面向企业竞争情报的弱信号识别研究
2021-09-07杨波邵婉婷
杨波 邵婉婷

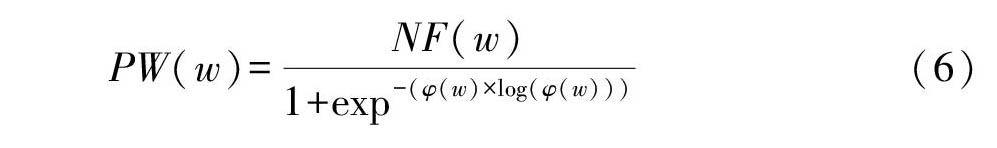

DOI:10.3969/j.issn.1008-0821.2021.09.006
[中图分类号]G250.25 [文献标识码]A [文章编号]1008-0821(2021)09-0053-11
随着中国市场经济的蓬勃发展,企业与企业之间的竞争愈发激烈,从而形成对竞争情报的迫切需求。其中,弱信号识别是竞争情报前瞻性研究中的重要组成部分,为企业监控竞争对手,预测未来的机会与风险提供有益参考。弱信号与大多数信息一致,都是从大量的数据中提取而出,通过合理的推断与联系,形成对人类有价值的信息,但由于其具有预见性的特点,也被称为预警信号。企业忽视弱信号就是轻视甚至压制可能阻止错误决策的警示信号,如同驾车闯红灯,定会导致失败。因此,为使企业及时感知并准确识别出市场的机遇与威胁,制定利于长远发展的管理决策,弱信号识别的研究至关重要。
目前,识别弱信号并预测未来情况已成为许多研究人员的目标,因此,许多技术用于从词或文档中获得最大洞察力,但大多需要人类专家的协助检测。如Griol-Barres Ⅰ等利用科学、新闻、社会来源的异构和非结构化信息对弱信号进行定量检测,应用多词共现分析法对人工挑选的部分关键词进行分析,并通过自然语言处理提取准确的结果。Yoon J提出一种在专家给定关键字的前提下,基于文本挖掘的弱信号主题识别方法,并通过太阳能电池相关的网络新闻报道,说明了该方法的可行性。邓胜利等通过专家给定系数下的层次分析法和隶属度函数对弱信号进行定量识别。
与此同时,学者们也着力于运用诸如深度学习和神经网络之类的技术来充分对互联网上不断增加的文本数据进行预见性分析。自然语言处理技术(NLP)能够很好地从文本数据中提取见解,其中单词嵌入技术能精准地捕获词语之间的相似性和基于上下文预测单词。Dieng A B等提出一种嵌入式主题模型,该模型将常规主题模型与单词嵌入结合在一起。但是,与未标记的数据相比,这些技术在应用于标记的数据时可提供更好的结果。而在Web文章中检测弱信号的情况下,文本数据通常没有标签。因此,基于深度学习的NLP技术不能确保弱信号检测过程的完全自动化。
但是,传统的主题建模技术显示了其完全自动化的能力,并吸引了许多使用新旧方法的研究者。因此,本研究使用一种广为人知的主题模型,即潜在狄利克雷分布(LDA)。LDA是一种无监督的机器学习技术,可根据输入的文档集及指定的主题数来独立运行,不需要手工标注的训练集,许多学者使用LDA检测弱信号:Pepin L等使用动态LDA检测弱信号,即对不同时间下的文本使用LDA算法提取主题,并使用主题演化的可视化散点图来检测弱信号;Gutsche T使用动态LDA来跟踪弱信號随时间的生命周期。
为充分地对企业弱信号进行自动化检测,本研究构建了一种新的弱信号识别方法,对LDA主题模型生成的主题和术语进行过滤,仅提取文本集中的预警信号,以检测出隐藏、重要且被限定为弱信号的单词。同时,为弥补LDA词袋模型的不足,增强模型结果的可解释性,运用BERT方法对每个过滤后的主题文档进行上下文的预测,以获得更多与弱信号语义相关的单词。本方法实现了全自动地识别文本弱信号,创新提出主题过滤和术语过滤双层过滤函数,并引入BERT深度学习模型,弥补了单一模型在文本处理上的不足,为弱信号识别研究提供了新方法、新思路。并将模型应用于企业社交媒体新闻数据集,以检测一段时间内的相关弱信号,为企业提供所处外部环境下的竞争情报信息,便于其及时捕获市场动向,并预先制定危机管理方案与战略决策目标。
1理论基础
1.1弱信号
“弱信号”最早由Ansoff H在1975年提出,并将其定义为“未来可能发生变化的症状”。他认为弱信号是对外部或内部的警告,这些警告具有不完整性,无法准确预估其影响,一个组织要及时应对不确定的环境,就必须提前做好准备,对可能蕴含威胁和机会的信息迹象作出反应。此后,Coffman B、Kamppinen、Mendonca S等学者对弱信号的概念作出了进一步的补充,他们认为弱信号具有以下特征:不易追踪,与夹杂的噪声难以区分;琐碎、易被忽视,却对未来可能造成重大影响;未来改变和趋势的早期线索。
我国弱信号的相关研究起步较晚,但也提出了相对深刻的见解。沈固朝认为弱信号是通过对组织竞争环境中迹象的观察、业内人员意见的分析,对未来的趋势波动做出早期判断。单彬总结出弱信号“弱”的4大原因:①能被感知的弱信号量较少;②有效的信息难以被捕获;③误导或虚假信号与有效信息并存;④收集信号的成本和精力有限。赵小康指出弱信号在生长过程中表现渐趋明显、确定性不断增加、包含的有效信息量逐步丰富、作为决策依据的情报价值持续提高的4项主要特征。
通常,弱信号的检测过程是半自动的,根据专家提供的关键字分析数据。如[24]在中,过程的一部分是手动执行的,而[5]则使用了基于关键字的挖掘技术。一些学者试图实现全自动化弱信号识别来克服这一缺点。而弱信号检测的全自动化研究尚处于起步阶段,相关的论文和项目数量较少。Gutsehe T提出了一种运用动态主题建模和时间序列分析方法对弱信号进行自动检测和预测,并取得较好效果。因此,本研究遵循与其相同的完全自动化方法,并在其基础上对主题和术语进行双层深度过滤,以获得更好的弱信号识别效果。
1.2 LDA主题模型
LDA主题模型又称为隐含狄利克雷分布,是在预先规定的主题数量下通过最大化词语共现的概率从文本集中查找潜在和隐藏的信息,如在一篇新闻报道中“足球”“运动”之类的词总是同时出现,即可把其归为体育类。Blei D M等认为LDA能很好地对文档主题进行抽取。
在弱信号识别领域,LDA被广泛应用于隐藏信息的检测,但庄穆妮等指出LDA词袋模型的不足,即在LDA中一篇文档仅为一组单词的集合,词与词没有先后顺序,无法很好地结合上下文信息。Maitre J等提出运用Word2Vec方法增强LDA主题模型。Kahvun L等在比较NLP领域中Word2Vec和BERT算法时,发现后者更能体现词语在语义和语法方面的复杂性,对解决一词多义的问题更有帮助。因此,为了弥补LDA词袋模型的不足,增强识别弱信号的可解释性,在本研究中将引入BERT模型对LDA的处理结果进一步处理分析,使提取出的弱信号语义信息更精准。
1.3 BERT深度学习模型
BERT(Bidirectional Encoder Representations from Transformers,双向Transformer编码表达)模型由谷歌2018年推出,并在NLP领域11个方向的精度刷新上实现了突破性的进展。BERT以Transformer算法为主要框架,能更好地捕获语句中的双向关系,并使用遮蔽语言模型MLM(Mask Language Model)和句子预测NSP(Next Sentence Prediction)的多任务训练目标,使模型的结果达到了全新的高度。其中BERT的模型结构如图2所示。
在BERT模型中仅含有Transformer编码器的Encode部分,而其中含有的MultiHead和Attention机制使其掌握并存储了全文档的语义和语法关系,能够很好地对文本进行特征提取。同时,BERT基于Google预训练集的Fine-tunning具有强大的迁移学习能力,在多项NLP任务中具有优异的表现。因此,本研究将运用BERT模型对经过主题过滤和术语过滤两层过滤函数的LDA主题模型结果进行语义上的扩展,以获取更多在语义上与提取出弱信号相近的单词,增强模型的可解释性。
2弱信号自动识别方法框架
2.1方法概述
目前,弱信号的识别过程缺乏自动化,大多研究依赖于手工输入或专家意见。因此,为克服人类专家的干预,设计一个全自动弱信号识别方法,本研究考虑使用与主题建模相关的无监督文本挖掘技术。其中,LDA常用于从文本数据集中提取趋势主题。与依赖关键词进行弱信号检测的研究相比,主題模型更多的是考虑单词代表的意义,而不是其本身。本文运用LDA主题模型寻找可能导致弱信号的主题,但不接受所有主题中都含有弱信号,也不认为主题中的所有术语都为弱信号。因此,本文提出了主题过滤和术语过滤两层过滤函数,用于仅提取潜在的弱信号,并运用BERT深度学习模型对弱信号进行扩展。
其方法框架如图3所示。第一步,收集数据,本研究收集了一段时间的社交媒体新闻内容作为弱信号识别研究的输入。第二步,弱信号识别,包括数据预处理和弱信号过滤两部分。数据预处理是对收集的文本集进行去停用词、分词操作。弱信号过滤包括运用LDA主题模型识别主题、对提取出的主题和术语过滤,以寻找潜在的主题和弱信号。第三步,弱信号输出,运用BERT模型词嵌入来增强识别出的弱信号并输出。
该方法具有如下优点:①泛化。提取出的弱信号不针对某一特定领域或主题,而是在指定的某段时间内应引起重视的预警信息,决策者可以根据自己的需求选择相关的弱信号;②自动化。弱信号的提取过程中没有人工干预,也不需要关键词的帮助,全自动地对文本进行弱信号检测。
2.2数据收集和预处理
弱信号识别任务中,文本数据集的质量与弱信号检测结果的准确性、预见性有直接的关联,本研究运用Python工具进行数据收集和预处理工作,基本步骤如下。
1)文本数据收集。运用网络爬虫技术,从互联网中收集一段时间的新闻数据。本研究以社交媒体新闻为研究对象,因其具有传播范围广、传播及时性强、传播速度快等特点,对弱信号识别而言是较优的数据源。
2)文本集清洗与分词。对收集的新闻数据集进行基于中文停用词表的清洗,目的是过滤其中不相关、无意义以及非文本的信息。并运用Jieba对清洗后的数据进行分词,最终得到可用于系统输入的数据集。
2.3基于LDA-BERT融合模型的弱信号自动识别
2.3.1 LDA主题模型训练
LDA主题模型的主要挑战之一是确定最优的主题数k。超参数α和β的值分别表示文档主题密度和单词主题密度,它们在建立主题和术语之间的一致性上发挥着重要作用。
目前,研究人员提出确定最佳主题数k的主流方法有困惑度法和一致性法。困惑度值越小,则主题分类的结果越优,但赵凯等学者在进行主题分类时发现随着主题数量的增加,其模型困惑度值逐渐递减,难以确认最佳主题数k。与此同时,黄佳佳等学者提出一致性法来权衡主题质量,并发现基于此提取出的主题具有较高的可解释性,因此本研究遵循这种方法,并应用[34]提出的主题相关性度量值c_v确定最佳主题数。
为了找到一致性最高的模型,本研究采用控制变量法进行测试,每次运行仅改变主题数k的值,并保持其他参数值不变。使用c_v值作为一致性度量,并基于滑动窗口、标准化点互信息(NPMI)和余弦相似度确定其值,然后返回一致性度量最高的主题数k作为模型的最优结果。
2.3.2主题过滤
本节中提出的主题过滤函数,有助于评估主题含有弱信号的可能性,并用于对LDA主题模型提取出的主题进行过滤,该方法由Logistic函数推导而出。Logistic函数常用于说明人口的进步和增长,但在语言学中被用来模拟语言变化,一个边缘的术语随着时间的推移其传播速度会增加,但如果它是弱信号,传播速度增加后将仍处于边缘状态。
本研究定义如下3个度量函数以确定主题的弱性:紧密中心度、主题权重以及主题自相关函数。
第一个度量,紧密中心度。通过主题与主题之间的距离表示其相似性。许多距离度量可以用来计算相似性,如Jaccard距离、余弦距离和Hellinger距离。Pepin L等学者发现当距离测量呈现出S形变化时,能最有效地表示文本之间的相似度。基于此原则,本文选用Hellinger距离计算主题的紧密中心度。其中,h表示Hellinger距离。
第二个度量,主题权重。模型内相关主题的一致性代表着主题的意义分配。因此,本文基于主题z的一致性和所有主题一致性的总和来定义主题z的权重值W。其中,Coh(z)表示主题z的一致性大小。
第三个度量,自相关。自相关性是目前盛行的数据趋势分析工具,趋势分析是基于以往数据对未来可能发生情况的推测,它量化并解释了随着时间的推移混乱数据中的趋势和模式。自相关描述了同一变量在不同时期之间的关系,即变量对应值与其滞后变量对应值线性相关。而在新闻数据集中,与某个主题相关的文档频率会随着时间而改变,因此,每个主题在几天内的自相关性可帮助过滤出可能不包含弱信号的主题。自相关函数AC定义如下,其中Coy(z)k是主题z滞后k期的协方差。
利用上述3个度量函数组成评判主题弱性的函数WK,其函数值越低,主题内含有的术语越弱,但其当足够低时也可定义为噪声。定义主题z的弱函数WK(z)如下。
根据弱信号的定义,稀有是其主要特征,且随着时间的推移,它们的运动是缓慢的。因此只有WK函数低值对应的主题才被认定为弱主题。根据帕累托原则,弱信号形成的信息不超过20%,且在[24]中人类专家定义噪声的阈值范围为0%~2%,表示文本中携带无意义信息单词的概率。基于此,本文决定忽略WK函数的低值情况,并定义新的筛选阈值:噪声低于1%,弱信号低于15%。下图表示文本中的信号分布情况。
2.3.3术语过滤
基于定义的主题过滤函数能提取出可能包含弱信号的主题,但这些主题内的术语不一定都为弱信号,因此,本节将探讨如何从这些术语中有效地提取弱信号。
Chuang J等提出独特性和显著性两种术语衡量标准来判断某一主题中术语所传达的信息,以获得可理解的主题。其研究发现,单词由潜在主题生成的可能性与主题的边际概率之间的差异产生了显著性,而该显著性是属于总体频率和独特性的产物。同时,Sievert C等通过主题内不同术语的相关性以寻求该主题内最相关的术语,并取得相比于概率指标更优的结果。
综合上述,基于术语在主题中的概率和术语与主题之间的相关性,本研究提出一种新的术语过滤函数PW(w),其中,NF(w)是主题z中术语w的归一化频率,φ(w)表示主题z中术语w的概率。
同时,基于2.3.2主题过滤中所述,弱信号具有稀有性,因此本文仅提取PW函数值在1%~15%的項。
2.3.4弱信号输出
在主题过滤和术语过滤两层过滤函数下,能很好地对弱信号进行识别与提取,此外,对结果的分析与理解也至关重要。而弱信号稀有、微量的特点导致提取出的弱信号较少,为进一步获得与所提取弱信号相关的单词,提高模型结果的可解释性,本文使用BERT深度学习模型,将每个单词看作一个向量,重建单词上下文,使语料库中共享公共上下文的单词在语义空间上相互接近,并扩展与提取结果相似的弱信号。
本文遵循以往学者的研究,运用Google预训练的BERT模型,将每个过滤的主题文档作为模型输入,在经过训练后输出与提取弱信号高度相似的单词列表,以突出基于新闻数据集提取的弱信号,获得更强的模型可解释性。
3弱信号自动识别方法应用研究
弱信号在竞争情报中占有重要地位,多数企业也将弱信号识别作为其发展的重要目标。本研究将提出的基于LDA-BERT融合模型的弱信号自动识别方法应用于企业社交媒体发表的网络新闻,以检测一段时间内企业所处外部环境下的竞争情报早期预警信息。通过网络爬虫工具收集2020年11月1日—2021年1月的企业社交媒体新闻数据共计14486篇,并运用Python开源库Jieba、Gensim等对其进行分词、主题建模和自然语言处理等操作。
3.1 LDA主题模型训练结果分析
为找到最优主题模型对应的主题数k,本研究运用Gensim库中的LdaModel模块和pyLDAvis可视化工具,通过计算不同主题数下的一致性度量c_v值及其主题分布情况进行综合评判。
首先,本文对已进行清洗、分词等预处理操作的2020年11月1日—2021年1月的企业社交媒体新闻数据集进行LDA主题建模。其次,运用控制变量法测量不同主题数k下的一致性度量c_v值,并设定k值的范围为1~50。最后,综合不同主题数k的一致性度量c_v值及其主题分布情况选出LDA主题模型对应的最优主题数。模型结果如图5所示。
主题模型的一致性指数越高,其分类结果越优。在图5中,当主题数量k值为5或9时,模型的一致性指数取得较高值,同时,通过比对不同k值下的主题分布情况,发现当一致性指数较低时(如k=20、34、50),其主题分布呈现出不均匀且主题大小差异性较大的特点。因此,通过综合分析一致性度量c_v值及主题分布情况,本文认为企业社交媒体新闻数据集下的LDA主题模型最优主题数k值为9。
3.2主题过滤结果分析
对基于LDA主题模型提取出的9大主题,通过计算紧密中心度、主题权重以及主题自相关函数3大度量评判主题的弱性,过滤出可能包含弱信号的主题。
在本节中,首先计算每个主题与其他主题之间的Hellinger距离,得到一个9*9的距离矩阵以测量主题的紧密中心度。其次,运用Gensim库衡量每个主题的一致性,并代人权重函数W(T)以确定主题的权重。最后,基于所有主题每天的文档频率计算主题的自相关函数,其中函数滞后期的确定较为关键。通常,非重叠时间序列的自相关性低于重叠序列的自相关性,且数据越不重叠,其自相关性越低,而大多用于趋势分析的样本之间没有重叠,因此,观测较长滞后期的变化是有益的。
在弱信号检测中,本研究希望最小化主题过滤函数值,即IVK函数分母部分尽可能大,因此,拟通过设置较高的滞后期以减少时间序列之间的重叠周期,使得自相关函数AC最小化。因此,选择所观察数据周期的一半作为自相关函数的最佳时滞,即将滞后期定为15。
图6~图8分别显示了2020年11月、2020年12月和2021年1月的主题过滤结果。图中红色标记的是可能包含弱信号的主题过滤结果,这些主题的IVK函数值高于结果集的1%,而低于结果集的15%。
以月为观测周期,通过主题过滤函数从每月的9大主题中分别提取出T3、T7、T9 3个可能包含弱信号的主题,但这些主题内的术语并不都为弱信号,因此,本文还将通过术语过滤函数从其中抽取弱信号。
3.3术语过滤结果分析
LDA主题模型根据每个主题中术语出现的概率对其进行分组和排序。为尽可能地捕获主题内的弱信号,需要从主题中获取足够多的术语。因此,基于主题过滤结果,本文分别从2020年11月主题T7、2020年12月主题T3和2021年1月主题T9中提取500个术语,并统计每个术语对应的文档频率.运用术语过滤函数从其中提取出弱信号。表1~表3分别列出主题T7、主题T3和主题T9的弱信号提取结果。
表中部分单词已表现出与企业日常活动或所处环境的经济态势相关(已加粗),为增强模型的可解释性,运用BERT算法对过滤出的术语进行上下文预测,最大化目标单词的概率。
3.4弱信号提取结果分析
本文预挖掘某段时间内企业竞争情报相关的弱信号,尽可能地从社交媒体新闻数据集中获得更大的洞察力。因此,为弥补LDA词袋模型的不足,增强模型结果的准确性、可解释性,使用BERT深度学习方法在语义上扩展过滤出的术语,赋予弱信号更多的情景信息与类似的单词。表1中“协作”一词与本文研究的内容略相关,对其进行扩展后,发现一些重要的弱信号,如“团结”“合营”“资源”“共享”等。
同时,信号的演变在提取结果中也得以显现,如在2020年12月主题T3过滤的术语中,“持续”“恶化”“增加”之类的弱信号开始向“爆发”“感染”“复苏”等词转变,而在2021年1月初主题T9过滤出的弱信号中已变为“紧急”“严重”“威胁”等词,结合年初疫情暴发的背景.可挖掘出弱信号随时间增强的特性。
此外,提取出的弱信号也为企业提供了相关竞争情报信息,本文将从企业外部环境经济态势和企业日常活动开展两方面进行具体分析。
1)企业外部环境经济态势相关。如,2020年11月T7中提取出的“国际”,2020年12月T3中提取的“自贸区”“全球性”等都表现出我国经济向着国际化方向发展的态势。其中,“自贸区”源于东盟十国和中国、新西兰、日本、澳大利亚、韩国共15个国家共同签署的《区域全面经济伙伴关系协定》,是当前世界经贸规模最大、人口最多、最具潜力的自由贸易区。与此同时,在2020年11月,中国上海举办的第三届中国国际进口博览会中,食品及农产品、汽车、技术装备等6大展区中累计意向成交达726.2亿美元。在此态势下,企业应把握时代的契机,加强与其他国际企业之间的合作,寻求自贸区中可协同稳定发展的商业伙伴,并紧跟国家经济政策,及时制定企业国际化发展战略,向成为国际化优质企业进军。
2)企业日常活动展开相关。如,2020年11月T7中提取出的“协作”一词,运用BERT模型丰富其语义信息后,得到如“互助”“共赢”“资源共享”等词。而在当月,苹果、谷歌继诺基亚、高通、三星、英特尔、LG电子等多家信息公司后也加入美国NeXt G AHiance 6G联盟,表现出企业与企业之间加强合作、互惠互利更利于彼此的发展。此外,2020年12月T3中提取出的“媒体”一词结合2021年1月中的“推广”一词,表示企业在互联网时代下应注重其媒体推广,结合其目标客户媒体及推广方式的偏好,有针对性地展开定向推广活动。
综合上述,本研究提出的基于LDA-BERT融合模型的弱信号识别方法很好地基于企业社交媒体新闻数据集检测出企业外部环境经济态势和企业日常活动开展相关的弱信号,同时对其综合进行分析与理解,发掘出弱信号随着时间的推移,部分在语义上会逐渐增强的演化特性,为企业决策者进行危机预警和战略决策管理提供有益参考。
4结语
本研究提出一种基于LDA-BERT融合模型的弱信号自动识别系统。运用无监督学习算法LDA对预处理后的企业社交媒体新闻数据集进行主题分类,并提出主题过滤和术语过滤双層过滤函数分别用于从LDA主题模型结果中过滤出可能包含弱信号的主题,以及仅从主题中提取可能为弱信号的术语。其中,主题过滤基于3大度量函数评判主题的弱性:紧密中心度用Hellinger距离衡量主题与主题之间的相似性,主题权重以一致性大小衡量主题的重要性,自相关性在设定的滞后期下观测主题随时间的演变。本研究不接受主题过滤结果中的术语皆为弱信号,因此运用术语过滤函数,以主题内术语的归一化概率和术语对应的文档频率构建模型,仅保留其中潜在的弱信号。最后,为弥补LDA词袋模型的不足,增强模型的可解释性,将双层过滤函数的结果输入BERT深度学习模型,并输出一系列早期预警信号,可在语义上扩展单词,丰富提取出的弱信号,从上下文中赋予其更多含义。
对该模型进行测试,以识别一段时间内企业竞争情报相关的弱信号。利用2020年11月—2021年1月的企业社交媒体新闻数据集,本文成功检测出如“自贸区”“国际”“协作”“推广”等与企业外部环境经济态势和企业日常活动开展相关的弱信号,并以月为周期对提取出的弱信号进行综合分析,发现其随着时间的推移,部分在语义上会逐渐增强的演化特性。本模型解决了当前弱信号识别领域研究人工参与较多、主观性较强的问题,实现了全自动化的弱信号检测过程,大大减少了人类专家的时间和成本。同时提出LDA-BERT融合模型及双层过滤函数,在既保障仅提取相关弱信号的前提下,又充分合理地对弱信号在语义上进行扩展,使模型结果具有较高的解释能力,为情报搜集工作中的弱信号检测提供了新方法、新思路。
此外,本研究仍存在些许不足,由于弱信号与噪声都具有微量、当前意义不明确、运动缓慢的特点,导致文本去噪工作开展得不够完全。本研究通过设定较长的滞后期,运用其自相关性能有效的过滤出部分文本噪声,同时也可能过滤出少许有一定价值的弱信号,不能完全无损的从文本集中对其进行提取。因此,未来将着重研究弱信号识别领域的文本去噪工作,为决策者提供更精准的预警信息。
