基于卷积神经网络的飑线识别算法
2021-09-03金子琪王新敏鲍艳松路明月
金子琪 王新敏 鲍艳松 栗 晗 魏 鸣 路明月
1)(中国气象局·河南省农业保障与应用技术重点开放实验室/河南省气象台,郑州 450003) 2)(南京信息工程大学气象灾害预报预警与评估协同创新中心/中国气象局气溶胶与云降水重点开放实验室/气象环境卫星工程与应用联合实验室,南京 210044) 3)(南京信息工程大学大气物理学院,南京 210044) 4)(南京信息工程大学地理科学学院,南京 210044)
引 言
飑线是由许多雷暴单体侧向排列而形成的强对流云带,是一种典型的中尺度对流系统,其水平尺度长、宽均约几十至上百千米,持续时间为几小时至十几小时。飑线出现时通常伴有雷暴、大风、冰雹等灾害性天气,给人民生活和社会生产带来极大危害。2004年7月12日苏南至上海地区发生强飑线过程,产生8~11级雷雨大风 ,经过闵行华漕地区时出现龙卷,造成多处房屋倒塌,死亡7人,伤及多人,部分地区因高压线损坏停电[1]。2009年6月3—4日河南、安徽等地遭遇罕见强飑线袭击,导致河南省的商丘、开封和济源24人死亡,81人受伤,直接经济损失达16.069亿元[2]。2017年7月7日下午至午夜,河北西北部与北京中北部发生一次罕见强飑线过程,导致较大范围的雷暴大风和短时强降水等强对流天气;北京全市范围出现8级以上短时大风,并伴有雷电、冰雹及短时强降雨,延庆、昌平、怀柔、门头沟、平谷、朝阳出现10~11级短时大风[3]。
雷达资料具有高时空分辨率的特点,对中尺度对流系统的监测和临近预报具有独特优势,借助计算机自动识别包括飑线在内的各类短时强对流性天气,能够帮助气象工作者更加及时地分析海量观测数据,对天气形势做出判断。目前基于雷达数据对中尺度对流系统的自动识别和预报已发展出多种算法,如基于交叉相关法的利用相关跟踪雷达回波(tracking radar echoes by correlation,TREC)[4]、基于单体质心法的风暴识别、追踪、分析和临近预报(thunderstorm identification,tracking,analysis,and nowcasting,TITAN)[5]以及风暴单体识别、追踪和预报算法(storm cell identification and tracking algorithm,SCIT)[6]等,这些算法已成为各短时临近预报系统的重要组成部分[7-8]。还有学者提出专门针对飑线的自动识别算法,杨吉等[9]拟合椭圆长轴设计动态模板和得分函数,实现雷达拼图线状中尺度对流系统的自动识别和跟踪,其线性得分值能较好地反映中尺度对流系统各阶段的线性状态,但算法在系统分裂与合并时跟踪效果较差,且不适用于“厂”字型等其他类型的飑线。程凌舟等[10]针对飑线中心强度较强且连接成线的特征,基于小波变换模极大边缘检测理论和Hu矩理论计算雷达回波图像的特征向量,当模板矩特征向量与待匹配图像矩特征向量的欧氏距离小于设定阈值时,将目标识别为飑线。李哲等[11]在杨吉等[9]的基础上提出一种飑线优化识别算法,采用4种不同参数方案,根据回波强度自动挑选最优方案,能够同时识别不同强度或不同发展阶段的飑线,比单一参数识别效果明显改善。上述方法均属于人工提取特征法,核心思路是提取飑线的若干图像特征作为因子,将其放入数学模型,并与事先设定的阈值进行对比从而识别飑线。
人工智能自20世纪90年代开始应用在气象领域,如台风预报、降水预报、云分类、大气廓线反演等[12-16]。深度学习是人工智能中神经网络算法的一个新分支,常见的深度学习模型有卷积神经网络(convolutional neural network,CNN)、深度信任网络(deep belief network,DBN)、堆栈自动编码器(stacked auto-encoder,SA)、受限玻尔兹曼机(restricted boltzmann machine,RBM)等。深度学习的概念起源于人工神经网络,本质上是堆叠多个隐含层的深度网络,相比于传统的人工神经网络具有更多的隐含层和更复杂的网络结构,通过组合低层特征增加网络深度和非线性变换能力,将原始特征映射为更加抽象的高层特征,以更好地发现数据的有效特征表示[17]。由于层数深、参数多、结构复杂,深度学习模型具有很强的学习能力,因此常用于大量样本数据的训练,挖掘其中隐藏的函数关系和物理规律。在强对流天气方面,有学者提出基于深度学习的强对流临近预报方法[18-19],但基于深度学习的飑线等强对流天气的自动识别算法目前在国内报道较少。
卷积神经网络可以提取图片数据特征,在图像处理特别是目标分类方面效果显著,已被广泛应用于计算机视觉、自然语言处理等领域[20]。雷达回波图中目标的自动识别可以看作是一种图像分类问题,因此本文提出采用卷积神经网络来识别雷达回波中的飑线,以河南省郑州和驻马店雷达为试验对象,挑选飑线数据建立样本集用于模型的训练、验证和测试。针对样本分类的不平衡问题,提出并测试了不同改进方案对识别效果的效果。
1 数 据
本文使用的雷达基数据来自河南省气象台。雷达数据来自河南省郑州和驻马店SA波段雷达,雷达探测半径为460 km,径向分辨率为1 km,2008—2020年雷达共探测到22次飑线过程(表1)(表中时刻均为世界时,下同)。

表1 飑线过程发生时间Table 1 Occurrence time of squall line processes
卷积神经网络的输入是图像,而雷达基数据以二进制文件的形式储存,因此需要对雷达基数据进行预处理。首先提取各仰角层的基本反射率因子计算得到组合反射率因子,然后采用双线性插值[21]算法将极坐标系下的组合反射率因子插值到笛卡尔坐标,为了便于模型的训练需适当降低分辨率,最终得到时间分辨率为6 min、空间范围为920×920 km、格点分辨率为2.5 km、大小为360×360的雷达反射率因子矩阵。
为了建立用于卷积神经网络的训练、检验和测试的数据集,需对样本中的雷达回波进行分类和标识:首先挑选发生飑线过程的22 d雷达体扫数据,共7188个,然后根据雷达基数据中的基本反射率因子矩阵画出雷达回波图,并人工将其分为飑线回波和非飑线回波两类。基于雷达数据进行飑线判别的依据见表2。参考这些依据,本文将满足以下条件的雷达回波图判别为飑线回波:雷达反射率因子大于40 dBZ且连续长度超过100 km,长宽比超过5:1的回波带。最终判别飑线回波2067个,非飑线回波5121个。选取由这22 d的飑线个例构成模型所需的数据集,随机挑选2008年5月9日—2018年6月13日18次飑线过程雷达回波数据的四分之三作为训练集,用于模型的训练和调参,剩余四分之一作为验证集,用于优化模型时评估训练效果,从而改进模型结构,优化模型参数。2018年6月13日—2020年6月24日4次飑线过程的雷达回波单独构成测试集,不参与模型训练,以客观验证模型的时间泛化能力,数据集详细信息见表3。

表2 飑线判别依据Table 2 Criteria of squall line discrimination

表3 数据集信息Table 3 Information of datasets
2 飑线识别算法
2.1 卷积神经网络
雷达识别飑线本质是一个图像分类问题,雷达回波相当于一个二维图像,图像颜色对应回波强度,飑线回波具有弓形、线状和强反射率因子等显著特征,通过提取这些图像特征并与历史样本对比从而识别出飑线。如何有效提取图像特征并在所提取特征和样本类别间建立函数关系,可采用卷积神经网络解决该问题。
卷积神经网络模型包括输入层、卷积层、池化层、全连接层和输出层。模型输入为原始图像或经过预处理的图像。卷积层、池化层和全连接层属于隐含层。卷积层由一组卷积核组成,卷积核相当于可以自动学习的滤波器,通过滑动窗口对输入的图像进行卷积运算后输出特征图,不同卷积核的组合能提取图像的多个特征,在误差反向传播中卷积核能够根据误差不断修改自身的权值,使分类结果更加贴近目标。池化层又被称为降采样层,输入的特征图按一定规则划分为若干矩形区域,取每个区域的最大值或平均值输出,这样能够减少网络的计算量和参数数量,降低过拟合的影响,同时尽可能地保留图像特征,在卷积网络的设计中通常会将池化层穿插在卷积层之间[26]。全连接层类似于传统的BP神经网络,层与层之间所有的神经元相连接。图像在经过多层卷积、池化后得到的高层特征输入全连接层进行映射后连接到输出层,最终得到输入图像的类别所属概率向量。
2.2 建立飑线识别模型
本文采用深度学习框架PyTorch构建卷积神经网络。PyTorch是一个基于Python的科学计算包,提供各类封装好的函数和模块。用户可以自由灵活地设计网络结构和损失函数,将输入数据导入后网络便可自动进行前向传播和误差反向传播的计算,完成网络训练。
视觉几何组(visual geometry group,VGG)网络由Simonyan等[27]提出,结构非常简洁,但耗费计算资源较多。相较于其他卷积神经网络,VGG采用多个3×3的卷积核代替较大的卷积核(11×11,7×7,5×5),这样做的主要原因是在保证具有相同感知野的条件下,多个小卷积核堆积相当于增加了非线性层数,加深网络深度保证学习更复杂的模式。由于VGG在图像分类和目标检测任务中表现良好,本文参考VGG设计网络。整个网络包含1个输入层、8个卷积层、5个池化层、5个全连接层和1个输出层。所有卷积层使用的卷积核均为3×3,步长为1,为了使卷积后的特征图大小不变,边缘使用相同像素进行填充。前2层池化层窗为2×2,步长为2,后3层池化层窗口为3×3,步长为3,方式为最大池化。每个卷积层和全连接层后面使用ReLU作为激活函数。训练过程的参数设置:学习率0.001,优化算法为自适应矩估计[28],迭代训练100次,损失函数为交叉熵函数。
网络输入的图像为360×360分辨率的雷达反射率因子矩阵,经过8次卷积和5次池化得到5×5大小、256个通道的特征图,拉伸为长度为6400的一维向量,经过4个全连接层后映射为长度为2的一维向量,分别表示输入的雷达反射率因子矩阵属于飑线回波和非飑线回波的概率,选取概率最大值作为分类结果。
3 飑线识别试验
3.1 识别效果评价方法
模型输出雷达回波图像属于飑线类别和非飑线类别的概率,取概率最大值作为对应的分类结果,即0/1分类,这将飑线识别问题转化为一个二分类问题。本文在此基础上采用临界成功指数(CSI)、公平风险评分(ETS)、命中率(POD)、误判率(FAR)定量评价模型的识别效果[29]。CSI和ETS代表了模型对飑线样本和非飑线样本的综合识别能力,POD表示模型对飑线样本的识别率,FAR表示模型对非飑线样本的误识别率。
需要注意的是,上述评分标准原本用于评估短时临近预报效果,而非识别效果,不过在评估预报效果前也需要设定阈值将雷达回波转化为0/1分类结果,两者相似,同时对于飑线的识别效果目前缺少一个广泛使用的评价标准,故在此引入。
3.2 模型优化试验
使用验证集对卷积神经网络的学习效果进行检验,识别结果是CSI为0.59,ETS为0.47,POD为0.77,FAR为0.27(表4原方案),总体看模型能够较好地分辨飑线和非飑线样本。经过多次试验,发现非飑线样本的识别准确率高于飑线样本,这说明网络对非飑线样本的识别能力优于飑线样本,本研究认为原因有两个:①样本比例不平衡,在训练样本集中飑线样本与非飑线样本的数量比例约为2:5,这会导致模型更关注多数类(非飑线),从而使少数类(飑线)样本的分类性能下降,即总是将样本放到样本量较多的分类中;②相对于传统的图像分类任务,本文使用的雷达回波图像分辨率更高,使模型需要更多的层数降采样,常见的VGG网络一般为16层,而本文设计的网络为20层,其结构更深,过强的学习能力造成过拟合现象。针对以上两种原因,本文分别提出不同的改进方案。

表4 改进方案识别结果Table 4 Identification result of different schemes
对于样本组成比例不平衡解决思路[30]如下:①过采样:通过增加分类中少数类样本的数量实现样本均衡;②欠采样:通过减少分类中多数类样本的数量来实现样本均衡;③给分类中不同样本数量的类别赋予不同的权重,一般小样本量类别权重高,大样本量类别权重低。本文分别采用过采样和降采样的思路,通过增加或减少训练集中的样本数量建立新的训练集。表5给出新旧训练集的对比,过采样重复增加1倍的飑线样本,使飑线样本与非飑线样本的数量比例由2:5上升至4:5;降采样则随机减少1000个非飑线样本,使两者的数量比例由2:5上升至2:3。该操作仅针对训练集,验证集和测试集中两者的比例未改变。对于卷积神经网络中的过拟合问题,当前主要通过增加网络的稀疏性以及随机性,改善网络的泛化性能[31]解决,如作用于全连接层的随机丢失[32],通过在训练过程中随机地忽略一定比例的节点响应,增加网络的稀疏性;作用于卷积层的最大响应激活函数[33],将其他卷积层的连接全部断开,只保留上一层节点向下一层的激励最大值;作用于池化层的随机池化[34],依据概率分布进行随机的池化操作,给池化过程引入随机性。基于以上分析,本文尝试对网络结构进行优化:在全连接层中加入随机丢失,随机忽略50%的神经元节点,同时将全连接层的数量从5层减少为3层,降低网络的深度。

表5 训练集对比Table 5 Comparison of training sets
为了比较不同改进方案的效果,本文设计4组试验(表4):①使用过采样后的训练集进行训练,②使用降采样后的训练集进行训练,③使用结构优化后的网络进行训练,④同时使用降采样的训练集和结构优化后网络进行训练。由表4可以看到,与未进行改进的结果相比,过采样方案的CSI上升至0.65,ETS上升至0.52,POD上升至0.80,FAR下降至0.26;降采样方案的CSI上升至0.74,ETS上升至0.63,POD上升至0.93,FAR下降至0.23。说明过采样和降采样可缓解样本比例不平衡问题,过采样方案的提升幅度比降采样小,这可能是因为简单地重复采样无法有效增加样本信息,依然会导致过拟合。网络结构优化方案的CSI上升至0.87,ETS上升至0.82,POD上升至0.96,FAR下降至0.10,识别效果显著提升。其中ETS提升明显是因为该指标更看重对飑线样本的识别效果,原方案对飑线样本的识别能力较弱故评分低,而经过网络结构优化的方案对飑线样本的识别能力大幅提升。同时使用降采样训练集和网络结构优化方案的CSI为0.88,ETS为0.83,POD为0.97,FAR为0.10,与仅使用网络结构优化方案的结果相比无明显提升。
分析上述试验可知,改变样本组成比例和网络结构优化的方案均能够明显提升飑线样本的识别效果,但前者提升的幅度低于后者。在使用网络结构优化方案的基础上,再使用降采样训练集未能带来效果的明显提升,说明对于本文使用的数据集优化网络结构已足够改善样本比例不平衡的问题,不需要刻意减少非飑线样本量,因为非飑线样本中包含多种其他天气条件下的雷达回波,过多删除可能导致卷积神经网络丢失关于其他天气样本的重要信息。
3.3 识别模型效果评估
在网络结构优化的基础上,使用测试集对卷积神经网络模型的学习效果进行测试。图1~图3给出3次飑线过程回波随时间的变化和识别结果。
2018年6月26日郑州雷达探测到的飑线过程(图1)。05:12对流初生,位于西南方向,算法识别结果为非飑线。06:48对流发展为多个单体排列成线状,雷达回波最大值达到50 dBZ,自西北向东南移动,算法将其识别为飑线。07:48系统逐渐减弱,正南方向开始生成新的对流单体,识别结果变为非飑线。08:30正南方向的多个对流单体继续发展排列成线状,回波最大值达到60 dBZ,原西南方向飑线消亡后残留的对流单体向正南方向靠近,算法重新将其识别为飑线。10:00西南方向的对流已完全与正南方向的新飑线系统合并,系统缓慢向东北方向移动。11:30正南方向的飑线系统开始减弱,但在东南方向有多个新的对流单体生成。12:36正南方向的飑线系统完全消亡,只留下一片弱回波区,东南方向对流单体继续发展排列成线状,回波最大值达到55 dBZ,系统向东移动。13:24系统减弱,不再呈线状,后部生成一个面积较大的对流单体。
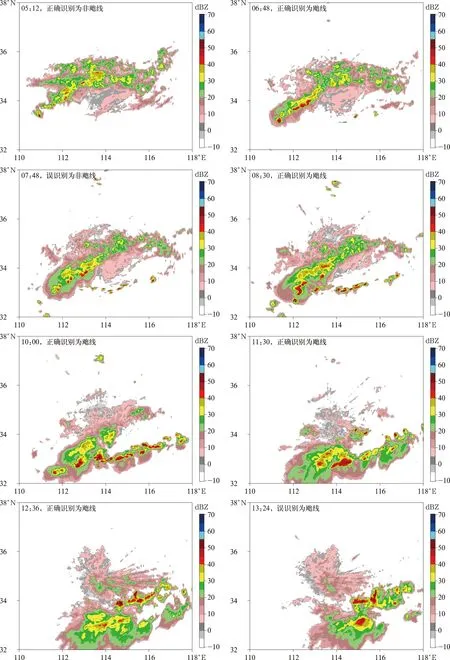
图1 2018年6月26日郑州雷达探测飑线过程的识别结果Fig.1 Identification results of squall line detected by Zhengzhou radar on 26 Jun 2018
2019年6月3日驻马店雷达探测到飑线过程(图2)。11:00对流初生,西北方向有多个对流单体,算法识别结果为非飑线。12:00对流单体发展,排列成线状并向南移动,算法识别为飑线。12:36系统分裂成两个较短的回波带,识别结果为非飑线。13:12两个回波带合并,系统发展旺盛,回波最大值达到65 dBZ,西面生成一个小的对流单体与系统一起移动,算法重新将其识别为飑线。13:48系统逐渐减弱并向东南方向移动,未识别为飑线,可能是因为系统长宽比较低。14:12后系统进入消亡期,排列不再呈线状,西面的对流单体消散。16:00系统消亡,识别结果为非飑线。

图2 2019年6月3日驻马店雷达探测飑线过程的识别结果Fig.2 Identification results of squall line detected by Zhumadian radar on 3 Jun 2019

续图2
2020年6月24日郑州雷达探测到飑线过程(图3)。08:48对流初生,位于东北方向,算法识别结果为非飑线。09:48对流发展,回波最大值达到60 dBZ,自北向南移动,算法开始将其识别为飑线。11:00多个对流单体继续发展排列成线状,飑线系统形成,开始向东南方向移动。12:00系统发展,长度超过200 km,同时西南方向有新的对流单体生成。13:18系统发展到鼎盛,长度超过250 km,西南方向的对流单体与系统一起移动但未合并,系统与单体之间发展出一条短回波带。14:06系统在向东南方向移动时逐渐减弱,同时西南方向的对流单体和短回波带也减弱消散。16:00系统进入消亡期,回波强度进一步减弱,对流单体排列不再呈线状,识别结果为非飑线。16:42系统完全消亡。

图3 2020年6月24日郑州雷达探测飑线过程的识别结果Fig.3 Identification results of squall line detected by Zhengzhou radar on 24 Jun 2020

续图3
由图1~图3各时次的识别结果可以看到,在对流发展较弱阶段,模型能够正确识别为非飑线,在飑线发展强盛阶段,模型能够正确识别为飑线,说明经过训练的模型把握了飑线的强回波和线状特征,且能够与对流较弱的情况区分。在飑线消亡或新生阶段,回波强度减弱,形状不规则,此时模型识别能力下降,这是因为样本集建立在对飑线的主观判别、分类和标记上,对于某些飑线特征不明显,特别是飑线消亡或新生阶段的样本,判别依据难以把握。
表6是验证集和测试集识别结果的对比,可以看到,测试集的CSI,ETS和POD分别为0.66,0.58和0.86,FAR为0.24,这是因为深度学习模型的建立依赖大量历史数据作为学习样本,而飑线的历史个例不足,训练集的代表性有待提高。不同天气个例飑线区域的回波强度和空间分布形态差异很大,验证集中的样本和训练集来自相同的飑线过程,所以识别效果理想,而测试集中的样本来自其他未参与训练的飑线过程,具有训练集未曾包含的图像特征,所以识别效果降低。由于训练后的网络已经能够分辨飑线过程典型的强回波和线状特征,因此模型的识别能力下降不大,具有较好的外延性。

表6 验证集与测试集识别结果Table 6 Identification results of validation set and test set
4 结 论
本文提出基于卷积神经网络的飑线自动识别方法,使用2008—2020年河南省郑州和驻马店雷达的飑线数据作为样本训练、验证和测试模型的识别能力,并针对样本组成比例不平衡提出改进方案,并比较不同方案的识别效果,得到以下结论:
1)飑线在各类天气过程中占比小,建立样本集时存在样本组成比例不平衡的问题,这对飑线识别效果有一定影响。改变采样方式和优化网络结构均能够缓解样本不平衡,显著提升识别效果,但前者提升幅度低于后者,且两种方法的结合未带来识别效果的明显提升。
2)模型用于测试集的效果CSI为0.66,ETS为0.58,POD为0.86,FAR为0.24,表明卷积神经网络能够提取并学习飑线和非飑线回波的图像特征,对飑线有良好识别能力,具有较好的外延性。
深度学习为中尺度对流系统的自动识别提供新思路,但仍存在局限性。深度学习模型的建立依赖于大量历史数据作为学习样本,人工对样本进行分类的主观偏差、样本集代表性不足等会影响模型的识别效果,可以通过优化飑线判别依据、建立更加具有代表性的样本集等途径对模型进行优化。
需要指出的是,本文仅从雷达回波的角度进行分析,实际飑线的判别还需要结合其他天气条件。本文用于建模的样本来自河南省郑州和驻马店雷达数据,在其他地区的适用性有待研究。
致 谢:本文计算得到南京信息工程大学高性能计算中心的支持和帮助。
