基于先验约束的深度学习地震波阻抗反演方法
2021-08-18印兴耀宗兆云李炳凯瞿晓阳郗晓萍
宋 磊 印兴耀* 宗兆云 李炳凯 瞿晓阳 郗晓萍
(①中国石油大学(华东)地球科学与技术学院,山东青岛 266580; ②东方地球物理公司研究院地质研究中心,河北涿州 072751)
0 引言
地震波阻抗反演以地震资料为基础,通过综合利用地质和测井资料从有限频宽的地震数据中恢复得到宽频带波阻抗数据,现已广泛应用于油气勘探阶段的储层定性、定量预测和油气开发阶段的井网部署、储量计算、油藏动态监测等方面[1-2]。由于实际地球物理问题十分复杂,人们对其认知通常又十分模糊,这使得在反演波阻抗时构建的模型大多是近似的。而深度学习算法可从大量已有数据中学习到隐含知识,从而使所构建数学模型更有利于对那些知识背景不清晰、模型欠精确的问题进行求解,因此该算法适用于波阻抗反演。
深度学习源于神经网络研究,此概念由Hinton等[3]率先提出。相比于提升方法、支持向量机、最大熵方法等通过人工抽取样本特征且只能学习到没有层次结构的单层特征的“浅层学习”方法而言,深度学习通过对输入样本逐层进行特征变换以学习得到数据的层次化特征表示[4-6]。深度学习模型的复杂度高,非线性层级数大,可实现对复杂函数的逼近,但通常复杂模型的训练效率低、易陷入过拟合。而随着云计算、大数据时代的到来,高性能计算集群有效地缓解了训练的低效性,海量训练数据降低了过拟合风险,促进了深度学习的研究与应用的逐步升温[7]。目前深度学习已广泛应用于计算机视觉[8]、图像处理[9]、语音识别[10]和自然语言处理[11]等领域,并给这些领域带来了巨大的变革。
神经网络技术在油气地球物理领域应用较早,印兴耀等[12-14]在上世纪90年代初就开展了基于神经网络的储层预测技术研究,并取得良好应用效果。近年来随着深度学习的兴起,国内外众多学者基于此开展了大量研究,如利用深度学习算法识别断层和盐体[15-17],进行地震相分类[18],提取弹性参数[19-20],进行储层预测等[21-22]; 在波阻抗反演方面,依据算法所采用的学习方式分为三类主要方法:基于监督学习的波阻抗反演[23]、基于无监督学习的波阻抗反演[24]和基于半监督学习的波阻抗反演[25-26]。
基于监督学习的波阻抗反演方法需耗费大量时间制作标签数据(通常来源于测井波阻抗数据)集,且标签数据的质量也会影响网络的反演精度。无监督学习波阻抗反演方法将物理模型与神经网络结合,在网络学习过程中引入正演模型。这种无监督学习方式减少了网络对标签数据的依赖,但同时因缺少真实标签数据的约束,故其反演精度通常低于监督学习地震反演方法。
半监督学习波阻抗反演方法结合监督学习反演方法与无监督学习反演方法的优势,同时使用大量无标签数据(指无对应测井数据的地震数据)和少量有标签数据(有对应测井数据的地震数据)对网络模型进行训练。训练时将地震数据输入网络模型,得到估计的波阻抗; 将该波阻抗再输入到正演模型,得到合成记录; 通过对比合成记录与输入记录、标签数据与网络估计的波阻抗数据计算损失函数优化网络模型。因此,半监督学习反演方法既减少了训练时获取大量波阻抗的难度,又将井中波阻抗作为标签约束网络反演,保证了反演精度。但此类方法仍存在一些问题: ①在构造复杂区,数据特征也十分复杂,在训练网络模型时,为了更精确地表征地震数据与波阻抗数据之间的映射关系,可能会丢失较多局部特征,使网络反演结果丧失一些细节信息。尽管可通过增加网络深度或延长训练周期以便于网络学习这些局部特征,但由于数据量限制,很容易陷入过拟合。②由于地震数据采集设备的限制及处理过程中的低频损失,获取的地震数据通常缺少低频成分,由于深度学习的基础是数据,若仅据带限地震数据对网络模型进行训练,则网络所预测的波阻抗也会缺少低频成分。而低频成分蕴含地质构造的基本信息,缺失该成分在一定程度上会降低基于波阻抗反演结果开展储层预测的精度。③受现场环境及采集条件影响,所采集原始数据通常包含大量噪声,尽管可在处理阶段降噪,但这样也会损害其中的有效信息,如何提高网络模型对含噪地震数据的反演精度,也是亟待解决的问题之一。
为此,本文提出基于先验约束的深度学习波阻抗反演方法,即根据待反演区地震相类型对其进行区域划分,并为每个区域生成相应子网络,使每个子网络仅用于对应区域反演任务; 将初始模型用作一类特殊标签以丰富反演结果的低频信息、提高反演结果横向连续性; 在模型中引入具有生物真实性的强抗噪神经元激活函数Rand Softplus[27]以提高其抗噪性能。最后将上述方法针对Marmousi 2模型进行测试,并将其成功地应用于M油田的实际地震数据的反演。
1 方法原理
1.1 反演流程
反演的具体流程主要包括五个方面。
(1)区域分割:将已取得的地震相分类结果作为最初的区域分割结果,为保证每个分割区域内具有较充足数据量并存在一定数量的井数据,合并相邻的内部反射结构类似且面积较小的区域。
(2)数据预处理:首先对地震数据与测井数据进行标准化处理,再进行井震标定,构建时深关系,然后根据每个区域内的测井数据与地震数据为每个区域提取区域子波并构建区域子波集,最后根据测井数据与构造解释结果构建初始模型。
(3)训练反演模块:反演模块由一系列网络模型构成,这些网络模型是根据区域分割结果自动生成的,每个网络模型唯一对应一个分割区域。网络模型的输入是地震数据,输出是波阻抗数据,训练时使用与网络模型对应分割区域内的训练数据,并采取半监督学习方式训练这些网络模型。
(4)波阻抗反演:将地震数据依据区域分割结果输入到反演模块的对应网络模型中,再合并反演模块中所有网络模型预测的波阻抗以获得最终反演结果,最后对反演结果进行反标准化处理。
(5)评价反演结果:利用均方误差、相关系数和确定系数三项指标定量地评价反演结果。
1.2 网络模型
循环神经网络(RNN)具有一个隐藏状态向量,可在序列数据之间传递,使其能捕获序列数据中的长距离依赖关系。而卷积神经网络(CNN)使用固定大小的卷积核并通过滑动窗口方式对输入数据进行处理,故在局部特征提取方面有较大优势。本文充分考虑了二者的优势而构建了深度学习网络模型框架(图1),包含全局特征提取层、局部特征提取层和回归层三个主要部分。

图1 深度学习网络模型框架
1.2.1 全局特征提取层
全局特征提取层的功能是提取输入地震数据中长时间依赖关系,即全局特征,由一系列GRU (Gate recurrent unit)[28]构成。GRU是RNN的一种,用于处理长期记忆与反向传播时梯度消失的问题,它使用重置门和更新门控制信息流动。
在图2所示结构中,前向传播过程可表示为
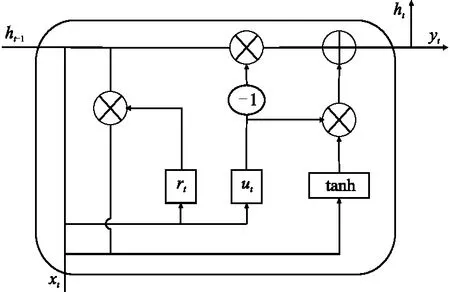
图2 GRU结构示意图
(1)
式中:rt、ut分别为重置门和更新门的门控信号,rt门控信号用于控制是否忽略之前的隐藏状态,而ut用于控制隐藏状态变量的更新;xt、yt、ht、ht-1分别为当前时刻的输入、输出、状态变量及前一时刻状态变量;W和b分别是权值矩阵和偏置向量。
1.2.2 局部特征提取层
局部特征提取层的功能是提取输入地震数据的局部特征。由于卷积层中的膨胀系数(dilation)可控制卷积核的感受野大小,所以首先利用一组膨胀系数不同的并行卷积块提取地震数据中不同尺度的局部特征,再使用一个全连接层和一个卷积块组合局部特征。这里的卷积块由一维卷积层(Conv1d)、批归一化层(Batch normalization)[29]和Rand Softplus激活函数组成。
卷积层由包含多个神经元的特征面组成,每个神经元通过卷积核与前一层特征面局部区域相连以提取输入特征[30]。卷积层的前向传播过程表示为
yl=yl-1*Wl+bl
(2)
式中:yl-1、yl分别为第l-1、第l层输出;Wl、bl是第l层卷积核和偏置向量; “*”是卷积运算符。
批归一化层用于处理中间层数据分布变化问题,加速网络的收敛速度。其定义为
(3)
式中:μ、σ分别为输入数据的均值和标准差;ε是常量,用于保证分式中的分母不为0;λ、ψ均为可学习参数。
激活函数是网络模型的重要组成部分,是网络非线性的来源,使网络能逼近高度非线性函数。常用的激活函数有Tanh、Relu、Softplus等。由于这些激活函数只是对生物神经元输出相应特性的高度简化与模拟,使用这些激活函数的网络模型在抗噪性、不确定性信息处理及功耗等方面与人脑仍存在巨大差距。Rand Softplus激活函数通过引入反映生物神经元随机性的参数,将Relu与Softplus函数有机结合,使其具有强抗噪能力,定义为
f(x)=(1-η)max(0,x)+ηln(1+ex)
(4)
式中:x为神经元输入值;η为生物神经元随机性参数,其值与输入数据的噪声水平有关,详细的计算步骤[27]如下。
(1)计算神经网络输入数据所含噪声标准差
(5)
(2)调整噪声标准差:由于同一层内部分标准差远大于该层均值,为避免归一化操作导致其分布不均匀,将大于2倍均值的标准差设定为2倍均值。
(3)噪声标准差归一化处理:随着网络深度增加噪声标准差呈逐渐减小趋势,为此对噪声标准差做归一化处理,从而得到参数η。
(4)η置零操作:为控制网络的稀疏性,设置比例系数阈值ηth,将η中小于ηth的部分置为0。
1.2.3 回归层
回归层的功能是将数据从特征域映射到目标域,即首先使用一个全连接层来组合全局特征提取层和局部特征提取层所提取的特征。由于在特征提取时改变了输入数据尺寸,所以再使用一组串行反卷积块对合并后特征进行上采样,使其具有与标签数据相同的采样率; 再使用一个GRU和一个全连接层将上采样后数据从特征域映射到目标域。其中反卷积块由反卷积层、批归一化层和Rand Softplus激活函数组成。反卷积层与卷积层思路类似,仅是运算不同,可将其理解为卷积层的逆过程,其前向传播过程与卷积层的反向传播过程相同,反向传播过程与卷积层的前向传播过程相同[31]。
1.3 反演框架
本文采用半监督学习方式,并构建图3所示的基于先验信息约束的半监督学习反演框架。

图3 本文方法反演框架
该反演框架由数据分类、反演、正演和数据合并等四个主要模块组成。数据分类模块的功能是将输入地震数据按区域分割结果进行分类。为消除分块训练后的拼接痕迹,在对区域边界处数据进行分类时,对数据向上、向下延拓半个子波长度; 当可延拓长度小于半个子波长度时,延拓至整个二维剖面边界处; 最后将分类后数据依次输入到反演模块的相应网络模型中。反演模块由n个网络模型组成,每个网络模型(图1)对应一个分割区域,网络模型的输入是地震数据,输出是波阻抗,训练时使用相同分割区域内的训练数据训练相应网络模型。数据合并模块的功能是根据区域分割结果将各分割区域内的波阻抗数据或地震数据进行合并,从而得到与输入地震数据对应的波阻抗数据或合成地震数据。正演模块的功能是将波阻抗进行正演,从而得到合成地震记录。即首先根据
(6)
将输入的波阻抗转换为反射系数; 然后从区域子波集中选取与输入波阻抗数据属同一分割区域的区域子波; 最后将反射系数与区域子波进行褶积,得到合成地震记录。式中IP为纵波阻抗序列。
训练时,反演模块中各个网络模型内部可学习参数的优化受以下三个过程的综合影响:
(1)无标签地震数据输入到数据分类模块后,地震数据按所属区域类别输入到反演模块的相应网络模型中,得到多组预测波阻抗数据,这些波阻抗数据经过正演模块后又得到多组合成地震数据,通过计算合成地震数据与分类后输入地震数据之间的均方误差(lseismic),更新反演模块中相应网络模型内部参数。
(2)将井旁道地震数据输入数据分类模块进行分类,同样将分类后地震数据按类别输入到反演模块的相应网络模型中,得到多组预测波阻抗数据,通过计算这些预测波阻抗数据与相应井段之间的均方误差(lwell),更新反演模块中相应网络模型内部参数。
(3)将所有地震数据输入到数据分类模块中进行分类,再按类别将地震数据输入到反演模块的相应网络模型中,得到多组预测波阻抗数据,计算这些预测波阻抗与对应初始模型数据之间的均方误差(lmodel),从而更新反演模块中相应网络模型内部参数。
在训练初期,初始模型可使网络快速收敛到某一局部低值,但由于初始模型与地下真实波阻抗存在一定差距,若在训练后期仍将其作为标签对网络进行训练,则会使反演模块的预测结果过度模型化,因此应随着训练的进行对初始模型进行更新。本次采取每隔一定训练周期将反演模块预测的多组波阻抗输入到数据合并模块中进行合并,再用合并后波阻抗数据更新初始模型。
综上,构建如下损失函数
(7)
(8)

反演模块中网络模型优化完成后,便可利用上述反演框架开展波阻抗反演,其具体过程是:将待反演地震数据输入到数据分类模块进行分类,即将地震数据按类别输入到反演模块的相应网络模型中; 通过反演模块得到一组预测波阻抗数据; 再将这组预测波阻抗输入到数据合并模块,得到反演结果; 最后再对该反演结果进行定量评价。
1.4 反演结果的评价
反演模块经训练后,地震数据通过数据分类、反演、合并模块可得到预测波阻抗数据,地震数据通过数据分类、反演、正演、合并模块可得到合成地震数据。通过计算真实波阻抗与预测波阻抗、输入地震数据与合成地震数据的均方误差(MSE)、相关系数(PCC)和确定系数(R2),定量评价反演结果。
(1)MSE是预测数据与真实数据对应点误差的平方和,其值越小说明预测数据与原始数据拟合越好,其定义如式(8)所示。


(9)
(3)R2用于评价变量之间的拟合优度,值域为[0,1],其值越大,表明变量之间拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比越高。其定义为
(10)
2 模型数据测试
2.1 无噪声条件下的波阻抗反演
选取Marmousi 2模型(图4a),生成波阻抗数据(图4b),再根据下式对波阻抗数据做标准化处理
(11)
式中x是任意输入数据。将标准化后的波阻抗数据与主频为30Hz的Ricker子波输入到正演模块,得到相应的正演地震数据; 再对该地震数据进行滤波,使其缺失5Hz以下频带(图4a)。将地震相划分结果作为区域分割结果的初值,对相邻的内部反射结构类似且面积较小的区域进行合并,如将剖面左侧的透镜体与周围区域进行合并(图4c区域Ⅰ)、将剖面中部的两个断层结构进行合并(图4c区域Ⅱ),得到最终的区域分割结果(图4c)。均匀地抽取20道的波阻抗作为伪井数据。然后进行层位解释及断层解释,据此将二维剖面分割为多个区块。针对具有测井数据的区块,将测井数据在该区块内进行内插外推; 而对于无测井数据的区块,则根据相邻区块内的数据对该区块做插值或延伸,生成图4d所示的初始模型。
按照DL/T 573-95《电力变压器检修导则》规定,变压器一般在投入运行后的5年内和以后每间隔10年大修一次。我厂#6B高厂变为N.M.G变压器厂生产的、接线组别为△/YO/YO-1-1的变压器 (额定电压:22/6.3V)。1996年投运,当时对变压器内部进行了全面检查,未发现问题,修后运行状况良好。根据我厂检修计划的安排,决定在2015年#6机组大修中对该变压器进行全面预试。

图4 Marmousi2模型数据
使用地震数据、伪井、初始模型和子波训练反演模块中的网络模型,训练时将迭代周期设置为1000,每个迭代周期的批训练量为50,损失函数中的α、β、γ分别设置为1.0、1.0、0.1,训练时每隔50个迭代周期更新一次初始模型。随后用训练好的反演模块进行波阻抗反演(图5a,设定为Result1)。
基于上述反演框架,首先测试无初始模型约束条件下反演效果,即将γ设置为0,得到了图5c所示反演结果(设定为Result2); 然后测试无初始模型和区域分割结果约束条件下的反演效果,即将γ设置为0且不进行区域分割(认为整个地震剖面属于同一区域),得到图5e所示反演结果(设定为Result3)。表1显示不同先验约束条件下网络在训练阶段与预测阶段的计算时长(Intel i7 9700、Nvidia GeForce GTX 1050Ti),发现引入各种先验信息约束后,网络的计算时间仍保持在可接受范围内。

表1 不同先验约束下网络的训练和预测阶段运行时长
为了更直观地对比不同先验约束条件下的反演效果,根据
(12)
分别计算Result1、Result2与Result3与真实波阻抗的相对差值,结果如图5b、图5d和图5f所示。
由于事先已知模型的波阻抗,可通过计算Result1、Result2和Result3与真实波阻抗的MSE、PCC和R2平均值定量评价不同约束条件下网络模型的反演效果。表2、表3和表4分别为Result1、Result2和Result3与真实波阻抗在整个剖面上以及在图5中红色矩形1、2、3标示区域的MSE、PCC和R2平均值。
分析、对比图5中不同先验约束条件下的反演结果及表2~表4中定量评价结果,可直观地发现,充分利用初始模型和区域分割结果等先验信息能较大程度上消除反演结果中纵向抖动现象,提高反演结果的横向连续性; 且在一些构造复杂部位,这种效果改善更明显。如图5a、图5c和图5e中红色矩形1、2、3标示区域,这主要是由于该区域地下构造较复杂,存在构造突变和断层,此时初始模型和区域分割结果向网络提供基本构造信息,并对网络预测结果做出明确的空间约束。而且反演模块中每个网络模型只负责构造形态相似区域的反演,使这些网络模型能从训练数据中捕捉更多局部特征,在使用训练好的网络模型进行反演时,其反演结果的细节信息也会更丰富,即反演精度更高。
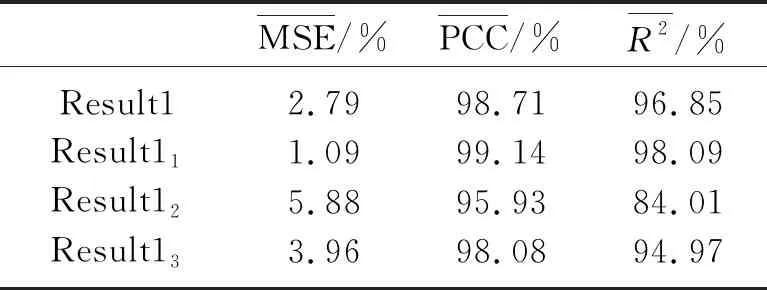
表2 Result1的定量评价
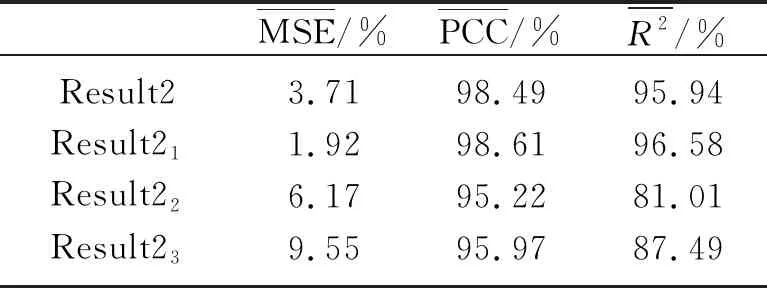
表3 Result2的定量评价
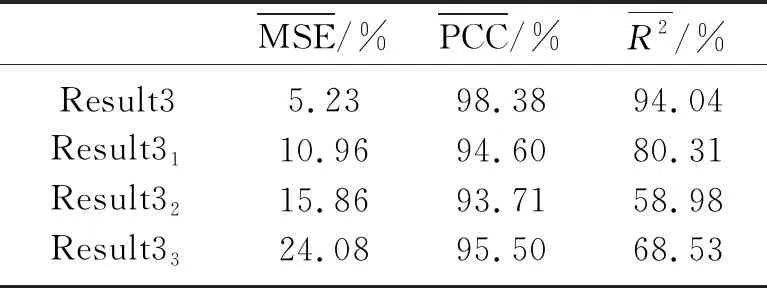
表4 Result3的定量评价
但在图5a中红色箭头所指区域的反演效果却出现了退化,这主要是由于在进行区域分割时该处(图4cⅠ区域)纵向长度较短,由于地震数据的自相关性,当将该处地震数据输入到网络模型时,网络易将该处地震数据与其他某些道集数据相混淆,所以呈现反演精度降低的现象。

图5 不同先验信息约束条件下的反演结果(左)及其与真实波阻抗的相对差值(右)
2.2 含噪声条件下的波阻抗反演
为测试网络模型对噪声数据的适应能力,向原地震数据中分别加入4%、8%、12%的高斯随机噪声,然后在网络模型中分别使用Rand Softplus和Tanh激活函数对含噪地震数据进行反演。图6显示0、4%、8%和12%含噪条件下使用Rand Softplus和Tanh两种激活函数的反演结果。图7为上述反演结果与真实波阻抗的相对差值。表5和表6归纳在上述噪声条件下所得反演结果的定量评价。


表5 基于Rand Softplus激活函数的反演结果定量评价

表6 基于Tanh激活函数的反演结果定量评价

图6 不同噪声条件下使用Rand Softplus(左)和Tanh(右)激活函数的网络模型的反演结果

图7 图6所得反演结果与真实波阻抗的相对差值
3 实际数据应用
将本文反演方法应用于M油田实际三维地震数据。所选测线(图8)穿过3口井(W1、W2、W3),包含427个CDP,纵向时间长度为378ms、采样间隔为2ms。区内Hor3界面(红线)的上部与下部地震数据的反射结构有较大差异,下部振幅强度大、连续性好、内部反射结构有序; 而上部振幅强度小、连续性差、内部反射结构相对杂乱,因此以Hor3为分界线将该剖面分为上、下两个区域。本次将W1和W3设定为训练井,W2作为测试井,训练井用作网络标签,而测试井不参与子波提取、初始模型构建与反演模块的训练。

图8 地震数据、测井数据与地震层位解释结果
首先对数据进行预处理。
(1)据式(11)对井数据、地震数据做标准化处理。
(2)井震标定,构建时深关系; 再从井旁地震道分别提取Hor3层上、下相邻区域的子波(图9)。

图9 Hor3层上、下相邻区域的子波
(3)当标签数据与输入地震数据的频谱范围差异较大时,不利于网络快速收敛,还会降低网络预测精度[33],因此需滤去测井数据中的高频成分。
(4)根据地震层位解释结果,并综合利用测井数据,构建初始模型(图10)。

图10 本文方法构建的初始模型
然后用区域子波、井数据、地震数据与初始模型训练反演模块中的网络模型,训练周期为500,每个周期的批训练量为20,损失函数中的α、β、γ分别设定为0.2、1.0、0.1,训练时每隔30个周期更新一次初始模型。
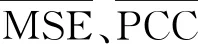
从上述反演结果可知,本文反演方法不仅在训练数据集中有标记数据上具有较好反演效果,且在无标记数据上仍能取得较高反演精度。合成地震记录与输入地震记录的对比结果(图11d)充分证明了本文方法反演结果的合理性与准确性; 与稀疏脉冲反演法结果(图11b)相比,本文方法反演结果中横向连续性更好,且层与层之间的粘连效应较弱。

图11 本文方法在实际数据中的应用
4 结论
在深度学习地震反演算法中,本文尝试引入不同的先验约束条件,由此提出一种基于先验约束的深度学习地震反演方法。为增强算法的稳定性与抗噪性,并减少算法对标签数据的依赖性,在网络模型中选用了强抗噪性的Rand Softplus激活函数,且采取半监督学习方式对网络模型进行训练。经过理论分析与实验测试取得以下认识和结论:
(1)采用区域分割策略后,每个网络模型只需负责数据特征相似区域的反演,这使网络模型能从训练数据中提取更多有效信息,从而丰富了反演结果的细节信息,提高了反演精度。但由于地震数据的自相关性,在一些纵向长度较短的地震道,反演精度会有所退化。
(2)将初始模型作为一种特殊标签来约束网络的反演过程,可使网络充分利用初始模型中含有的低频分量和构造细节信息,从而丰富了反演结果的低频信息,提高了反演结果的横向连续性。
(3)Rand Softplus激活函数通过引入反映数据随机性的参数,提高了网络对噪声数据的适应能力。尤其是在强噪声条件下,该激活函数对反演精度的提升更为明显。
