基于spark技术的心脏病预测平台研究与设计
2021-08-31杨宇
杨宇
(贵州电子信息职业技术学院,贵州凯里,556000)
0 引言
随着信息技术的不断发展,大数据和人工智能技术已经渗透到医疗行业有关信息系统和智能化平台,智慧医疗、医疗大数据也开启了新一轮的研究浪潮[1],如何利用大数据及人工智能技术辅助医生对有关病例实施智能化诊断、决策成为主要的研究领域。心脏病是人类健康的头号杀手,通过对人体的有关体测指标的挖掘分析,实现辅助病理医生进行心脏病预测具有重要作用[2]。本文采用spark大数据处理技术[3],结合HDFS分布式数据存储技术[4],设计一种心脏病预测平台。利用SpringBoot技术搭建Web服务器[5],结合Mysql数据库实现心脏病预测模型与Web服务器的数据实时交互[6]。
1 系统设计
1.1 系统整体设计
本系统的整体实现构架如图1所示。
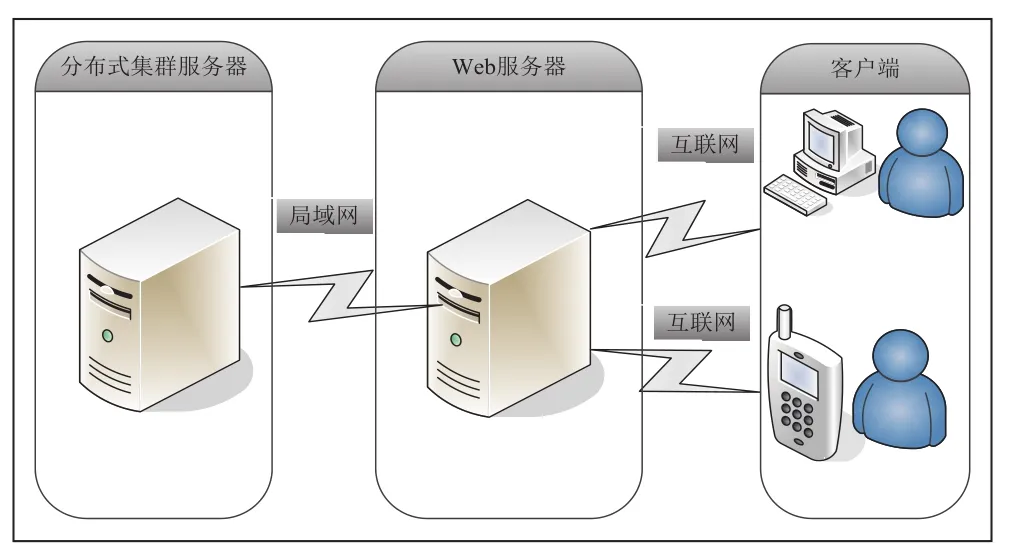
图1 系统整体构架图
整个系统主要由分布式集群服务器、Web服务器、客户端三个部分组成,其中分布式集群服务器主要负责对心脏病体测数据分析建模,其内部组成结构如图2所示。
在图2中,HDFS分布式文件存储系统用于存储心脏病体测数据,Spark大数据处理平台主要提供SparkMllib机器学习库[7],用于心脏病预测模型的建模分析,MSQL数据库主要用于存储Web前端提交的待测试数据及预测结果。
图1中的Web服务器及客户端的基本构成如图3所示。
在图2中,spark集群的sparkMllib库中的机器学习算法的预测结果被写入MYSQL数据库。在图3中Web服务器主要采用SpringBoot+Vue技术进行搭建[8],主要负责与客户端进行数据交互,为预测数据提供提交平台与结果反馈平台,以提供良好的用户体验,完成系统闭环设计。客户端主要由PC机浏览器、手机浏览器及微信入口三个部分构成,Web服务器同时支持以上三种访问模式。
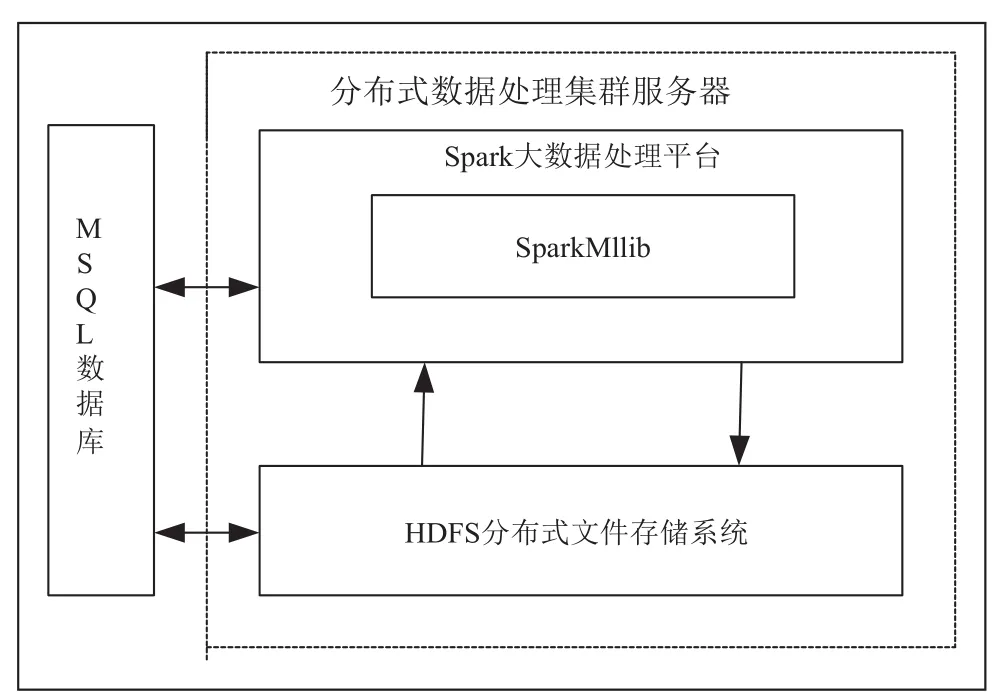
图2 分布式集群服务器结构图
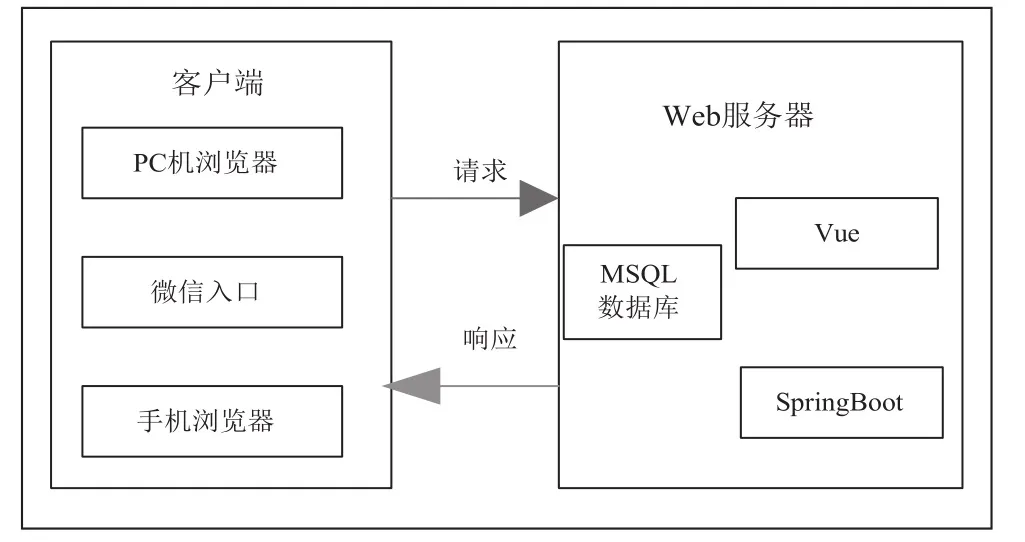
图3 Web服务器及客户端
1.2 系统模型设计
由于心脏病预测属于二分类任务,因此模型主要采用Spark大数据处理平台下的机器学习算法模块Mllib中的决策树算法进行实现。
(1)决策树算法实现预测模型
决策树是一种经典的分类算法,已经在许多分类任务上取得了良好的效果。决策树算法的模型结构呈现树状结构,每一个节点代表一个属性,每一个输出代表一个测试输出,每个叶子节点代表一个输出类别。模型训练时,以损失函数最小化为学习目标,通过不断迭代优化,即可得到预测模型[9]。决策树构建过程就是把数据按照其特征分布划分到不同的区域,该区域就属于一个类别标签。在决策树的构建过程中,需要根据信息熵作为划分标准,信息熵的计算公式下[10]:
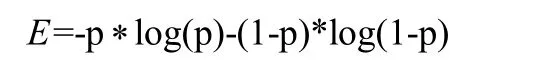
其中p表示当前节点的正样本比例,E表示该节点的信息熵,E的值越小越好。决策树算法训练心脏病预测模型流程图如图4所示。
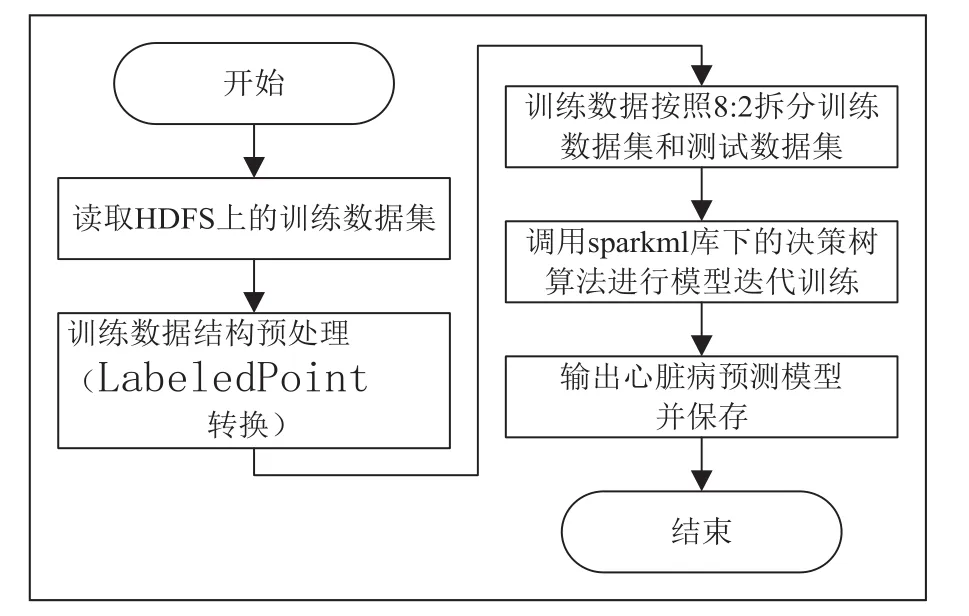
图4 决策树训练心脏病预测模型
(2)心脏病预测流程设计
Web前端提交的心脏病预测数据通过web服务器中的MSQL数据库和spark平台进行交互,从而达到疾病的预测,预测流程如图5所示。
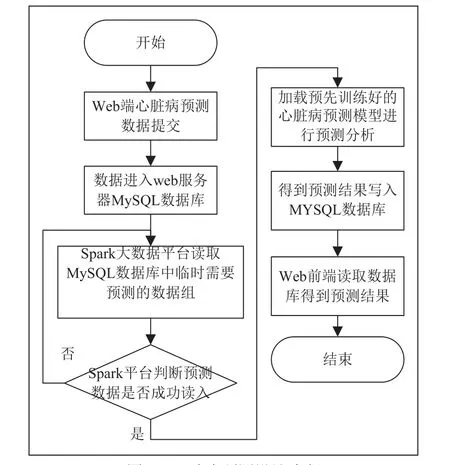
图5 心脏病预测设计流程
2 实验与分析
2.1 实验数据
本文美国某区域ICU开源体测数据为数据源,实验数据用到的字信息如表1所示。
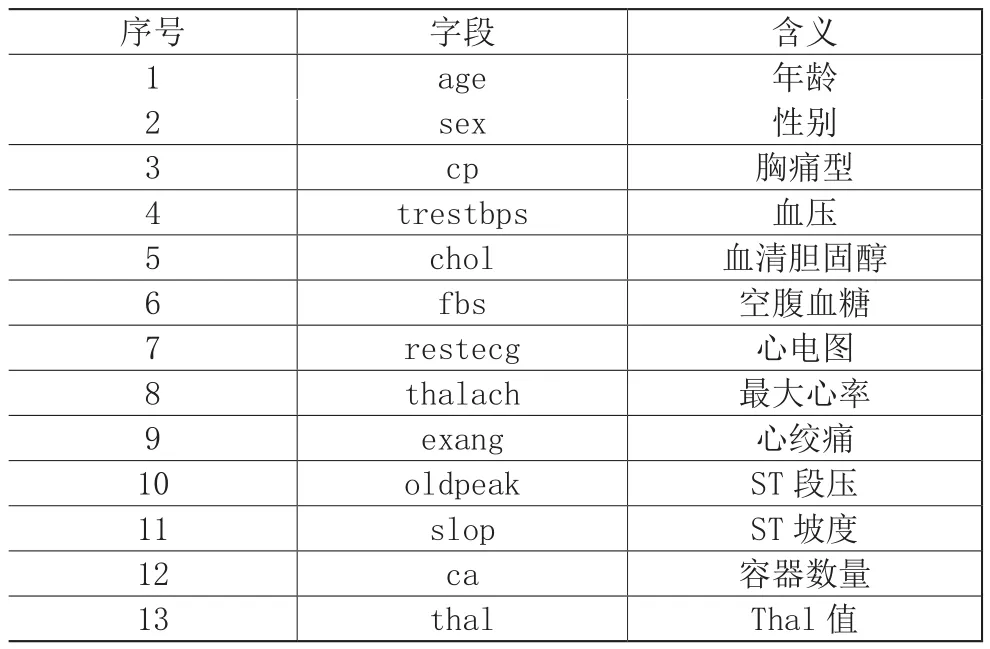
表1 实验数据字段信息
2.2 实验环境
本文实验环境采用1台管理节点服务器与4台计算节点服务器,搭建Hadoop+spark集群,其中集群共有5个节点,一个Master节点及4个Worker节点,每个节点的配置如表2所示。
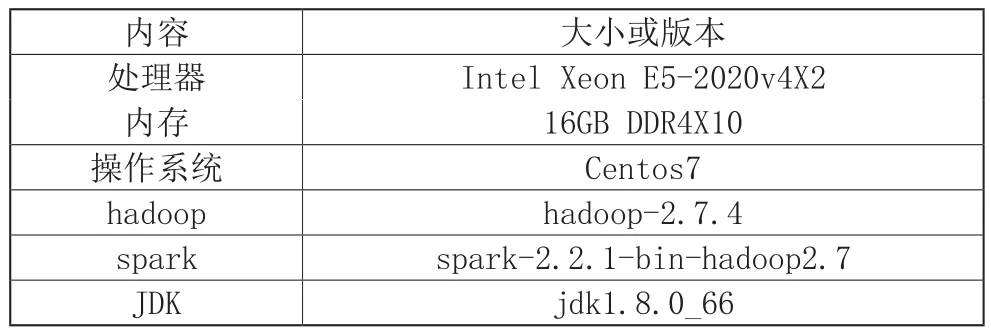
表2 每个节点配置
2.3 结果分析
数据集中80%作为训练集、10%作为验证集、10%作为测试集利用训练集数据,采用决策树算法进行训练,然后再用验证集对模型进行测试,通过20个epoch,模型准确率变化曲线如图6所示。

图6 心脏病预测模型准确率
如图6得知,当训练学习到15个epoch时,预测准确率达到89.%,随着迭代次数的不断增加,准确率变化不大,整个模型最终的预测准确率为89.2%。
Web前端的预测界面如图7所示。

图7 预测结果界面
在图7的左侧输入需要提交的体侧参数,点击提交分析预测按钮,即可在右侧得到是否患心脏病的预测结果。
3 结束语
本文主要阐述了基于spark技术的心脏病预测平台的系统整体设计、模型设计及测试结果,通过闭环的系统,将spark数据分析平台和JavaWeb进行整合,实现了对指定体侧数据是否患心脏病的预测。测试结果表明:该系统稳定可靠、操作简单、实时性……具有一定的社会意义及参考价值。
