商业银行反洗钱智能识别模型应用探析
2021-09-06王巍栋王彦博邓昌智马羚
王巍栋 王彦博 邓昌智 马羚

在当前科技与金融深度融合的时代背景下,我国反洗钱监管体系不断完善,惩罚力度不断加强,各金融机构的反洗钱监测系统亟须借助大数据、数据挖掘、机器学习、图计算等智能技术进行迭代升级。本文从商业银行反洗钱业务实际出发,对构建反洗钱智能识别模型存在的难点进行归纳,并创新提出商业银行构建反洗钱智能识别模型的“GREAT框架”。而后,针对反洗钱样本数据量大但正负样本极度不平衡的特点,运用仿真模拟方法对数据进行样本衍生,再运用有监督学习中解释性较强的逻辑回归模型实现对反洗钱可疑模型的构建,同时借鉴金融风控场景中经常使用的评分卡模型对逻辑回归模型结果进行从评分向用户得分的转换,并将优化后的模型在商业银行反洗钱领域尝试应用。相较于传统的规则模型,优化后的模型在保证覆盖率的前提下,筛查效率大幅提高,能够有效提升反洗钱业务的报送效率。
我国商业银行反洗钱业务现状
反洗钱、反恐怖融资工作是推进国家治理体系和治理能力现代化、维护经济社会安全稳定的重要保障。当前,我国对反洗钱的监管和惩罚力度日渐增强。2021年4月16日,央行发布了《金融机构反洗钱和反恐怖融资监督管理办法》,进一步明确并完善了我国的反洗钱监管措施。
洗钱活动主要发生在金融领域,处于反洗钱核心地位的商业银行等金融机构均已依据中国人民银行发布的《金融机构大额交易和可疑交易报告管理办法》等相关要求,建立了一套完整的反洗钱监测报送系统。在每个交易日日终时,将当天交易数据传送到反洗钱系统,然后经过可疑模型筛选出可疑客户以及对应的交易数据,推送给反洗钱相关工作人员,待人工调研审查核对后统一报送至上级部门。面对数量庞大的可疑交易数据以及每日不断累积的亟待审核的可疑交易数据,工作人员需要在一定时间周期内完成所有被反洗钱系统可疑模型判定为疑似参与洗钱活动的客户以及相关交易的数据审查,人工审核工作量巨大。除了审核工作本身繁杂耗时之外,往往需要联系到客户本人或者相关人员对客户进行身份核实以及交易信息核验,因而人工成本高昂、效率难以提高。
因此,充分运用大数据和人工智能等新兴技术,对现行的反洗钱可疑模型进行迭代升级,以科技赋能反洗钱业务提质增效,已成为金融科技时代商业银行反洗钱业务发展的必由之路。传统的反洗钱可疑模型是根据中国人民银行发布的相关管理办法来进行规则设计,进而构建的规则模型,未能充分利用相关业务数据的潜在价值。而运用数据挖掘、机器学习等智能技术对反洗钱可疑模型进行优化,在参考中国人民银行相关管理办法的基础上,更加注重相关业务数据本身的信息含义,挖掘和学习数据中的规律,提高可疑模型的精确度,使其能够更加精准地定位洗钱活动相关客户及交易,降低人工审核工作负担。对反洗钱可疑模型的优化不仅能够将传统可疑模型筛选出的疑似洗钱交易数据量进行大幅缩减,而且能够尽可能全面地发现参與洗钱活动的客户及相关交易情况。
基于“GREAT框架”视角的反洗钱智能识别技术
基于当前反洗钱业务的发展现状和数据特点,数据挖掘与机器学习建模主要存在三方面技术难点:一是正负样本极度不平衡;二是由于业务冷启动造成的数据积累不足、样本规模小;三是模型的精准度不足。针对上述难点,结合商业银行业务实践,本文创新提出以智能化算法建模解决反洗钱监测识别问题的“GREAT框架”,即运用图技术(Graph based techniques)、强化学习技术(Reinforcement learning techniques)、集成学习技术(Ensemble learning techniques)、仿真模拟技术(Analog simulation techniques)和迁移学习技术(Transfer learning techniques),以期为反洗钱监测识别的智能化应用提供技术支撑。
通过图技术(Graph based techniques)实现反洗钱客户关联关系挖掘。在反洗钱客户身份识别工作中,大量的客户身份信息不完整,导致系统智能识别的效果有限,大量工作需要人工介入参与。针对该难点,可运用“图技术—知识图谱”技术,对企业和个人的交易、法人、股权等错综复杂的关系进行挖掘,通过客户关联关系洞察和异常关联结构挖掘,快速发现符合反洗钱特征的异常图结构模式,识别可疑账户群组,识别反洗钱团伙,实现数据甄别分析智能化。
通过强化学习技术(Reinforcement learning techniques)实现小样本下模型权重优化。由于模型的训练过程受到样本数量限制和分布的影响,传统的反洗钱模型往往存在泛化能力不足的问题。强化学习技术为进一步提升模型泛化能力、提高预测结果准确性提供了有效的解决思路。以初期积累的小样本数据作为初始状态构造初始化的模型,通过深度强化学习算法对初始模型进行调整,并利用调整后的模型和环境进行交互,得到交互后的新状态和相应的奖励。如此反复循环,在过程中不断优化,最终生成不同状态下的优化模型,从而尽可能优化对洗钱客户的识别准确率,进一步提升模型的泛化能力。
通过集成学习技术(Ensemble learning techniques)解决可疑交易的漏报问题。在反洗钱工作的长期开展过程中,由于犯罪分子已经较为熟悉相关法律和管理办法,传统依托规则设计的可疑模型往往难以识别犯罪分子参与的洗钱交易,从而导致可疑交易的漏报。事实上,每天都会有海量交易数据进入反洗钱监测系统,其中绝大多数正常交易数据可以通过可疑模型直接过滤掉,大量被可疑模型命中的交易数据会转交至人工审查。但也存在部分可疑交易未被模型识别的情况,若人工对该部分数据也无法覆盖,则可能造成漏报情况。因此,反洗钱可疑模型的精准度至关重要。
集成学习通过训练多个弱分类器,将每个弱分类器的结果进行投票,往往能产生优于单一机器学习模型的查准率和查全率。因此,集成学习较传统机器学习模型有更高的坏样本覆盖能力,可有效减少漏报问题。有金融机构采用多数投票规则,将多种机器学习算法构建的模型进行集成融合,对反洗钱可疑模型的精准度进行提升。
通过仿真模拟技术(Analog simulation techniques)解决样本不平衡问题。反洗钱数据的普遍特点是样本数据量极大,但是正负样本极度不平衡,上报样本数量远小于非上报样本数量。极度不平衡样本又可归纳为两类,一类是上报样本数量虽然远小于非上报样本数量,但是上报样本数量本身具有一定规模,则可以运用对非上报样本随机欠抽样的方法来解决;另一类是上报样本数量极少,且在比例极其悬殊的情况下,则可以运用仿真模拟的方式衍生上报样本数据。本文将详细探讨样本衍生在反洗钱场景中的应用案例。
通过迁移学习技术(Transfer learning techniques)解决样本规模小的问题。现实中,数据往往是孤立的,同行业数据无法共享,即便是同公司,不同部门之间的数据也常常是独立存储和维护的。对于一些交易流水较少的金融机构来说,往往会遇到样本规模小、数据不足的情况;在跨机构、跨地域、跨境合作的场景下,存在不同区域特征差异大和数据分布偏移等特点,导致直接合并数据来建模不能满足传统机器学习对于建模数据独立同分布的首要条件。因此需要优先解决数据与模型泛化能力的矛盾。迁移学习是解决小样本机器学习模型泛化能力问题的一种有效手段,它可以基于现有数据,运用更加复杂的迁移学习方法,学习形成一个泛化能力强的模型。有金融机构运用迁移学习技术,在不同分行间实践并验证了嫁接迁移、样本迁移及特征迁移技术的可行性和有效性。
基于仿真模拟技术的商业银行反洗钱可疑模型实践案例
本文选取某股份制商业银行反洗钱某场景下的数据作为研究样本,运用前文“GREAT框架”中的仿真模拟技术(Analog simulation techniques)进行样本衍生,以解决该银行此场景下的正样本(上报样本,占整体样本的少数)不足的问题。样本衍生即对正样本进行过采样。常用的过采样方法,如简单过采样方法,一般直接复制少数类样本。由于该方法的本质是对相同数据的重复学习,其优点是容易实现,而缺点是容易导致过拟合问题。无论是从账户角度还是用户角度出发,反洗钱样本数据维度多,每个账户对应拥有上百种特征变量,且其中包括连续型和离散型特征。本文针对不同数据类型的特征提出不同的仿真构造方法,具体内容如下。
连续型特征样本衍生
对于连续型特征,如交易额、交易频率等,采用SMOTE (Synthetic Minority Oversampling Technique,合成少数类过采样技术)方法构建新样本。SMOTE算法的核心逻辑是:对于上报客户群体数据集α中的每一个样本a,根据样本的连续性特征,以欧式距离为标准计算它到上报客户样本集中其他所有样本的距离,升序排列后选择前K个样本作为其K近邻。从K个近邻中随机选择一个近邻b,按照公式c=a+rand(0,1)*|a-b|进行线性插值,构造新的样本点c,重复选择N次完成N个新样本点的构造,N为衍生样本构建的倍数(见图1)。
在运用SMOTE进行过采样之前,需要对样本进行清洗,去除其中的异常值,避免插值衍生过程产生大量噪声样本,影响模型效果。
离散型特征样本衍生
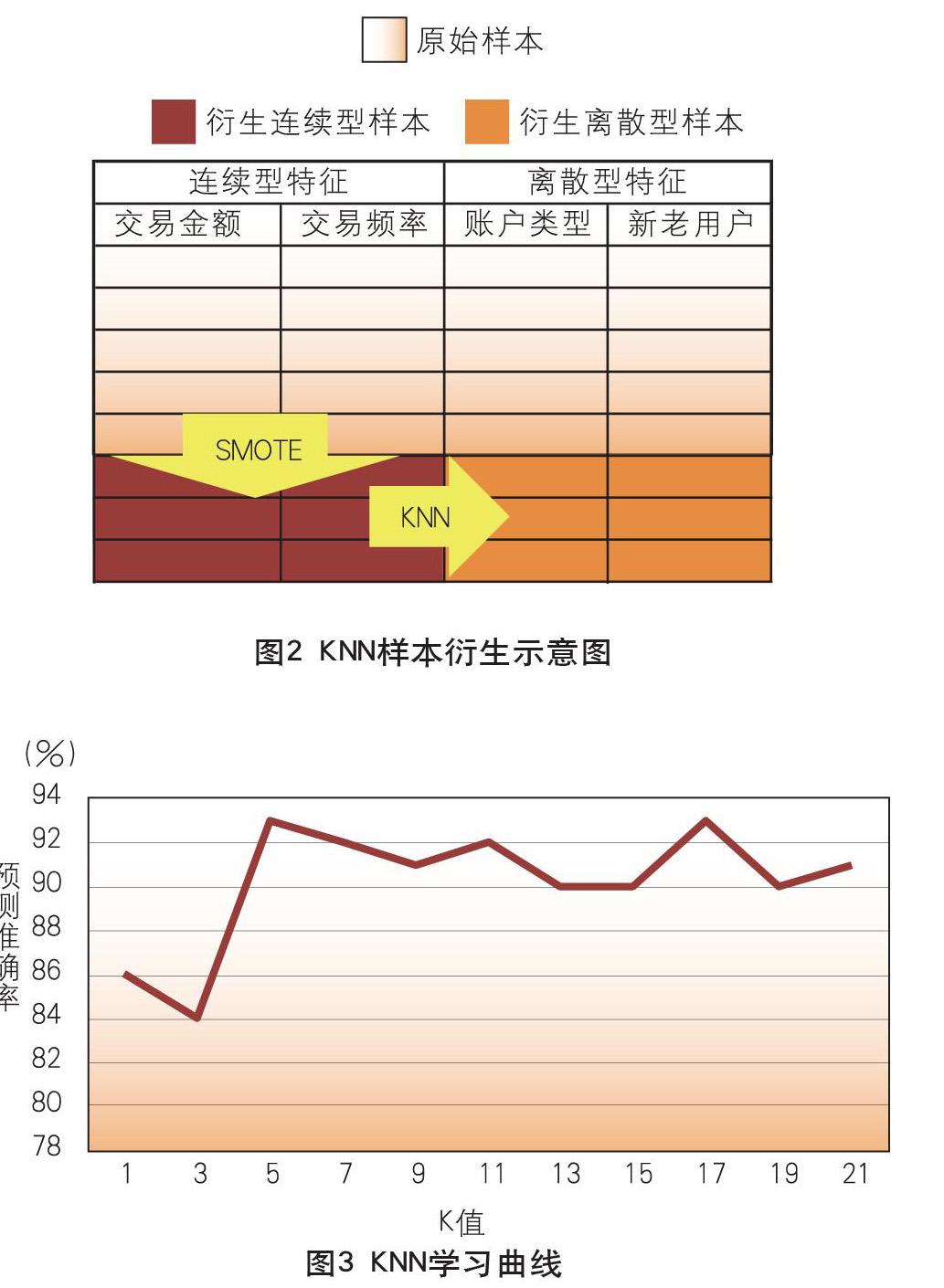
对于离散型特征,如账户类型、是否新老用户等,可以转化为多分类问题,将衍生的连续型样本数据作为入模变量,拟构造的离散型特征作为目标变量进行衍生。因此,有监督机器学习相关分类算法,如KNN(K-Nearst Neighbors,K近邻算法)、随机森林、SVM(Support Vector Machines,支持向量机)等均可适用。本文采用KNN算法,其核心逻辑是对于衍生的连续型数据集β的每一个样本A,以欧式距离为标准计算它到上报客户样本集α所有样本的距离,升序排列后选择前K个样本作为其K近邻。对于上报客户样本的每个离散型特征B,选择K近邻中占比最大的特征取值作为A样本离散型特征的取值,以此类推, 完成A样本所有离散型特征的取值,则衍生样本构建完成。KNN 算法的优点在于易理解,适合于多分类问题,对于作为目标变量的多类型离散型特征具有较好的适用性(见图2)。
模型调优
在样本构建过程中,SMOTE和KNN都涉及对样本K近邻的确定,即确定距离样本最近的K个样本。在关键参数K值的选择上,如果K值设定过小,容易受到训练数据噪声的影响,导致过拟合;如果K值设定过大,则会受到距离较远的错误样例的影响,导致学习效果不佳。因此,考虑根据原始样本数据构造学习曲线,分析KNN关键参数K值与KNN算法拟合效果的关系,选择学习曲线中拟合效果最优的节点,以此节点的K值作为参数应用KNN,如图3所示。基于上述逻辑,本例中KNN预测效果最佳的K值为5。
需要注意的是,在样本构造过程中,SMOTE和KNN都是基于距离的算法,需要对样本数据进行标准化或归一化处理,将有量纲的数据转换为无量纲的数据,避免样本数据量纲不统一造成的偏差。
模型结果
本研究采用逻辑回归模型,目标变量为“是否上报”的二分类标签。相对于难以解释的深度学习模型,逻辑回归模型可以充分满足监管机构对洗钱活动认定的解释性要求,通过对特征进行分箱处理,根据特征系数可以看出不同特征对最后预测结果的影响,能够直观展现客户为何被判别为进行可疑交易,符合反洗钱系统需要对所有筛选出的可疑交易明确涉罪类型的要求,为人工复核提供排查方向和内容。
经过前期的数据清洗、筛选等处理后,样本与特征均已达到了入模的标准,即可构建模型,逻辑回归模型结果为:AUC为0.82,KS为0.57,模型拟合效果良好,能够较好地区分正负样本,最后将对目标变量的预测结果映射为分数,能够更加直观地表现各账户上报概率的预测结果以及预测值与其影响因子的关联关系,便于设定阈值划分样本。在逻辑回归阈值的选择上,与传统的逻辑回归以0.5为阈值不同,需要人工设定预警分数,超过预警分数的样本即认定为上报样本。在業务实践中,业务分析人员可以动态调整预警分数,在筛查效率与涉罪样本覆盖率之间权衡,虽然降低预警分数阈值可以提高涉罪样本覆盖率,但会降低筛查效率。在本例中,采用逻辑回归模型相较于传统规则模型, 可以在实现覆盖规则模型筛查出的78%上报样本的同时,成倍降低业务人员人工复核工作量,大幅提升相关业务的工作效率。
结语
在商业银行反洗钱管理的业务实践中,实现反洗钱智能识别模型准确率最大化、降低人工筛查成本和误报率,已成为各商业银行的迫切需求。为解决该类问题,本文创新性地提出了一套基于图技术、强化学习、集成学习、仿真模拟和迁移学习等新兴技术的“GREAT框架”,并针对该框架中仿真模拟技术在商业银行反洗钱业务的应用进行实证分析。实证结果显示,该方法可以在保证查全率的基础上,提高筛选排查的查准率,能够帮助银行相关业务部门开展高效、准确的反洗钱工作。
龙盈智达(北京)科技有限公司何姗、甘睿、张月、史杰、徐奇、杨璇对本文亦有贡献。
(作者单位:华夏银行法律合规部反洗钱管理室,龙盈智达〔北京〕科技有限公司,中科金审〔北京〕科技有限公司)
