承传统并行计算优化中的任务映射、分级存储和并行流水等策略,在策略的生成过程中人工干预较多,系统缺乏主动认知和自主决策的能力,并且明显缺点是各类计算优化只针对特定体系结构的异构系统。从研究趋势以及研究需求上看,未来计算体系结构的特点应具备“应用决定结构”的主动认知的动态重构过程,因此,对灵活可变特征的异构体系结构模型有待进一步研究。
4 结束语
本文回顾了主流异构并行编程模型及研究进展,针对异构并行计算关键问题进行讨论。前文已经指出异构并行计算架构系统的三元悖论对开发者来说一直都是挑战,随着计算器件多样化,支持软件定义的异构融合模型软件工具链内涵仍需不断扩展和完善。2008 年,邬江兴院士根据“结构决定功能、结构决定性能、结构决定效能”的公理,提出拟态计算(Mimic Structure Calculation,MSC)架构。拟态计算是在异构计算的基础上实现基于主动认知的多维环境动态重构,实时感知计算任务关于时间的负载分布和能耗状况,调度合适的软硬件功能模块,协同完成计算任务以拟合期望的能效曲线。结合拟态计算的思想,理想的异构编程模型应具备融合多类计算资源、结构的主动感知和动态重构的特征。异构融合的编程模型能够提供灵活的底层资源的抽象,通过软件定义形式实现多模态计算模型。结合研究团队在拟态计算和高效能计算方面的积累,对新型异构体系架构的研究有以下几个方向:
1)软件定义互连。异构内涵不断丰富,未来的网络体系包含多种异构计算资源,存储资源和相互间的各种网络连接资源。软件定义互连基于可重构和可编程技术,具有可扩展的硬件/软件架构,允许应用程序对硬件进行在线定义,动态更改交换互连的功能、性能,实现对不同应用场景的最佳拟合适配。软件定义互连将是针对未来多样化需要的新型网络技术,是交换与互连技术及产业的未来演进形态,其发展趋势主要包括两点:一是突破软件定义互连技术基础理论、基础支撑技术和共性关键技术问题,形成覆盖标准规范、芯片、设备、网络平台、软件、工具等在内的体系化成果;二是着眼关键应用的新型体系结构发展,打造支持软件定义互连为内核的产业体系,形成从终端到边缘计算、汇聚接入、核心交换的软件定义大互连生态。
2)内生安全。异构体系架构的核心特征是基于能效的软硬件变结构协同计算和基于性能的变结构协同处理。在此基础上,拟态计算架构支持在效能和性能目标间自由转换,并具备动态优化和管理的功能。拟态计算所具有的多样性、动态性和随机性的协同处理特点,恰好能够弥补传统系统在应对基于内生安全问题攻击时的静态性、确定性和相似性安全缺陷。因此,利用对威胁感知的功能等价动态变结构协同处理环境的非确定性,就可以创造以内源性的“测不准”效应规避内生安全问题的新型防御体制。从应用维度上看,基于拟态计算的异构变结构协同计算能够适配基于构造效应的内生安全机制。在未来的研究中,功能等价条件下的软硬件变结构协同处理体制机制将成为解决内生安全问题的关键。
3)类脑计算。类脑计算以融合科学计算和神经网络计算为核心,基于拟态计算与软件定义互连技术,实现软件与硬件、控制与计算的分离,计算、存储、互连等资源可灵活定义的“左右脑”融合计算架构。类脑计算通过资源动态自适应匹配方法,构建主动认知重构的处理结构,生成多目标约束下的资源调度方法,实现任务与资源的优化匹配。基于软件定义的可重构计算方法结合人脑工作机理的抽象与建模,实现深度神经网络与拟态神经计算的融合,推动人工智能从原理模型、算法到实现架构的发展,为边缘终端、移动终端等设备的智能化实时信息处理提供强力支撑,是未来计算系统发展的一条可行的技术途径。
随着软件定义互连、内生安全、类脑计算技术的发展,本团队将应用场景进一步扩展至晶上系统(System on Wafer,SoW)领域。软件定义晶上系统立足我国集成电路成熟工艺和工具“代差落后”的基本国情,借助领域专用软硬件协同计算结构和晶圆级互连拼装集成的联合迭代创新,解决SoW 发展初期领域专用混合粒度预制件设计、异构多Die 之间互连、动态可重构网络等关键问题,并将作为SoW 内部Die-to-Die 之间的计算互连规范,致力于构建一个开放式的SoW 生态。
