面向人脸识别的口罩区域修复算法
2021-09-10李悦钱亚冠关晓惠李蔚王滨顾钊铨
李悦,钱亚冠,关晓惠,李蔚,王滨,顾钊铨
(1.浙江科技学院大数据学院,浙江 杭州 310023;2.浙江水利水电学院信息工程与艺术设计学院,浙江 杭州 310027;3.杭州海康威视网络与信息安全实验室,浙江 杭州 310051;4.广州大学网络空间先进技术研究院,广东 广州 510006)
1 引言
基于深度学习的人脸识别技术已被广泛应用于金融、公安、教育等领域,其中 DeepFace[1]是应用深度学习的经典人脸识别算法,在 LFB(lable2 +aces in the wil2)[2]数据集上取得了97.35%的识别率,已经接近人类的水平。最近提出的ArcFace[3]算法,则达到了99.8%的识别率。但目前的人脸识别算法在实际应用中易受一些外部因素(如人脸遮挡、光照、面部表情、面部朝向等)的影响。其中,遮挡的影响最为显著,可导致识别率降低10%左右[4]。
2020年年初,新型冠状病毒肺炎疫情突然爆发,要求人们必须佩戴口罩进入公共场所。尤其在机场、火车站等需要计算机人脸识别的场所,口罩对人脸的遮挡必然会影响识别的效率和准确率,而摘下口罩又会增加交叉感染的风险。因此,如何在戴口罩的情况下实现高精度的人脸识别成为当前急迫需要解决的问题。
事实上,遮挡条件下的人脸识别一直是该领域的研究热点[5-6]。Bang等[7]提出了两阶段的重建方法:先检测遮挡再恢复遮挡部分,这种联合遮挡检测和恢复方法可以产生有利于分类的良好全局特征。Zhang等[8]用去遮挡的自编码网络恢复被遮挡区域。Yuan等[9]利用3D重建修复人脸遮挡部位,但该方法需要与目标身份相同的参考数据。Zhao等[6]以相同身份的人脸图片为基础,使用生成对抗网络(generative a2versarial network,GAN)[10]生成无遮挡的人脸。Duan等[4]提出了 BoostGAN(boosting generative a2versarial network)先粗略后精细地恢复人脸。He等[11]提出一种人脸图片编辑方法,通过属性分类约束更加精确地修改人脸属性。Iizuka等[12]和Li等[13]利用GAN,结合全局判别器与局部判别器,从整体以及局部区域判断修复图片的语义一致性。以全局判别器与局部判别器同时使用为基础,ID-GAN(i2entity-2iversity generative a2versarial network)[14]将基于深度学习的识别器和基于GAN的判别器相结合,修复真实且保留身份的人脸。这类方法的缺陷是在生成遮挡区域边缘时会失真。
但是这些方法并没有专门针对口罩遮挡,因而去除口罩遮挡的效果不佳。口罩遮挡面积较大,鼻子以下的面部特征被掩盖,可利用的特征关键点减少。考虑人脸边缘包含了大量的人脸结构信息,如果以边缘为基础修复人脸,有可能产生更好的效果。因此,本文提出新的人脸口罩区域修复算法ID-EFCGAN(ID-e2ge to +ace con2itional generative a2versarial network),利用条件生成对抗网络(con2itional generative a2versarial network,CGAN)[15]生成边缘图,在此基础上再利用CGAN恢复被遮挡区域的人脸。为提升 ID-EFCGAN的性能,提出空间加权对抗损失和身份一致性损失训练上述网络,其中身份一致性损失通过约束生成人脸与真实人脸有相似的特征表示,使生成人脸与真实人脸的身份信息一致,从而保证人脸识别效果。利用关键点信息构建了两个佩戴口罩的人脸数据集进行实验,结果表明,佩戴口罩的人脸经过本文的去遮挡处理后,可使 ArcFace的识别准确率达到98.39%。
2 口罩遮挡下的人脸识别
针对佩戴口罩的人脸,本文不改变现有人脸识别算法,采取修复口罩遮挡部分的思路,提高人脸识别准确率,具体过程如图1所示。本文提出端到端的人脸修复模型ID-EFCGAN(以下简称ID-EFC),由边缘生成网络和区域填充网络构成,分为两步去除口罩遮挡:(1)恢复人脸边缘。对于戴口罩的人脸图片,利用人脸关键点信息定位口罩,并生成口罩掩码。借助口罩掩码获得口罩区域缺失的人脸图像。利用边缘生成网络恢复口罩缺失区域的边缘。(2)口罩缺失区域填充。基于恢复的边缘图,区域填充网络还原遮挡区域的人脸。最后,利用已有的人脸识别算法对去除口罩遮挡的人脸进行识别。
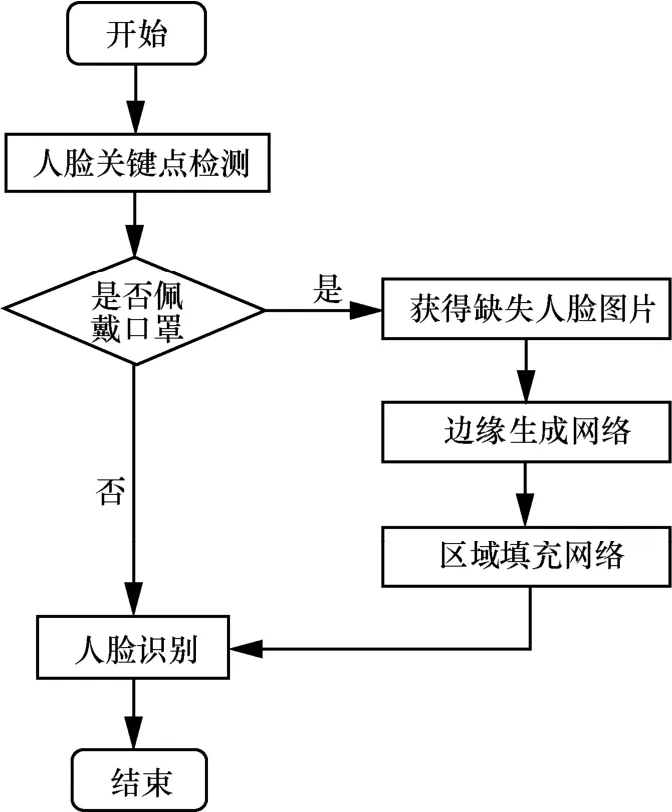
图1 去除口罩遮挡实现人脸识别的流程
边缘生成网络和区域填充网络均采用 CGAN的结构,由生成器和判别器组成。为方便后续描述,将边缘生成网络的生成器和判别器分别记为G1和D1,区域填充网络的生成器和判别器分别记为G1和D1。用C表示人脸边缘图,X表示人脸图,将戴口罩的人脸图片记为Xwear,借助口罩掩码获得的口罩区域缺失的人脸图记为Xmask,真实的无遮挡人脸图记为Xgt,其灰度图和边缘图分别记为Xgray和Cgt。
2.1 边缘生成网络
为了生成口罩区域的人脸边缘,需先定位口罩并获得口罩区域缺失的人脸图。利用人脸关键点信息,结合先验知识初步获取口罩的位置和形状。由于每张图片中的头部姿势和脸部大小不同,在算法中对口罩形状的大小以及角度进行自动调整。根据获取的口罩位置和形状信息,生成与人脸图片同样大小的口罩掩码,记为M。该掩码口罩区域像素值为1,其余区域像素值为0。相比用矩形框定位口罩,本文方法更加精准,不会过度扩大遮挡面积。利用式(3)获得口罩区域缺失的人脸图Xmask。

其中,⊙为Ha2amar2乘积。
在获得Xmask后,进一步利用边缘生成网络还原缺失区域的人脸边缘,通过生成器G1与判别器D1的动态博弈,生成尽可能真实的无遮挡边缘图(如图2所示)。具体步骤为:
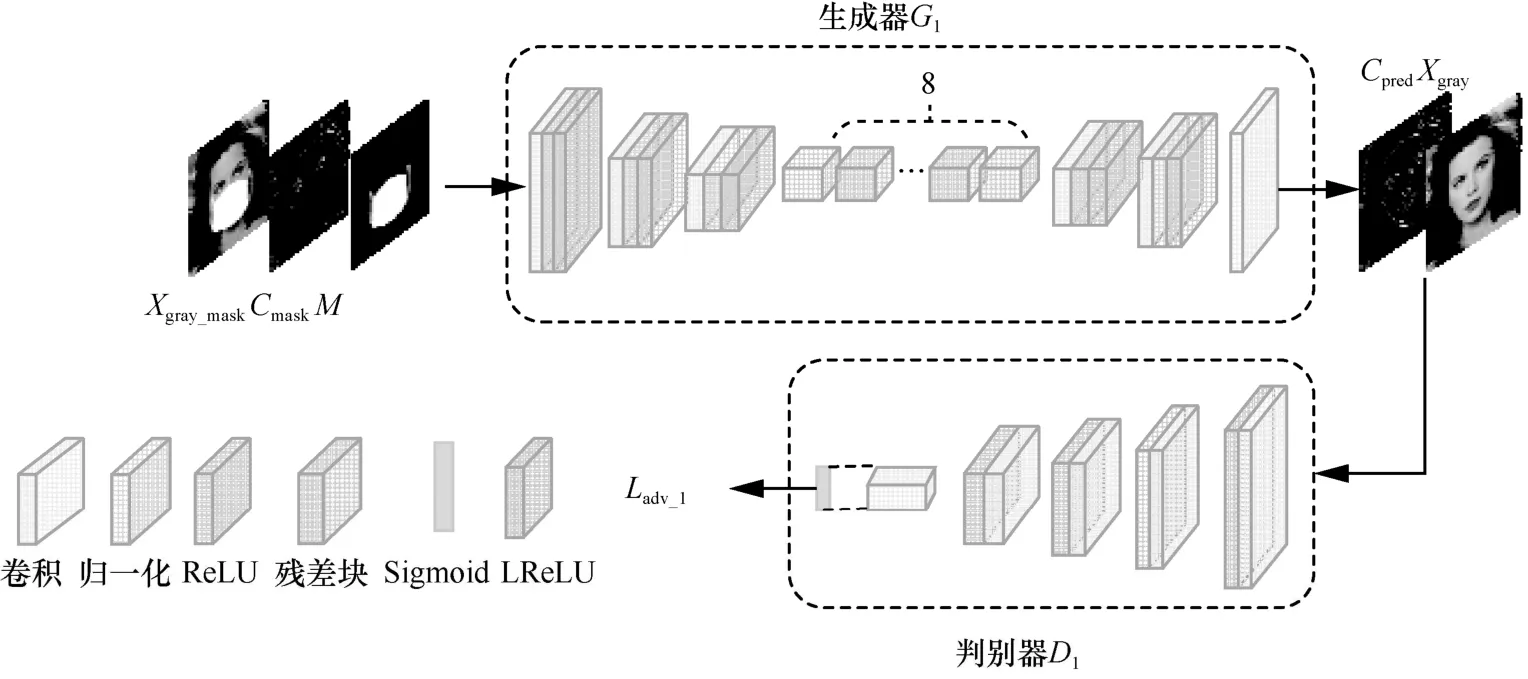
图2 边缘生成网络的结构
(1)获取Xmask的灰度图和边缘图,分别记为Xgray_mask和Cmask,其中,边缘图利用Canny边缘检测器[16]获取;
(2)将获得的灰度图Xgray_mask输入生成器G1,边缘图Cmask作为生成器G1的条件,生成无遮挡的边缘图Cpre2;
(3)获得无遮挡边缘图Cpre2后,判别器D1不仅判断Cpre2是来自真实数据还是生成器G1,而且判断生成的Cpre2与灰度图Xgray是否匹配;
(4)利用式(4)获得原始的无遮挡边缘图Cgt和Cpre2的组合,记为Ccomp:
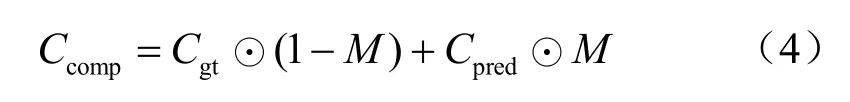
Ccomp中的无遮挡区域的边缘来自Cgt,遮挡区域的边缘来自生成器的预测Cpre2。
2.2 区域填充网络
在获得组合边缘图Ccomp后,进一步利用区域填充网络填充Ccomp生成人脸,通过生成器G2和判别器D2的动态博弈,生成尽可能真实的无遮挡人脸图(如图3所示)。具体过程为:
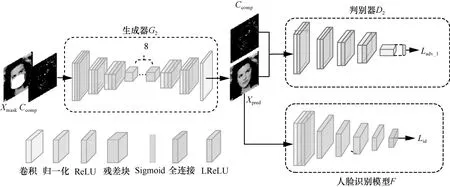
图3 区域填充网络的结构
(1)将缺失的人脸图Xmask和组合边缘图Ccomp输入生成器G2,其中Ccomp作为生成器G2的条件,生成无遮挡的人脸图片Xpre2;
(2)获得无遮挡人脸图Xpre2后,判别器D2不仅辨别出生成器G2“伪造”的Xpre2,而且判断生成的Xpre2与边缘图Ccomp是否匹配;
(3)借助式(5)获得原始的无遮挡人脸图Xgt和Xpre2的组合,记为Xcomp:
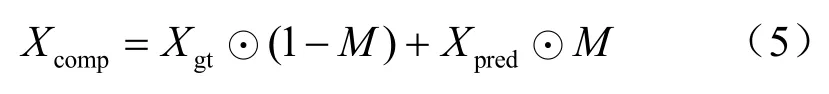
Xcomp中的无遮挡区域来自Xgt,遮挡区域来自G2生成的Xpre2。在获得无遮挡人脸图片Xcomp后即可进行识别。
2.3 空间加权对抗损失
图4(a)展示了遮挡区域与未遮挡区域对抗损失函数的分布,可以看到两个区域的分布存在差异,无差别地对待这两个区域可能会影响生成图片的质量。为此,本文引入空间加权对抗损失。考虑遮挡可看作大面积空间连续噪声[5],本文对口罩遮挡区域和未遮挡区域的对抗损失赋予不同的权重,定义空间加权对抗损失为:
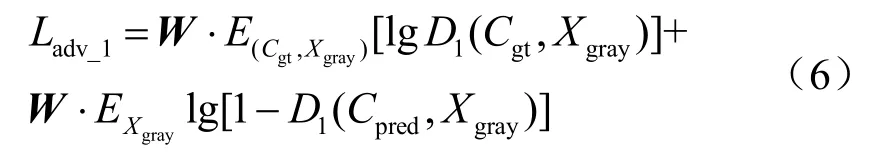
其中,W称为空间权重,大小为N×N的矩阵,其中每个元素表示相应区域损失的权重。W中的元素仅有两种取值,分别为口罩区域对应的权重取值和未遮挡区域对应的权重取值(如口罩区域对应的权重均为 0.75,未遮挡区域对应的权重均为1),该部分的具体取值将在实验部分讨论。引入空间加权对抗损失后,两个区域的分布更加接近,如图4(b)所示,这表明空间加权对抗损失更加合理地对待这两个区域。
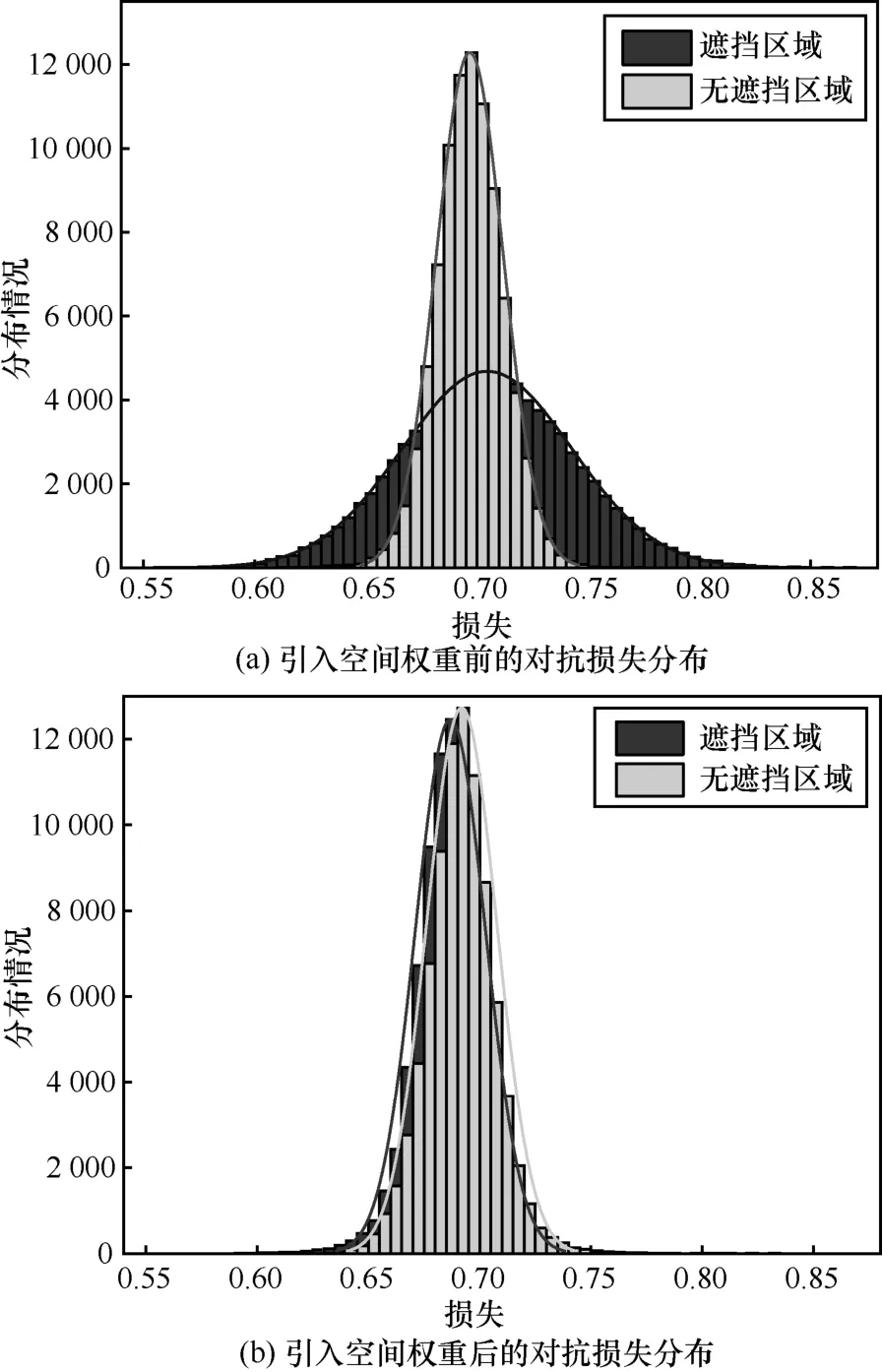
图4 被口罩遮挡区域与无遮挡区域对抗损失函数的分布
2.4 身份一致性损失
去除人脸口罩遮挡后的人脸识别准确率取决于:
(1)生成的人脸要尽可能真实;
(2)生成人脸Xpre2与真实人脸Xgt的身份要一致。
为此,本文在GAN的结构中引入一个训练好的识别网络,用于计算身份一致性损失,度量生成人脸与真实人脸的身份特征之间的距离,使生成人脸与真实人脸在语义上更加相似:
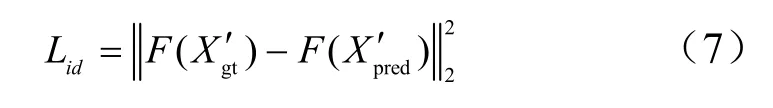
其中,F为预训练好的人脸识别模型,提取身份判别所需的人脸特征;Xg′t和Xp′re2分别是经过人脸检测器MTCNN(multi-task convolutional neural network)[17]裁剪对齐后的真实人脸和生成人脸。通过最小化身份一致性损失,真实人脸的身份特征引导着人脸的生成,使得生成人脸在身份特征空间中逼近真实人脸,从而保留大量身份信息。
为了实现边缘图到人脸图这两种不同风格图像之间的转换,本文引入感知损失[18]与风格损失[19],与本文设计的身份一致性损失、空间加权对抗损失加权求和作为总的损失函数训练区域填充网络。风格损失通过计算预训练网络不同层特征图之间的距离,衡量两张图片之间高级感知及语义差别:
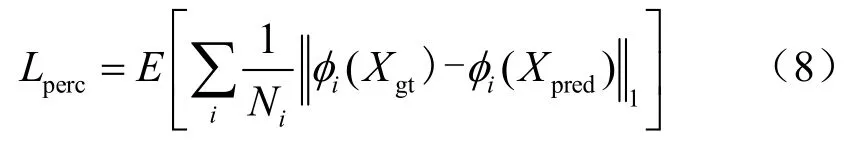
其中,Ni是第i层激活映射的元素个数,φi是VGG-19网络的第i层激活映射。风格损失利用表示风格特征的 Gram矩阵[20],计算风格特征之间的绝对误差,衡量两张图片的风格差异。风格损失可以有效避免棋盘效应,对于大小为Ci×Hj×Wj的特征映射,风格损失函数定义为:
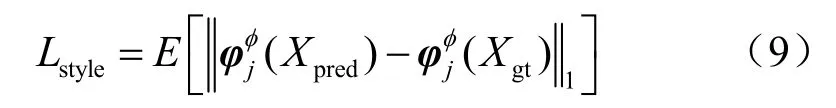
其中,是由激活映射iφ构造的大小为jj C×C的Gram矩阵。
为了提高生成图片的质量,在区域填充网络的损失函数中引入本文提出的空间加权对抗损失函数,对口罩区域的损失赋予与其他位置不同的权重。区域填充网络的空间加权对抗损失:
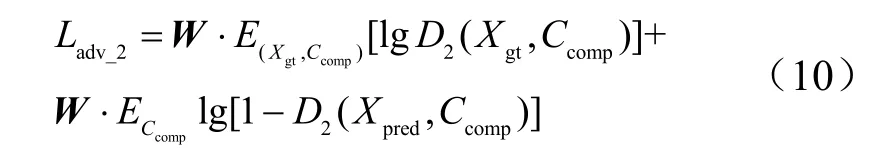
最终得到区域填充网络生成器G2和判别器D2的损失分别如下:
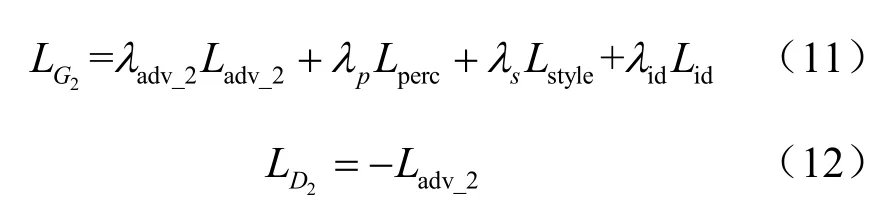
利用LG2训练区域填充网络生成器G2,利用LD2训练区域填充网络判别器D2。
3 实验设置和效果评估
首先,定性和定量地分析生成图片的质量;然后,分析空间加权对抗损失的有效性;最后,从人脸识别的准确率角度评估本文模型是否更好地保留了身份信息。
3.1 实验设置
目前用于人脸识别的公共数据集主要有CASIA-BebFace[21]和 LFB[2]。CASIA-BebFace用于身份鉴定和人脸识别模型的训练和测试,包含10 575个身份的494 414张图像,每张图片的大小为250 2pi×250 2pi。LFB用于人脸识别模型的测试,包含5 749个身份的13 233张人脸图像,绝大部分人仅有一张图片,每张图片的大小为250 2pi×250 2pi。但以上两个数据集中的人脸均未戴口罩,为此本文借助关键点信息,将口罩添加到人脸图片上,合成了两个戴口罩的数据集 CASIABebFace mask和 LFB mask。CASIA-BebFace mask包含约42万张图片,其中34万张用于训练,4万张用于验证,其余用于测试;LFB mask包含 13 170张人脸图片,用于测试。测试集中的人脸身份均没有在训练集中出现。
本文所有实验均在4×GeForce RTX 2 080ti服务器上进行,生成器以参考文献[18]为基础构建,判别器使用PatchGAN[22],网络的所有层都使用实例归一化(instance normalization,IN)。实验使用的人脸识别模型为ArcFace。
设置Can2y边缘检测器的参数σ为2,损失函数的权重分别为λa2v,1=1,λa2v,2=λp=0.1,λs=250,λi2=1。分两个阶段训练:第一阶段,分别训练生成器G1和G2直到收敛,设置生成器G1和判别器D1的学习率分别为10-4和10-5,使用A2am优化器优化,设置参数β1=0,β2=0.9。第二阶段,联合训练生成器G1和G2,设置生成器和判别器的学习率分别为10-5和10-6。
3.2 生成图片的质量
本文分别展示边缘生成网络和区域填充网络修复的边缘图(如图5所示)和人脸图(如图6所示)。图5中从左往右各列依次为真实的人脸图Xgt、戴口罩的人脸图Xwear、口罩区域缺失的人脸灰度图Xgray_mask、口罩区域缺失的人脸边缘图Cmask、预测的人脸边缘图Cpre2、组合边缘图Ccomp和真实的人脸边缘图Cgt。图6中从左往右各列依次为真实的人脸图Xgt、戴口罩的人脸图Xwear、口罩区域缺失的人脸图Xmask、组合边缘图Ccomp、预测的人脸图Xpre2和组合人脸图Xcomp。从图5和图6可以看出,基于人脸边缘图恢复了被口罩遮挡的区域,并保留了原图中未被遮挡的区域。
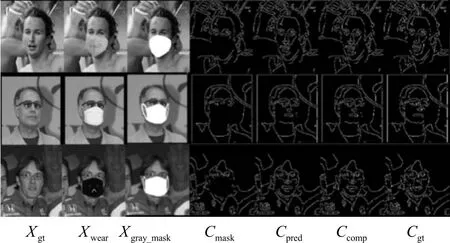
图5 边缘生成网络生成的人脸边缘图示例

图6 区域填充网络生成的人脸图示例
本文从视觉效果定性分析去除口罩后的图片质量。图7和图8展示了人脸头部姿势、光照和口罩样式不同的人脸图片。第一行是姿势和光线不同的戴口罩人脸图片,第二行是未戴口罩的真实人脸,第三行是 ID-EFC去除口罩后的人脸图片,接近第二行的真实人脸。实验结果表明,ID-EFC的有效性不受头部姿势、光照和口罩样式的影响。尽管测试数据集和训练数据集中的人物身份无一相同,包括头部姿势、脸部大小和口罩的遮挡形状也不相同,但ID-EFC仍能生成没有虚假边缘和区域的人脸图片,恢复大部分细节,取得良好的视觉效果。

图7 ID-EFC在CASIA-BebFace mask数据集上去口罩遮挡人脸示例

图8 ID-EFC在LFB mask数据集上去口罩遮挡的人脸示例
本文以未引入空间加权对抗损失和身份一致性损失的模型为基准模型,命名为EFCGAN(e2ge to +ace con2itional generative a2versarial network),简称为EFC,将其与ID-EFC进行实验对比。图9给出了各种模型在CASIA-BebFace mask数据集上去除口罩遮挡后的部分结果。图9中第一行和最后一行分别为戴口罩的人脸Xwear和真实人脸Xgt,中间三行中从上往下依次为使用矩形掩码训练的模型 EFCroc、使用本文口罩掩码训练的模型EFCmask和ID-EFC去除口罩后的人脸。可以看出,使用 EFCroc得到的人脸不够真实,容易产生虚假区域。使用EFCmask去遮挡的效果明显提升,人脸变得真实,表明本文生成口罩掩码的有效性。但EFCmask修复的人脸在嘴巴和鼻子等关键部位有些失真,因为该模型未充分考虑身份信息。相比之下,ID-EFC修复的鼻子和嘴巴部位更真实、自然,这是因为引入了身份一致性损失,有利于身份细节的恢复。

图9 不同模型在CASIA-BebFace mask数据集上去除口罩的人脸示例
本文进一步用PSNR和SSIM这两个常用的图像质量评价指标定量分析修复图片的质量。各模型去除口罩遮挡后的图片对应的PSNR和SSIM见表1。从表1中的结果看,EFCroc的两项指标均为最低,ID-EFC的两项指标最高,而EFCmask的两项指标居中,说明ID-EFC生成的人脸图片质量最好,这与之前的定性分析结论是一致的。

表1 不同模型生成图片的PSNR和SSIM
3.3 空间加权对抗损失的效果
下面将进一步验证空间加权对抗损失对提升图片质量的效果,对比引入空间加权对抗损失La2v(包括La2v_1和La2v_2)前后 EFCmask模型在CASIA-BebFace mask和LFB mask上的PSNR和SSIM 值(见表2)。表2中引入La2v的 EFCmask模型修复图片的PSNR和SSIM值均较高,说明La2v对提升图片质量有较好的效果。为了进一步研究口罩区域损失的权重取值对生成图片质量的影响,固定无遮挡区域的权重均为1,口罩区域的权值wmask分别取0.5、0.75、1、1.25和1.5,实验结果如图10所示。权重wmask取值为1时,表示模型 EFCmask的对抗损失没有引入空间权重。从图10可以看出,权重小于1时的PSNR高于权重大于1时的PSNR,并且在权重为0.75时,PSNR最高。因此,本文选取口罩区域对抗损失的权重为 0.75,无遮挡区域对抗损失的权重为1。

表2 空间加权对抗损失使用前后的结果对比
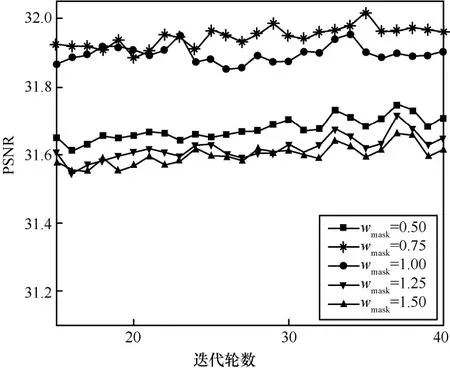
图10 口罩区域对抗损失权重取值对PSNR的影响
3.4 人脸识别效果
通过对比添加身份一致性损失Li2和空间加权对抗损失La2v(包括La2v_1和La2v_2)前后模型对遮挡下人脸识别的影响,证明ID-EFC能更好地保留身份信息。首先将人脸对齐裁剪成尺寸为112 2pi×112 2pi的图片,用ArcFace提取裁剪对齐后的人脸特征,然后验证成对人脸图片是否属于同一身份。成对图片中一个是图库中未戴口罩的人脸,另一个是戴口罩的人脸或去除口罩遮挡的人脸。使用模型去除口罩后的人脸进行识别的准确率见表3。
表3中最后一列,ArcFace在LFB数据集上的准确率高达99.82%,但是当人脸存在口罩遮挡,对遮挡人脸不进行任何处理,直接基于整张遮挡人脸进行识别时,其在LFB mask数据集上的准确率只有94.26%,下降了5.56%,说明口罩遮挡的确会影响人脸识别准确率。以ArcFace在LFB mask数据集上的准确率94.26%为比较基准,从左往右对比:ArcFace在EFCroc修复的人脸数据上的准确率只有93.87%,低于直接识别整张遮挡人脸的准确率(94.26%);ArcFace在EFCmask修复的人脸数据上的准确率为97.98%,较遮挡下人脸识别准确率提高了 3.72%;EFCmask加入La2v后,准确率提高了 3.8%;加入Li2后,准确率提高了3.88%。而同时引入La2v和Li2后,ID-EFC将遮挡下人脸识别准确率提升了 4.13%,最终准确率为98.39%,说明 ID-EFC的模型能更好地保留身份信息。

表3 不同模型在LFW mask数据集上的人脸识别准确率
图11更直观地展示了ArcFace在各个模型去除口罩后的人脸数据上进行人脸识别的 ROC曲线。GT和OCC分别表示无口罩遮挡和口罩遮挡下人脸识别的ROC曲线。随着空间加权损失与身份一致性损失的加入,AUC值不断增大,说明人脸识别的效果变好。通过AUC值可以发现,遮挡条件下,ID-EFC(EFCmask+La2v+Li2)对提高识别准确率的效果最好。

图11 在LFB mask数据集上人脸识别ROC曲线
本文通过比较不同模型修复的人脸的身份特征,进一步分析ID-EFC取得较好效果的原因。利用t-SNE[23]将512维的身份特征降至2维,观察属于同一身份特征的聚集性与可分性,可视化结果如图12所示。图12(a)(b)(c)分别表示口罩遮挡下的人脸、EFCmask修复的人脸和ID-EFC修复的人脸的身份特征。图中同一形状的点表示属于同一个身份的特征。由图12(a)可发现,口罩遮挡下不同身份的人脸在身份特征上存在重叠,因此即使性能优良的 ArcFace也无法在遮挡的情况下保持高精度的准确率。用EFCmask(如图12(b)所示)去除遮挡后的人脸特征也仍然存在部分重叠。而ID-EFC(如图12(c)所示)修复的人脸特征实现了最大的聚集度,容易根据身份特征对其进行分组,显示了身份一致损失对提高口罩遮挡下人脸识别准确率的有效性。

图12 身份特征可视化
3.5 口罩类型对识别效果的影响
为了进一步研究不同类型的口罩遮挡对人脸识别的影响,本文分别测试不同类型口罩遮挡下的识别准确率,结果见表4。本文使用黑、白和蓝3种口罩,对人脸的遮挡面积分别约为40%、39%和37%,在这3种口罩遮挡下,ArcFace的识别准确率分别为91.23%、95.77%和93.18%,见表4。其中遮挡面积为 40%的黑色口罩遮挡下的识别准确率最低,说明该种口罩对人脸识别效果的影响较大。

表4 不同类型口罩遮挡下的人脸识别准确率
为了进一步分析遮挡面积和口罩颜色对识别效果的影响,本文分别测试不同颜色和不同面积的口罩遮挡下的识别准确率,结果见表5。
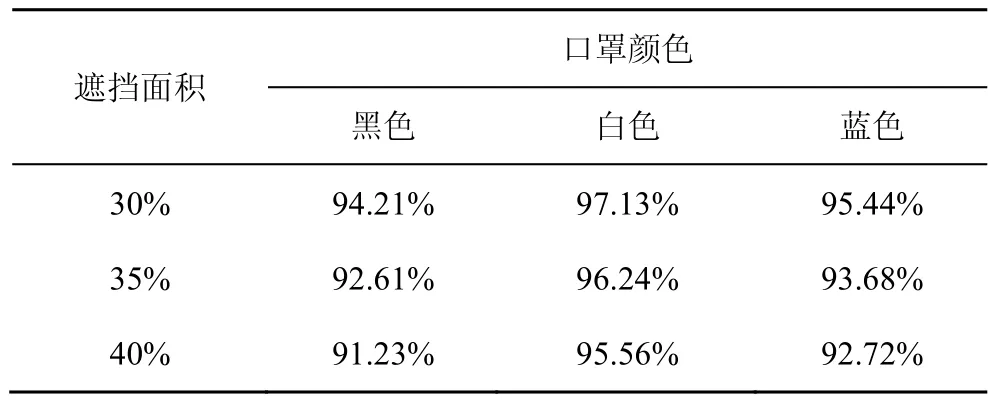
表5 不同面积和颜色的口罩遮挡下人脸识别准确率
可以发现,在口罩颜色相同的条件下,识别准确率随着遮挡面积增加而逐渐下降,这说明遮挡面积对识别效果有一定的影响。除此之外,在遮挡面积相同的情况下,黑、白、蓝3种口罩遮挡会对识别效果产生不同程度的影响,以 35%遮挡面积为例,黑、白、蓝3种口罩遮挡下的识别准确率分别为92.61%、96.24%和93.68%,说明黑色口罩遮挡对人脸识别模型性能的影响最为严重,蓝色次之,白色最小。
4 结束语
本文提出了一个人脸口罩区域修复深度学习模型ID-EFC,并设计了空间加权对抗损失和身份一致性损失对其训练。实验表明,空间加权对抗损失的引入能有效提升生成图片的质量;身份一致性损失的引入能更好地保留生成图片的身份信息,这两种损失在口罩区域的修复中起着重要作用。ID-EFC的应用,可提高口罩遮挡下的人脸识别准确率。此外,ID-EFC能够处理不同头部姿势、光照和口罩样式的人脸图片,具有良好的泛化性能。下一步的工作是优化现有模型,推广到多种遮挡类型的人脸识别任务中。
