基于卷积神经网络近红外光谱法测定水体污染物
2021-08-24张林
张林
(商洛学院,商洛市人工智能研究中心,陕西商洛 726000)
随着我国现代工业的快速发展,环境污染问题日趋受到公众关注。人们希望能够对水质进行实时监测,了解污水中有害物的种类及浓度[1]。由于水体中污染物种类繁多,污染物浓度的实时监测难度很大[2]。污水中的污染物主要分为有机污染物和无机污染物两类,无机污染物主要以自然产生的碳水化合物为主,有机污染物是以人类工、农业活动产生的残留物为代表,通常指农药等化工产品中的芳烃类和酚醛类等[3]。一般情况下无机污染物的危害不大,水体通过自净就可恢复;而有机污染物对水体危害较大而且持久,容易造成生态链失衡,如果人误食含有机污染物的水体中的鱼虾身体健康将会遭受危害[4–6]。水中的污染物扩散速度较快,目前提高污水中危害物的检测速度是防范水污染的重要措施之一,对人与自然的和谐发展具有重要意义。
传统的污水危害物检测方法均需借助化学试剂和先进的检测设备,如化学分析法、色谱法等,这些方法虽然能够较准确测定污水中的危害物含量,但其样品处理过程复杂,检测耗时长,且对检测人员的技术要求较高,因此难以大范围推广[7–9]。近红外光谱处理技术是利用C—H、O—H、N—H等有机基团对近红外光的合频与倍频对样品成分进行间接预测的方法[10–12]。近红外光谱检测技术是一种简单、便捷的检测方法,它具有高的灵敏度和稳定性,测定污水中的危害物便捷而高效。在对污水中有害有机物质进行检测时,传统的检测方法一般不能有效分辨有机物的种类及含量,而近红外光谱检测技术能够对有机物基团的吸收光谱进行增强[13],从而实现污水中有机污染物的辨别与准确定量。由于普通的近红外光谱增强技术存在热效应差的缺陷,笔者构建了一种近红外光谱增强方法并将其应用于污水中有害物质的检测,提高了检测精度与灵敏度。
1 算法描述
1.1 二维光谱信息矩阵
由于神经网络(Convolutional Neural Network,CNN)具有特殊的深度学习训练结构[14],需要对输入的光谱信息进行降维处理。通常采用重新构建二维光谱信息矩阵的方法对其进行降维,将每个样本的近红外光谱数据转换为二维光谱矩阵,具体处理过程如下:
设x表示其中一个样本的光谱数据向量,且以列向量的形式表示,则该样本的二维近红外光谱数据矩阵可以表示为:
S=xxT(1)
如果x代表的是一个三维光谱数据的一个列向量,则一个典型的二维光谱矩阵可以表示为:
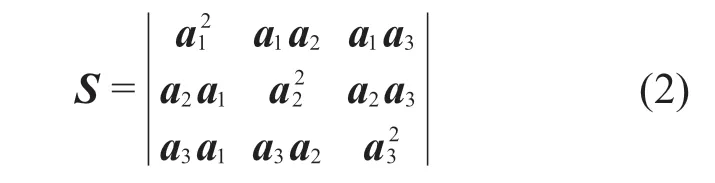
该矩阵被称为原始近红外光谱的信息矩阵,其中包含所有原始光谱的有效信息。此二维光谱信息矩阵即保持着与原始光谱间的相关性,同时又符合CNN模型对输入数据的格式要求,另外,将光谱信息降维成二维向量,更加有利于CNN网络对光谱特征的提取,实现更好的模型预测效果。
1.2 卷积神经网络
卷积神经网络是一种端到端的有监督的神经网络[15–16],其基本结构分为输入层、卷积层、非线性激活层、池化层和全连接层5层。其中卷积层是卷积神经网络的核心运算过程,向量经过卷积后会发生偏置,因此引入非线性激活函数对卷积后的向量进行修正,经过非线性激活函数修正后得到结果:

池化层主要作用是对卷积层输出的数据再次降维,以达到减小运算复杂度的目的。目前常用的是最大值池化和平均值池化两种方法,本实验采用最大值池化法对数据进行降维处理。
2 实验部分
2.1 数据来源
实验采集300个水样,将采集到的水样于试管中密封,于15 ℃条件下避光保存,3 h内完成光谱采集和理化分析数据的统计,其统计数据列于表1。检测样本的污染物含量较低且分布密集,对检测设备的精度有较高的要求。

表1 采集水样污染物统计数据
采用美国热电尼高力仪器公司生产的NEXUS型傅里叶变换红外光谱仪及其透色组件完成水体样本近红外光谱的采集。光源由波长为400~2 400 nm的石英卤素灯提供,光谱分辨率设定为16 cm–1,每个样本扫描32次。
2.2 光谱数据处理
利用热电尼高力仪器公司提供的OMNIC软件对采集的样本近红外光谱进行一阶平滑处理,消除噪音干扰,将经过处理的数据导出,利用统计分析软件MATLAB 2017对导出的数据进行聚类分析,结果表明光谱的前20个主成分累计贡献率超过99.1%,因此选用前20个主成分作为样本的有效数据进行建模,有效降低了CNN模型的运算复杂度。主成分分析光谱累计贡献率如图1所示。

图1 水样近红外光谱前20个主成分方差累计贡献率
2.3 预测模型的建立
采用卷积神经网络的方法建立水样中可持续污染物含量的检测模型,用MATLAB软件进行编程。采用实验样本对模型进行多次训练,对模型结构进行调整与改进。整个模型以BP神经网络为基础,设置卷积核函数对其进行初始化,将偏置设置为0,采用留一交叉验证的方法确定最佳参数。采用损失函数对欧氏距离进行定义:
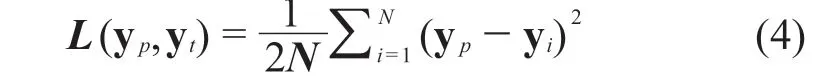
式中:yp——模型的预测值;
yi——样本的理化分析值。
试验过程中将模型的学习率设定为0.5,最大迭代次数设定为1 000次,模型随着迭代次数的增加而收敛,且损失函数平滑下降,说明模型的学习状态较好,没有出现过拟合现象。
2.4 模型的评价
引入相关系数r、均方根误差(RMSEC)、预测标准差(RMSEP)3个指标对预测模型进行评价。其中相关系数r值越接近于1,说明模型的拟合效果越好,RMSEC和RMSEP的值越低说明系统的稳定性越好。
3 结果与讨论
3.1 建模结果分析
同时建立标准的BP神经网络模型,与PLSR模型进行对比,其中BP神经网络模型设定为单隐层结构。将300个水样样本数据按照2∶1的比例划分为校正集和验证集,即200个样品用于对模型的训练,100个样品用于对模型的验证。对模型进行10次重复训练和测试,得模型平均值,其结果列于表2。由表2可知,近红外光谱分析方法对水体中的氰化物、总汞和多环芳烃的预测精度较高,采用卷积神经网络建立的模型总体效果优于BP、PLSR建模方法。

表2 不同模型水中污染物建模结果
分析结果表明,卷积神经网络技术能够用于建立近红外光谱水中持久性污染物含量检测模型,且模型比传统建模方法预测精度更高。采用卷积神经网络模型能够有效地简化光谱数据的维度,同时实现更好的预测效果。研究表明采用卷积神经网络模型独特的深度学习方法能够有效提取光谱数据的特征点,从而获取更加有效和细致的局部抽象映射。另外由于卷积神经网络模型的结构能够有效降低不相关数据对模型的影响,能够提高预测模型的鲁棒性和健壮性。由于需要对多层结构进行大量的训练,才能使卷积神经网络模型达到最优,接下来将对模型训练集样本所占数量对模型效果的影响进一步加以讨论研究。
3.2 训练集样本数量对模型预测效果的影响
为了探讨训练集样本数量的多少对卷积神经网络模型预测能力的影响,采用相同的划分方法将训练集样本按照所占总样本的10%~90%对模型进行训练,对氰化物的检测训练结果列于表3。

表3 不同训练集样本数量下模型的预测效果
采用验证集样本对模型的拟合精度进行评判,根据模型评价原则,对比实验数据发现,随着训练模型样本数量的增加,卷积神经网络预测模型的预测精度和稳定性逐步提高。当对模型的训练样本数量小于60时,模型得不到足够的训练,不能有效预测验证集样本中的数据。3种污染物的预测相关系数随训练集样本数量的变化情况如图2所示。

图2 预测系数随训练集样本数量占比变化情况
由图2可以发现,随着训练集样本数目的增加,卷积神经网络建立的水中污染物含量预测模型的性能稳步提高,说明利用卷积神经网络建立水中污染物含量模型,在大数据环境下能够稳定且有效地对水体中的各污染物含量进行动态检测和预测。
4 结语
将卷积神经网络技术与近红外光谱检测方法相结合,应用于水中持久性污染物含量的检测,设计了一种有效的卷积神经网络回归模型,并在低浓度污染物的检测中取得了较好的效果。首先采用不同的建模预测方法进行对比分析,采用卷积神经网络所建立的预测模型,其稳定性和线性预测精度均较理想,然后对比分析训练集样本个数对模型预测能力的影响,发现随着训练样本数量的增加,采用卷积神经网络技术建立的模型性能显著提高,说明在大数据环境下,卷积神经网络模型能够适应水中污染物动态检测的需求。
