集成多种策略模型的维汉神经网络机器翻译系统
2021-08-19宜年艾山吾买尔刘胜全
宜年,艾山·吾买尔,刘胜全
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆多语种信息技术重点实验室,乌鲁木齐830046)
0 引言
神经网络机器翻译(Neural Machine Translation,NMT)是最近几年研究人员主要关注的机器翻译方法,该方法随着计算能力的提升和网络结构的优化使得其在多个翻译任务上的性能超过统计机器翻译,从而成为当前机器翻译领域中最引人注目的方法。2014年Sutskever等人[1]提出了一种端到端的神经网络机器翻译框架——编码器-解码器结构。随后Bahdanau等人[2]提出了注意力机制,改进了编码器-解码器模型对于长句子翻译不好的缺陷。2017年Facebook提出了ConvS2S翻译模型[3],该模型根据利用多层卷积神经网络和门控机制来构建翻译模型,使得模型的训练时间更短和性能更好。2017年Google根据编码器-解码器框架和注意力机制提出一种基于自注意力(Self-Atten⁃tion)机制的Transformer模型[4],该模型相比于之前利用循环神网络和多层卷积神经网路的模型。它仅使用自注意力机制来构成编码器和解码器,从而使得模型训练时间显著缩短,并进一步提升了机器翻译的性能。Transformer是目前学术界和工业界使用最广泛的机器翻译模型。在本次的维汉机器翻译任务中,我们使用Transformer模型实现了维汉机器翻译模型,主要选用Facebook团队研发的FairSeq开源系统。
1 神经网络机器翻译及相关策略
1.1 基于自注意力机制的Transformer模型
Vaswani等人[4]提出了Transformer模型。它在机器翻译领域取得了显著的提升。不同于RNNSearch模型,它是完全基于自注意力机制,能够有效地提升模型训练的效率。但它同RNNSearch一样,同样由编码器和解码器构成。Transformer模型中的编码器与RNN⁃Search的作用相同,都是用于将源语言序列所包含的语义信息转换为特征向量。Transformer的编码器有N层结构相同的子层组成。其中每一个子层都由多头注意力和前馈神经网络以及残差网络构成。多头注意力通过利用自注意力来提取序列中所包含的信息,前馈神经网络这可以将包含提取信息的特征向量进行特征组合和非线性映射。使得特征向量在向量空间上更接近目标语言的特征向量。而残差网络是为了防止模型结构因为过于复杂而引起的退化。
对于第k层编码器,其的公式为:
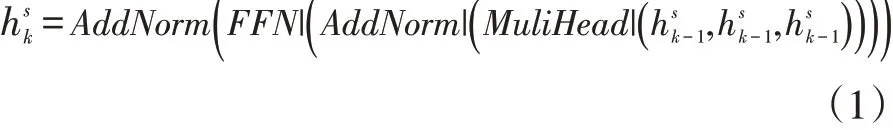
公式中MultiHead()为多头注意力;FFN()为前馈神经网络;AddNorm()为残差网络。为k-1层编码器的输出,dmodel为模型隐状态的维度。当k=1时为词嵌入层的输出。它由词向量和位置信息向量加和得到。通过N次上述过程的迭代可以的得到序列的特征向量hs,它为编码器最后一层的输出即之后会将该特征向量输入到解码器中,用于预测目标序列的字符。
解码器的结构与编码器的结构类似,也是由N层结构相同的子层组成。不同于编码器,解码器的每个子层都由三部分组成,其中两部分与编码器的相同。不同的是在多头注意力之前增加了一个遮掩多头注意力(MaskMultiHead())用于提取已知的目标序列的特征。对于第K层的遮掩多头注意力,其公式为:

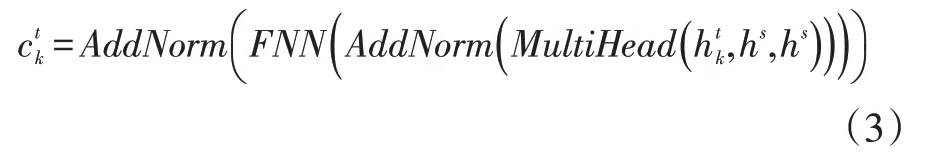
通过将ct经过线性转换和softmax操作之后,可以得到目标序列的概率:

Linear为线性操作。在训练阶段,可以通过最小化交叉熵损失(最大化目标序列概率)来指导模型的更新:

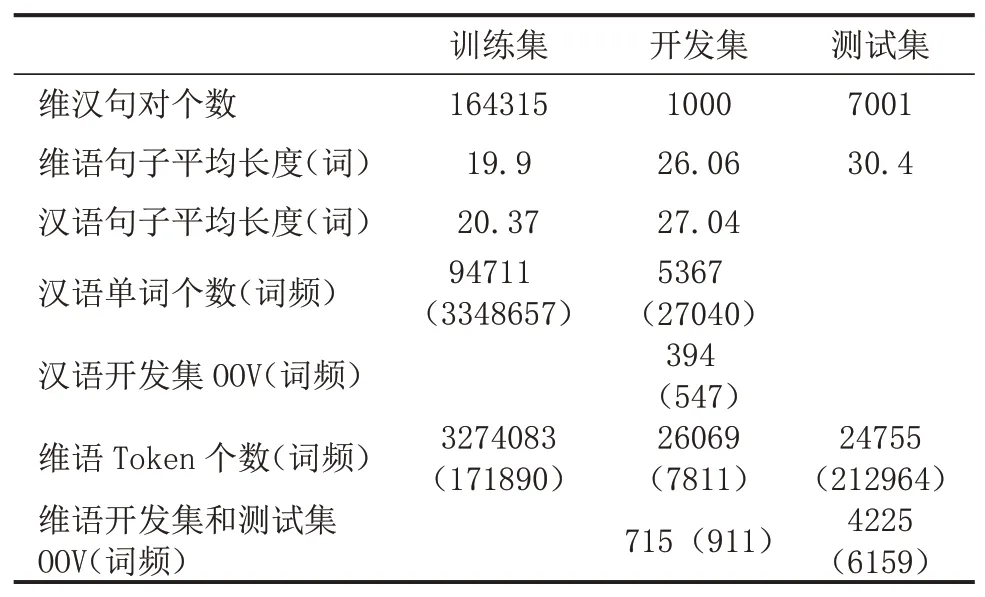
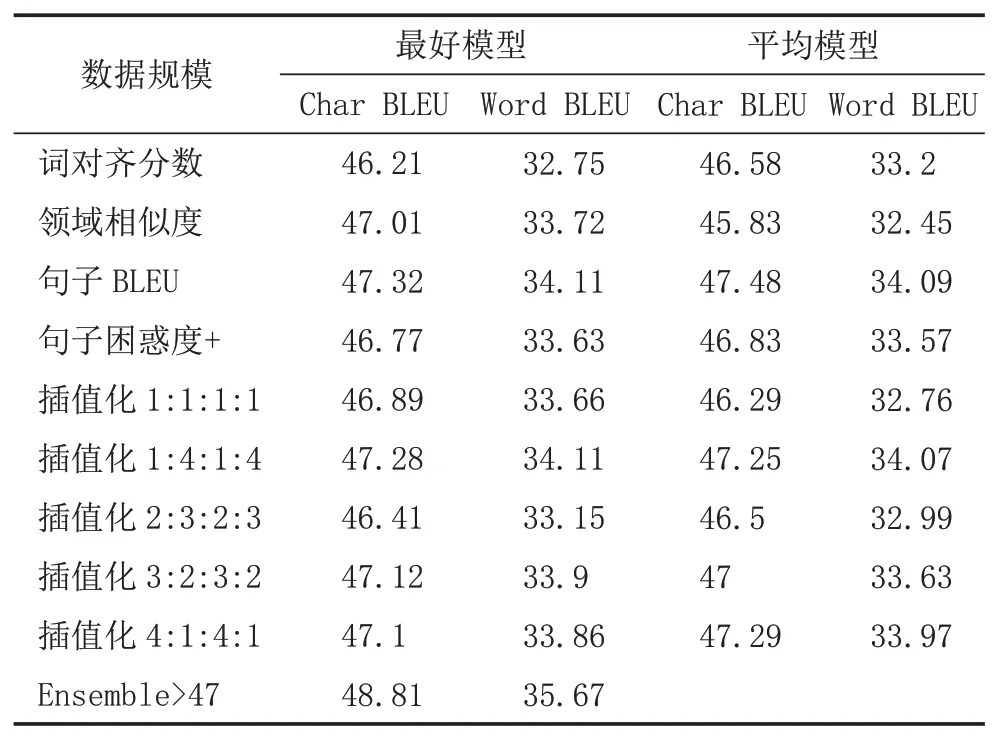
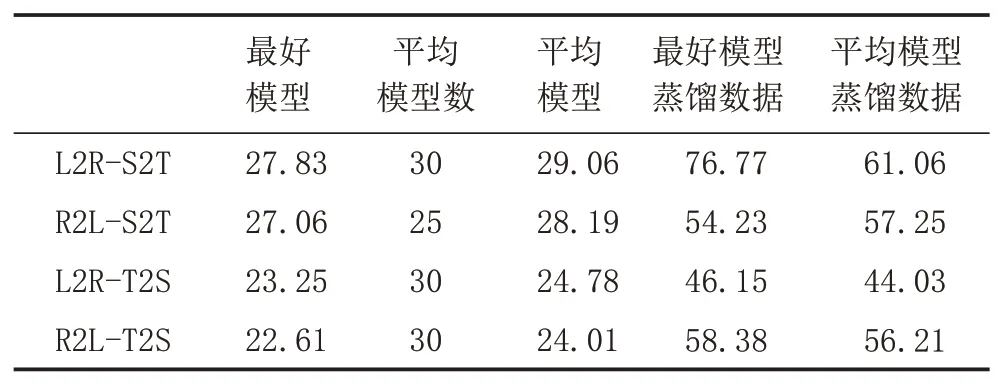
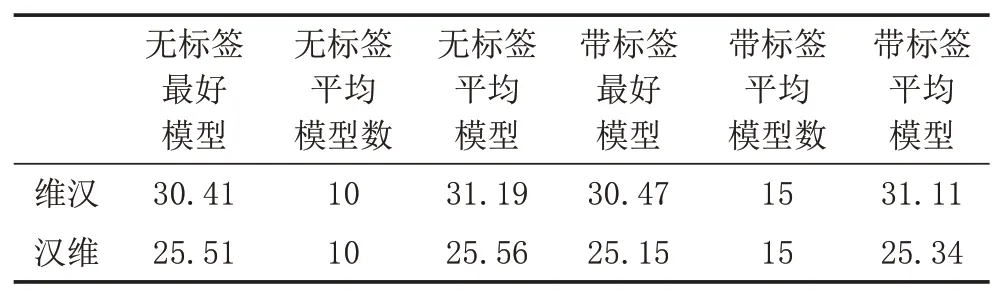
y 文献[5]提出了通过反向翻译(Back Translation,BT)的方法,利用单语言数据提高模型性能的方法,反向翻译已成为机器翻译系统最主要的数据增强方法。本次评测提供了目标端的汉语单语言文本,通过数据预处理保留了6881603条句子。本文中,使用CCMT2020提供的维汉数据,采用知识蒸馏的方法实现了汉维翻译模型,对全部单语数据进行循环翻译(Round Trip Translation)构建《真实汉语句子、伪造维语句子、伪造汉语句子》的语料库利用语言模型的困惑度、sim(Y,YPseudo)、领域相似度、Y,XPseudo的词语对齐值等对DPseudo进行排序,然后与真实数据合并进行使用。文献[6]提出了添加 伪造数据不一定全部是质量高的数据,如何从大量的伪造数据中选出质量高,而且对模型性能提升有帮助的数据是充分挖掘反向翻译的关键问题之一[7]。本评测系统研发中,借鉴已有的方法,尝试采用基于语言模型计算伪造句子困惑度、通过词对齐计算句子对齐度、对真实句子和循环翻译的句子计算BLEU值、领域相似度计算等方法来评价数据质量,根据实验结果使用插值化的方式使用多种评价值的方法,对评价值不在0-1之间的方法,使用Max-Min方法对困惑度进行归一化,以便于在插值化使用的保证每个评价值都在0-1之间。 (1)基于语言模型计算伪造句子的困惑度:该方法中利用双语语料库的维吾尔语文本,利用KenLM1https://github.com/kpu/kenlm工具实现维吾尔语N-Gram语言模型,并对反向翻译得到的伪造维语句子计算困惑度,按照困惑度高低对所有句子进行排序,然后使用Max-Min方法对困惑度进行归一化,以便于在插值化使用的保证每个评价值都在0-1之间。 (2)利用句子词语对齐工具fast_align1对伪造的维汉句对计算基于对齐率的归一化句子对齐质量值。 (3)利用循环翻译的结果,对真实的汉语句子和伪造得到的汉语句子计算句子BLEU,按照BLEU值进行排序。 (4)领域相似度是基于预训练模型的基础上,2019年腾讯CCMT评测报告[8]中的两层全连接网络的方法计算,模型直接加载预训练语言模型,获得句子向量,将句子向量输入到两层的全连接层中,以实现领域内外作为分类器目标进行建模,具体公式为: 领域内数据为正例,通用领域数据为负例,训练BERT领域二分类器,使用BERT领域二分类器对伪造数据中的汉语数据使用分类器进行分类,得到分类为正例和负例的概率,其中分类为正例的概率为领域相似度值。 领域内数据选取:以开发集和训练集的每个句子计算相似度,使用编辑距离方法计算字符串相似度,开发集里面每个句子和训练集中的每个句子计算相似度,大于0.5的保留然后排序,将最相似的20个句子保存起来;开发集里面每个句子和单语汉语中的每个句子计算相似度,大于0.5的保留然后排序,将最相似的20个句子保存起来,如果大于0.5的不够20条,有多少就保留多少。 由于训练分类器,领域内数据和通用领域数据应当有一定的差别。因此采用和选领域内数据相同的方法选取参与训练的通用领域数据。 具体做法:中文开发集作为领域内数据集,使用编辑距离方法计算字符串相似度,给开发集里面每个句子和训练集中的每个句子计算相似度,小于0.5,大于0.1的保留然后排序,将最不相似的100个句子保存起来,给开发集里面每个句子和汉语单语每个句子计算相似度,小于0.5,大于0.1的保留然后排序,将最不相似的100个句子保存起来,将得到的这些最不相似的句子合并之后,将长度小于5的句子去掉,去重,从中随机选和领域内数据相同数量的数据作为通用领域数据。 知识蒸馏(Knowledge Distillation,KD)[9]是一种知识迁移的方法,是一种基于“教师-学生网络思想”的训练方法,由于其简单、有效,在工业界被广泛应用。针对NMT的特点,本文采用句子级的知识蒸馏方法来获取伪造数据,具体的知识蒸馏过程包括不同策略和机构的模型训练、生成翻译文件、混合真实和蒸馏文件从新训练系统。本系统中,分别使用Left2Right(L2R)、Right2Left(R2L)、Source2Target(S2T)、Target2Source(T2S)方式训练四个Teacher模型,然后生成训练数据的四个蒸馏文件,与真实数据合并,采用最大似然估计的方法训练得到学生模型。 Sennrich等人[10]在WMT16比赛中使用模型参数平均方法,该方法可以提升模型鲁棒性。模型平均是指在使用不同数据和不同方式进行训练过程中保存在验证集上翻译结果最好的N个模型,并在利用这N个模型翻译源端语言时对其翻译得到的目标端字符概率平均,是一种融合策略[11]。利用在训练中得到的N个模型预测当前时刻木掰断语言单词的概率分别,进而将多个模型的预测的概率分布进行加权平均,以联合预测最终输出。本文中,对真实数据与伪造数据混合训练的多种策略的模型、知识蒸馏后的模型等进行模型平均,根据实验结果选用合理的系统。 在本次的维汉机器翻译任务中,对维汉双语数据和机器翻译数据都进行了预处理和过滤,主要操作全角字符转半角字符、处理转义字符、控制字符等特殊字符过滤、分词及token、单语、双语语料筛选等,维吾尔语分词使用本课题组自己开发的工具,汉语分词使用清华大学分词系统THULAC,过滤掉句子长度比例3以上的句子,最终保留维汉句子164315条。对汉语单语数据,除了采用以上的预处理方法之外,去掉了“网址,email”或句子中英文或数字的单词比例超过句子的25%的句子以及长度大于100汉语单词的句子,最终保留了6881603条句子。数据统计如表1所示。 表1 评测数据统计分析 在本次的机器翻译评测中,我们使用的操作系统版本为CentOS 7.2,CPU为Intel Xeon CPU E5-2640,内存256G,显卡NVIDIA Tesla V100(4块),显存16G。本次实验中,使用了Transformer模型,采用了Facebook开源的FairSeq1https://github.com/pytorch/fairseq系统的PyTorch版本。本次评测采用FairSeq系统Transformer Big Model,每个模型使用1块GPU核进行训练,BPE,每个batch大约含有4096 to⁃ken,模型训练60 epoch,每epoch保存一次模型用于之后的模型平均。模型中词嵌入层的维度为1024,解码器和编码器包含6个子层,其中每个子层的头自注意力机制使用16个头,前馈神经网络中隐层维度为4096。本次评测采用了dropout机制,dropout设为0.3。使用Adam梯度优化算法来训练得到最终的模型参数,其中β 1=0.90,β2=0.98。初始学习率为0.001,warmup步数设定为4000,beam size=24。汉语和维语端均使用BPE切分,每一个的BPE词表大小为8K,联合切分。 为了充分利用评测提供的汉语单语数据,对伪造平行语料库进行数据规模和选择方法方面的实验,使用10个模型进行平均得到模型的平均值。本实验中,使用维汉真实数据实现汉维翻译模型对全部汉语单语数据进行翻译,使用维吾尔语文本训练得到基于N-Gram的语言模型,实验数据是通过语言模型对伪造数据计算困惑度排序,按照排序结果依次提取。 从表2可以看出,3百万数据的Best Model和平均模型的值处于第二的水平,最好单模型的结果略低于4百万数据训练的单模型,平均模型的水平略低于3.5万数据训练的平均模型,所以本系统中确定选用3百万句对维汉伪造语料库。 表2 反向翻译不同规模数据的实验对比分析 如何从伪造语料库中选择使用对系统训练帮助最大的数据是充分挖掘单语言的关键问题之一。本文中,为了选出来最好的数据,单独和插值化的方式使用语言模型计算伪造句子的困惑度、领域相似度、循环翻译的原句子和最终伪造句子的句子BLEU值分数、词对齐分数等作为评价伪造句子质量的方法从维汉伪造平行语料库选择300万数据与真实数据合并训练模型,实验结果如表3所示,表3使用伪造数据使用知识蒸馏的汉维和维汉翻译。 表3 不同数据选择方法的实验结果 从实验结果可以看出,通过循环翻译把汉语句子翻译成维语,然后把伪造维语句子再一次使用机器翻译翻译成汉语,对最初的真实汉语句子和最后的伪造汉语句子进行相似度计算的方法评价伪造维语句子的方法是最有效的数据选择方法之一,其次领域相似度也是相对有一定效果。插值化的方式合并使用词对齐分数、领域相似度、句子BLEU、句子困惑度等也能接近句子BLEU的水平,集成Char BELU 47以上的模型得到模型值为48.81。 为了提高系统的适应性,提高仅有少量数据的潜力,采用知识蒸馏的方法开展了实验,分析了知识蒸馏的可行性,并在表4中的模型就使用4种方式进行了知识迁移和微调。从表4可以看到,不同解码方向和不同语言方向的确对模型性能具有较大的影响。 表4 Teacher模型的实验结果 从表4和表5,可以看出知识蒸馏对维汉模型和汉维模型的性能有较大幅度的提升。为了测试蒸馏文件加入类似于反向翻译的伪造数据添加标签的作用,实验中分别实现了不带任何标签的蒸馏数据与真实数据合并的学生模型、带 表5 Student模型的实验结果 根据表5的结果,利用四个蒸馏数据和真实数据,对表3中Char BLEU值大于47的模型进行基于三种策略的微调:①直接利用四个蒸馏数据对模型进行微调,然后集成模型;②四个蒸馏数据和真实数据的混合数据对所有模型进行微调,然后集成模型;③使用四个蒸馏数据进行微调,然后再使用真实的数据进行微调,最终集成模型。 表6 知识蒸馏与微调系统结果对比 表7 多个系统在开发集上的性能对比 本文对机器翻译系统性能有影响的反向翻译和数据评价、知识蒸馏、微调、模型平均等进行比较详细的对比实验,并融合使用以上多种策略所得到的模型后,取得了显著提升。从本文实验中,可以得到通过反向翻译生成伪造数据,并合理的方式筛选机器翻译得到的伪造数据对提高低资源翻译模型帮助非常明显。1.2 反向翻译与伪造数据选择

1.3 知识蒸馏与微调
1.4 模型平均
2 数据
3 实验
3.1 实验环境
3.2 伪造数据选用实验

3.3 知识蒸馏、微调和模型平均实验


4 结语
