基于抗几何变换的离散深度哈希算法
2021-09-03孙帮勇
刘 芳, 孙帮勇
(1.南京理工大学 计算机科学与工程学院, 江苏 南京 210014;2.西安理工大学 印刷包装与数字媒体学院, 陕西 西安 710048)
近似最近邻搜索方法在大规模视觉搜索中得到了广泛的应用[1]。哈希技术由于其低存储量和快速检索速度而成为近似最近邻搜索方法中最重要的技术之一。哈希方法的目标是找到一个映射函数可以将每个样本编码成哈希码,同时保持原始样本的相似性[2]。
现有的哈希方法主要分为两类:数据独立的哈希方法和数据依赖的哈希方法。数据独立的哈希方法是在不使用训练数据的情况下,利用随机投影实现有效哈希函数学习,其典型代表是位置敏感哈希(LSH)[1],此类方法在针对较长哈希码时效果良好,但需要大量存储[3]。鉴于此问题,学者们又开发了数据依赖的哈希方法[3,4],通过训练数据来学习哈希函数。然而,这些方法都是利用手工特征进行哈希码函数学习,无法捕获原始数据的复杂语义结构[5]。
针对此类问题,有学者引入了深度哈希概念,即利用深度神经网络捕获原始数据的复杂语义结构[6]。然而,这些方法在实际应用中存在两个挑战。第一,一些哈希方法[5,6]不能充分考虑图像的几何变换,这会导致哈希码的几何不变性减小,最终影响图像检索的性能。第二,对于现有的哈希方法[7,8],首先利用连续松弛策略学习连续近似哈希码,然后通过量化操作将其转换为离散哈希码。因此,这些方法不能在优化过程中直接学习离散哈希码,这会影响生成的次优哈希码。
本文提出了一种基于抗几何变换的离散深度哈希算法,即几何变换离散哈希(TIDH),利用抗几何变换和语义监督信息直接生成离散哈希码。TIDH的概述如图1所示。为了学习几何不变性,提出了抗几何变换模块,以实现几何不变描述特征学习。为了学习离散哈希码,将离散哈希码学习和特征学习设计在统一的框架中,以便利用语义监督在优化过程中直接学习离散哈希码。两个公共检索数据集CIFAR-10和NUS-WIDE上的实验结果表明,TIDH可以取得比其他先进哈希方法更好的性能。
1 相关工作
根据标签信息的利用程度,哈希算法可以分为三类:无监督哈希算法、半监督哈希算法和监督哈希算法,本文回顾了三个相关领域的文献。
1.1 无监督哈希算法
无监督哈希方法通过未标记的训练样本将样本投射到哈希码中以学习哈希函数[9-11]。例如,苏毅娟等[2]结合PCA与流形学习,将原始高维数据降维,然后通过最小方差旋转得到哈希函数和二值化阈值,进而将原始数据矩阵转换为哈希编码矩阵,最后通过计算样本间汉明距离得到样本相似性。近年来,无监督深度哈希方法[12-14]利用深度神经网络捕获复杂语义结构的优越性能,极大地改善了此前的无监督哈希方法[12-14]。例如,Xia等[13]在不使用标签信息的情况下,利用自编码器和受限玻尔兹曼机去实现层次哈希函数学习。Do等[12]开发了一种使用深度神经网络的无监督离散哈希方法,该方法利用补充变量来解决二进制约束问题。Wu等[14]使用自学的方式进行有效的哈希函数学习。
1.2 半监督哈希算法
半监督哈希方法通过标记的训练样本和未标记的训练样本将样本投影到哈希码中[15-17]。半监督哈希是一种很有代表性的哈希编码方法,它通过最小化有标签训练样本上的经验误差,最大化有标签训练样本和无标签训练样本上的误差来生成紧凑的哈希编码。随着深度神经网络的发展,出现了大量的半监督深度哈希方法。其中一个典型方法是半监督深度哈希(SSDH),它通过最小化有标签训练样本和无标签训练样本上的误差来学习有效哈希码。
1.3 监督哈希算法
监督哈希方法利用带标记的训练样本在保留语义相似性的情况下,进行有效的哈希函数学习[18-21]。例如,刘治等[4]通过设计优化问题的求解方法,改善了哈希算法的效果。唐珂等[3]通过二进制重构嵌入和带核的监督哈希来进行非线性哈希函数学习。然而,这些方法都是利用手工描述特征来生成哈希码,无法捕获原始数据的复杂语义结构。近来,鉴于深度神经网络强大的特征学习特性,许多深度监督哈希方法已经被开发出来,以保持相似哈希函数学习。例如,Lin等[18]利用深度神经网络同步进行哈希码学习和深度特征学习。Yang等[19]开发了一种新的跨批处理引用方法来生成紧凑的哈希码。Li等[20]提出了一种新的深度联合语义嵌入哈希方法,可以捕获样本之间丰富的语义相关性。Deng等[21]提出了一种新的基于三联体的深度哈希方法,该方法可以利用三联体训练样本学习哈希码的相关性。本文是利用抗几何变换和语义监督信息直接指导离散哈希码的学习。
2 基于抗几何变换的离散深度哈希算法
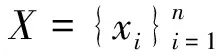
2.1 离散哈希码学习
TIDH方法将几何不变性构建模块、深度特征学习模块和离散哈希码学习模块集成到一个统一的框架中,其总体框架如图1所示。该方法的体系结构由两个子网组成,每个子网包含4个具有批处理标准化(BN)的卷积层、4个最大池化层和2个完全连接层。4个卷积层分别采用128个、128个、256个、256个3×3窗口的滤波器,这些卷积层的激活函数均采用整流线性单元(ReLU)。最大池化层使用2×2个窗口。两个子网络的卷积层共享相同的权值参数。第一个全连接层的神经元的数量为1 024,激活函数是tanh函数。第二个全连接层是哈希层,它包含K个单位,可以直接生成离散哈希码。哈希函数可以定义为:
bi=HI(xi)=2×round(ψ(wbThi+vb))-1
(1)
其中,
(2)
式中:bi代表图像xi的离散哈希码;hi为图像xi的深度特征,是图像xi经过卷积神经网络学习的全连接层的特征;wb代表哈希层的权重参数;vb代表哈希层的偏置;ψ代表Hard-Sigmoid函数,ψ(x)=max(0,min(1,c+1)/2),c代表实数;HI代表哈希函数。
式(1)中哈希函数难以求导,不适合在网络训练过程中传播梯度。本文受文献[22]的启发,利用直通式估计器执行反向传播,即利用Hard-Tanh函数传播梯度,Hard-Tanh函数定义为:
Htan(x)=max(-1,min(1,c))
(3)
式中:Htan(·)代表Hard-Tanh函数;max(·)代表最大函数;min(·)代表最小函数。
2.2 几何不变特征学习
现有研究表明,有效的局部特征不仅存在性质的区别而且可以保持几何变换不变性[23,24]。因此,所提取的特征需保持三个重要的几何变换不变性,即旋转不变性、平移不变性和缩放不变性。为了学习几何变换不变性的哈希码,多通过最小化参考图像和转换图像之间的二元特征差异来解决这个问题,一般采用一组旋转、平移和缩放函数来计算变换后的图像。为了使二值特征更具特色,本文通过增加任意图像特征之间的距离来进一步增强二值特征,现将优化问题表述为几何保持损失函数:
(4)
式中:d=‖bi-bi,g‖;bi代表图像xi的离散哈希码;bi,g代表转换图像xi,g的离散哈希码。如果图像xi与其转换图像xi,g相似,则si,g=1;如果图像xi与其转换图像xi,g不相似,则si,g=0。转换图像包含旋转、平移和缩放三种转换的所有图像。 在学习过程中,本文通过几何保持函数将有效的局部特征编码到深度神经网络的顶层,然后通过反向传播优化网络参数,学习离散哈希码。
2.3 目标函数
本文的目标是找到合适的映射函数HI,并保持汉明空间中相似样本的相似性。基于此目的,提出了相似损失函数,以使相似哈希码尽可能接近,不相似哈希码尽可能远离[25]。为保持哈希码的相似性,可将相似学习损失函数Lp定义为:
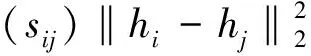
(5)
式中:‖·‖2代表L2的范数;m为常数。
在进行离散哈希码学习时,上述损失函数的标签信息并没有被充分利用[26]。标签信息可提供有用的监督信息用于增强离散哈希码的语义信息。本文将通过学习更多的潜在语义信息来提高哈希码的有效性。其语义监督损失函数为:
(6)
式中:Ll为语义监督损失函数,可保证离散哈希码具有语义属性;δ(·)为softmax函数;yi为图像xi的标签信息;wl为权重参数。
综合考虑上述等式,TIDH的最终目标函数L为:
(7)
式中:α和β表示控制参数。
最终目标函数式(7)是凸函数,可通过深度学习库TensorFlow中的Adam优化器进行优化。该算法可利用语义监督来指导离散哈希码学习,使生成的哈希码包含更多语义信息和抗几何变换性质。
3 实验及结果分析
3.1 实验数据及环境
本文实验环境为:GeForce GTX Titan X GPU、中央处理器为 Intel(R) Core i7-5930K 3.50 GHz、内存为64 G、操作系统为Ubuntu 14.04。根据本文提出的方法对两个基准数据集CIFAR-10和NUS-WIDE进行评估。
1) CIFAR-10图像数据库:该数据集是检索时使用最广泛的数据集之一。包含10个对象类别,每个类包含6 000张图片,总计60 000张图片。这些类包含飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车等内容。数据集被分成训练集和测试集,分别有50 000和10 000张图像。本文将使用训练集进行网络训练,使用测试集作为检索评估的查询。
2) NUS-WIDE图像数据库:NUS-WIDE数据集是从Flickr网站收集的大规模多标签数据集,它包含了与81个概念相关的269 648个样本,每个概念至少包含5 000个样本。本文从21个最常见的概念中选取了195 969个样本。如果两个样本共享至少有一个概念,则它们被认为是相似的,否则,它们被认为是不同的。本文将从21个最常见的概念中随机抽取100个样本作为查询,剩下的样本作为训练集和图库集。
将提出的TIDH方法与9种最新的哈希方法进行比较,包括BRE[27]、MLH[28]、KSH[29]、DSRH[30]、DSCH[31]、DRSCH[31]、DHN[6]、DPSH[20]和DDSH[32]。在这些方法中,BRE、MLH和KSH是非深度方法,它们利用512维的GIST描述符作为CIFAR-10和NUS-WIDE数据集的输入。对于利用深度特性的非深度方法(例如BRE-CNN、 MLH-CNN和KSH-CNN),本文利用CNN的4 096维特征来表示CIFAR-10和NUS-WIDE数据集的每一幅图像。对于深度学习方法(例如DSRH、DSCH、DRSCH、DHN、DPSH和DDSH),本文使用128×128的图像作为三个数据集的输入。采用三个汉明排名指标来评价TIDH和其他方法。这些指标分别为平均精度(MAP)、前500幅检索图像的精度(precision@500)和前k幅检索图像的精度(precision@k)。这三个指标可以反映检索性能[27],其指标值越大,表示检索性能越好。
3.2 实验结果分析
表1显示了CIFAR-10数据集上不同位数图像的检索结果。图2(a)显示了CIFAR-10数据集上不同哈希位返回的前500幅图像的精度曲线;图2(b)显示了CIFAR-10数据集上64位哈希位不同返回图像的精度曲线。
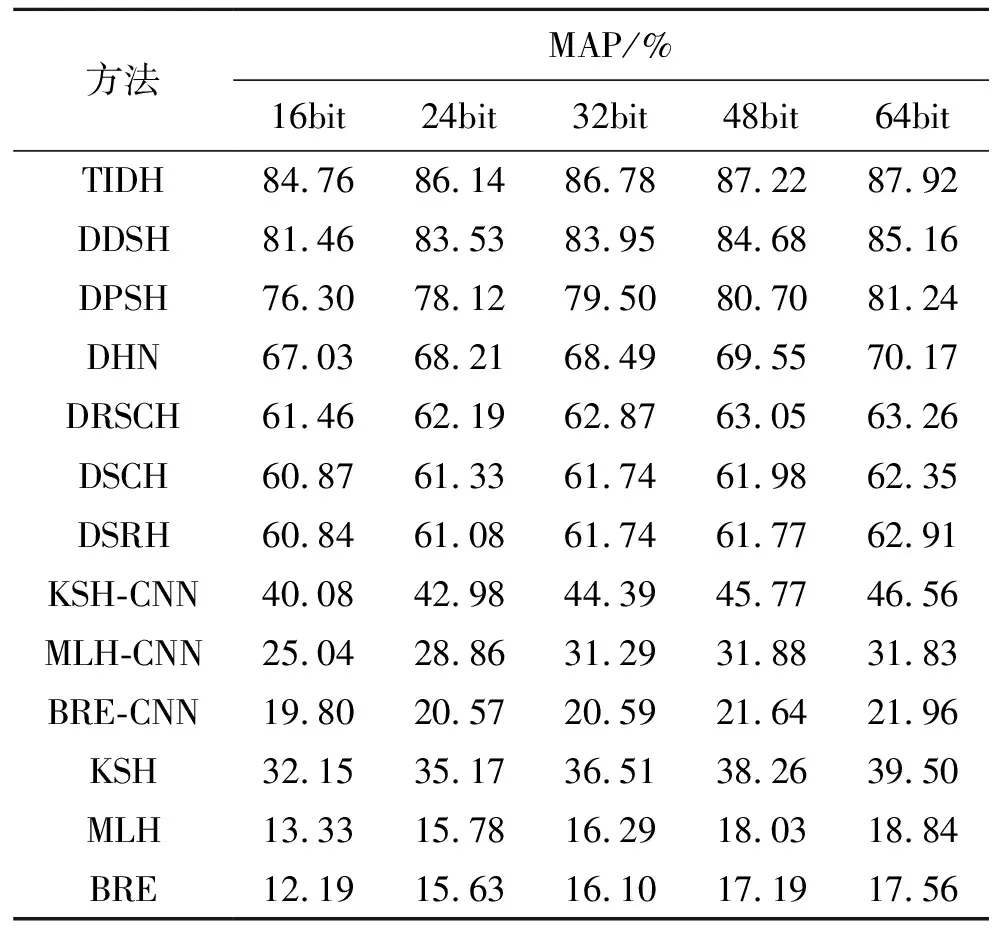
表1 CIFAR-10数据库上不同监督哈希算法的性能对比Tab.1 Performance comparison of different supervisedHashing algorithms on the CIFAR-10 dataset
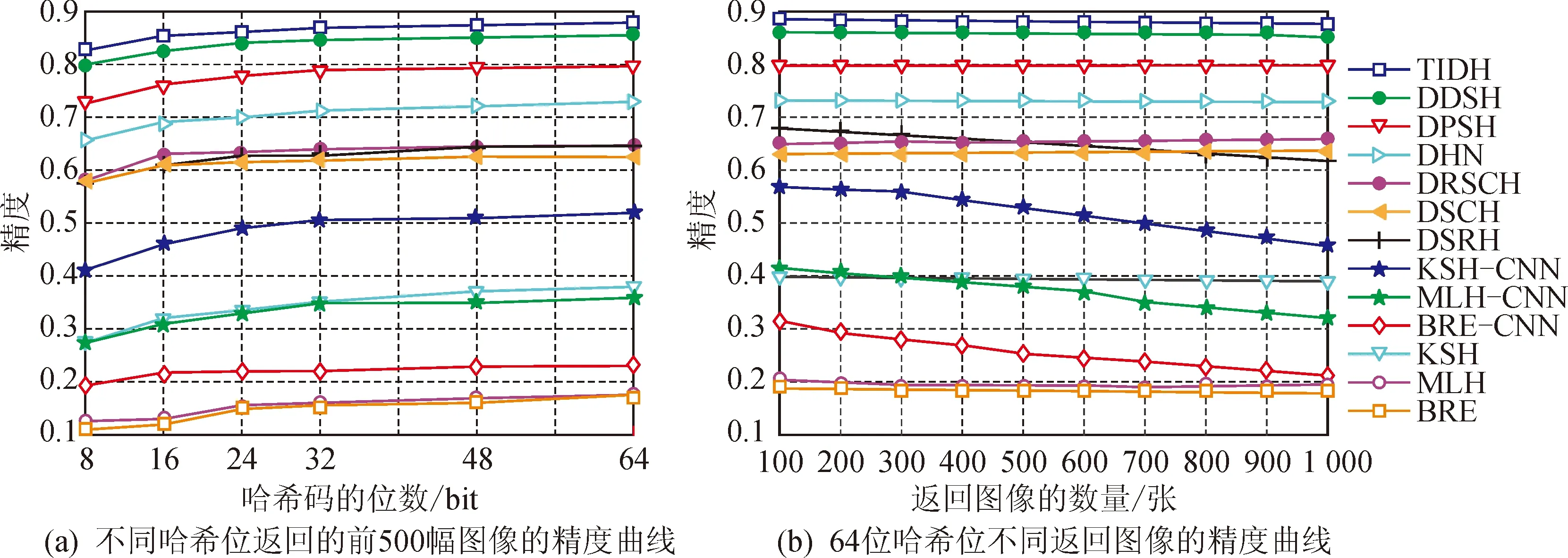
图2 CIFAR-10数据集上的实验结果Fig.2 Experimental results on CIFAR-10 dataset
由此可见:①使用4 096维CNN特征的非深度检索方法较使用512维GIST特征的检索方法获得的检索性能更佳,例如,BRE-CNN可将32位的检索映射结果从BRE的16.10%提高到20.59%,验证了深层特征可提高非深层方法的性能;②在CIFAR-10数据集上,对于不同的哈希位,TIDH方法比9种现有哈希方法获得的映射结果更好;对于CIFAR-10数据集,TIDH方法的检索效果最佳,此外,相较于以前最佳方法DDSH的85.16%,TIDH方法的检索准确率提高到87.92%,验证了TIDH方法对三个模块更加有效;③虽然其他两个指标比较显示,9种现有哈希方法在两个指标上都取得了良好的性能,但在不同bit的前500幅返回图像的检索结果上,TIDH方法的表现仍然相对更好,特别是在64bit的不同返回图像的检索结果上,TIDH方法更为优越,也取得了更好的检索结果;④TIDH方法检索结果显示:本文采取的利用抗几何变换和语义监督信息直接生成离散哈希码的策略,使得深度哈希方法在图像检索方面具有有效性。
与CIFAR-10数据集相比,NUS-WIDE是一个更加复杂的多标签数据集。为了进一步评价所提TIDH方法的有效性,将其与其他几种哈希方法进行比较,包括BRE、MLH、KSH、DSRH、DSCH、DRSCH、DHN、DPSH和DDSH。表2显示了NUS-WIDE数据集上不同bit的图像检索结果。图3(a)显示了NUS-WIDE数据集上不同哈希位返回的前500幅图像的精度曲线;图3(b)显示了NUS-WIDE数据集上64位哈希位不同返回图像的精度曲线。由此可以看出,在精度曲线上,所提出的TIDH方法已经超过6种深度哈希方法(即DSRH、DSCH、DRSCH、DHN、DPSH和DDSH),而且该法还将48位检索映射结果从61.98% (DSCH)、61.77% (DSRH)、63.05% (DRSCH)、79.95%(DHN)、82.58% (DPSH)、82.74% (DDSH)提高到84.18%。此结果表明,TIDH方法不仅能利用抗几何变换模块来实现几何不变描述特征学习,而且还能利用监督信息来学习离散哈希码。
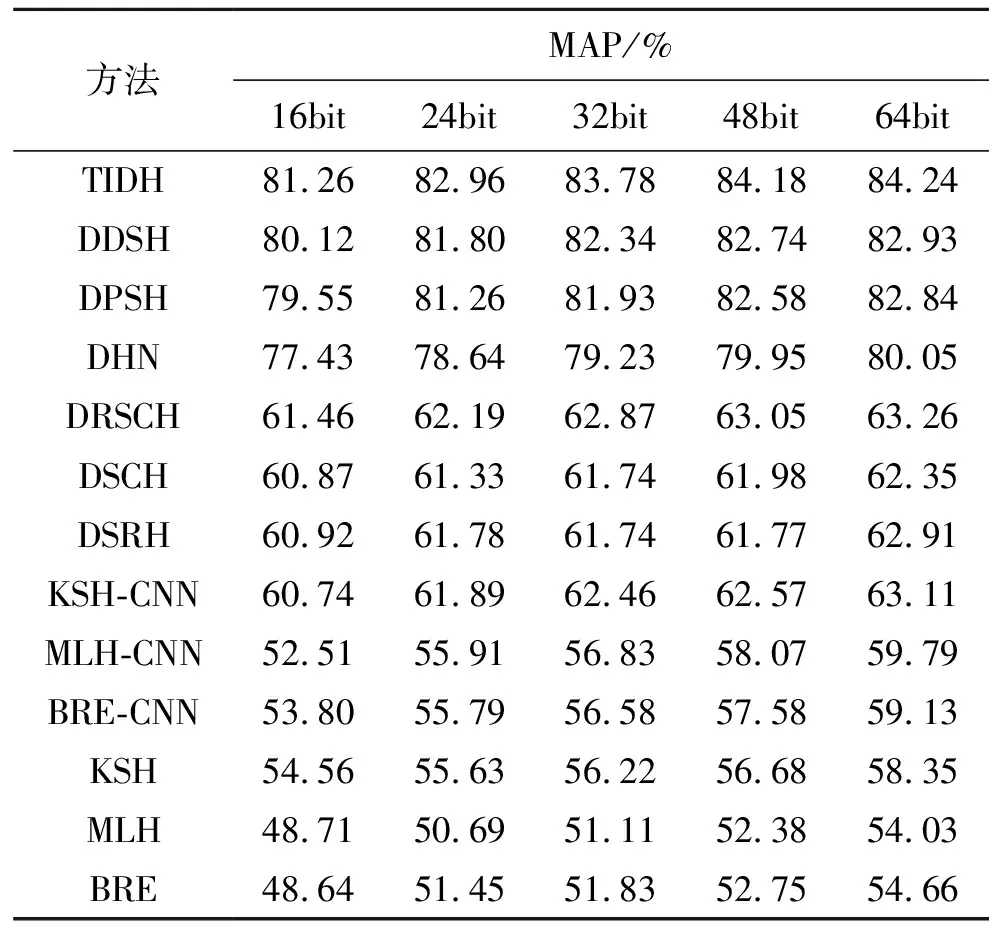
表2 NUS-WIDE数据库上不同监督哈希算法的性能对比Tab.2 Performance comparison of different supervisedHashing algorithms on the NUS-WIDE dataset

图3 NUS-WIDE数据集上的实验结果Fig.3 Experimental results on NUS-WIDE dataset
4 结 语
本文提出了一种基于抗几何变换的离散深度哈希算法,该算法利用抗几何变换和语义监督信息直接生成离散哈希码。为了学习几何不变性,提出了抗几何变换模块,以实现几何不变描述特征学习。为了学习离散哈希码,将离散哈希码学习和特征学习设计在统一的框架中,以便利用语义监督在优化过程中直接学习离散哈希码。在两个数据集CIFAR-10和NUS-WIDE上的大量实验结果表明,所提出的TIDH方法是有效的,其性能较其他最新、最先进的哈希方法更为优越。该方法可应用于行人再识别、跨模态学习等领域。
