基于深度学习的织物印花分割算法研究
2021-08-23汪坤史伟民李建强彭来湖
汪坤 史伟民 李建强 彭来湖

摘 要:针对织物图像特征提取和检测问题,研究了一种基于卷积神经网络U-net模型的织物印花分割算法,并根据织物印花的特点对原有模型进行改进,从而更精确地实现对织物印花图像的分割。实验选取100张原始织物印花图像,并利用人工标注的方法标注出分割好的图像,作为训练的标签,将训练图像和标签通过翻转、裁剪等数据增强算法得到1000张图像和对应标签进行训练。实验对比了本文算法和一些传统分割算法,结果表明,本文的分割算法能够更有效地分割出织物印花图案。
关键词:织物印花;图像分割;U-net;深度学习
中图分类号:TS101 文献标志码:A
文章编号:1009-265X(2021)03-0045-06
Abstract: Aiming at the problem of fabric image feature extraction and detection, this paper studies a fabric printing segmentation algorithm based on U-net model of convolutional neural network, and improves the original model according to the characteristics of fabric printing so as to more accurately segment the fabric printed image. In the experiment, 100 original fabric printing images were selected, and the segmented images were marked by manual labeling as the training labels. 1000 images and corresponding labels obtained by data enhancement algorithms such as flipping and clipping were trained. The experiment was conducted to compare this algorithm and some traditional segmentation algorithms. The results show that the segmentation algorithm could more effectively segment the fabric printed pattern.
Key words: fabric printing; image segmentation; U-net; deep learning
織物印花是织物生产过程中重要的环节,对于印花质量的检测必不可少。由于印花图案复杂多样,且大部分具有不规则性,印花花纹常为随机分布,检测其质量有着很大的难度,而织物背景则相对简单。因此,对于后续的织物质量检测(如疵点检测等),印花部分和背景部分的检测方法有时会有不同,有时只需考虑印花部分的检测。如果能够精确地将印花图案从整体织物图案中分割出来,对印花部分和背景部分分别检测,那么无论是对于检测效率还是检测准确率都有着很大的帮助。
近年来,在图像分割领域,有着很多不错的成果。传统图像分割算法有很多,主要包括以下几种。
基于阈值的分割,通过设置不同的灰度值阈值,将整体图像按不同灰度等级分割为不同的区域。Otsu[1]提出阈值分割领域经典的最大类间方差法。刘健庄等[2]在Otsu的基础上提出一种二维阈值分割法,同时考虑当前点的和其相邻区域像素点的灰度信息,从而达到更好的分割效果。
基于聚类的分割,将像素点按照一定规律分为几个不同的区域,并对每个像素点进行分类,判断每个点所属的区域,从而进行分类。K均值[3]聚类通过分析图像的颜色信息进行聚类。模糊C均值[4]算法引入模糊理论,使得算法能够更好的收敛。
基于区域生长[5]的分割,先在图像中找到若干个初始点,再将初始点邻域的像素点根据一定准则合并形成新的区域,不断合并区域,直到无法合并为止。
随着深度学习[6]的发展,各类图像检测问题都应用到深度学习,其中卷积神经网络(CNN)[7-8]仿造生物视知觉构造,对于解决图像处理问题有着很好的效果。本文采用卷积神经网络U-net[9]模型对织物印花进行分割,并根据织物印花图片的特点以及实验中遇到的问题对模型进行了一定的改进。经过实验,该分割算法效果很好。
1 改进U-net织物印花分割模型
1.1 改进U-net模型框架结构
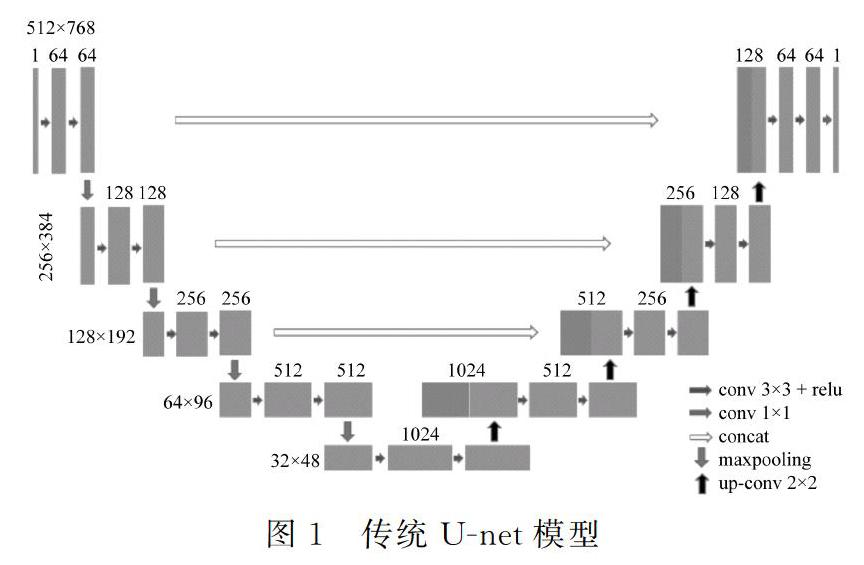
传统U-net模型常用于语意分割,其模型结构如图1所示,其结构形如字母“U”,因此该模型被命名为U-net。
如图1所示,模型左边为一个下采样过程,可以理解为一个编码的过程,将尺寸较大的原始图片通过多层的卷积核卷积并池化压缩到一个较小的尺寸,同时提取出图像的特征。再通过右侧上采样过程解码,通过反卷积将特征图放大,同时为了得到更多原始图像信息,将左侧的一些浅层特征连接到反卷积后的特征图上,最终将特征图恢复到原图尺寸,从而得到像素级的分割预测图。
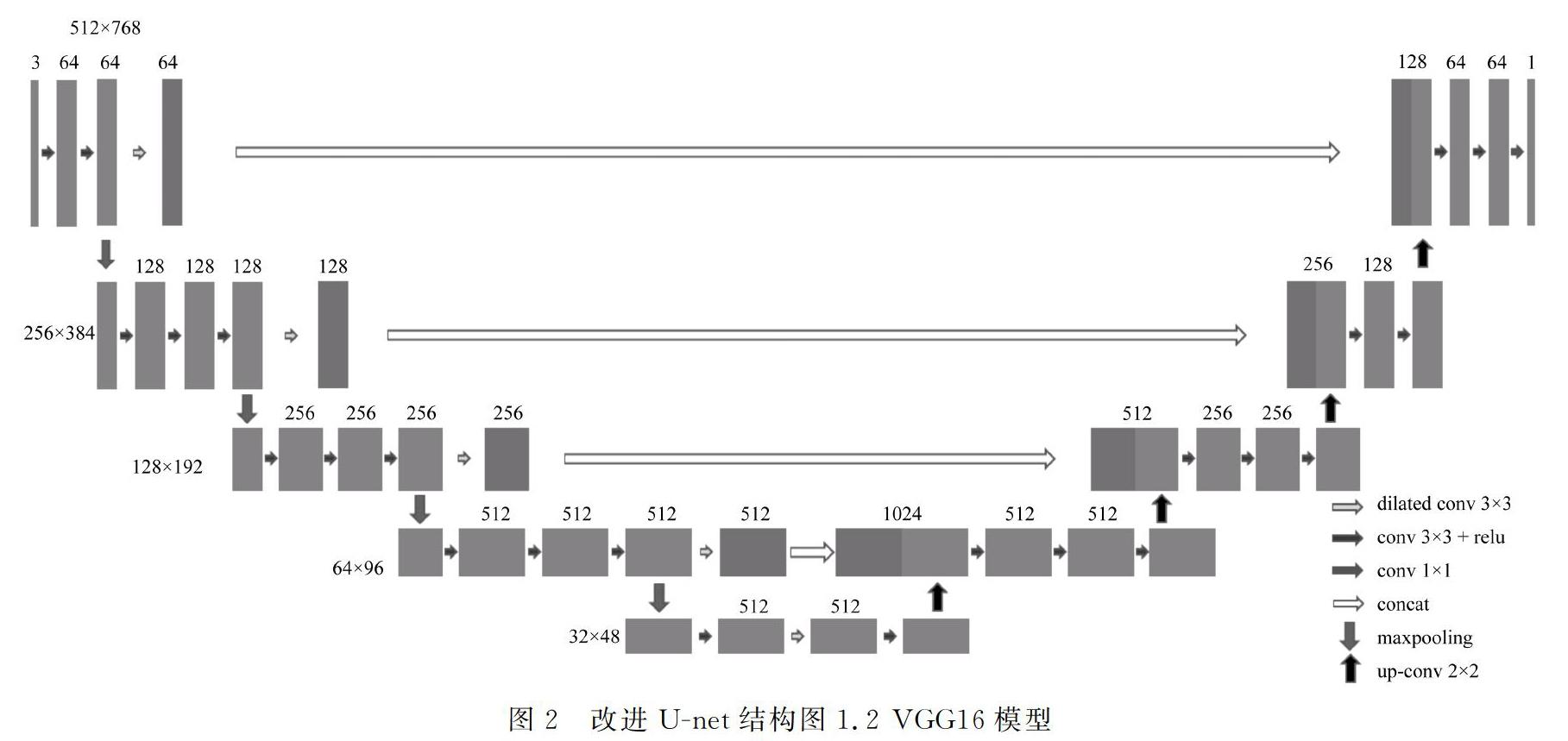
本文使用的织物印花图案由于花型复杂多样,且具有不规则性,印花大小也不相同,原始U-net模型结构较浅,无法精确提取到织物印花的特征,得到的分割效果不够理想,因此对U-net模型进行了一定的改进,利用更深的VGG16模型取代左侧下采样部分,并在模型中加入空洞卷积[10]以提高卷积核感受野。改进U-net模型整体结构如图2。
牛津大学在2014年提出了VGG16模型,该模型的突出特点是简单实用,该模型在图像分类和目标检测上都有很好的效果。
VGG16模型常被用来提取图像特征。图2中左侧蓝色下采样结构即为VGG16模型,原VGG16模型共13个卷积层和3个全连接层,本文算法舍弃了最后3个全连接层,只通过多层卷积从输入图片中提取出32×48×512的特征图作为右侧上采样的输入。
相比原U-net左側下采样部分,VGG16模型卷积层更多,结构更深,因此能提取到更多输入织物图片的细节特征。
1.3 空洞卷积
感受野是卷积神经网络中一个重要的参数,它表示经过卷积池化后的特征图中每个像素点映射到输入图片的区域的大小。很显然,感受野越大,特征图上每个点能蕴含越全局的特征。
空洞卷积相比普通卷积,在卷积核的每行每列之间加入空白的行和列,普通卷积和空洞卷积的卷积核如图3所示。普通3×3卷积核每个点都表示一个参数,3×3空洞卷积核只在奇数行和列有参数,双数行和列用零填充。可以看到空洞卷积相比普通卷积在参数量不变的情况下增大了感受野,同为9个参数的3×3卷积核,空洞卷积的感受野增大到了5×5,从而提高了卷积模型的学习能力,同时减小了参数过多可能导致的过拟合问题。
改进模型在U-net模型左侧增加了多个空洞卷积。
1.4 激活函数
卷积为线性过程,为了提高深层网络的表达能力,需要引入非线性[11]的激活函数。
U-net常用的激活函数为ReLU[12]函数,其表达式为式(1):
ReLU=max(0,x)(1)
ReLU函数具有计算速度和收敛速度快的优点,但由于在输入为负时,它的值为零,在某些情况下会导致一些神经元永远不会被激活,导致资源浪费。为了避免这个问题,模型采用PReLU[13]激活函数,其表达式如式(2):
PReLU=max(αx,x)(2)
其中α值很小,一般取0.01,PReLU与ReLU右半部分图像完全一致,不同点是左半部分不为零,而是一个很小的负值,理论上说,它具有ReLU的优点,且不存在神经元不会被激活的问题。
1.5 损失函数
分别使用L1损失和L2损失进行对比实验。设标签图片每个点的标签值为g(i,j),模型输出图片每个点的值为y(i,j),其中i,j分别为像素点的宽和高。w,h分别为图片的宽和高。
L1损失为:
lossL1=1w·h∑w,hi,jyi,j-gi,j(3)
L2损失为:
lossL2=1w·h∑w,hi,jyi,j-gi,j2(4)
1.6 准确率评估
为了更好的评估花型分割结果的好坏,引入准确率评估如式(5)、式(6)。
acc=1w·h∑w,hi,joi,j⊙g(i,j)(5)
oi,j=1yi,j>0.50yi,j<0.5(6)
g(i,j)为点(i,j)的标签值,属于前景时为1,属于背景时为0,o(i,j)为输出y(i,j)经过二值化得到的结果。
式(5)表示准确率为标签值和输出值相同的像素点占总像素点的比率。
2 实验与分析
2.1 数据集与数据增强
采用TILDA纺织纹理数据库,并通过手动标注的方法对织物印花进行分割,得到训练标签图,图4为两组训练图片和标签图。对原始数据集约100张图片进行标注,之后通过翻转、切割等数据增强方法将数据集扩充到1 000张,其中800张作为训练集进行训练,其余200张作为测试集测试模型预测结果。图5为数据增强中裁剪和翻转示意图。
2.2 模型训练
2.2.1 实验环境
实验使用Inter(R)Core (TM)i58400 2.8 GHz处理器,GPU为英伟达GTX1060 6 GB,内存为双通道16 GB;软件环境为WIN10 64位,python3.6,tensorflow1.10.0。
2.2.2 模型训练
在上述实验环境下对训练图片进行训练,总共进行约600轮迭代,初始学习率为0.001,并随着训练的进行,不断减小学习率。分别采用原U-net模型和改进U-net模型进行训练,同时比较不同损失函数对训练的影响,训练过程中利用tensorflow可视化工具tensorboard对训练可视化,监测训练过程。
训练过程中学习率变化如图6所示,随着迭代次数增加,学习率不断减小。
图7表示分别使用L1损失函数和L2损失函数时,改进模型的准确率对比。可以看到,随着迭代次数增加,准确率不断提升,到200轮迭代左右时准确率趋于稳定,另外,使用L1损失函数能得到更好的分割结果。
图8、图9表示原U-net和改进U-net在训练过程中损失以及准确率变化对比。从图中可以看到,由于原模型结构较浅,收敛速度相对较快,但稳定后最终结果无论是训练损失还是准确率,改进U-net模型相比原模型都有很大的优势。
2.3 结果和分析
对比了不同损失函数下的分割结果,同时对改进模型与原U-net模型的分割结果进行了比较。将测试集图片通过训练好的模型得到输出矩阵,将矩阵转换为灰度图像。
从测试集中选取几张图片展示分割结果,如图10、图11所示。
图10(c)、(d)表示在L1、L2损失下部分测试图片的输出结果。
从图9和表1可以看出,使用L1损失函数时得到的分割结果与标签值基本相同,准确率达98.33%,而使用L2损失函数时分割结果与标签结果有一定差距,准确率为93.55%。
从图11和表2可以看到,由于原U-net模型网络结构较浅,无法完整提取织物印花信息,分割效果很不理想,分割准确率为88.67%。
3 结 论
采用改进U-net模型对织物印花进行分割,通过对U-net模型的改进以及训练参数的调节,总体来说能得到比较好的分割结果。另外,如果有合适且足够多的训练样本,分割方法不仅對织物印花分割,在其他图像的分割上都能有很好的效果。
当然,算法仍然有很多可以改进的地方,主要有以下几点。
a)数据集较小,由于采用人工标定,人力有限,数据集图片数量相对较少,容易产生过拟合,对不同种类织物图片泛化能力较差。
b)分割只是对将印花从背景中分离出来,没有对不同印花进行区分,接下来主要考虑研究多种类的分割。
参考文献:
[1]OTSU N. A Threshold Selection Method from Gray Level Histogram[J].IEEE Trans on System Man and Cybernetics,1979,9(1):62-66.
[2]刘健庄,栗文青.灰度图像的二维Otsu自动阈值分割[J].自动化学报,1993,19(1):101-105.
[3]李鹏飞,张宏伟.基于k-means聚类的纺织品印花图像区域分割[J].西安工程大学学报,2008,22(5):551-554
[4]SARKAR J P, SAHA I, MAULIK U. Rough possibilistic type-2 fuzzy c-means clustering for MR brain image segmentation[J].Applied Soft Computing,2016(46):527-536.
[5]FAN JIANPING, ZENG GUIHUA, Body M, et al. Seeded region growing: an extensive and comparative study[J].Pattern Recognition Letters,2017,26(8):1139-1156.
[6]LECUN Y, BENGIO Y, HINTON G. Deep learning[J].Nature,2015,521(7553):436-444.
[7]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale lmage recognition[J].Computer Science,2014,9(4):23-31.
[8]卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):1-17.
[9]RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]//International conference on medical image computing and computer-assisted intervention. Springer, Cham,2015:234-241.
[10]YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[J].arXiv preprint arXiv:1511.07122,2015.
[11]李明威.图像分类中的卷积神经网络方法研究[D].南京:南京邮电大学,2016.
[12]GLOROT X, BORDES A, BENGIO Y. Deep sparse rectifier neural networks[C]//Proceedings of the fourteenth international conference on artificial intelligence and statistics.2011:315-323.
[13]HE K, ZHAN X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on image net classification[C].IEEE. International Conference on Computer Vision,2015:1026-1034.
