基于任务特征的一种小样本学习方法
2021-08-20龚泽凯范兆伦崔海波
龚泽凯,范兆伦,崔海波
(湖北大学计算机与信息工程学院, 湖北 武汉 430062)
0 引言
随着机器学习的发展,出现了各种各样的深度学习网络,比如卷积神经网络,生成对抗网络和长短期记忆网络等.这些优秀的神经网络模型在图像方面取得了非常良好的效果,然而这些网络都得益于大量带标签的训练数据.数据成本也是现在应该关注的问题,对所有数据都进行标注是不经济的.例如,稀有生物的图片和新型产业数据样本非常少,所以让机器自己学会学习是非常重要的一步.对于一个年纪不大的孩子,让他去识别不认识的动物,只需给他少量的样本,比如几张熊猫和猫的图片,他就能非常准确地识别熊猫和猫.所以人工智能关键的一步就是如何像人一样学会如何去识别未知的类别.元学习就是基于机器如何在类人学习的基础上提出来的,即从少量带有标签的数据中学习如何去区分类别.小样本学习是元学习在监督学习领域的应用,实际上,很多元学习的问题都是小样本学习的问题.
小样本学习具有类人学习能力,减少了数据收集、成本开支、学习的样本数量有限等特点[1].由于小样本学习的任务样本非常少,传统的监督学习非常容易过拟合.文献[2]中提出了一种孪生神经网络,通过将图片进行向量化处理得到特征函数,然后通过比较余弦相似度来进行判断两个图片是否为同一类别,这种神经网络更适合于小样本学习的领域.但是小样本学习上可能有上百个学习任务,为了追求模型网络更好的泛用性和快速适应的效果,Vinyals等在建模上引入了注意力和记忆网络提出了匹配网络,并且在数据上要求测试集和训练集都相同的数据分布,以此来达到更好的效果.Finn等[3]提出了一种快速适应的深度神经网络MAML,只需要更新模型初始化参数就可以在多个任务上表现出非常好的表现.本研究在此基础上,提出了使用任务特征嵌入的方式来达到追求更好的实验效果[4].
1 研究背景介绍
目前小样本学习网络主要分为基于循环神经网络的模型、基于度量方法的网络和基于最优化的参数网络等3种网络.
1.1 基于循环神经网络的方法早期用于小样本学习的方法是基于卷积神经网络模型的,比如RNN和LSTM.文献[6]中提出的MANN,通过筛选权值的大小来记录信息进行记忆更新,但是经过任务类别过多的时候,LSTM处理就显得些许吃力,随后文献[7]中提出了SNAIL模型,SNAIL提出加入注意力的机制来提高网络能力.
1.2 基于度量方法的网络如果在小样本学习的任务中用普通的神经网络分类,其结果就会导致过拟合,因为神经网络分类器中需要优化的参数太多,而非参数的方法是不需要优化参数的.通过对样本数据间的距离建立模型,文献[8]的匹配网络提出训练和测试在同一个条件下进行,在训练的时候不断地让网络看观察一个类别的少量样本.文献[9]中提出原型网络将每个类别中的样本数据映射到一个空间中,并且提取他们的“均值”来表示为该类的原型.使用欧几里得距离作为距离度量,对数据类别距离判断归类.
1.3 基于最优化的参数网络基于最优化的参数网络方法通过之前大量的相似任务的学习,网络模型学习到一个表现最好的参数作为初始值,然后再用于其他任务的训练,通常不需要或者微调几次就可以在新任务上收敛,其中具有代表性的就是文献[3]中的MAML.
2 算法设计
2.1 任务嵌入在目前的一些小样本学习中,通常将图像映射到嵌入空间,然后利用特征嵌入进行后续的操作,存在通用的特征嵌入不适用于某些任务的问题,会影响预测的结果.而基于元学习的参数生成器将通用的图片特征嵌入转化为动态的任务感知功能嵌入,如图1所示.

图1 动态的任务感知功能嵌入
在同一个图像边界上,不同的任务分类处理不同.它采用一个简单的二值分类器来学习一个独立于任务的线性边界,从而分开正负样本,并且泛化到任务中[10].
2.2 基于任务特征的小样本学习模型在网络中有两个子模块组成,如图2所示.任务感知元学习器G采用任务描述t∈T生成预测网络中里特征层的权重.对于一个输入图像x,预测网络根据F(x;θt)=y来预测二值标签y,表示输入图像和任务描述t的相似度,其中参数θt由权值生成器生成.虽然t作为任务描述并没有直接作用于预测网络的输入,但是影响了网络层的参数从而将任务信息注入到任务感知功能嵌入中.
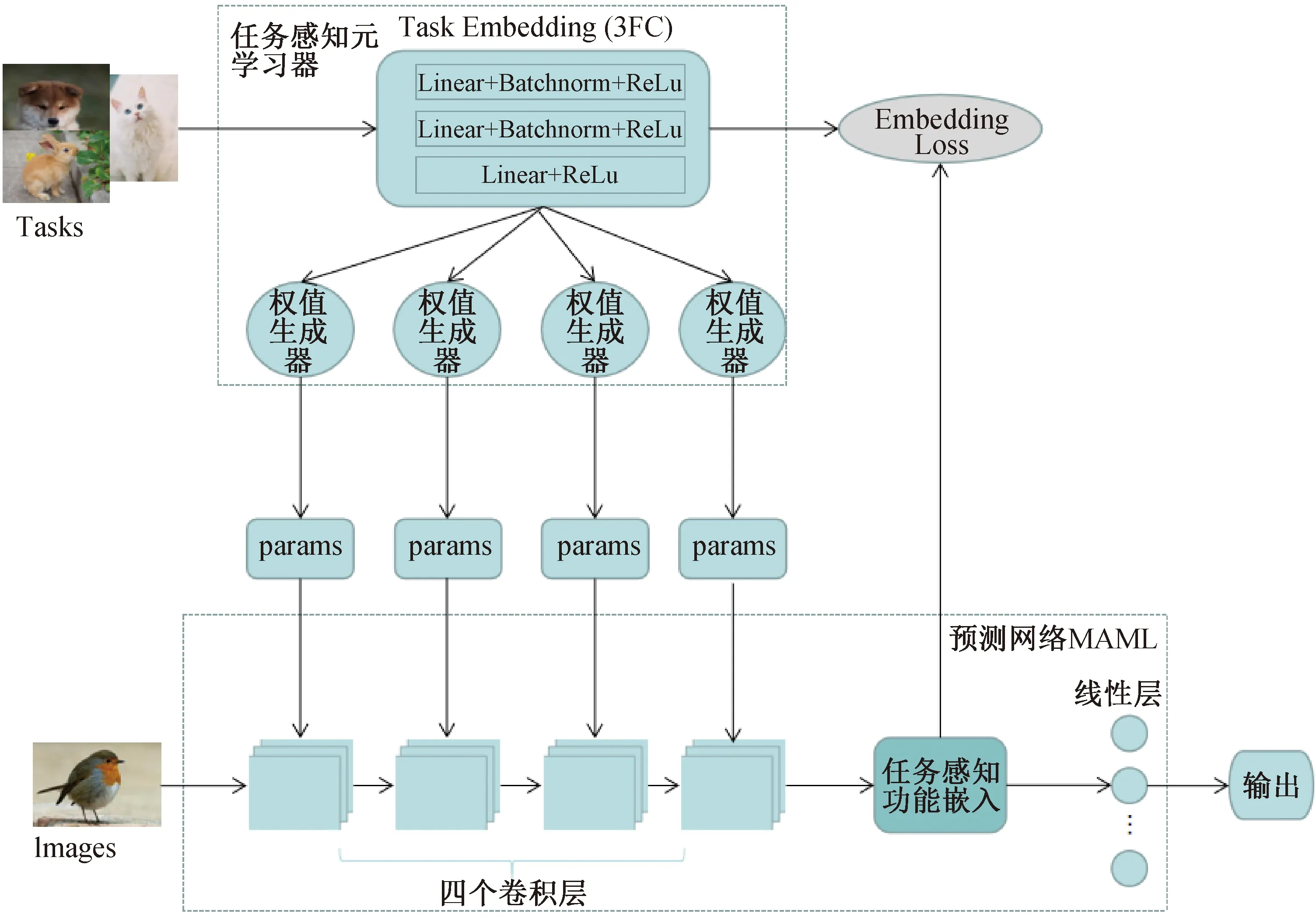
图2 基于任务特征的小样本学习模型
在预测网络中,用f代表学习模型,样本x通过f得到输出a.在训练阶段,模型被训练后能够快速适应任务.任务学习过程为T={L(x1,a1,x2,a2,…,xH,aH),q(x1),q(xt+1|xt,at),H},L是损失函数,q(x1)是初始x服从的分布,q(xt+1|xt,at)是x过渡时期服从的分布,模型在t时刻选择一个at输出一个长度为H(在监督学习中H=1)的样本.在模型学习的时候,首先需要一个模型去适应的任务分布p(T).在小样本学习问题中,从任务分布中抽样一个任务Ti,从qi中抽取N个样本用于训练,得到任务Ti的损失L(Ti),然后再抽取新样本进行测试.模型关注测试中误差值的变化情况,并以此为依据来提高模型性能.实际上,在所有的抽样任务Ti上的测试误差构成了学习训练阶段的训练误差,在最后阶段,从p(T)中抽样一些新的任务,每个任务含有N个样本,通过这N个样本的学习后,模型的性能作为训练阶段的模型能力评估.
考虑一个用参数θ表示的模型f(θ),当在一个新任务Ti上学习时,参数θ是在任务Ti经过一次或多次梯度下降更新得到的θ′i.在该方法中,模型梯度更新表示为:
(1)
其中,φ是模型初始化参数,β是用于更新初始化参数的超参数学习率.
2.3 任务权重分解在任务感知元学习器中,输入一个任务后在任务嵌入中类似word2vec的方式将任务转化为向量.在其中有3层FC网络(2*(Linear+BatchNorm+ReLu)+(Linear+ReLu)).在权值生成器(generator)中有一个权重分解方案来简化生成器的设计,如图3所示.Wi∈Rk×k×Cin×Cout(k是卷积核大小,Cin和Cout分别是输入和输出通道数)是第i个生成器生成的权重,Xi是图片特征处理生成的image features,那么输出Xi+1为:
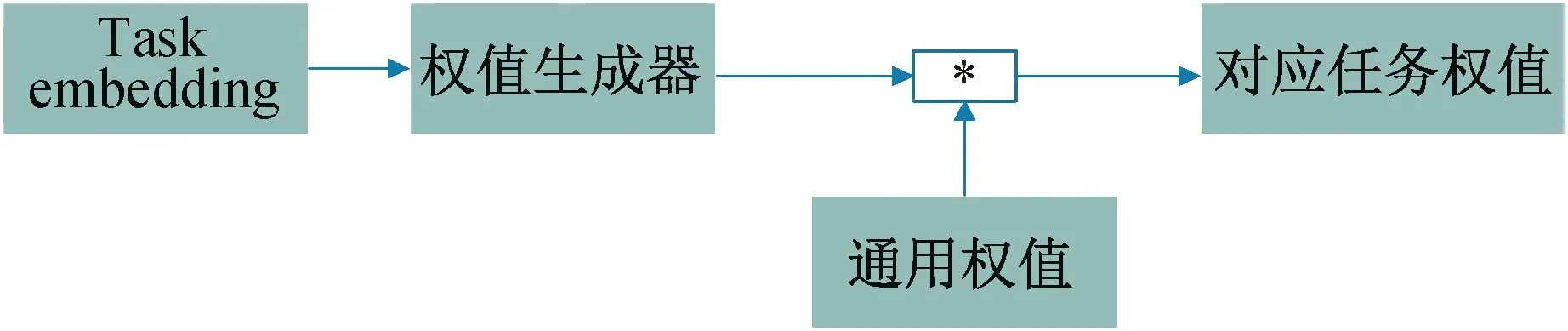
图3 任务权值生成
xi+1=Wi*xi
(2)
其中Wi是第i个生成器的输出,它可以被分解为:
(3)
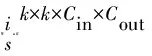
2.4 损失函数由于在元学习器上用于训练任务的数量远小于训练网络的图像数量,所以元学习器中设有一个嵌入损失防止退化,对于一个任务嵌入et=T(t)和任务感知功能嵌入TF(x;θt)投影到一个联合嵌入空间中,如果样本是正样本,那么对应的任务感知功能嵌入就和et接近,如果样本是负样本,那么对应任务感知功能嵌入和et就远离.使用hinged cosine similarity作为距离的度量,那么损失公式L1为:
(4)
其中,xi是第i个样本,yi∈{0,1}是标签的one-hot编码,T是任务数量.
在预测网络的分类过程中,预测出来的标签和真实值之间的误差采用多分类交叉熵形式,那么其损失公式L2为:
(5)
故,总损失函数公式L为:
L=L1+L2
(6)
3 实验过程及结果
3.1 数据集介绍本次实验使用的数据集是Omniglot和MiniImagenet.
Omniglot是小样本学习中常用的数据集,包含来自50个不同字母表的1 623类不同的手写字符.1 623类字符中的每一个都是由20个不同的人通过亚马逊的Turk平台在线绘制的.
MiniImagenet从ImageNet数据集中随机采样的100个类别组成,其中每个类别具有600张尺寸为84×84的图像.
3.2 实验过程在实验中,使用SGD(momentum=0.9)作为优化方法,初始学习率设置为0.001,每经过4 000次迭代学习率减半,预测网络中卷积网络大小设置均为3×3×32,每层用Batchnorm来增强收敛速度和稳定性,激活函数为ReLu,作为对比实验组的模型均与参考文献保持一致.在Omniglot数据集中,采用1 200类用于训练,423类用于测试,所有图像均设置为28×28.MiniImagenet数据集分为3个部分,64类用于训练,16类用于验证,20类用于测试.Omniglot数据集上5-way1-shot和5-way5-shot设置15张图片作为查询图像.20-way1-shot和20-way5-shot分类任务使用5张图片作为查询图像,用随机的一千个测试批次的平均值准确率作为准确率.MiniImagenet上用5-way1-shot和5-way5-shot设置15张图片作为查询图像,随机六百个测试批次的平均准确率作为准确率.
3.3 实验结果本文中实验结果如表1和表2所示,其中匹配网络采用了文献[8]的结构,基于度量方法的网络采用了文献[2]的结构,基于最优化的参数网络采用文献[3]的结构.在Omniglot上,5-way1-shot,20-way1-shot,20-way5-shot取得了不错的分类准确率.随着分类任务的复杂度增加,本文中模型在准确率上要高于其他模型.在MiniImagenet上的两个分类任务,均设置了比较多的查询图像,保证模型的表现出了略优于其他模型的分类准确率.

表1 Omniglot上分类准确率比较

表2 MiniImagenet上分类准确率比较(95%置信区间)
4 结语
本研究提出了基于任务特征的小样本学习方法,目前主流的模型方法类型有3种,即度量模型、匹配模型和参数模型,MAML是参数模型的代表.通过元学习的策略,引用任务特征嵌入来搭配快速学习的模型MAML,来提高应对不同任务的能力,更好地提高了模型的泛化能力.实验结果证明在Omniglot和MiniImagenet上有提高分类结果的准确性.待改进的工作:(1)可以寻找更好的任务嵌入的方式,或许会有更好的效果;(2)小样本学习样本库的规模变得复杂,学习模型执行效率会有所降低.
