基于变分模态分解和引力搜索算法的径流预测模型研究
2021-09-03李晓春包苑村罗军刚左岗岗
李晓春, 包苑村, 罗军刚, 左岗岗
(1.陕西省江河水库工作中心, 陕西 西安 710018;2.西安理工大学 西北旱区生态水利国家重点实验室,陕西 西安 710048)
月径流时间序列受到多种因素的影响和制约,当前流行的数据驱动模型能很好地捕捉径流时间序列的非线性关系,但由于月径流属于小样本,使得数据驱动模型容易陷入过拟合以及局部最小值等情形[1]。支持向量回归机(SVR)采用结构风险最小化准则设计学习机器,折衷考虑经验风险和置信范围,在小样本的情况下具有更好的泛化能力[2]。与此同时,径流时间序列的高度非线性和不稳定性,决定了需要将SVR与其它模型方法相结合,才能更好地提升预测精度。黄巧玲等[3]将耦合离散小波变换(DWT)与支持向量回归机(SVR)结合,建立了月径流预测的小波支持向量机耦合模型(WSVR),并应用于泾河张家山站的月径流预测中。结果表明,WSVR模型可以有效提高单一支持向量机模型的预测精度。周有荣等[4]利用同热传递搜索(SHTS)算法,对混合核支持向量机(SVM)关键参数和混合权重系数进行优化,结果表明,SHTS算法寻优精度高于TLBO、GWO优化算法。李祥蓉[5]利用静电放电算法(ESDA)优化混合核SVM关键参数和混合权重系数,研究结果表明,混合核ESDA-SVM模型在预测精度、泛化能力等方面均优于对比模型,具有较好的实际应用价值。王迁等[6]将粒子群优化算法(PSO)引入到SVR模型中,建立了PSO-SVR模型,实现了对SVR的RBF核函数的三个参数的自动优选。实验表明,PSO-SVR模型较ANN模型稳定性更强、可信度更高,且具有更好的应用价值。梁浩等[7]在优选多元线性回归(MLR)、人工神经网络(ANN)和支持向量机(SVM)单一预报模型的基础上,分别基于经验模态分解(EMD)、集合经验模态分解(EEMD)和小波分解(WD)构建了多种混合模型。结果表明,混合预测模型的预测精度均高于单一模型。
上述研究成果成功将多种优化算法与模型组合,在实例应用中取得了不错的效果。但大多数研究方法在实验开始时就将整个径流时间序列分解,实际带入了径流时间序列的未来信息[8]。同时,许多优化算法易陷入局部最优[9]。因此,本文提出基于变分模态分解(VMD)、引力搜索(GSA)与支持向量回归机(SVR)的组合模型。VMD分别对训练集数据和测试集数据进行分解,GSA对SVR的参数进行全局寻优。将本模型应用于渭河流域临潼站与咸阳站的月径流预测中。实例研究表明,该模型在有效提高预测精度的同时,也更加符合实际预测过程。
1 研究方法
1.1 Mann-Kendall(M-K)检验
在月径流的预测中,通常训练集与测试集的比例为7∶3左右。由于月径流属于小样本,按比例分配后,测试集的数据量过少,缺乏实际研究意义,因此引入Mann-Kendall(M-K)检验。
M-K检验是一种检验水文时间序列的趋势以及突变点的非参数统计检验[10]。给定月径流时间序列变量x={x1,x2,…,xn},则统计量Sk为:
(1)
其中:

(2)
M-K检验假设x有独立的观测值,如果没有趋势存在,这些观测值分布相同。在此假设下,Sk的均值和方差分别为:
E(Sk)=0
(3)
(4)
x的检验统计量定义为:
(5)
在显著性水平1-α(Z1-α)下,通过比较UFn与标准正态变量来检测x的趋势,α(0<α<0.5)是M-K检验错误拒绝原假设H0的容忍概率。当|UFn|≥Z1-α时,拒绝H0;否则,接受H0。在拒绝H0的条件下,如果|UFn|大于(小于)零,x随时间呈单调增加(减少)的趋势。

1.2 变分模态分解(VMD)
鉴于月径流时间序列的高度不稳定性,引入电力系统的信号分解模式[11],将月径流序列分解为多个分量,以便模型更好地学习月径流的变化规律。
VMD是一种新的信号分解模式,对原始信号采用非递归和变分模式分解的方法[12],将输入信号分解成若干个子模式,即周期性的分量(IMF)和一个残差(R)。VMD可以手动设置分解的模态数K,对噪声具有较好的鲁棒性,能显著降低计算的复杂度。因此,VMD可以对训练集和测试集分别进行分解,以避免模型在训练过程中混入测试集的信息,同时也能保证训练集与测试集的特征维度一致。
VMD的核心是一个受限的变分问题,将非平稳信号f分解为K个有限带宽的模态分量,为了保证每个模态分量的估计带宽之和最小,须使所有模态之和与原始信号相等。Dragomiretskiy与Zosso在2014年提出了该受限变分问题[13]:
(6)
式中:uk是模态函数的集合;ωk是第k个模态的中心频率;K是模态数;δ(t)是狄拉克分布;⊗是卷积运算;uk(t)是各子序列的模态函数; e-jωkt是复平面上模态函数中心频率的向量描述。
1.3支持向量回归机(SVR)原理及其参数
支持向量回归机(SVR)首先通过核函数[14]将低维的非线性回归问题映射至高维的空间,在高维的空间计算回归函数,基于结构风险最小化原则[15],有效避免因数据量不足而引起的预测精度过低、泛化能力差等问题。具体的计算过程为:
给定训练样本数据S={(xi,yi)|xi∈R,yi∈R,i=1,2,…,m},其中xi为模型输入,yi为模型输出,m为样本数量。则SVR的回归函数为:
y=wT·φ(x)+b
(7)
式中:wT为权重向量;b为偏置向量;φ(x)用于将输入向量映射至高维空间。
假设我们能容忍f(x)与yi之间最多有ε的偏差,即仅当f(x)与yi之间差值的绝对值大于ε时才计算损失,于是SVR问题可以转化为:
(8)
其中:
f(x)-yi≤ε+ξi

运用拉格朗日乘子求解式(8)得:
(9)

由Karush-Kuhn-Tucker[16]条件解得的SVR模型可以表示为:
(10)
式中:K(xi,x)=φ(xi)Tφ(xj)为核函数。
支持向量回归机中常用的核函数包括线性核函数、多项式核函数和高斯径向基核函数[17](RBF)。针对径流预测问题,RBF核函数具有超参数少、映射维度高与决策边界多样的优点,可以更好地适应非线性的径流预测问题。
RBF核函数的主要超参数有惩罚系数C、不敏感损失函数ε。除此之外,RBF核函数还有一个独有参数gamma,隐含地决定了数据映射到新的特征空间后的分布,gamma值越大,支持向量越少,gamma值越小,支持向量越多,支持向量的个数会影响训练与预测的速度。
1.4 引力搜索算法(GSA)
引力搜索算法(GSA)是一种新的启发式搜索算法[18],它受万有引力定律的启发,适用于模型的参数寻优,具有较好的全局搜索能力。GSA可以描述为一个n维的空间中有s个粒子,则第i个粒子的位置定义为:
Xi=(xi1,…,xid,…,xin)
(11)
式中:xid表示第i个粒子在第d维的位置;n为搜索空间的维度。
在开始搜索前,所有粒子的位置都是随机的。在某一时刻t,粒子i与j之间的引力为:

(12)
式中:Mpi(t)为施力物体j的惯性质量;Mai(t)为受力物体i的惯性质量;G(t)为引力常数,其值随时间的变化而变化,如式(13)所示(通常设置G0为100,α为10);Rij(t)为i与j之间的欧式距离,如式(14)所示;ε为一个小的常数,用来防止i与j之间的欧式距离为0。
(13)
(14)
粒子i在t时刻受到的其它粒子的引力为:
(15)
式中:randj为[0,1]范围内的随机数。
在第d维,粒子i的加速度为:
(16)
式中:Mii(t)为粒子i的惯性质量。
假设重力质量和惯性质量相等,则重力质量和惯性质量可更新为:
Mai=Mpi=Mii=Mi,i=1,2,…,n
(17)
(18)
(19)
式中:fiti(t)为粒子i在t时刻的适应度值。worst(t)与best(t)在求解最小值问题时定义为:
(20)
(21)
在求解最大值问题时,则定义为:
(22)
(23)
将粒子i的加速度加到当前的速度上,就可以得到现在的粒子速度和位置:
(24)
(25)
每次迭代后,同步更新粒子的位置和速度,直至达到最大迭代次数或达到要求的精度。
1.5 评价指标
为了更好地反映模型的预测效果。本实验选取均方误差(MSE)和纳什系数(NSE)对测试集的预测结果进行评价。
(26)
(27)
式中:yi为i时刻的预测值;y0为i时刻的实测值;y为实测值的均值;n为测试集样本数量。
1.6 VMD-GSA-SVR预测模型
VMD-GSA-SVR预测模型是一种新型的集成预测模型,其具体的预测流程如图1所示。

图1 VMD-GSA-SVR模型预测流程图Fig.1 VMD-GSA-SVR model prediction flow char
1) 对实测月径流数据进行M-K突变点检测,突变点前的数据作为训练集,突变点后的数据作为测试集。
2) 对训练集数据进行VMD分解,确定模态数K,再将测试集数据分解成同样的K个模态分量。
3) 将训练集输入SVR模型中,运用GSA对SVR的三个参数C、gamma、ε进行全局寻优,用MSE作为GSA的适应度值公式。
4) 将测试集代入经过参数优化的GSA-SVR模型进行预测,并用评价指标进行评价。
2 实例分析
2.1 资料来源与实验环境搭建
咸阳水文站位于陕西省咸阳市东关,始建于1931年6月10日。1957年6月20日,其基本水尺断面迁至秦皇路咸阳桥上游一侧(上游2.6 km处),更名为咸阳(二)站。该站东经108°42′,北纬34°19′,控制流域面积46 827 km2,距河源606.9 km,距河口211.1 km。临潼水文站距咸阳站下游53.7 km,位于临潼区行者乡,东经109°12′,北纬34°26′,集水面积97 299 km2。本文选取咸阳站1956—2010年660个月的实测月径流数据,选取临潼站1960—2006年564个月的实测月径流数据,如图2和图3所示。
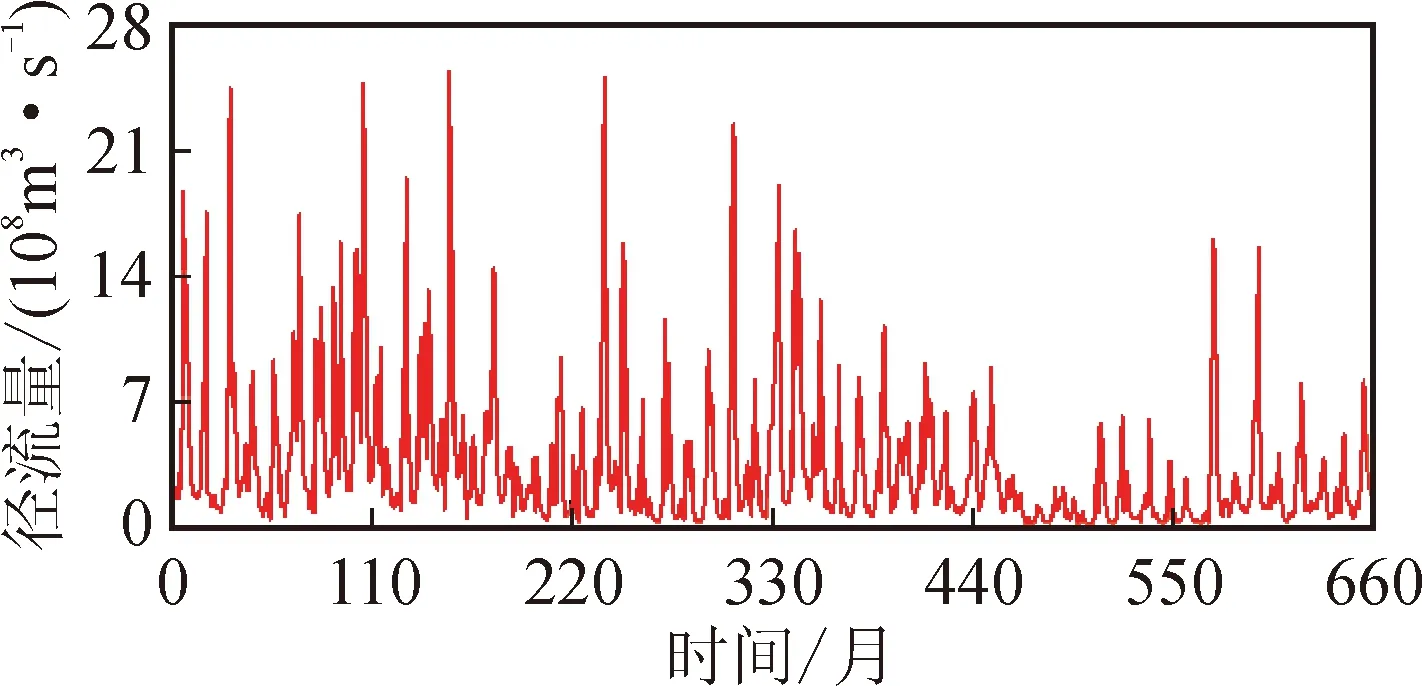
图2 咸阳站月径流序列Fig.2 Monthly runoff series of Xianyang Station

图3 临潼站月径流序列Fig.3 Monthly runoff series of Lintong Station
本实验编程使用python 3.7,其中VMD分解使用第三方库vmdpy;SVR使用sklearn库;GSA与对比优化算法使用第三方库optimal。
2.2 训练集与测试集的划分

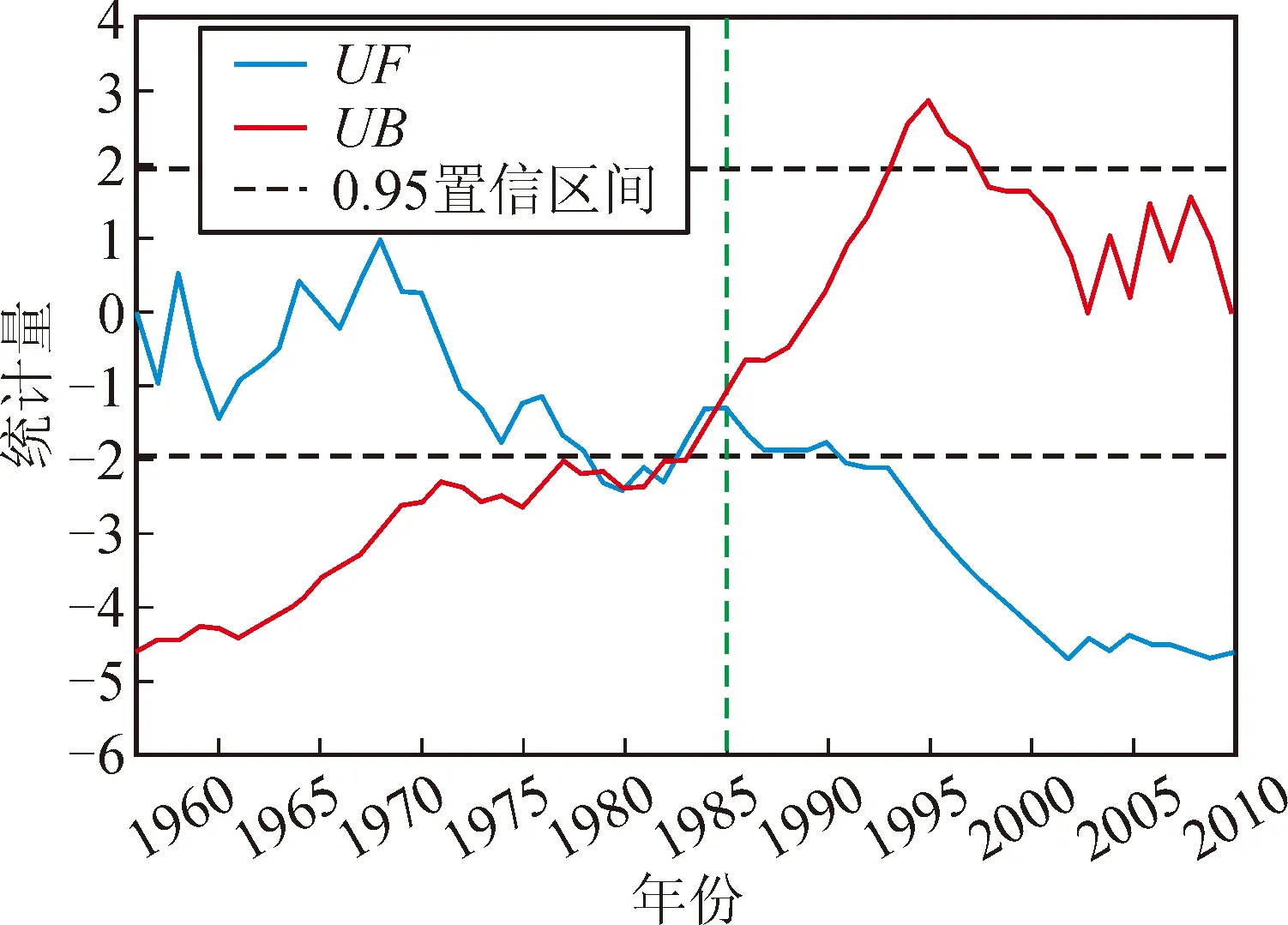
图4 咸阳站月径流M-K突变点检测结果Fig.4 Monthly runoff M-K mutation point detection results at Xianyang Station

图5 临潼站月径流M-K突变点检测结果Fig.5 Monthly runoff M-K mutation point detection results at Lintong Station
由图4与图5可知,咸阳站的突变点在1985年左右,因此选择1985年前348个月的实测月径流作为训练集,1985年后312个月的数据作为测试集;临潼站的突变点在1989年左右,因此选择1989年前300个月的实测月径流作为训练集,1989年后264个月的数据作为测试集。
2.3 月径流的VMD分解
多数信号分解方法不能手动选择模态数K,因此,很多研究在实验开始时就将整个径流序列进行分解,再划分训练集与测试集,这样做实际上将测试集的未知信息带入到了模型的训练过程中。鉴于此,可先对训练集进行分解,再选择和训练集相同的模态个数K,对测试集进行分解。
确定训练集VMD的分解模态数K时,采用枚举法,两个站的训练集数据在K=8时分解效果最好,且无模态混叠现象[19]。其余初始参数γ、α分别设置为0、2 000。测试集数据则使用与训练集相同的参数进行分解。
如图6与图7所示,两个站点的训练集数据和测试集数据分别被分解为7个周期性分量(IMF)和1个残差(R)。IMF的频率由大到小排列,R表示序列的趋势走向。每一个模态都表现出原始序列的特征,使模型能更加准确地学习径流序列的周期性与规律性特征。根据月径流的年际变化规律,将每一个模态分量滞后12个月作为模型的输入,原序列的第13个月作为输出。在考虑滞后的情况下,咸阳站的训练集样本实际为336个月,测试集为300个月;临潼站的训练集样本实际为288个月,测试集为252个月。
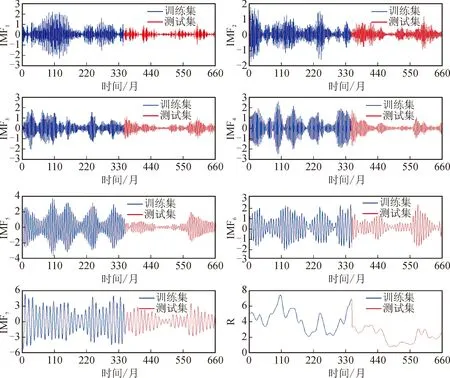
图6 咸阳站月径流VMD分解Fig.6 VMD decomposition of monthly runoff at Xianyang Station

图7 临潼站月径流VMD分解Fig.7 VMD decomposition of monthly runoff at Lintong Station
2.4 模型预测及结果评价
为了便于比较,选择无优化调参的SVR和PSO优化调参的SVR作为对比。SVR的核函数选择RBF核函数,其三个参数C、gamma、ε的搜索区间分别为[0.01,100]、[0.000 001,1]、[0.000 001,1],迭代次数n为100次,种群规模N=40。其中GSA的初始参数G0=100,α为10;PSO的初始参数c1=1.5、c2=1.7。
输入训练集进行模型训练,得到优化后的SVR参数,如表1所示。

表1 优化后的SVR参数结果Tab.1 Optimized SVR parameter results
图8和图9分别为咸阳站、临潼站测试集预测结果。表2为各站预测评价结果。
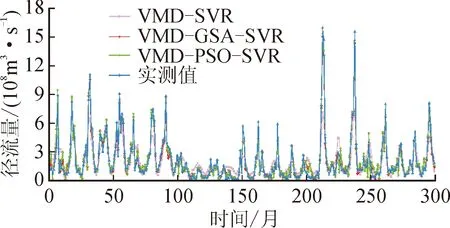
图8 咸阳站测试集预测结果Fig.8 Prediction results of test set at Xianyang Station

表2 各站预测评价结果Tab.2 Prediction and evaluation results of each station
利用优化好的参数建立PSO-SVR、GSA-SVR模型,将测试集输入模型得出预测结果并进行评价。由图8和图9可知,在未使用优化算法时,VMD-SVR模型的拟合效果较VMD-PSO-SVR模型、VMD-GSA-SVR模型明显偏差,这证明了优化算法对SVR学习过程的重要性。相较于VMD-PSO-SVR模型, VMD-GSA-SVR模型对峰值与谷值的预测更为精确,表明GSA算法对SVR参数的寻优能力明显优于PSO算法。引力搜索具有良好的全局搜索能力,而粒子群算法易陷入局部最优,因此,通过引力搜索优化的支持向量回归机取得了更优的预测效果。
由表2可知,VMD-GSA-SVR模型对咸阳站月径流预测的MSE为0.306 3,较VMD-SVR、VMD-PSO-SVR模型分别降低了84%、35%;VMD-GSA-SVR模型对咸阳站月径流预测的NSE为0.946 2,较VMD-SVR、VMD-PSO-SVR模型分别提高了45%、2%。VMD-GSA-SVR模型对临潼站月径流预测的MSE为0.712 1,较VMD-SVR、VMD-PSO-SVR模型分别降低了了66%、9%;VMD-GSA-SVR模型对临潼站月径流预测的NSE为0.952 0,较VMD-SVR、VMD-PSO-SVR模型分别提高了61%、2%。由此可知,VMD-GSA-SVR模型在两个站的预测结果评价中均达到最优,这说明该模型具有良好的拟合精度以及泛化能力。
3 结 论
本文针对月径流小样本数据,建立了VMD分解、GSA与SVR组合的VMD-GSA-SVR模型,并将其应用于渭河流域咸阳站和临潼站的实测月径流预测中。
1) 利用M-K突变点检测划分训练集和测试集,能更好地测试模型对未知数据的拟合程度。
2) 先对训练集进行VMD分解,再将训练集的VMD参数代入测试集进行分解。这样在分解过程中就不会将测试集的信息带入模型的训练过程,更加符合预测实际。
3) 利用GSA对SVR的三个参数进行寻优。相较于PSO-SVR模型,GSA-SVR模型在预测中取得了更低的误差以及更高的精度,证明GSA是一种可靠有效的优化算法。
4) 将VMD-GSA-SVR模型应用于渭河流域咸阳站和临潼站的实测月径流预测中。相较于VMD-SVR模型与VMD-PSO-SVR模型,VMD-GSA-SVR模型均取得了最优的预测结果。该模型为渭河流域的月径流预测提供了一条新的途径。
