基于卷积神经网络的时域语音盲分离方法研究
2021-09-03孙浩源
景 源,孙浩源
(辽宁大学 信息学院,辽宁 沈阳110036)
0 引言
现实的复杂声学环境,通常需要利用语音分离的方法来达到语音增强的目的.正因为语音分离对语音处理技术显得尤为重要,所以语音分离技术得到了广泛的研究,众多方法被相继提出以实现对语音信号的盲分离.例如,一些学者通过研究语音混合信号的时频特性来探索语音盲分离的可行性,同时还提出了一些利用语音时频特征的语音盲分离的方法.虽然,一些其他研究希望跳过时频特征,从其他角度来处理语音盲分离问题.但这些众多其他系统的性能无法与时频方法的性能相提并论,尤其无法将其缩放和泛化到大数据集方面.
目前的语音盲分离方法大多都是基于混合语音信号的时频域表示特征的基础上实现的,使用短时傅立叶变换(STFT)从混合频谱中近似估计出各个声源各自的纯净频谱[1],然后再通过使用非线性回归技术直接将混合频谱中的每个语音源信号的频谱近似表示出来[2-4],最后还原成分离后的语音波形.基于此原理,一些算法被提出可以先估计每个声源信号的加权函数(掩码),然后用其来掩盖在混合频谱中每个时频点上以恢复出各个源信号[5-7].由已有的一些文献可以看出,时频掩蔽方法现今仍然是最常见的语音盲分离手段,并且通过深度学习的训练手段来有效提高掩码估计的准确性,从而极大地提高了时频掩蔽方法的分离性能.在直接分离方法和基于时频掩码的语音盲分离方法中,每个声源的波形都是通过对声源的幅度谱估计值、混合声的原始相位或修改过的相位进行短时傅立叶逆变换(iSTFT)而得到的.
虽然在语音信号盲分离方法中,时频掩蔽方法比较常见,且可以取得不错的性能,但该类方法依然存在以下一些问题:第一,傅里叶变换只是通用的信号变换方法,但是并不说明它对语音信号盲分离具有最优的性能,大量研究正在寻找其更好的代替方法;第二,对干净声源的相位进行精确重建是一个重要且关键的问题,尽管已有一些方法在语音时频图谱上通过重建相位来试图解决此问题,但性能仍欠佳,尤其是不准确的相位估计会限制重建音频的质量;第三,想要成功地从时频表示中分离更干净的声源信号,需要对混合信号进行高分辨率的频率分解,这需要较长的时间窗来实现相关计算[8-10],这在一定程度上增加了系统的复杂度,进而限制了其在实时、低延迟应用中的适用性.
以上这些问题是在时频域角度上进行语音盲分离所引起的,因此本文尝试在时域中利用数据驱动的模型或方法来代替STFT,进而获得较好的语音盲分离性能[11-13].由于语音数据在数据信息上具有相当大的时域连续关联性,因此,可以通过利用时间卷积网络(TCN)提取语音编码特征[14-16].TCN在语音数据的卷积处理上允许对连续帧或片段进行并行处理[17],Yi Luo曾提出为了提高特征提取运算的整体感受野[18],卷积运算由膨胀因子指数增长的卷积层堆叠而成,此外,为了弥补由于大量零填充造成的这种空间层级化信息丢失,切割后的相邻片段重叠率高达50%,相应的多次计算重复数据等操作在一定程度上增加了系统延迟.
为此,本文尝试在卷积层中使用上一层有效数据代替卷积中的零填充来增加底层片段两端的卷积参与率,并缩减相邻的片段中的层叠部分长度,以达到在保持编码上下文高关联性的同时减少底层特征数据损失的目的.本文提出,改进的卷积时域分离网络,使用堆叠的膨胀一维卷积块代替深层LSTM网络,该方法对含有两个说话人混合语音盲分离的过程中,表现出其系统性能优于原时域语音分离网络以及已有时频掩蔽方法.
1 卷积时频语音分离网络
由参考文献[18]可知,卷积时域音频分离网络(Conv-TasNet)由四个处理阶段组成,如图1所示.首先,编码器模块将混合信号的短片段编码转换为中间特征空间中的相应表示[14-16],目的是为了计算混合音频的权重;其次,使用该空间特征表示用来估计每一个源的乘法参数(掩码);之后,用第二步生成的掩码遮掩在第一步编码后的混合音频权重上;最后,解码器模块通过转换掩蔽之后的特征编码来重建源波形合成目的音频,以达成最终分离的目的.

图1 TasNet 结构示意图
1.1 卷积编码器/解码器
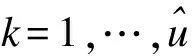
s=E(xUT)
(1)
其中U∈RN×L包含了N个向量(编码器基函数),每个向量长为L.E()是一个可选的非线性函数.有些文献采用整流线性单元(ReLU)作为E()以确保输出非负[11,17,19].
解码器使用一维转置卷积运算从该表示形式重建出波形,可以将其用矩阵乘法表示为:

(2)

尽管在实际操作中将卷积编码器(Encoder)—解码器(Decoder)的操作表示为矩阵乘法的形式,但在部分相关文献中仍然使用了“自动卷积编码器”一词,因为在模型实现中,卷积层和转置卷积层可以较为轻松地处理相邻段之间的重叠,从而表现为更短的训练时间和出色的收敛性.
1.2 估计分离掩码模块
此模块是通过对C个说话源进行估计并总共输出C个向量(掩码)实现在每一帧上分离语音的步骤.mi∈R1×N,i=1,…,C,其中mi∈[0,1]表示非负且分离后编码点的功率不能大于混合信号编码点的功率,mi就是每个向量点的遮掩码.将mi应用到混合表示s上得到相应的源表示:
di=s⊙mi
(3)
其中⊙表示对应点相乘.估计的每个源的波形信号i,i=1,…,C通过解码器重建出来:
(4)
基于编码器—解码器体系的结构可以较为完整的重构输入的混合信号这一需求,且完整的相位信息将被纳入掩码的计算.
1.3 卷积分离模块
堆积卷积模块的设计是受时间卷积网络(TCN)的启发[14-17].该体系设计成一个由众多一维膨胀卷积块堆积而成的堆叠卷积分离模块,如图2所示.在分离体系中各种任务建模序列中使用TCN而不是RNN或CNN,这样才能适应时域表示中的各种相位信息的处理,并且TCN可以对连续帧或片段进行并行处理,不用等待上一帧运算的完成,下一帧的运算可以同时进行,大大增加了运行效率.
特征提取部分由多个膨胀因子逐渐等比增加的一维卷积块组成[18],每一层的一维卷积都是时间卷积结构中的隐藏层结构.在逐级输出中隐藏层中的膨胀因子呈指数级的增长,以确保特征提取运算中能获取足够的时间上下文窗口,提高系统的感受野,以利用语音信号的长时依赖性.如图2中的不同色块所示,X个膨胀因子分别为1,2,4,…,2X-1的卷积块按次序排列,每一次卷积运算结果首先要输出保存再传输进入下一个卷积运算中.

图2 Conv-TasNet系统流程图
X次运算编成为一个次序的运算排列,总共重复R遍次序运算.每个块的输入都进行递补填充,以确保每一隐藏层输出长度与输入的长度一致,同时也减少由于逐次卷积导致片段边缘信息参与度低下的失真.由于输入的数据是定量2 ms的语音片段,所以在时间卷积运算中,或可以进行非因果运算,将递补数据填充在两端.
R重序列每个序列X重卷积总共输出的R×X个结果作为TCN的输出将被馈送到核大小为1的卷积块(1×1-conv块)以估计掩码.1×1-conv块与非线性激活函数一起为C个目标源估计C个掩码矢量,生成多个分离掩码图.
图3中显示了每个一维卷积块的设计.这里的一维卷积块的设计遵循之前某种早前方法[20],使用了残差网络(Residual network)和跳跃链接(Skip-Connection path).
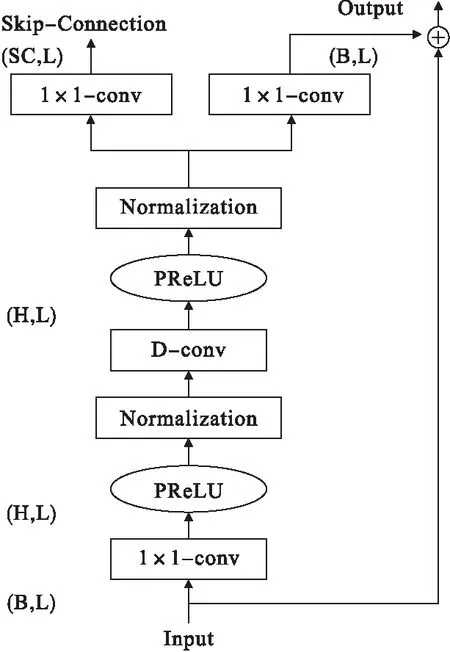
图3 1-D 卷积块设计图
一个卷积块的残差路径(Residual path)输出作为下一个卷积块的输入,而所有块的跳跃链接路径总和还要再经过一次一维卷积计算,输出的结果作为下一个激活函数的输入.为了进一步减少参数的总量以缩减模型的规模,这里采用深度可分离卷积(S-conv)替代每一个卷积块中的原有标准卷积[21,22].以前的各种文献证明,深度可分离卷积(也称为分离卷积)在语音分离任务中是有效的并且不会降低效果.
深度可分离卷积可将标准卷积运算解耦为两个连续的运算,即深度卷积(D-conv)以及跟随其后的逐点卷积(1×1-conv).深度卷积负责滤波,作用在输入的每个通道上;逐点卷积负责转换通道,作用在深度卷积的输出特征映射上.实际操作表现为可分离卷积的输入向量和可分离卷积的卷积核进行卷积操作,也就是相应行进行卷积相乘,然后又通过逐点卷积进行线性的空间特征变换.
在第一个逐点卷积和深度卷积块之后添加了非线性激活函数和归一标准化操作(Normalization)[23].非线性激活函数是参数整流线性单位[11,17,19](PReLU):
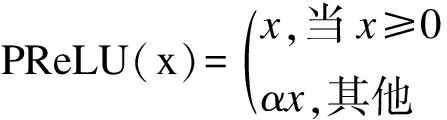
(5)
其中α∈R是一个控制整流器负斜率的可训练标量.网络中归一化方法的选择取决于因果关系要求,本实验中基本采用的是非因果关系.对于非因果配置,有些文献[23]认为全局层归一化(gLN)优于所有其他归一化方法.在gLN中,特征会在通道和时间维度上进行归一化:
(6)
(7)
(8)
其中F∈RN×T是特征,γ,β∈RN×1是可训练的参数,ε是一个为了数值稳定的小常量.
为了确保分离模块对于输入的缩放不敏感,先将选择的归一化方法应用到编码器的输出s上,然后再将该结果馈送到分离模块.
分离模块的开始处添加了一个线性1×1-conv块作为瓶颈层(Bottleneck Layer)[20].这个块确定了随后卷积块的输入路径和残差路径的通道数.如果该线性瓶颈层拥有B个通道,则对于通道数为H且核大小为K的一维卷积块,第一个1×1-conv块和第一个深度卷积块中的核大小应分别为K1∈RB×H×1和KD∈RH×K,并且残差路径中的核大小应为LRS∈RH×B×1.跳跃连接路径中的输出通道数可以不同于B,将该路径中的核大小表示为LSC∈RH×SC×1.
2 基于一维堆叠卷积的新方法
本文基于已有时间卷积网络(TCN),为了补充零填充失真计算的数据量,探索如何在稳定基本计算量的基础上获得更好的计算模型.
从实例验证的测量结果可以看到,对于频率为fc=|2ft-fj|的互调发射,文献[1]和文献[2]能够获得与本文方法一致的测量结果,但对于其它类型的互调发射,或者受限于测量设备的动态范围,无法获取测量数据,或者难以判断测量结果的准确性;相较于文献[3]的方法,本文的方法增加了线缆长度调节和互耦项消除技术措施,使得测量方法更具广泛性,而且VHF/UHF频段的环形器的带外插入损耗随入射功率变化而变化,为获取准确的测量结果,文献[3]的方法需对不同入射功率下的插入损耗进行标定,使得测试工作量非常大,本文的方法则有效避免了这一问题.
由于在原堆叠结构在隐藏层和隐藏层之间的卷积运算过程中,选择使用零填充保持输入输出数据长度的一致性.且因为本系统出现多次卷积运算,其中大量的零填充导致原编码向量在卷积提取特征中累计损失大量编码数据.此方法会造成原始数据失真,损害推理能力.因此,对无效数据进行填充是一种更合理的方法.
其次,由于数据预处理阶段要把语音波形切割,为此会出现大量毫秒级的数据片段,且连续片段之间的重叠数据量会大大增加卷积计算量.在多次正交的实验中显示,降低相邻两个连续片段的重叠帧数,由原有的50%重叠数据量降低到30%,能明显改善数据处理时间且输出结果收敛.
在非因果卷积中,每一层卷积操作,新生成的编码段都需要在片段边缘集中性的使用零填充来保持片段长度,这种操作会误差性的遮掩住来源于原始数据片段两边缘的数据.这种特征提取的失真随着卷积层的深入计算越来越多,承载的信息量每进入下一个卷积层都会被压缩,片段两边缘的信息则会被逐渐挤压到尺寸更小的数据段中.在每一个堆叠卷积也就是扩张因子从1扩张到2X-1的隐藏层特征上递过程中,承载信息数据的节点量将会被压缩至一半.数据长度虽然前后一致,但有效信息载荷将随着流程的顺序执行而逐步累积失真.
卷积层包含多个特征面,每个特征面中的神经元通过卷积核与上一层的特征面进行局部连接,使用非线性函数对局部加权进行激活,从而获得卷积层中每个神经元的输出值.卷积计算可描述为:
Hi+1=F(Ai⊗Wi+1+bi+1)
(9)
Hi+1为卷积层的输出特征矩阵;Ai为原始输入矩阵或上一层输出特征矩阵;Wi+1为第i+1层卷积核权重向量;⊗表示进行卷积操作;bi+1为第i+1层的偏置;F()为非线性激活函数.此公式可表现每一次卷积操作的输出中,失真填充的数据损失会在下一层的卷积操作累计叠加,层数越多,失真数据的数量也将会成指数速度增长.
此时的TCN是以最小化损失函数L(W,b)为网络的训练目标,选用均方误差(Mean Squared Error,MSE)作为损失函数:
(10)
一个卷积层循环如图4,所有隐藏层中需要零填充的节点由空白节点表示,第二层B1节点的零填充使得C2节点受到有效数据萎缩的影响,且C层还有C1和C16两个节点需要继续添加零节点,之后的D层将继续受到下两层有效数据量减少的内卷损失.到一个单循环结尾的E层的输出中不仅两边需要补充一半的零节点,而且中间核心八个节点也要经受之前连续三个隐藏层计算的内卷损失.最终输出层(output)中的结果相较于原始数据,数据边缘的卷积参与率低下,且无效数据填充致使特征提取失真严重.
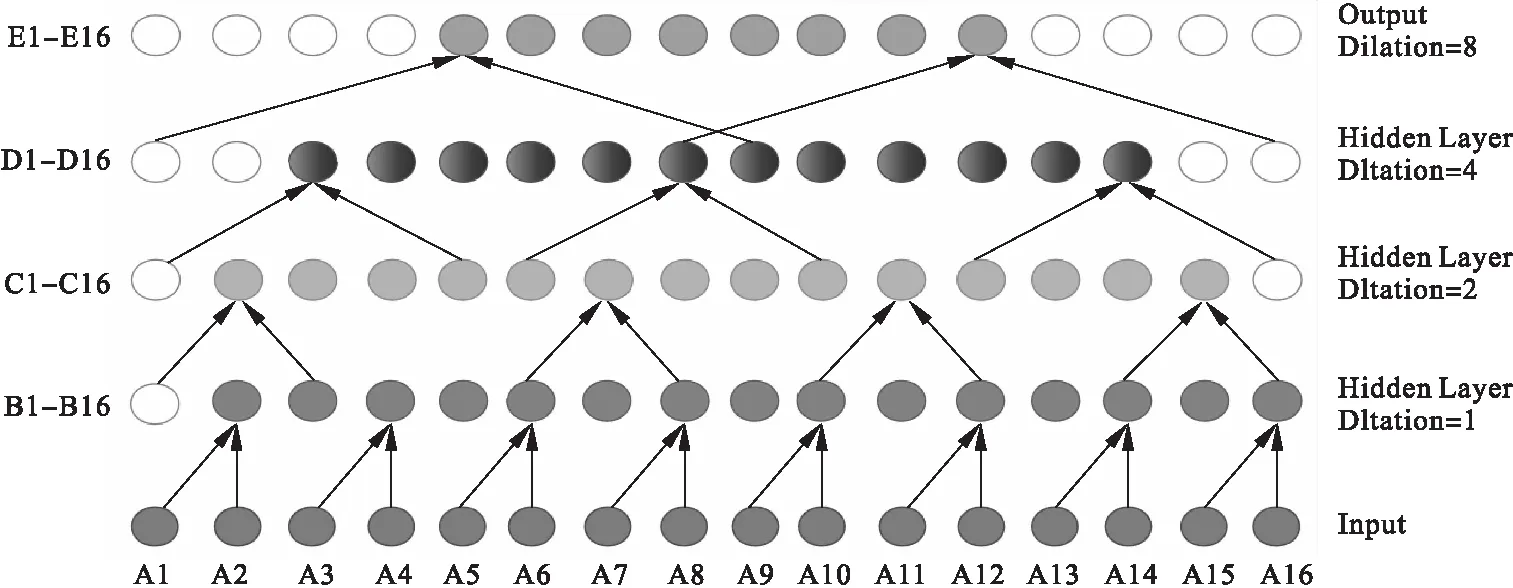
图4 非因果的零填充逐次卷积示意图
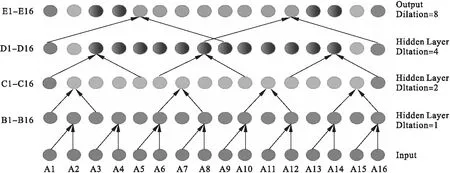
图5 递补填充的非因果示意图
依次填充直到进入最后的E层,需要填充的数据量是单个数据片段长度的一半.由图5所示,新提出的数据进位补偿可以有效弥补零填充带来的数据断裂.
此项填充方法将运用于框架中所有时间卷积运算中,总共有R×X个修正输出,再经历一次加和运算作为TCN的总输出.
3 实验结果及分析
3.1 数据集
实验使用WSJ0-2mix数据集[24]评估了所提出的新处理系统在两说话人混合信号上语音分离的性能.在数据集中生成了40 h的训练数据和12 h的验证数据.通过从“华尔街日报”数据集(WSJ0)中的不同说话人中随机选择语音并以介于-5 dB和5 dB之间的随机信噪比(SNR)进行混合来生成混合语音[25].以相同的方式生成5 h的评估集,所有波形均重采样到8 000次/s(Hz),2 ms片段共采样16次[5,7].
3.2 实验配置
网络在4 s长的段上训练了100个epochs.初始学习率设置为1e-3.如果在3个连续的epochs内,验证集的准确性没有提高,则学习率将减半.优化器使用Adam[26].卷积自动编码器使用30%的stride size(即连续帧之间有30%的重叠).训练期间应用最大L2范数为5的渐变裁剪.标准化过程统一使用的是全局层归一化(gLN)[23].
根据以往的文献中的经验,体系中一些超参数是固定的[18].编码过程中滤波器的数量N为512个,每个滤波器的长度L为2 ms(采样频率为8 000 Hz,一个片段上共有16个采样点),瓶颈和剩余滤镜中的通道数B为128个,残差链接SC通道数为128个.
卷积块中的通道数H为512个,卷积核K的大小为3,膨胀因子最大为8也就是每一次重复中都要做8次卷积运算,一共做3次重复.
3.3 训练目标
训练端到端系统的目的是最大化提高尺度不变的信噪比(SI-SNR)[27],该信噪比通常被用作评估源分离的指标用以替代SDR.SI-SNR公式定义为:
(11)
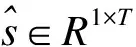
3.4 评估指标
将尺度不变的信噪比改善(SI-SNRi)和信噪比改善(SDRi)作为评估分离准确性的客观指标[27].
3.5 与理想时频掩码方法的比较
按照某些文献中的常用配置[28],计算理想时频掩码时,STFT的帧长为32 ms,帧移为8 ms,使用的窗函数是Hanning窗.理想掩码包括理想二值掩码(IBM)和理想比例掩码(IRM).
3.6 实验结果与分析
实验数据集WSJ0-2mix原本为两个人的声音,该示例的混合声音是两个说话人的重叠语音.对编码器和解码器的基函数是按照其欧几里德距离的相似性进行排序[29].
图6和图7是估计出的两个掩码,分别掩盖在编码器的输出上,可以分别得到两个分离后的功率向量.用估计出的两说话人掩码重叠的功率向量图与它们的编码器表示非常相似,所以单一的掩码可以抑制与干扰说话人相对应的编码器输出,并提取每个掩码中的目标说话人.根据每个说话人在每个时间点在相应基输出处的功率,对编码器表示进行着色(不同灰度分别表示一个人的编码功率),这显示出编码器表示的稀疏性,如图8所示.

图6 Speaker1 Mask
图7 Speaker2 Mask

图8 染色后的编码器输出

表1显示了在不同编码器和估计激活参数的参与下,修正后的方法对算法的数据提升.在表2中比较了和其他先进方法在同一个WSJ0-2mix数据集上的性能,并列出了文献中报道的最佳结果.表中缺失的值是因为研究中没有报告这些数字,或者因为结果是使用不同的STFT配置计算的.虽然依旧有一些算法的性能已经超过了本文,但与以前的所有方法相比,本实验的模型尺寸明显更小,从而具有可选择性的优势性能.

表1 新网络中不同配置的分离效果

表2 在数据集(WSJ-2mix)与其他常见方法的对比
虽然在递补填充代替零填充的步骤中引入了新的计算参数,但是并没有增加明显的计算时延,而且在最终的输出结果上有了数据意义上的进步.
4 结束语
本文采用了在时域堆叠卷积上进行递补填充的框架,既缩小了切片重叠以减少输入的数据总量,又保持了相邻片段的数据相关性,修正了无内容填充的数据偏移.该框架是一种用于时域语音分离的深度学习框架,解决了STFT域语音分离在包括相位和幅度的解耦和高延迟等一系列的劣势.这类时域卷积网络同时具有高准确性、低延迟和小模型尺寸的特点,使得其成为离线、实时、低延迟语音处理应用中的一个合适选择,如嵌入式系统和可穿戴助听器等电信设备.
然而由于使用固定的时间上下文长度,本框架对单个说话人的长期跟踪可能会数据特征丢失,特别是混合音频中存在长时间停顿的情况下,系统在单个声源特征的提取是否能识别记忆.所以需要更进一步的测试仿真混音和噪音下的泛化能力;适当可以提高输入信号维度和信息量的情况下测试输出效果,例如当有多个麦克可用时,扩展本框架来融合多通道输入语音可能会增加系统的处理能力,特别是在恶劣语音输入的情况下的收益可能会更加明显.
综上所述,本改进的框架是在语音分离算法中,为进一步提高其精度、速度和降低计算成本,探索了新的研究方向和思路,这将使语音分离的自动化成为实际应用中每种语音处理技术所共同具有的必要特征.
