基于卷积神经网络的图像精度深度优化
2021-08-23蒋平
蒋 平
(安徽开放大学 开放教育学院,合肥 230022)
在日常生活中,人类通过视觉系统得到大部分信息,这些信息属于图像信息,所以图像是人类感知世界的重要载体。随着移动互联网的不断普及,网络上的图像信息呈指数型上涨,形式也变得更加多种多样。越来越多的图像信息被以数字化的方式存储到互联网中,图像来源不断广大,图像种类日益增多。在计算机视觉应用领域,图像精度优化在图像处理中占有重要位置,图像精度优化效果好,会对目标识别、图像识别以及场景解析等工作起到非常重要的帮助。为挖掘出图像中有价值的信息,需要对图像精度深度优化,以便进一步加工处理。目前,已有较多关于优化图像精度的方法,但因为其复杂性,有很多问题需要解决,并没有一个通用的评价标准。传统的图像精度深度优化方法优化效果较差,优化后的图像精度难以满足实际应用需求,因此对图像精度深度优化方法更进一步的研究具有重要的实际意义,为此设计一种基于卷积神经网络的图像精度深度优化方法。经过实验证明,此次设计的基于卷积神经网络的图像精度深度优化方法比传统优化方法优化后的图像精度高,满足了图像精度优化方法的设计目的,解决了传统方法优化精度差的问题。
1 图像精度深度优化方法设计
为了解决传统的图像精度深度优化方法优化后的图像精度仍然较差的缺陷,设计一种基于卷积神经网络的图像精度深度优化方法。该方法的整体设计流程如图1所示。
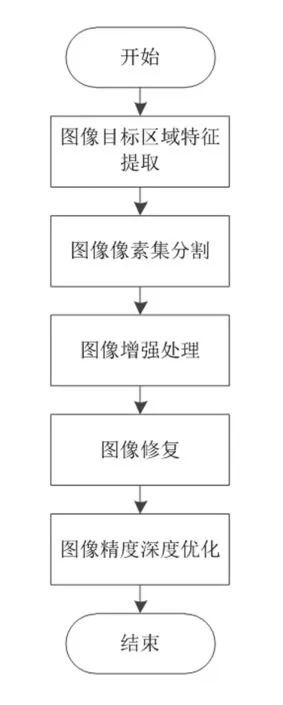
图1 整体设计流程
1.1 图像目标区域特征提取
采用目标监测方法提取图像目标区域特征,目的是对图像中的最优目标定位,映射出目标区域的图像特征,用其表示图像信息。利用深度学习框架生成多个特征图以对图像的原始特征进行提取,其原理如图2所示:

图2 图像特征提取原理
图像特征提取如图2所示,图像提取过程中会生成多个特征图[1],以为目标分类和位置回归做准备。在上述过程中会生成多个边框,为了达到更好的效果,对损失函数进行改进,目的是为了更准确地识别出图像目标属性。在该过程中涉及到3个相关的代价函数[2]:目标区域中物体分类的代价函数、边界框位置的代价函数、目标属性分类代价函数。
其中目标区域中物体分类的代表函数表示为:
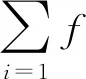
为遵循多任务损失定义,计算图像边界框位置的代价函数,表达式为:
式中,l(r)代表图像目标区域,Nw代表非目标区域,e代表图像变量,te、t分别代表图像的参数化坐标。
目标属性分类代表函数表示为:
式中,M代表图像预测损失值,Ft为图像目标属性[4],w为图像目标图像属性分类参数,d代表图像数据集。
将上述训练好的图像目标区域特征标注[5]于图像数据中,为图像精度优化提供基础。
1.2 图像像素集分割
上述过程提取了图像的目标区域特征,在此基础上,对图像像素集分割[6],通过图像相邻像素颜色、亮度、纹理等特征,将像素点聚类为一个个小的图像块,将图像细分[7]为多个目标区域。分类的图像像素点具有较大的相似性,所以将其当作一类点进行处理,以简化计算时间。首先转化图像颜色空间[8],转化公式为:

然后设定种子点[9],利用图像的三维色彩颜色以及图像的二维空间位置信息,计算像素点距离[10],表达式为:


最后,对图像进行分割处理,设置为每个超像素的中点,减少图像极端位置[11]带来的干扰,计算公式为:

根据上述计算,对图像三维颜色以及二维空间的处理,完成图像像素分割,为图像精度深度优化提供基础依据。
1.3 图像增强处理
在上述图像目标区域特征提取与图像像素集分割的基础上,对图像增强处理。根据上述处理可知,处理后的图像存在细节信息丢失[12]的现象,为了解决图像全局结构信息不足的问题,根据卷积神经网络并行架构,通过交替无监督和有监督学习训练网络,将该架构应用至图像超分辨率重构与修复中去,能够提升图像精度优化效果。对图像信息修复前,光滑图像,其过程如图3所示:
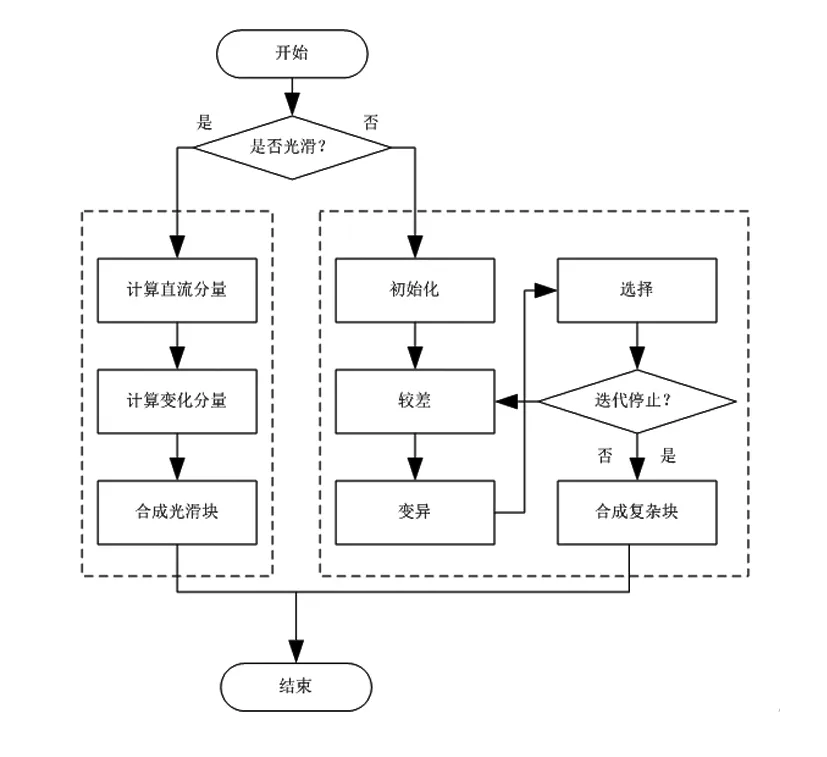
图3 图像光滑区域处理过程
固定当前的修复图像,求解公式如下:

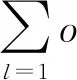
由于图像中存在两种形式,全尺寸图像与图像块,利用全尺寸图像描述图像特性较难,因此将全尺寸图像与图像块看作两个独立的变量[13],并引入辅助变量,进行求解,计算公式为:
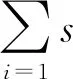
将图像中的图像块看作一种原子组合,用二进制码进行编码,定义如下:
p=[p1,p2,…,pn]
(9)
其中,p代表图像的基因位。
利用适应度函数评估图像个体优劣程度,在图像块中,重构信号与原始信号相差越小,表明图像块个体越优秀。然而在实际的图像重构过程中,得不到图像的原始信号,只能获得观测向量,因此用观测误差的倒数定义适应度函数:
式中,f(t)代表图像块基于整体图像的适应度,y代表图像原始信号,A△为图像观测误差,u代表图像的有效空间。
为此,采用交叉和变异算子增加图像的原子个数,寻找图像相对位置的基因片段,已达到图像信息交互的目的,图像基因活性的数学公式表示为:
式中,C代表图像的基因活性参数,V代表图像交叉规则,mh图像的基因位的活性值,△(p)为图像特征的平均稀疏度。
在此基础上,搭建深度学习框架,该框架描述如下所示:
式中,F‖X‖代表图像细节信息,s为图像中的权重系数,x为图像中的像素块。
卷积神经网络并行架构,主要是指将训练数据划分到不同窗口下,每个窗口都存在完成网络模型,使用不同数据进行训练。如图4所示。
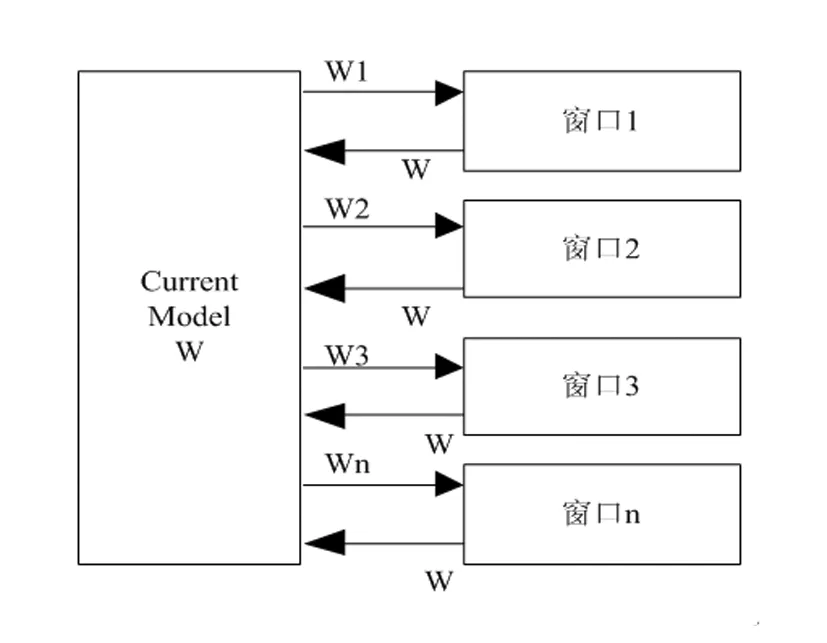
图4 卷积神经网络并行架构
通过交替无监督和有监督学习训练网络,利用第一层神经网络描述图像中的低频参数[14],利用第二层神经网络修复图像与真实观测值的残差值,运用第三层神经网络确保数据的保真度。
图像细节信息恢复表达式为:
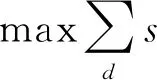
根据上述计算,对图像细节信息修复,以对图像增强处理,完成图像精度深度优化。
2 实验
对上述设计的基于卷积神经网络的图像精度深度优化方法进行具体的实验验证,并将其与传统的基于均值滤波的图像精度深度优化方法对比,对比两种图像精度深度优化方法优化后的图像精度。
2.1 实验软硬件环境配置
在实验软件环境方面,使用Ubuntu14.04 64位操作系统,采用C++编辑语言,具体的软件配置见表1。

表1 实验软件配置
在硬件方面,使用了服务器级主板,并配备了处理器与显卡,具体的硬件配置见表2。

表2 实验硬件配置
实验采用Camvid数据集内的图像数据作为实验对象,将数据分为评估集与测试集各200张图像。评估集采用传统方法设计的优化方法进行图像优化,测试集采用此次设计的图像精度深度优化方法进行图像优化。
为保证实验结果准确性,将实验图像在VGG模型的基础上进行预训练,并进行10万次迭代。为减少实验时间,将实验图像每40张做一次优化,每种方法各进行5次实验。并对图像进行训练,为了提高效率,将所有图像划分为178×178大小的图像,并对每张图像进行下采样处理。
2.2 结果与分析
传统方法与此次设计的优化方法的优化精度对比结果可知,传统图像优化方法在图像优化时,优化的图像精度与图像特征提取精度均较差,与实际的图像视觉效果相差较大(见图5,图6)。此外,传统图像精度优化方法在优化过程中,产生的计算量较大,难以获得较好的图像精度优化效果。而此次设计的方法在图像精度深度优化上,优化精度较高,说明此次设计的优化方法能够快速、准确地对图像细节信息进行修复,从而保证优化后的图像精度较高,满足图像深度优化需求。

图5 精度深度优化对比结果
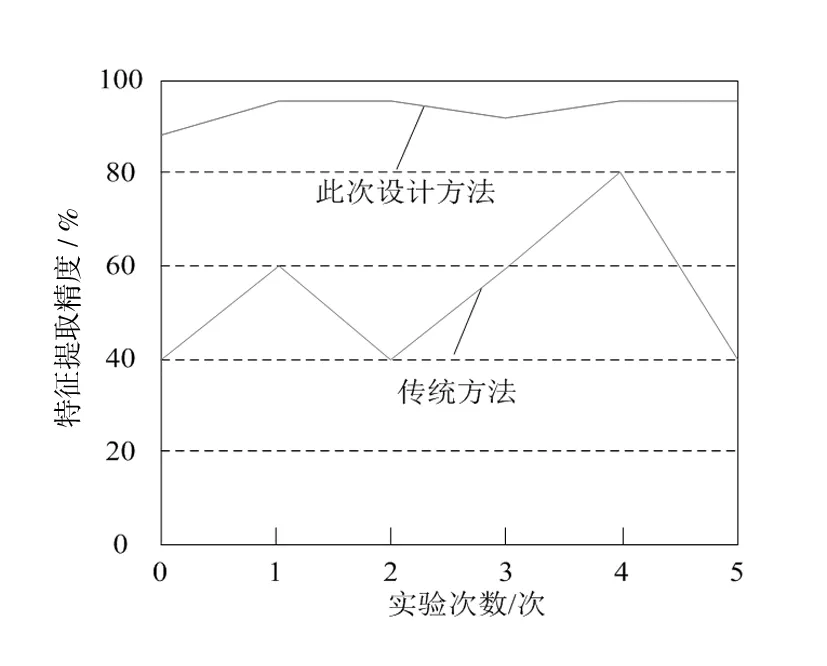
图6 图像特征提取精度
在上述基础上,采用这两种方法进行图像分割与图像增强时间比较。
由表3和表4可知,此次设计方法的图像分割与图像增强时间均低于传统方法,说明该方法的图像分割与图像增强的效率高,实际应用效果好。
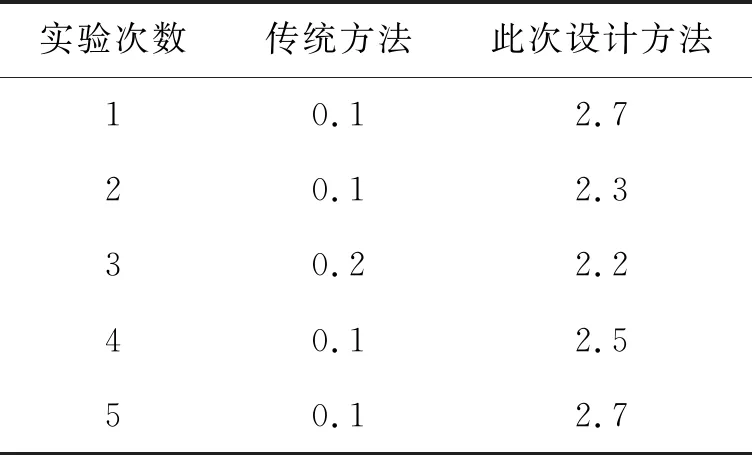
表3 图像分割时间比较 s

表4 图像增强时间比较 s
综上所述,此次设计的基于卷积神经网络的图像精度深度优化方法比传统方法优化效果好,比传统方法优化后的图像精度高,能够解决传统优化方法优化后的图像精度差的问题,更具有效性和实用性。
3 结语
本研究设计了一种基于卷积神经网络的图像精度深度优化方法,经实验证明,该方法优化后的图像比传统方法精度高,但是仍然存在较多的不足之处,在下一步的研究中,网络中涉及到的参数较多,训练时间开销较大,图像精度优化时间等问题需要做进一步的提高。从实验数据方面看,本研究使用的数据集样本相对较小,在下一步的研究中可以使用自然图像集,深度研究此次设计的方法在实际环境中的优化能力。
