水利行业地下水监测系统水位埋深数据质量评估与对比
2021-08-25王卓然鲁程鹏
邱 磊, 孙 龙, 于 钋, 王卓然, 李 伟, 林 锦, 鲁程鹏
(1.河海大学 水文水资源学院, 江苏 南京 210098; 2.水利部信息中心, 北京 100053;3.南京水利科学研究院, 江苏 南京 210029)
1 研究背景
为水利部门编制《地下水动态月报》服务的地下水观测站(采用数据人工报送方式,下文简称“人工站”)分布在全国地下水开发利用主要平原区,共布设2 800个人工观测站,水利部将获得的地下水信息以单站月报形式延迟1~2个月进行传输归档。这种原有地下水监测方式存在传输手段落后、数据传输时效性差、机民井占比较多、监测能力和监测数据质量低等问题[1],给需要实时获得地下水水情的相关研究造成诸多不便。为了总体上提高地下水监测数据的时效性和准确性,2014年,我国启动建设国家地下水监测工程[2],该工程共建设监测站20 401个,其中水利部建设监测站10 298个(下文简称“自动站”)[3],基本实现了对全国大型平原、盆地地下水动态的区域性监控[4]。与人工站相比,自动站采用先进的信息采集监测设备和技术传输,实现了数据采集、传输、存储的自动化,有效提高了监测能力和监测数据质量[1-5]。
数据质量决定了它的价值。目前,国内外本领域技术研究人员在数据质量方面做了许多相关研究。若对数据量庞大的全部统计数据进行分析,则效率极低,可采用部分抽样的方法进行质量评估[6]。数据质量问题产生于数据在监测、远程传输、汇编过程中的各个环节。数据质量评估首先明确数据质量问题产生的来源及其分类[7],其次从时间和空间两个维度,从合理性[8-10]、完整性[9、11]、差异性[11]、一致性[12]、代表性[13]等多方面进行分析。每个方面给定评价水平量化标准,进而建立相对完整的数据质量评估体系。
近年来,不同领域相继开展了人工观测站和自动监测站的数据质量对比分析[14-16],但是关于地下水人工站和自动站的水位埋深数据质量对比分析几乎未见报道[17]。地下水监测数据是观察地下水超采治理成效、实施地下水管理与决策的基础,全国不同系统为不同功能建设的地下水观测站数量众多,自动站与人工站数据监测位置不同,很难在单站监测数据上进行直接对比。本文利用布站位置不同的人工站和自动站2018年同期水位埋深资料,采用统计学方法,从完整性、合理性、代表性、一致性4个方面对水位埋深数据进行质量评估及对比分析,旨在说明自动站与人工站监测数据在统计意义上的差别,同时比较国家地下水监测工程水位埋深数据和原人工站监测数据的质量优劣,从而发现目前我国地下水水位埋深数的据质量问题,并提出提升数据质量的方法[18]。
2 数据来源与研究方法
2.1 数据来源
收集整理人工站和自动站2018年地下水埋深数据,根据空间连续性、历史延续性和地缘政治地位,将地下水观测站按流域进行分割。如果对全部的自动站水位埋深数据进行完整性、合理性分析,则工作量大、耗时长,因而按实有水位埋深数据站点总数的5%,结合随机抽样、分层抽样的方法,确定了499个样本站点,对全部人工站和代表性自动站进行地下水埋深数据完整性、合理性评估,各类型站点分布见表1。
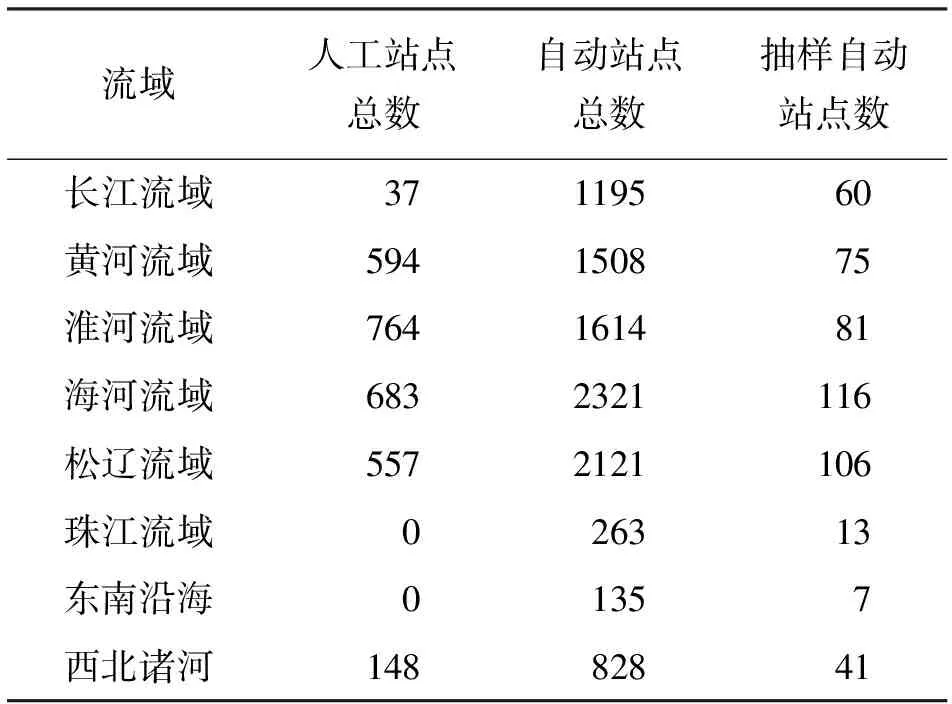
表1 各流域地下水观测人工站、自动站及所选取的抽样自动站数量
2.2 评估指标
数据质量是指监测的数据能否满足预期要求[19]。本文从完整性、合理性、代表性、一致性4个方面对两套地下水水位埋深数据进行质量评估和对比分析。
(1)完整性。完整性是指监测系统在研究时段内监测的数据频次和总量是否满足预期要求,数据有无缺失[20],缺失率可以衡量数据的完整性程度[21]。数据缺失率计算公式如下:
(1)
式中:W为研究流域监测数据缺失率;n为流域内观测站点总数;Ai为站点i的缺失数据量;Bi为站点i的理论数据量。
(2)合理性。合理性是指实测的地下水位埋深数据是否在合理范围之内,有没有数据录入错误现象。数据异常率最能直接反映出研究时段内监测到的地下水位埋深数据的合理程度,异常率是指监测数据中的异常数据量与实际监测总数据量的比值,其计算公式如下:
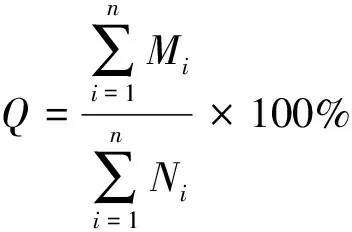
(2)
式中:Q为研究流域监测数据异常率;n为流域内站点总数;Mi为站点i的异常数据量;Ni为站点i的实际数据量。
本文结合统计模型和距离模型检测出全部地下水水位埋深数据异常值。
基于统计模型对异常值检测,首先给定一个置信区间,超过此置信区间的数据即为异常值。计算数据集的最小值Qmin、第1四分位数Q1、中位数Q2、第3四分位数Q3、最大值Qmax这5个统计量,绘制出箱型图,箱内包含了大多数的正常数据,处于箱体的上边界和下边界之外的数据,视为统计上的异常数据[22],其上、下边界的计算公式如下:
max=Q3+(Q3-Q1)×1.5
(3)
min=Q3-(Q3-Q1)×1.5
(4)
箱型图在非正态分布数据中判断异常值的时效性是有限的,故本文仅采用箱型图对地下水埋深数据进行初步异常值检测,还需采用基于水位埋深差的距离模型对异常值进行精细检测。
地下水埋深时间序列前后数据应具有较高的关联性,即前后数据在正常情况下的差值应在一定的阈值内,采用基于水位埋深差的距离模型对时间序列数据的异常值进行精细检测,是在计算水位埋深时间序列变化率的基础上,事先给定速率变化界限,通过计算检验,得到异常值发生的位置。其具体方法步骤如下:
步骤1:读入地下水水位埋深时间序列数据{y(t)}。
步骤2:计算相邻时间序列地下水水位埋深变化率Δy(t):
Δy(t)=y(t+1)-y(t)
(5)
步骤3:求出变化率Δy(t)的均值μ和方差σ:
(6)
式中:T为水位埋深监测时间序列(T=1,2,…,N)。
(7)
步骤4:异常值发生的位置位于:
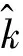
(8)
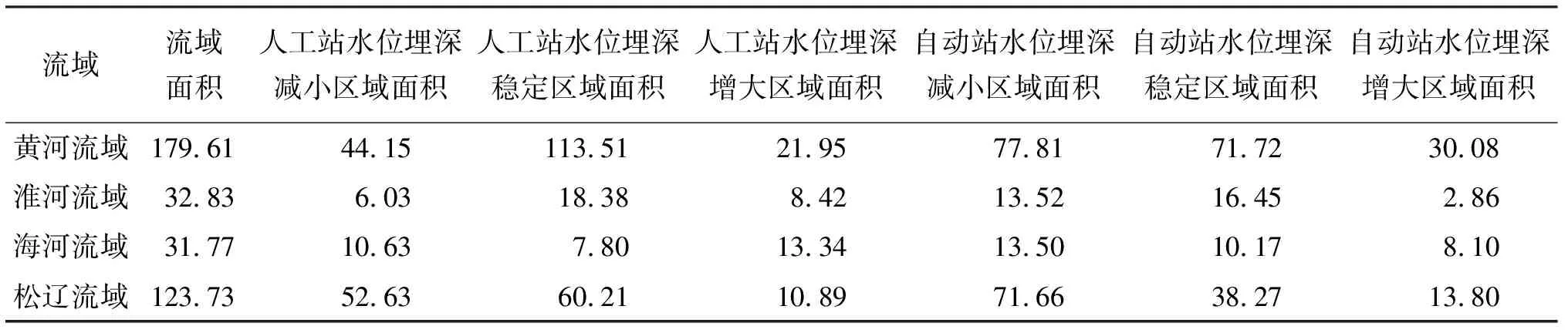
(3)代表性。代表性是指监测的水位埋深数据能够在多大程度上反映研究区域内水位埋深要素的真实空间变化特征。本文分别计算人工站、自动站2018年的年内水位埋深变化,并绘制松辽流域、黄河流域、淮河流域、海河流域的人工站、自动站水位埋深变化等值面图,进而评估自动站的水位埋深在空间上的变化是否能够真实地反映地下水埋深要素的变化特征。
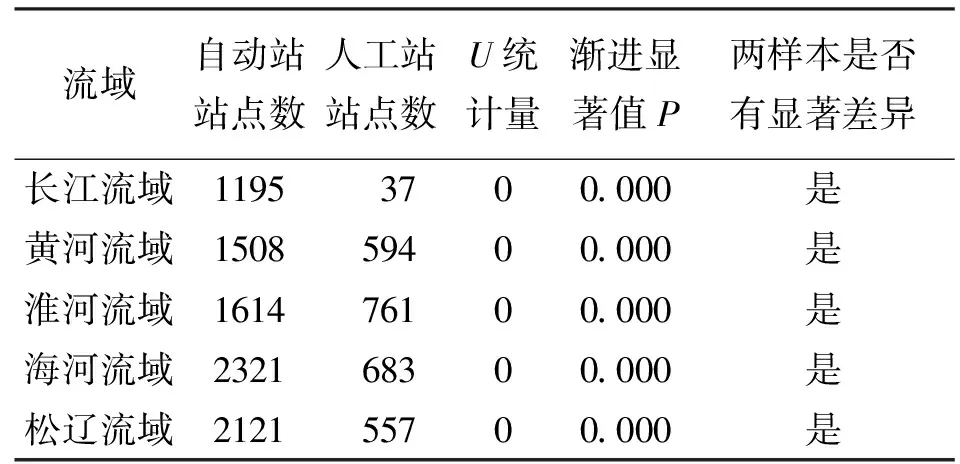
(4)一致性。一致性是指在一定显著性水平下各流域两套监测系统地下水月平均埋深以及2018年年内水位埋深的变化趋势是否一致。本文以黄河流域、淮河流域、海河流域、松辽流域为研究单元,在对各研究流域内人工站、自动站的月平均水位埋深进行一致性检验时,由于并不了解总体的分布类型,因此采用非参数检验中的曼-惠特尼检验法(Mann-Whitney)。曼-惠特尼检验需要借助于渐近显著性(双侧)P值来进行判断。当渐近显著性值p 对水文时间序列进行变化趋势分析能够掌握水文要素变化发展规律[23]。本文结合线性趋势法和Mann-Kendall检验法判断水位埋深变化趋势及趋势显著与否。Mann-Kendall检验借助于统计量Z,统计量Z>0为上升趋势;Z<0为下降趋势[24-25]。当|Z|≥1.64时,表示统计量通过了置信度为95%的显著性检验[26],在统计期内水位埋深变化趋势显著,否则变化趋势不显著。 逐个检测各流域代表性自动站和全部人工站2018年水位埋深缺失数据,人工监测站每5 d监测1次数据,自动监测站每4 h监测1次,每日监测6次[17]。结合统计模型和距离模型检测出全部异常值,各流域的缺失率和异常率如表2所示。 由表2可知,与人工站相比,自动站各流域整体缺失率和异常率均有所减小,水位埋深数据的完整性及合理性较好。自动站的仪器设备更加先进,实现了整个监测过程的全自动化,仪器稳定性良好,监测精度更高。 表2 所选流域代表性自动站和全部人工站2018年水位埋深数据缺失率和异常率 选取黄河流域、淮河流域、海河流域、松辽流域为本次代表性评估的研究单元,计算各流域人工站和自动站2018年的年内地下水水位埋深变化,并采用反距离权重插值法绘制地下水水位埋深变化幅度等值面图,分析各代表性流域人工站、自动站地下水水位埋深减小、稳定和增大区域的面积,其结果如表3所示。 表3 所选流域人工站和自动站2018年地下水水位埋深年内不同变化区域面积 104 km2 将地下水埋深变幅分为3个等级。地下水埋深变幅在-0.5~0.5 m之间属于稳定区;大于0.5 m为埋深增大区;小于0.5 m为埋深减小区[27]。由表3可知:(1)黄河流域、淮河流域、海河流域、松辽流域这4大研究流域,人工站水位埋深增大区域占各自流域总面积比例的范围为8.80%~42.00%,其中,占比最大的为海河流域,其次为淮河流域、黄河流域、松辽流域;人工站水位埋深稳定区域占各自流域总面积比例的范围为24.55%~63.20%,其中,占比最大的为黄河流域,其次为淮河流域、松辽流域、海河流域;人工站水位埋深减小区域占各自流域总面积比例的范围为18.37%~42.54%,其中,占比最大的为松辽流域,其次为海河流域、黄河流域、淮河流域。(2)黄河流域、淮河流域、海河流域、松辽流域这4大研究流域,自动站水位埋深增大区域占各自流域总面积比例的范围为8.71%~25.50%,其中,占比最大的为海河流域,其次为黄河流域、松辽流域、淮河流域;自动站水位埋深稳定区域占各自流域总面积比例的范围为30.93%~50.11%,其中,占比最大的为淮河流域,其次为黄河流域、海河流域、松辽流域;自动站水位埋深减小区域占各自流域总面积比例的范围为41.18%~57.92%,其中,占比最大的为松辽流域,其次为黄河流域、海河流域、淮河流域。 (3)从所选的4个流域整体分析,人工站水位埋深增大区域面积占研究区总面积的比例为14.84%,埋深稳定区域面积占研究区总面积的比例为54.33%,埋深减小区域面积占研究区总面积的比例为30.83%;自动站水位埋深增大区域面积占研究区总面积比例为14.90%,埋深稳定区域面积占研究区总面积比例为37.13%,埋深减小区域面积占研究区总面积比例为47.97%。自动站与人工站在3个埋深变幅等级中,埋深稳定区面积占研究区总面积的比例相差最大,差值为17.20%。由此可知,两种数据源绘制得到的各流域各等级水位埋深变幅均存在差异。 地下水自动站全部采用一体化的自动监测设备[28],实现了数据的自动接收、传输与归档,监测系统的稳定性及监测技术远远高于人工站,此外,两种不同类型的监测站点所处地理位置不同,人工站监测密度不及自动站的1/4,地下水监测自动站的覆盖范围明显大于人工站,结合文献[17]、[29]可知,自动站监测结果相比于人工站更具有代表性,更能表征我国地下水埋深的空间分布特点。 3.3.1 水位埋深月平均值一致性评估 利用非参数Mann-Whitney检验(统计量为U)比较各流域两套地下水监测系统2018年月平均水位埋深数据的一致性,分析结果如表4所示。 由表4可知,在所选的研究流域内,人工站与自动站2018年月平均地下水位埋深不具有一致性。原因可能是两套监测系统站点布设位置不尽相同,地下水埋深受站点所在地势影响较大,处于不同地理位置站点的地下水埋深可能会相差很大。 表4 所选流域人工站与自动站2018年月平均地下水水位埋深一致性分析结果 3.3.2 变化趋势一致性评估 结合线性趋势法和Mann-Kendall检验[31],判断所选流域人工站与自动站2018年地下水埋深月变化幅值和趋势性,结果如图1所示。 图1 所选流域人工站与自动站2018年地下水埋深月变化幅值和趋势性检验 由图1可知,2018年各研究流域内人工站水位埋深月变化幅值在-0.12~0.09 m之间,月平均变化幅值为-0.014 m,人工站水位埋深趋势性检验Z值为-3.09~3.50,平均Z值为-0.19;自动站水位埋深月变化幅值在-0.24~0.10 m之间,月平均变化幅值为-0.046 m,自动站水位埋深趋势性检验Z值为-4.79~6.10,平均Z值为-0.82。全流域内人工站和自动站水位埋深均呈减小趋势,且减小趋势均不显著,两套监测系统地下水位埋深变化趋势一致,并且各个流域人工站与自动站的地下水埋深变化趋势也相同,均呈减小趋势,但变化趋势并不显著。由此可知,人工站与自动站2018年水位埋深在时间上的变化趋势具有一致性。 地下水自动站覆盖了全国主要平原盆地和人类活动区,监测频率为4 h[32],与人工站相比,自动站的站点密度在一定程度上得到了优化,覆盖面更广,监测频次显著增加,实现了监测数据自动化传输,国家地下水自动监测站水位埋深数据质量高于人工站。 目前,我国地下水数据库的建设仍处于初步阶段,部分地区的地下水监测网布局不够科学合理,监测设备未及时更新,导致部分自动站站点数据质量不高。可以通过全面统筹规划地下水自动监测网,在重要地区和地下水超采区增设更加专业的监测井,不断更新地下水监测设备,进一步提高监测数据质量。此外,增加人工站与自动站监测网之间的有效融合也有待于进一步研究。 基于全国地下水人工站和国家地下水监测工程(水利部分)地下水自动站2018年同期水位埋深实测资料,采用总体评估和抽样分析相结合的方法,从完整性、合理性、代表性、一致性4个方面对两套地下水埋深数据质量进行评估与对比,分析结果表明: (1)自动站与人工站相比,水位埋深数据平均缺失率由13.53%降为6.39%,异常率由1.63%降为0.84%,自动站的水位埋深数据完整性和准确性均高于人工站。 (2)自动站监测水位埋深与人工站存在显著差异,两套地下水监测系统2018年各流域平均水位埋深数据不具有一致性,两套数据在水位埋深动态变化趋势上基本一致,具有较好的可比性。鉴于地下水自动站采用的监测设备更加先进、监测水平更高,且自动站站点的密度和覆盖范围较人工站显著增加,因而自动站监测数据更具有代表性。 (3)总体来看,国家地下水监测工程(水利部分)水位埋深数据质量高于原人工站的监测数据,但鉴于部分站点数据缺失率较高,因此,对监测设备及监测技术进行持续性改进提升仍是必要的。3 结果与分析
3.1 完整性及合理性评估结果
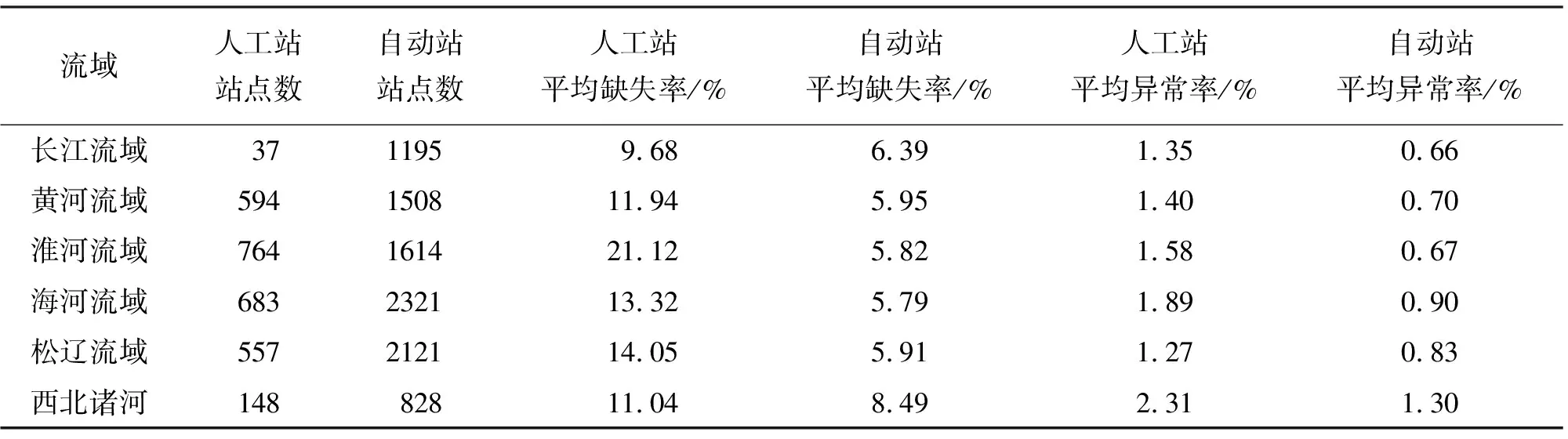
3.2 代表性评估结果
3.3 一致性评估结果
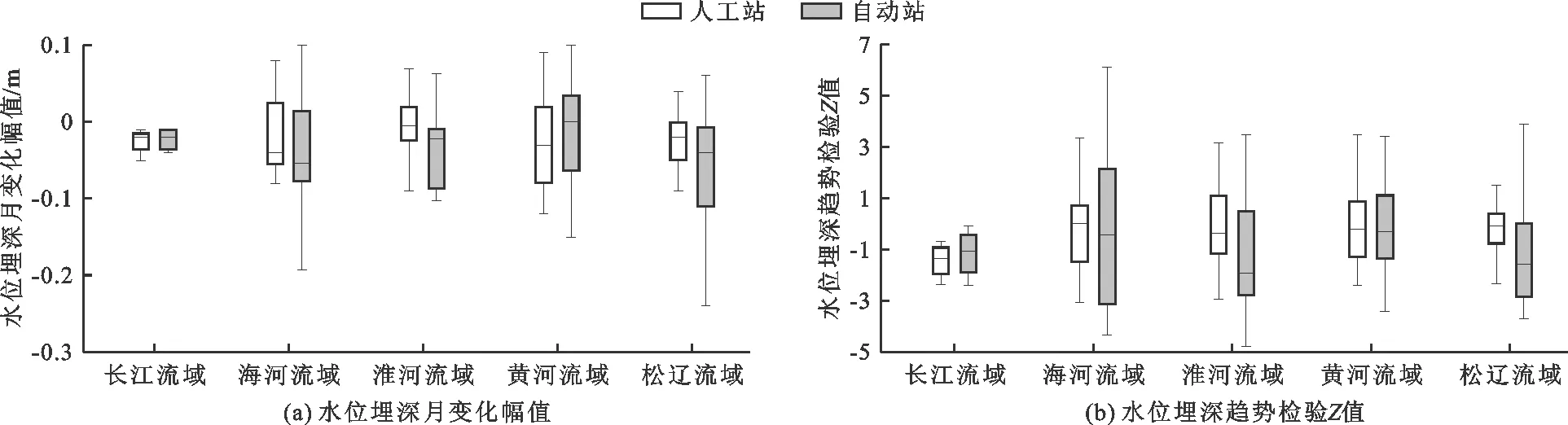
4 讨 论
5 结 论
