基于BERT与BiLSTM的铁路安监文本分类方法
2021-09-06张世同
张世同
(北京云至科技有限公司南京分公司,数据服务产品研发部,南京211801)
0 引言
铁路安监部门检查安全生产事故隐患,将运输、设备、工程中可能导致安全事故的隐患及风险因素以文本形式记录下来,并根据发牌制度,确定隐患分类,对应问题库,以确定责任部门和责任人。目前,铁路部门已经形成问题库,积累了大量的文本数据和分类数据[1]。为了更好地实现自动分类,解决目前分类完全靠人为经验的缺陷,采用人工智能文本分类,准确地对应到问题库中,可以确定责任人,以增强管理力度和规范化作业意识。铁路安监文本示例如表1所示。

表1 铁路安监检查文本分类示例

续表
现有的文本分类有基于词汇特征的TF-IDF和Word2Vec方法,基于深度学习的TextCNN和BiLSTM方法。TF-IDF通过词频统计,将文本转化为一个词频向量来提取文本特征。如果一个单词在该文本中词频非常高而在其他文本中词频较低,则认为该次对该文本有较大意义,因此可以对该单词的权重进行正向调整。随着词汇数量的增加,TF-IDF会出现维度爆炸的问题[2]。TF-IDF依赖于文本预处理时进行中文分词,目前的分词效果都不理想,特别是出现多义词的时候。铁路安监文本库中,文本描述有大量的术语,使得分词效果更加不理想,如“某车次副司机升降弓时未手比确认升降弓过程”。同时,TF-IDF仅仅考虑词本身,而为忽略了词的上下文语境信息[2]。
Word2Vec基于浅层神经网络进行文本特征提取,将词语表示成稠密向量,文本表示成向量矩阵,使用Skip-Grams和CBOW(Continues Bag Of Words)来建立词嵌入向量,降低了计算成本的同时提高了表示精度。借助Word2Vec的窗口化提取特征方法,可以获取词汇近距离前后文信息,但无法考虑到上下文信息[3]。LU等使用基于字符的Word2Vec(CLW2V)方法,使用CLW2V+CNN的模型,将铁路安监文本分类的Precision、F1分别提高到85%、83%[4]。
BiLSTM(双向长短期记忆网络对语言模型)实现了基于上下文的词嵌入表示,并显著提高了模型上下文的表示能力。Yang等人在Bi-LSTM-CRF融合模型的基础上引入了Attention机制并将该模型应用在生物文本实体识别上并获得了90.77%的F1值[6]。
2018年谷歌公司提出了BERT预训练模型,该模型文本向量化是基于字符的,结合BiLSTM能更好地表示上下文信息。DU等人采用BERT-BiLSTM-Attention-Softmax模型,对中医病例文本提取和自动分类研究,获取了89.52%的F1值[5]。LIU等人采用BERT-BiLSTMMultihead-Attention模型,进行二分类的中文文本情感分析,获得了93.06%的F1值[9]。
基于上述分析,针对铁路安监文本具有专业术语多、文本表述简单的特点,本文采用BERT作为字向量的提取方法,提出了BERT-BiLSTM-Softmax模型用于铁路安监文本分类研究。
1 BERT-BiLSTM-Softmax模型设计
在BERT预训练模型的基础上,对文本进行词嵌入向量表示,BERT模型最后一层的输出作为BiLSTM的输入,并使用已标注铁路安检文本进行训练,对BERT层进行参数微调。在BiLSTM中把双向加权向量全连接,输出一个新的向量给Softmax函数进行分类。BERT-BiLSTM-Softmax网络模型结构如图1所示。
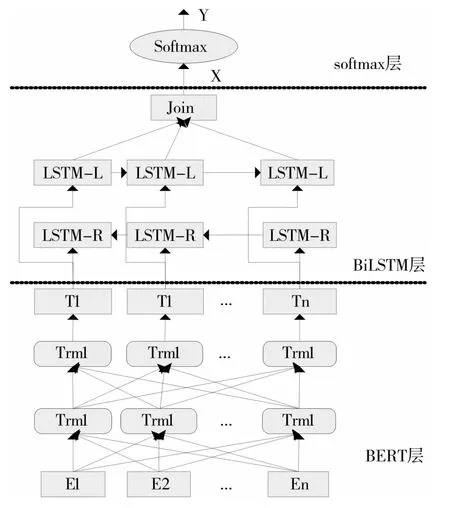
图1 BERT-BiLSTM-Softmax网络模型结构
Softmax函数用于多分类问题,对待分类文本计算每个可能分类的概率。Softmax函数形如公式(1):
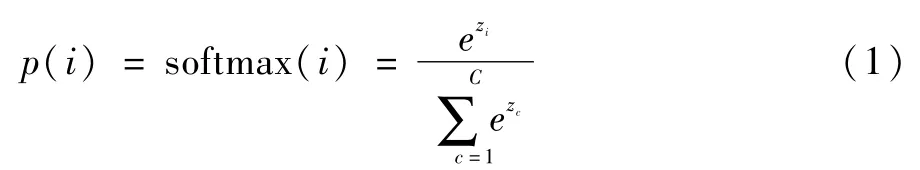
其中p(i)表示第i个类别的概率,zi为第i个节点的输出值,C为输出节点的个数,即所有类别个数。通过Softmax函数就可以将多分类的输出值转换为范围在[0,1]和为1的概率分布。使用交叉熵损失函数作为Softmax的Loss函数,如公式(2):
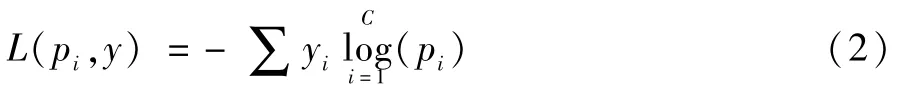
1.1 BERT预训练模型
Transformer方法通过计算目标词与源文本每个词之间的相似度作为权重系数,对其进行加权求和表示词向量,实现关注和提取上下文重点信息。Transformer使用了Attention机制的同时,提出Self-Attention结构,并结合Multi-Head Attention能够同时获取上下文信息。Transformer大量应用在预训练模型中,如GPT(Generative Pre-trained Transformer),如图2所示。
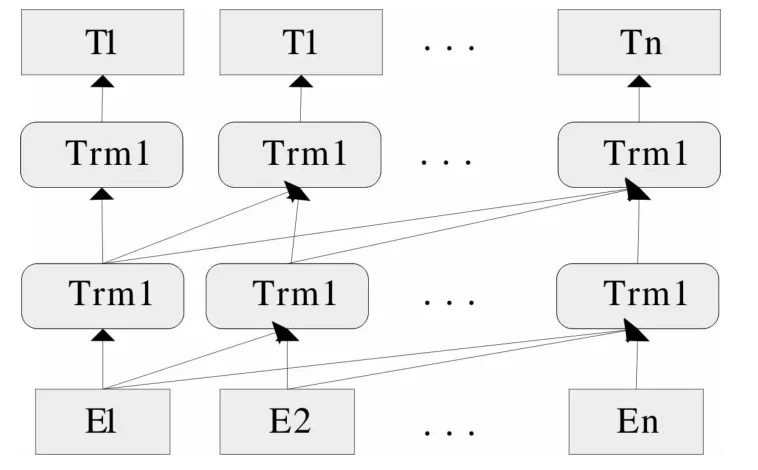
图2 GPT模型结构
BERT采用多个双向Transformer编码器层堆叠组成全连接神经网络结构,相比于GPT模型,BERT采用双向方法,能够同时捕获上下文语境信息。BERT采用多层Transformer作为核心架构进行特征提取的半监督学习模型,先进行无监督训练,经过多层神经网络训练,形成文本词向量表示。以最后一层的词向量作为后续任务的输入并结合Fine-tuning微调方法可以使用少量标注文本进行训练和参数调整达到较好的准确率。如图3所示。

图3 BERT模型结构
图中w是文本词嵌入向量,BERT采用词嵌入向量由三部分组成:Token、Segment、Position。第一个Token是CLS标志,可以用于之后的分类任务,为区别两个句子,用一个特殊标志SEP隔开它们。针对不同的句子,把学习到的segment embeddings加到token的embedding上面。最终的词嵌入向量E由三种向量求和而成E,E作为多层双向Transformer的输入。
1.2 BiLSTM层
在经典的RNN算法中,存在长期依赖问题(Long-Term Dependencies),LSTM采用长短期记忆网络的方法解决了这一问题。但是在文本中,词的信息不仅与上文有关,还与下文有关。所以,采用BiLSTM取代LSTM,可以全面地获得词语的上下文信息。BiLSTM由左右双向的LSTM叠加而成的,其模型结构如图4所示。
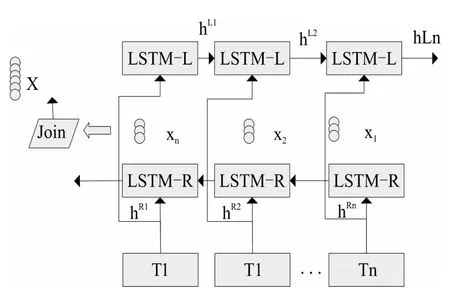
图4 BiLSTM模型结构
其中T为输入的词嵌入向量,经过分别经过左右向LSTM计算输出为hL向量和hR向量。最终的x向量是由hL、hR通过线性函数计算获得。
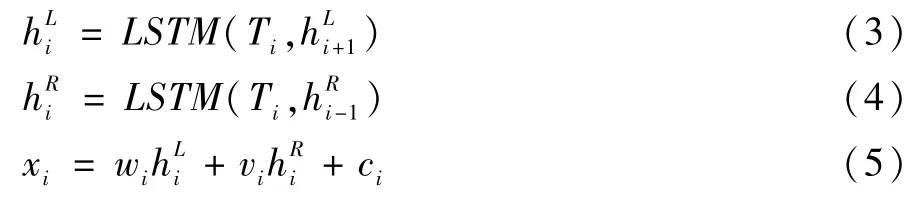
其中w、v分别为左向输出的权重向量和右向输出的权重向量,c为偏移向量。xi组成最终的输出向量x=(x1,x2,…,xn)。
2 实验步骤
2.1 数据预处理
本文使用某铁路集团公司机务、车务安检文本分类数据分别120043条和68780条,两数据集简称为DS01、DS02。均使用20%作为测试数据,80%作为训练数据。对DS01、DS02安检文本的二级分类进行训练和预测,DS01、DS02两数据集二级分类分别为16、8个。首先对安检数据格式化为类别和问题内容两个属性,再把问题内容文本中的标点符号剔除。数据集如表2所示。
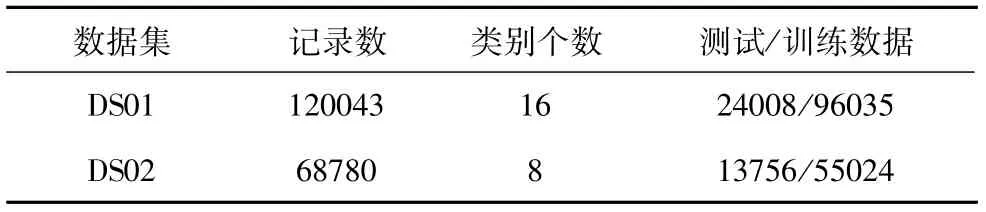
表2 数据集概况
2.2 实验环境
编程语言使用Python 3.7,使用Keras深度学习框架,它封装了BERT和TensorFlow。服务器环境使用NVIDIA推出GPU计算框架CUDA(Compute Unified Device Architecture),显存设置为4038MB。
2.3 参数设置
BERT网络结构网络层数为12,隐藏层维度为768,Multihead-attention个数为12,总参数大小为110M。文本词向量长度设置为150,batch-size设置为9,epochs设置为20。BiLSTM的层数为1,隐藏层神经元个数为128,设置dropout为0.1。采用Adam优化器,学习率为1e-5。迭代过程中设置Early-Stopping机制,监控accuracy最小变化为0.02,容忍度为3。
2.4 实验结果分析
本文分别在DS01、DS02上进行三组实验,分别得到TextCNN、BiLSTM-attention、BERT-BiLSTM三种模型的实验数据,比较loss、accuracy、precision、recall、F1-score几种指标。Accuracy代表测试的准确率,Precision代表精确度,Recall代表查全率,F1-score是Precision和Recall的调和平均值。公式如下,其中,TP表示把正样本成功预测为正;TN表示把负样本成功预测为负;FP表示把负样本错误地预测为正;FN表示把正样本错误的预测为负。

DS01、DS02的数据集实验结果如表3、4所示。

表3 DS01数据集实验结果
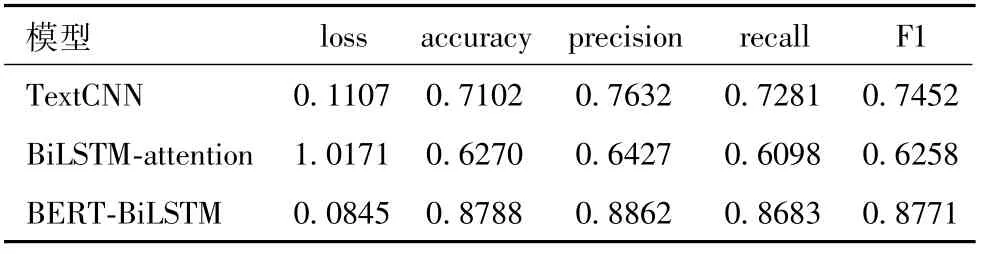
表4 DS02数据集实验结果
本文采用20个Epochs进行迭代,观察Precision、Recall、F1-score的变化情况,如图5、6所示。

图5 DS01数据集的预测指标变化趋势

图6 DS02数据集的预测指标变化趋势
由图5-6可知,使用BERT预训练模型提取文本特征,结合BiLSTM双向长短记忆模型用于铁路安监文本分类,较传统的TextCNN分类模型和单纯的BiLSTMattention模型在Precision、F1-score等指标上有显著提升。采用BERT的多层双向Transformer机制和Finetuning微调机制在标注训练文本较少时,能有效提升模型训练效率,提升预测精确率和准确率。根据图5、6所示,使用预训练模型的BERT-BiLSTM,能在训练开始就能获得较高的F1-score,说明BERT预训练模型的能显著提高训练效率,使用较短的GPU训练时间,就能获取很好的效果。
3 结语
本文通过BERT-BiLSTM-Softmax模型显著提高了铁路安监文本分类的精确率和F1值,帮助铁路安检系统实现智能辅助发牌功能,优化了铁路安监发牌流程,提高了安监系统的实施效果。随着高铁事业的跨越式发展,目前的安监问题库不能准确覆盖所有的检查问题情况,因此在安监系统实施中存在大量主观臆断为一个任意类型的情况。因此,下一步可以对安监文本进行离异点分析,找出离异点数据,通过专家系统进行标注,扩充问题库,进而不断训练更新分类训练模型,保持铁路安监发牌系统持续发展。
