融合微博热点分析和LSTM模型的网络舆情预测方法
2021-08-24刘定一沈阳阳詹天明刘亚军
刘定一, 沈阳阳, 詹天明, 刘亚军, 应 毅
(1. 三江学院 计算机科学与工程学院, 江苏 南京 210012; 2. 南京审计大学 信息工程学院, 江苏 南京 211815; 3. 东南大学 计算机科学与工程学院, 江苏 南京 210096)
中国互联网络信息中心发布的第45次《中国互联网络发展状况统计报告》[1]显示,至2020年3月,我国网民规模为9.04亿,互联网普及率达64.5%.习近平总书记在网络安全和信息化工作座谈会上指出[2]:网民来自老百姓,老百姓上了网,民意也就上了网.网络起着引导舆论和反映社情民意的作用,有效的舆情预测方法对预估网络舆情发展趋势,化解潜在的舆情危机,营造良好的网络生态环境,具有必要的现实意义.众多学者对网络舆情预测进行了大量研究,提出了很多预测方法,如指数平滑法[3]、Logistic回归分析[3-4]、微分方程[5-6]等,这些方法皆是利用舆情传播信息时间序列特征构建基于传统统计学的预测模型,该类模型简单易实现,但只适合线性关系预测.近年来,由于人工神经网络具有很强的非线性拟合能力,更多地应用于解决与时间序列相关的问题.文献[7]根据舆情的混沌特性,提出EMPSO_RBF神经网络方法对网络舆情进行预测;文献[8]基于粒子群算法收敛速度快的特性,构建粒子群优化BP神经网络模型完成舆情预测.但是随着国内网民规模的稳步增长和自媒体、移动社交平台等新兴表现形式的兴起,导致单一的神经网络模型不能达到较为精确的预测目标.在经济领域,使用网络信息进行预测模型的修正是近期研究的热点.文献[9]引入新闻报道等定性信息,建立基于循环神经网络的个股走势预测模型,提升股票涨跌预测准确率.文献[10]建立支持向量机模型检验微博情绪对股市的预测影响,结果表明加入微博情绪信息的预测模型能够更好地预测股票市场价格走势的变化.文献[11]利用旅游攻略在新浪微博中的微指数,根据灰色预测模型对旅游供给侧问题进行实证分析.以上研究初步表明实时的互联网数据能够用于经济活动预测,成为提高预测精度的积极补充.与经济数据类似,网络舆情的走势受外界因素影响更大,越来越呈现出明显的模糊性和不确定性.针对此缺陷,文中结合网络热点分析技术和深度学习模型,提出MH-LSTM网络舆情预测方法,在传统LSTM神经网络的基础上,增加微博数据作为预测模型的补充,提高模型的预测准确度,并将其运用在舆情事件百度指数的定量预测研究中.以PSO-BPNN模型、LSTM模型与文中预测模型进行试验对比,结果表明融合微博热点分析和LSTM的网络舆情预测模型比其他方法有着更高的预测精度.
1 相关技术
1.1 LSTM神经网络
循环神经网络(recurrent neural network,RNN)的一个特点是在训练和预测时加入了时间的概念,即本次的计算输出会受到前一次输出结果的影响,主要用途是处理和预测序列数据.由于在梯度下降过程中,每一层误差反传都会引入乘子,导致经过多步之后,乘子的连乘会出现梯度消失或梯度爆炸的情况.
长短期记忆神经网络(long-short term memory,LSTM)[12]是一种具有长记忆特征的RNN.与RNN单一tanh循环体结构不同,LSTM的结构包括一个输入层、一个循环体结构、一个输出层,通过“门”(gate)来控制丢弃或增加信息,从而实现遗忘或记忆的功能[13].“门”是一种使信息选择性通过的结构,由一个激活函数和一个点乘操作组成,能有效缓解RNN在训练时出现的梯度问题.1个LSTM存储单元有3个这样的门,分别是输入门(inputgate)、输出门(outputgate)、遗忘门(forgetgate),如图1所示.替代传统神经元的存储单元保证误差以常数的形式在网络中传递,在此基础上添加乘法门和非线性函数为模型引入非线性变换,使得信息有选择性地表达.
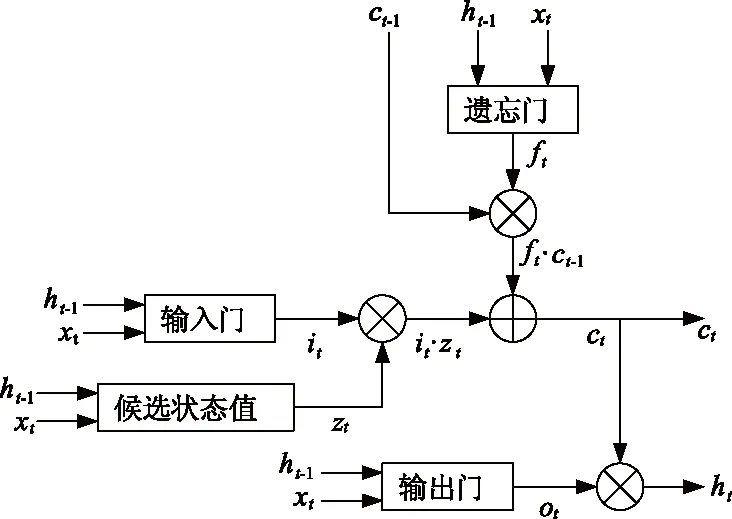
图1 LSTM单元结构
LSTM单元的计算公式如下:
it=σ(Wi[ht-1,xt]),
(1)
ft=σ(Wf[ht-1,xt]),
(2)
zt=tanh(Wz[ht-1,xt]),
(3)
ct=ft·ct-1+it·zt,
(4)
ot=σ(Wo[ht-1,xt]),
(5)
ht=ot·tanh (ct),
(6)
式中:it为输入门;ft为遗忘门;ot为输出门;σ表示激活函数,通常为Sigmoid;W为各神经网络层的权重矩阵;xt为当前时刻的输入值;ht-1为在当前时刻t接受上一时刻的输出值;ct-1为t-1时刻的状态值;zt为当前时刻的候选状态值;ct为当前时刻的状态值;ht为当前时刻的输出值.
1.2 PyTorch机器学习平台
与TensorFlow[14]类似,PyTorch[15]是由Facebook研发的一个轻量级分布式机器学习平台,是Python开源科学计算库NumPy的替代者.PyTorch中神经网络模型的符号表达式被抽象成计算图(computational graph),提供损失函数反向模式自动微分方法来反向求导传播参数.在机器学习中,同一个网络模型需要经过反复迭代才能达到最好的效果,在TensorFlow中,先定义一个计算图,每次迭代只是输入(feed)不同的数据,反复执行同一个计算图;与此不同,PyTorch每次迭代都重新构建一个计算图,故被称为“动态计算图”,这种方法加速了网络模型的收敛.文中设计的舆情预测模型借助于PyTorch平台实现.
1.3 网络热点分析技术
热点话题的发现是网络舆情预测的基础.在“互联网+”与Web2.0技术的推动下,微博(Microblog)已经成为中国社会的主流开放社交媒体,微博热点的发现是网络热点监控的重点[16].新浪微博正文一般不超过2 000个汉字,主题相对单一,是用户对自己关心或与自身利益相关的各种事务在情绪、意愿、态度等方面的网络表达.并由用户关系延伸出对微博正文的用户行为,包括对微博的转发、评论、回复、收藏等.微博热点发现即是对爬取到的微博正文的用户行为数据的计算和分析.基于微博正文定义微博内容的热度分值,由转发数、评论数、点赞数的占比总和得到,其基本公式如下:
(7)
式中:α、β、γ分别为转发数、评论数、点赞数的评分系数,且α+β+γ=1.
舆情信息属于典型的时序数据,在时间上具有继承性和延续性.百度指数直观反映了网民对热点关键字的搜索频次,微博热点与搜索行为之间存在必然的正相关性,即社交网络讨论越多,热度越大,搜索越多,百度指数数值越高.社交媒体造成当前舆情热点的发酵周期极短,绝大多数热点事件从曝光至舆情顶峰,大约只需1~3 d.虽然各舆情事件有各自的特点,但都呈现出大致相同的生命周期.图2根据“重庆保时捷女车主打人事件”、“996工作制事件”、“黑洞照片首发事件”3起网络热点事件(事件一、事件二、事件三)的百度指数信息(已进行量纲一化处理),绘制了舆情事件的发展过程,可以较为清晰地将网络舆情事件划分为爆发期、衰落期、淡化期3个阶段.这种演化性导致舆情数据的预测需要考虑位置较远的上下文信息,LSTM模型恰恰具有解决长期依赖问题的优势.
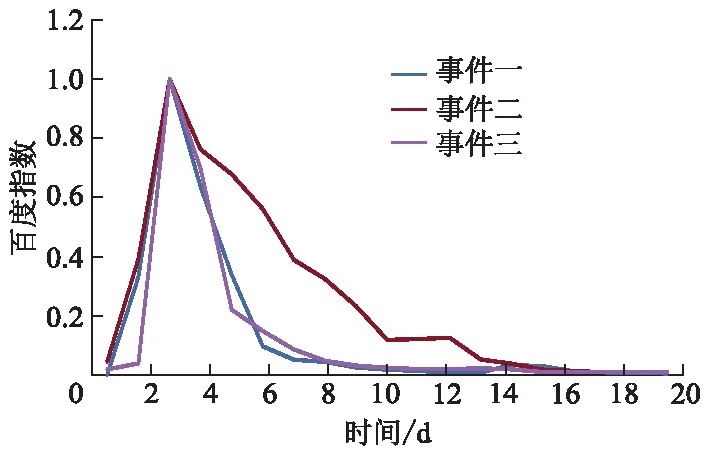
图2 网络舆情事件的生命周期
2 基于微博热点分析和LSTM的网络舆情预测方法
2.1 基于PyTorch的网络舆情预测系统架构
文中基于分布式爬虫技术[17]和PyTorch平台构建了用于舆情时序数据分析的网络舆情预测系统.系统由3部分组成:数据采集与存储、模型训练、模型部署与应用,如图3所示.
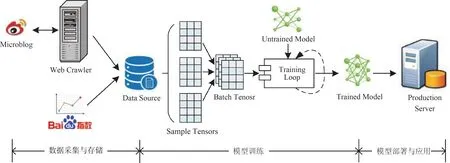
图3 网络舆情预测系统架构
在数据采集与存储部分,微博页面爬取使用Scrapy框架定制Spider进行,提取页面有价值数据后可按需要进行计算;百度指数等其他时序数据可在相关网站下载或手工采集.模型训练时,PyTorch的torch.util.data模块用于数据加载和处理;torch.nn模块提供常见的神经网络层和其他组件,包含全连接层、卷积层、激活函数、损失函数等,这些组件用于构建和初始化待训练模型;当模型根据训练数据得到输出结果后,torch.optim模块提供更新模型的标准方法,从而优化模型提高预测准确度.在多轮训练后,模型的参数趋于稳定,预测准确率达到目标标准后,即可进行模型部署与应用.系统整体基于Python3.6和PyTorch 1.1开发实现.
2.2 微博热度计算
在已知热点信息的前提下,定义微博热度分值由转发数、评论数、点赞数的权重累加得到,计算公式如下:
HotScorei=α×转发数+β×评论数+γ×点赞数.
(8)
转发数和点赞数可以反映网民对该话题的兴趣度,转发数越高代表网民对该话题越感兴趣,点赞数越高代表同意作者观点的人数越多,一定程度上反映了该话题的热点程度.参与评论的数量反映了网民对该话题的参与互动度,评论数越多代表参与的网民数量越多,该话题的互动性越好,越容易成为新的传播焦点.
研究[18]表明:舆情热点的形成也基本服从二八定律,即对于网络舆情传播造成重大影响的是头部20%的意见领袖;决定整个舆情事件传播规模的,是为数不多的人气媒体和权威网络平台.因此,根据关键词采集热点微博无须穷尽所有,对50个关键词匹配的微博进行热点分析,根据热度分值排序,取前10个累加,得到微博热度总分值,定义如下:
(9)
2.3 MH-LSTM模型结构
依托网络舆情预测系统,结合微博热点分析方法和LSTM网络,文中提出MH-LSTM(microblog hotspot-long short-term memory)神经网络模型.与股市、汇率、GDP、交通流等其他时序数据相比,舆情数据量不多(每年引起全民热议的舆情事件大约有30~50起,大多数舆情事件从产生到消亡持续约15~20 d).鉴于这一特点,设计MH-LSTM模型由单向LSTM和双向LSTM(bidirectional LSTM,Bi-LSTM)[19]两个隐含层组成,在保留LSTM网络特性的同时,降低由于训练样本较少而产生过拟合的风险.具体结构如图4所示.
根据舆情预测的特点,该模型第1个隐含层的输入包括4部分:百度指数BaiduIndex、微博热度总分值HotScore、时间偏移量Δt、上一时该隐含层的输出.时间偏移量指的是被预测日与舆情事件第1天之间的时间间隔,从舆情事件的生命周期模型可以看出与舆情爆发的时间差异也是影响舆情发展趋势的重要因素.
具体公式如下:
(10)
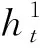
该模型第2个隐含层的输入包括2部分:同一时刻上一隐含层的输出和同一隐含层上一时间片的输出,具体公式如下:
(11)
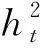
该模型的损失函数是预测误差平方和与模型权值参数的平方和之和,具体公式如下:
(12)
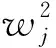
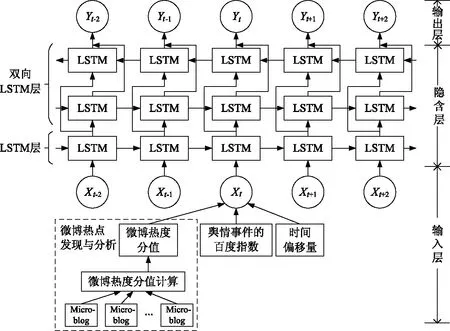
图4 MH-LSTM模型结构
MH-LSTM模型的训练步骤如下:
1) 定义MH-LSTM网络结构,根据公式(12)定义损失函数,设置每一层网络节点的舍弃率为0.2,设置优化器为自适应矩估计.
2) 根据公式(9)计算HotScore,BaiduIndex来源于百度网站.
3) 每一步处理时间序列中的一个时刻.将当前输入(BaiduIndext、HotScoret、Δt)和前一时刻输出(ht-1)传入MH-LSTM网络结构,计算得到当前输出(ht).
4) 根据当前输出和实际值计算误差,通过优化器反向传播求解,更新模型参数.
5) 重复上述步骤直至算法收敛.
该模型具有以下特点:
1) 能够表征时序数据.RNN是专门用来处理时序数据的,其每一个隐含层节点的输入既包含了输入层的输入,又有来自上一时刻隐含层的输出,这使它可以使用先前的信息来学习当前的任务.LSTM网络基于RNN进行改进,在保留上述优点的基础上,使得信息能够保持长时间的记忆.
2) 融合时效性强的微博数据.微博文本能够实时反映广大网民对于舆情事件的关注度,借此来作为趋势预测的补充.
3) 充分借鉴生命周期模型的规律.网络舆情事件的发展可大致分为爆发期、衰落期、淡化期3个阶段,以往发生的“历史数据”可作为新事件趋势预测的基础.
3 试验结果及讨论
3.1 样本数据的选取与处理
以2019年发生的“重庆保时捷女车主打人事件”(7月30日—8月14日)、“996工作制事件”(4月11日—4月26日)、“黑洞照片首发事件”(4月8日—4月23日)3起热点事件为训练样本,以“山东大学学伴事件”(2019年7月12日—7月27日)为测试样本,用训练样本训练模型优化参数,用测试样本验证模型的有效性和准确性.试验数据主要包括:百度指数、微博热度分值、时间偏移量.
在模型训练时,输入第1天的百度指数、微博热度分值和时间偏移量(即0),计算下一天的百度指数,比较计算结果和百度指数真实值,调整模型参数,如此反复.在模型测试时,只给出第1天的百度指数和每一天的微博热度分值,时间偏移量从0开始递增,测算第2天至第16天的百度指数.
3.2 试验结果分析
将文中提出的预测模型MH-LSTM与粒子群优化BP神经网络模型[8](PSO-BPNN)、传统LSTM神经网络模型进行对比分析.PSO-BPNN模型是较经典的舆情预测方法,它利用改进的粒子群算法优化BP神经网络的权值参数,选择热点话题的百度指数作为时间序列指标,经神经网络计算后得到舆情事件发展趋势的预测结果.在本试验中构建的传统LSTM网络结构包括LSTM和Bi-LSTM两个隐含层,该模型的神经网络部分与MH-LSTM一样,只是没有加入微博热点分值和时间偏移量.
利用MATLAB 2015a构造PSO-BPNN模型;依托网络舆情预测系统,构造LSTM模型、MH-LSTM模型进行对比试验,结果数据如表1所示,各模型预测结果对比如图5所示.由表1的试验数据可以看出,从拟合性和预测精度来看,相比于PSO-BPNN模型,LSTM模型和MH-LSTM模型的预测结果表现得更加优秀.由图5可以看出,LSTM模型和MH-LSTM模型的预测结果与真实值拟合得较好,预测结果更接近真实值;由于BP神经网络存在容错性差、学习不稳定等缺点,粒子群算法的自身局限性容易陷入局部最优,导致PSO-BPNN模型的预测结果稳定性较差,浮动较大,预测精度上也有所欠缺.
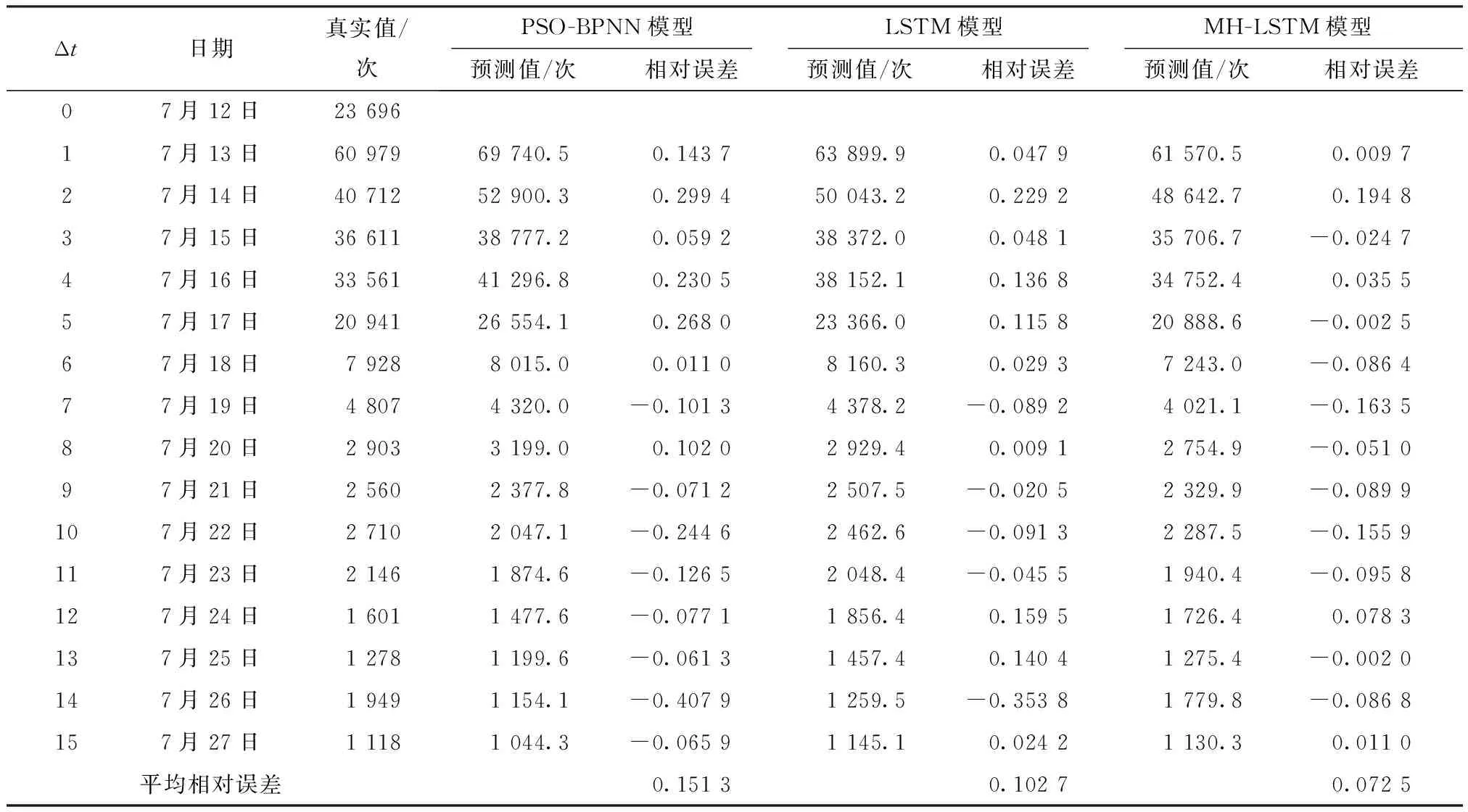
表1 各模型试验结果数据
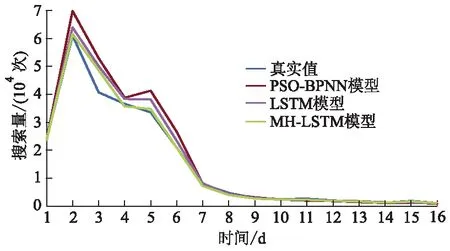
图5 各模型预测结果对比
为了进一步比较预测的准确性,通过式(13)和(14)计算预测值yi与实际值ri的相对误差(relative error,RE)和平均相对误差(mean relative error,MRE):
(13)
(14)
误差数据如表1所示.LSTM模型的MRE为0.102 7,MH-LSTM模型的MRE为0.072 5,都要优于PSO-BPNN模型的MRE(0.151 3).相比于LSTM模型,MH-LSTM模型加入了微博热度分值来修正模型,能够降低平均相对误差0.030 2,说明微博热点分析对舆情趋势预测有积极的影响.图6为3种预测模型的相对误差曲线图,从图中可以看出MH-LSTM模型的大部分相对误差都在10%以下,部分时间点的预测值误差接近0,预测结果整体较为稳定.因此文中提出的MH-LSTM模型能够更好地描述时间序列发展过程,具有较强的非线性拟合能力,能够很好地对舆情事件发展进行定量预测.

图6 各模型相对误差对比
4 结 论
基于网络爬虫技术和PyTorch机器学习平台构建了针对舆情时序数据分析的网络舆情预测系统.从预测模型和数据扩充两方面进行改进,提出融合微博热点分析和深度学习的新的预测方法MH-LSTM,该方法结合实时性的微博数据和权威性的百度指数进行网络舆情发展趋势预测,与PSO-BPNN模型、LSTM模型的对比试验验证了MH-LSTM模型的正确性和优越性.预测结果有助于政府对舆情信息的控制和引导,有利于社会发展的和谐稳定.
