基于自动化G/S模式的信息空间异构数据可视化共享机制研究
2021-08-29李强
李 强
(郑州航空工业管理学院,郑州 450046)
0 引言
由于信息时代的快速发展,信息空间中产生的数据剧增,且不同行业、不同科目的数据之间有着千丝万缕的关系,在做出决策时要综合各个方面的信息,因此需要访问大量不同类型的数据。由于不同类型的数据按照不同的结构存储在数据库中,也就形成了网络环境中的异构数据。异构数据的共享能够大大减少数据库的重复开发,方便用户快速获得更加全面的相关信息,因此国内外相继提出了信息空间异构数据共享机制。
异构数据共享就是整合不同位置、不同设备上传的信息,并支持用户在读取他人数据的同时进行各种操作、运算和分析,通过共享机制的设计与应用,为用户提供了一个统一和透明的界面,从而达到信息资源共享的目的。然而现阶段对于共享机制的研究主要侧重于对异构数据库的共享,典型的共享方式包括基于元数据目录服务的数据共享机制、基于空间数据网格的共享机制以及基于网关数据传送机制的共享机制。在传统的共享机制中,为了保证共享数据的安全性,会在共享之前对异构数据进行加密处理,这也就导致共享的透明性降低,在实际的应用过程中存在共享数据查询速度慢、查询受限等问题。
为了解决上述传统共享机制存在的问题,引入自动化G/S模式,实现对信息空间异构数据的可视化共享,即在保证数据安全的前提下,最大程度的提高共享的透明度。自动化G/S模式也就是地学浏览器/空间信息服务器模式,可以存储和交互不同种类、不同规模的数据。与传统的C/S共享模式相比,解决了无法处理音频、视频等类型数据的缺陷,并简化了数据查询和调度的工作流程。通过自动化G/S模式的应用,对共享机制进行优化设计,以期提高异构数据的共享功能,间接的提升数据资源利用率。
1 信息空间异构数据可视化共享机制设计
1.1 挖掘信息空间异构数据
在信息空间环境下,利用关联规则挖掘技术挖掘异构数据,在关联规则的约束下对比数据,并将符合规则的数据提出,得出异构数据的挖掘结果。定义初始信息空间的异构数据中包含N个事务数据,最小支持数为mincount,则在数据挖掘过程中最小支持度可以表示为:
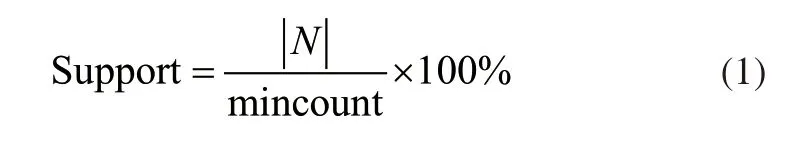
并以式(1)的计算结果作为挖掘的最小支持数要求,在此基础上对异构数据库进行第一次扫描,得出其中包含每个项目的出现次数,并生成候选项集C1。根据mincount要求得出集合L1,并执行L1L2操作,生成候选集C2,扫描异构数据库对C2中的项目进行计数。同理可以得出L2、Cn和Ln。比对Cn和Cn-1中的项集内容,并将重复的剔除,直到Cn集合为空。经过对信息空间异构数据的连续迭代,得到信息空间异构数据的挖掘结果,并以此作为可视化共享数据。
1.2 多元异构空间数据转换处理
多元异构空间数据转换的目的是将数据转换成相同形式,消除数据的异构性。数据转换处理可以分为两个部分,一个是异构空间数据向XML文档转换,另一个是XML文档数据与信息空间数据库服务器的相互转换。该封装器用于实现异构空间数据到XML文档的转换,该封装器由几个相互独立的封装器组成,每个封装器对应一个数据源,如图1所示。
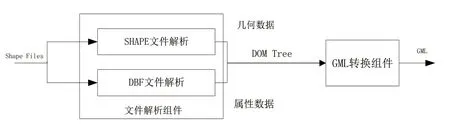
图1 数据转换封装器结构图
从图1中可以看出,文件解析组件用于解释SHAPE文件,提取集合数据,解释DBF文件,提取文档对象树属性数据。将空间数据库服务器中存储的关系数据映射成XML文档,并进一步转换为SVG格式,实现空间数据在客户端的可视化。图2中显示了具体的映射过程。
图2 文档数据与数据库服务器的映射转换关系图
1.3 集成信息空间异构转换数据
将转换完成的数据存储到数据端,服务器利用远程技术访问数据端的XML数据,并将数据映射到数据库服务器中,通过分析和查询操作,最终将操作结果上传给客户端。需要考虑的是在数据集成的过程中,信息空间还会产生新的异构共享数据,因此当多个异构数据源中的数据发生变化时,需要立即更新集成数据,保证异构数据与共享数据的同步性。
1.4 自动化G/S模式下构建共享浏览器缓存模型
自动化G/S模式由G端和S端两部分组成,其中G端为任意终端,也就是共享机制中的用户,在G端安装通用的地学浏览器装置,为了保证与服务器之间的有效交互,确定统一的地理标记语言为HGML,地理标记标准语言的基本数据类型如表1所示。

表1 HGML基本数据类型
G/S模式中的S端也就是信息空间分析的服务平台,该部分由数据注册中心、存储云以及分布式文件管理模块组成。在HGML数据传输共享标准的约束下,完成共享信息交互、解译客户端请求以及共享任务调度的功能。在自动化G/S模式下构建共享浏览器缓存模型,G端为了支持多类型数据存储,HGML对缓存的异构数据进行描述管理,设置数据的存储位置、更新替换等功能。G端缓存模型的设计结果如图3所示。

图3 自动G/S模式下G端缓存模型
通用浏览器的缓存机制主要基于缓存查询和自适应缓存替换策略。在实际的运行过程中,G端接收一个服务器传输来的异构数据,并产生一个Key值。通过数据对象的Key值判断缓存模型中是否存在该数据,若查询结果显示该数据已经存储过,则新接收的数据进入缓存替换模块,否则进入数据存储模块。通过建立多个缓存集合用来存储不同类型的异构数据,根据异构数据对象的类型检索对应的缓存位置,并对当前缓存模块的运行状态进行判断。一般来讲,缓存模块的运行状态可以分为正常存储和存储故障两种状态,若缓存模块处于正常存储状态,且异构数据的存储量小于缓存模块的空间剩余量,则将该数据直接写入对应的存储位置上,否则进入缓存替换模块。接收的所有数据完成缓存任务后,对G端的数据索引表进行更新。在共享数据的调用过程中,可以通过调取数据对象的Key和类型,执行读取、删除、存储等操作,缓存命中完成后,返回请求数据,降低数据缓存冲突的发生概率,同时也提升存储空间的利用合理性。
1.5 异构数据可视化发布
在构建的共享浏览器缓存模型中,除了共享异构数据外,还将异构数据对应信息空间不同侧面的数据视图以SVG文档形式存储,这些视图是实现网络环境下数据可视化的基础。SVG文档中定义了点、线、面等基本形状,并通过调整文档中数据的style属性指定视图元素样式。当客户端发出共享申请且通过后,自动化G/S模式调用相应的共享数据,抽取相应视图进行合并重组,建立用户可视化输出的二维数据视图。假设共享数据抽取了n个异构数据,且每个异构数据有m个数据侧面,则可视化数据视图集合可以表示为:

式中DBn为信息空间异构数据,的表达式为:

其中Ii和Pi分别对应的是DBn的指标集和侧面数据项。那么在异构数据可视化输出过程中,提取共享数据对应的视图,并按照共享数据的排列顺序连接视图,实现异构数据的可视化发布。
1.6 实现信息空间异构数据可视化共享
为了保证信息空间异构数据共享的安全性,需要借助一个数据共享纽带,也就是特定行业标记语言XXML。数据共享纽带的建立过程如图4所示。

图4 共享纽带建立流程图
在共享纽带中嵌入一个数据解析程序,数据解析的目的是对加密的异构数据进行解码处理,提升数据资源的查询、调用效率。若多个用户同时提交共享申请,为了避免中心服务器可能会出现提交负载不及时的问题,需要对网络负载进行均衡调度。定义异构数据共享线程中,节点的处理时间和速度分别为ti和vi,则存在如下关系式:

考察共享平台中的第一个数据节点,并对公式4进行调整。假设共享平台中剩余的数据节点均按照内部最佳调度策略进行处理,则剩余节点序列Nj中负载最大节点所消耗的调度处理时间为:

式中p1为共享负载最大节点。要保证共享过程中各个节点的负载均衡,提高共享任务的并行处理能力,则要求式(6)中的条件成立。

那么在自动化G/S模式下为每一个数据节点建立一个临时变量,设置临时变量的初始值为0,分别记录可视化共享的起止时间,得到各个节点的任务耗时。根据任务耗时的统计结果,按照由小到大的顺序排列节点序列,并按照序列顺序分配与提交共享任务。根据实时节点的处理进度,对共享任务顺序进行调整,直到所有节点完成异构数据可视化共享进程。
2 共享性能测试实验分析
为检验设计的基于自动化G/S模式的信息空间异构数据可视化共享机制的可行性,设计性能测试实验。实验的核心目标任务包括:设计机制是否能完成异构数据注册、传输、可视化和共享任务,是否具备数据共享和交互操作能力。
2.1 配置测试实验环境
为了保证实验变量的唯一性,实验选择地质异构数据作为实验的研究数据对象,并以地质数据共享平台作为实验的主要运行环境。在实验环境中安装计算机、服务器和数据传输网络设备,并在主测计算机上安装共享平台软件程序,得到平台的运行主界面。计算机和网络服务器选择的操作系统分别为Windows XP和MicrosoftIIS6.0。由于设计的异构数据可视化共享机制应用了自动化G/S模式,因此需要在实验环境中配置相应结果,保证该模式的正常运行。除了主测计算机外,搭建主机主测中心和数据存储环境,并模拟多个虚拟用户主机,用户主机在测试S端接口时可以使用浏览器直接访问,而在测试G接口功能时,需要利用客户端程序进行具体测试。实验环境中的网络运行服务器上均安装TomCat 6.0.18,并分别在两个服务器设备上部署S端数据注册程序和G端检索服务程序。
2.2 准备信息空间异构数据共享样本
为了给共享性能测试实验提供大量的数据支持,在实验环境下分别构建ArcIMS和GeoBeans WebGIS两个信息空间,且每个信息空间带有不同数量的异构数据。准备的实验信息空间和异构数据均存储在实验数据库中,方便数据调用。实验数据共享样本的准备情况,如图5所示。

图5 信息空间异构数据共享样本
另外异构数据的共享需要一定的权限,因此需要在共享平台上对导入的数据样本进行注册,保证样本数据的可读性。
2.3 设置共享性能测试指标
实验分别从共享性能和应用性能两个方面进行具体测试,其中共享性能的测试指标为共享信息的读写传输速度,该指标就是读取共享信息读取/写入任务的输入时间到读取/写入结果的输出时间,读写越快,证明共享效率越高,共享性能越优。另外应用性能的测试,主要就是将设计的共享机制应用到共享平台中,观察平台节点负载的变化情况和共享数据丢失情况,统计输入异构数据样本与共享接收数据样本之间的数据量大小,通过两个数据的相减计算,便可以得出量化的数据丢失结果。
2.4 描述共享性能测试过程
为了形成实验对比,除了设计的异构数据可视化共享机制外,还设置了传统数据共享机制和基于元数据的共享机制作为实验的两个对比项,具体的共享运行方案如表2所示。
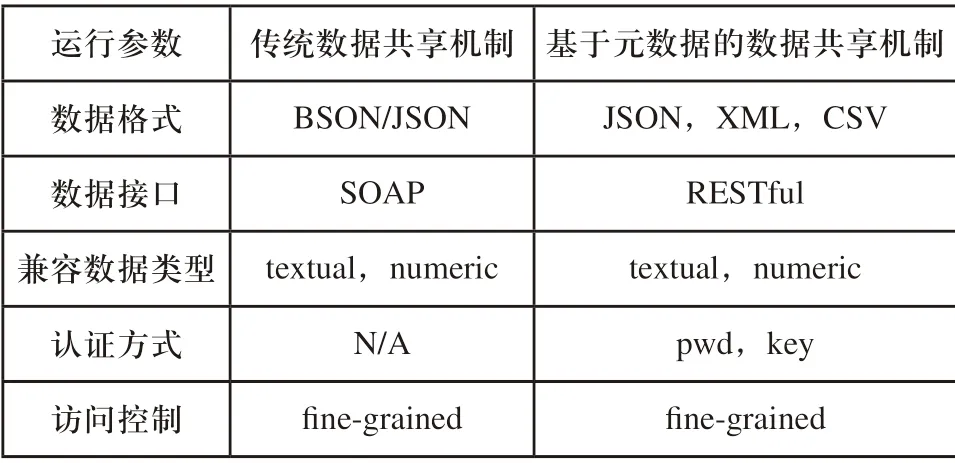
表2 共享机制运行方案
将共享机制与准备的共享数据样本存储空间之间形成连接,并在共享平台的驱动运行下,得出共享输出结果,其中设计共享机制的可视化输出结果如图6所示。

图6 信息空间异构数据可视化共享输出界面
分别设置异构数据读取、写入、查询等任务,调取共享平台的后台运行数据,并记录相关的测试数据,其中共享数据查询输出结果,如图7所示。

图7 异构数据共享数据查询界面
2.5 共享性能测试结果分析
为了保证实验结果的可信度,采用多次实验取平均值的方式得出测试结果,其中共享性能的测试结果,如表3所示。
从表3中可以看出,三种共享机制的平均读写耗时分别为1.35s、0.75s和0.44s,即设计可视化共享机制的共享传输速度更快,共享性能更高。同理可以得出三种共享机制在共享平台下的应用测试结果,如表4所示。

表3 共享性能测试结果
从表4中可以直观的看出,两种对比共享机制均存在不同程度的节点荷载分布不均的情况,而应用设计共享机制,节点负载均控制在区间[22,25]之内。从共享数据丢失情况来看,应用三种共享机制对应的数据丢失量分别为2.24MB、1.53MB和1.03MB。
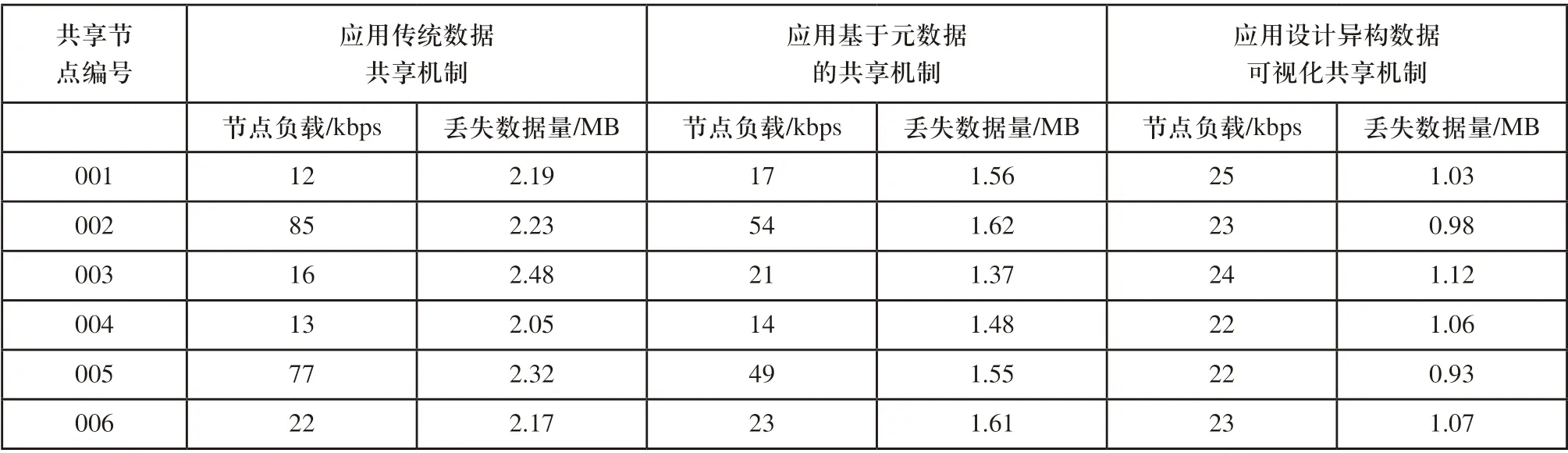
表4 共享机制应用性能测试结果
3 结语
综上所述,通过自动化G/S模式的应用能够有效的提升共享机制的运行性能和应用性能,对于信息空间而言具有较高的应用价值。然而在共享性能测试实验中,未考虑到共享平台多并发数的情况,针对这一问题还需要在今后的研究中进行补充。
