基于风光资源特性的独立微电网电源优化配置方法
2021-08-09林凌雪廖碧英管霖
林凌雪 廖碧英 管霖
(华南理工大学 电力学院,广东 广州 510640)
电源优化配置是微电网规划设计阶段的一个重要内容,受当地负荷水平、地理情况和气候条件等因素的影响,其中气候条件对风光发电设备的配置起了决定性作用。根据不同地区的自然资源特性,研究不同风光资源条件下微电网的电源优化配置,对提升微电网的规划水平和提高清洁能源的利用效率具有重要的意义。“风/光/储”是最典型的独立微电网电源组合方式,以风力发电和光伏发电为主,储能装置作为备用和补充、维护系统的稳定。
分析风光资源特性需要建立科学合理的风光资源指标评价体系与评价方法。目前国内外关于风能资源评价[1]和光伏资源评价[2]的研究较多,国内风电光伏行业已有一些规范的指标评价体系,如2013年国家能源局发布了NB/T 31045—2013风电场运行指标与评价导则,2016年发布了光伏电池行业清洁生产评价指标体系,但从电源规划层面进行风光总体资源评价的研究较少。文献[3]从运行层面对多种清洁能源互补发电提出了一种考虑多指标综合评价的多能互补方法。文献[4]采用平均距平百分率和变异系数作为衡量年内发电量波动性的指标,给出了以发电量年内波动性最小为目标的风电/光伏容量优化配置方法。在指标评价方法方面,文献[5]针对光伏资源利用水平,提出了基于熵权法的模糊综合评价模型,但在进行权重计算时,仅考虑了客观权重,过于依赖指标数据的信息量,未考虑主观权重,忽略了指标所代表的现实意义。文献[6]基于灰色评价法对风光互补系统的可靠性进行评价,采用熵权-层次分析法计算权重,虽然同时考虑了客观和主观权重,但层次分析法需要进行一致性检验,且在指标数较多时不能准确体现专家的意愿。
在独立微电网电源优化配置模型方面,现有研究中关于优化目标的建立,通常考虑了经济性[7]、环境污染[8]、供电可靠性[9]、弃风弃水量[10]和风光资源不确定性[11]等。文献[12]以总净现成本最低为优化目标,分析了不同补贴方式对电源容量配置优化结果的影响,结果表明,按发电量补贴的整体总成本比按投资安装补贴更少。关于运行约束,除了基本的机组出力等约束,文献[13]还考虑了可控负荷对系统运行成本及弃风光率的影响。文献[14- 15]考虑了多个目标的电源配置模型,并采用多目标优化算法对构建的多目标模型进行求解。文献[16]分析了不同独立微电网电源容量配置优化模型的差异及其造成的原因。
然而,现有模型很少考虑不同风光资源条件下独立微电网的电源优化配置问题。为此,本文提出了基于风光资源特性的独立微电网电源优化配置方法。首先构建包含风电资源、光伏资源和风光互补3类指标的风光资源指标评价体系;接着提出了基于熵权-复相关系数-序关系分析的主客观组合权重法,并采用模糊评价和灰色评价方法对风光资源特性进行分析;然后基于生成对抗网络(GAN)的场景模拟生成法和K- 中心点的场景聚类消减法构建了微电网场景模型,并建立了考虑经济性、供电可靠性和环保性的多目标电源配置优化模型,采用线性规划算法进行求解;最后进行独立微电网电源配置优化,以验证所提方法的可行性,并分析了代表地区的电源配置结果的差异及规律,以期为独立微电网电源配置提供参考。
1 我国不同地区的风光资源评估
1.1 风光资源指标评价体系
本文从电源规划配置层面,构建风光资源指标评价体系,包括风电资源评价指标、光伏资源评价指标和风光互补评价指标。其中,从出力大小、有效利用时数和出力波动性方面评价风电资源和光伏资源;从昼夜互补、季节互补方面评价风光互补的影响。风光资源的指标评价体系如图1所示。
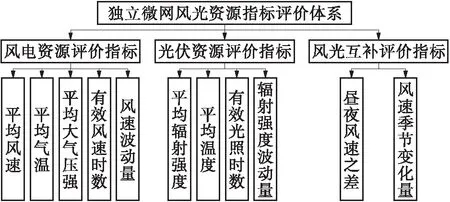
图1 独立微电网风光资源指标评价体系
风能的大小与风速、气温和大气压强有关,可用风功率密度D风表示,
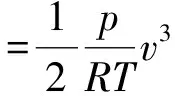
(1)
式中,p为大气压强,v为风速,T为气体的热力学温度,R为气体常数。
因此,风能的出力大小用平均风速、平均气温和平均大气压强表征,风能的有效利用时数和出力波动性分别采用有效风速时数和风速波动量表征。其中风速波动量Δv为统计周期内相邻单位时间平均风速变化值之和,由于风速波动性大,因此统计一年内每个小时的风速变化,其计算公式如下:
(2)
光伏的出力大小与辐射强度和温度有关[17],因此采用平均辐射强度和平均温度表征。光伏的有效利用时数和出力波动性分别采用有效光照时数和辐射强度波动量表征。其中辐射强度波动量ΔQ为统计一年内每日平均辐射强度变化之和,体现了辐射强度波动的日特性和季节特性,其计算公式如下:
(3)
由于光伏只能白天出力,且夏季出力比冬季多,若某地夜间风速比白天大、冬季风速比夏季大,则其风能和光伏具有天然的互补优势,有利于独立微电网电源配置。因此,对于风光互补性考虑两个方面:昼夜互补和季节互补,分别采用昼夜风速之差Δv昼夜、风速季节变化量Δv季节表征,其计算公式如下:
(4)
Δv季节=v冬-v夏
(5)
式中,v夜为傍晚6点至凌晨6点之间的平均风速,v昼为凌晨6点至傍晚6点之间的平均风速,v冬为1月1日至3月20日和9月24日至12月31日的平均风速,v夏为3月21日至9月23日的平均风速(我国属于北半球,考虑南半球地区时则相反)。
1.2 风光资源综合评价方法
模糊评价可获得各地区各类指标的评价等级,能直观反映各地区风光资源各类指标的优劣势,但无法比较相同评价等级的地区。灰色评价可以清晰对比出不同地区风光资源水平的大小,其中灰色关联度可以作为表示风光资源水平总体情况的指标。因此,本文采用模糊评价和灰色评价相结合的方法对风光资源指标进行分析,两种评价方法侧重点不同,可以从不同层面综合评价风光资源特性。在计算权重时,本文提出了基于熵权-复相关系数-序关系分析的主客观组合权重法。其整体流程图见图2。

图2 风光资源综合评价方法的流程图
1.2.1 主客观组合权重法
在指标体系评价过程中,各指标的权重会对评价结果产生重大的影响,本文采用客观和主观权重组合的计算方法,可以综合考虑指标数据的信息量和指标所代表的现实意义。
基于熵权法的客观权重取决于指标信息的多少和质量,但没有考虑到指标间信息存在重叠的情况;复相关系数法可以减小指标间重复信息的影响,适用于指标间存在错综复杂关系的情况,可用于改良客观权重。基于序关系分析法的主观权重无需一致性检验,且在指标数量较多时,可以解决因专家判断时犹豫而造成的“判断不完全”问题。主客观组合权重法的流程图如图3所示。
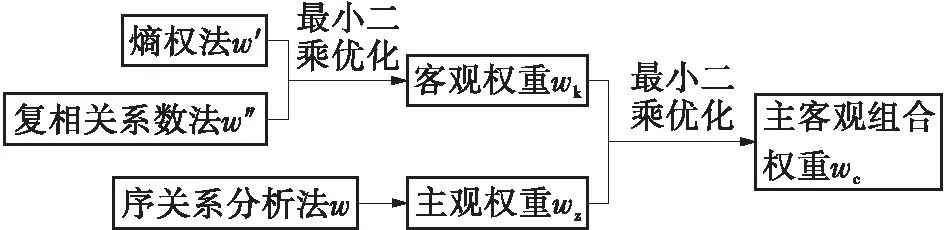
图3 主客观组合权重法的流程图
1)基于熵权法的客观权重法
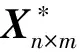

(2)计算第j项指标的熵值
(6)
式中,k=(lnm)-1,当pij=0时pijlnpij=0。
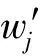
(7)
2)基于复相关系数法的客观权重法
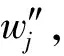
(8)
3)基于序关系分析法的主观权重法
序关系分析法通过对指标的重要性进行排序,根据序关系确定权重,序关系越重要,权重越大,其步骤如下:
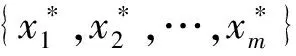
(2)给出序关系中相邻指标间相对重要程度的比较判断。专家根据对相邻指标xj-1与xj的重要程度的判断给出其权重之比,即
aj=wj-1/wj,j=2,3,…,m
(9)
相邻指标重要程度的比较分为同样重要、稍微重要、明显重要、强烈重要、极端重要5个等级,aj依次取值为1.0、1.2、1.4、1.6、1.8。
(3)计算权重系数wj。根据式(9)及权重之和为1,先求得指标xm的权重wm,并依次算出其余指标的权重
(10)
4)基于最小二乘优化的组合权重法
组合权重是对几种单一权重进行组合,合理的组合方式应兼顾各权重的优点。通过加权平均合成的组合方式容易产生组合权重方差较大的问题,通过乘法合成可能会导致“倍增效应”,因此本文采用基于最小二乘的优化法计算最优组合权重,可获得较为科学合理的组合权重,具体过程如下:
以主客观权重组合为例,假设各指标的主观权重为Wz=[wz1,wz2,…,wzm]T,客观权重为Wk=[wk1,wk2,…,wkm]T,各指标的优化组合权重为Wc=[wc1,wc2,…,wcm]T,计算标准化矩阵Xn×m中第i个被评价对象的评价值,即
(11)
基于最小二乘优化法,以主客观权重下的评价值和组合权重的评价值偏差最小为目标,建立优化组合评价模型,其表达式如下:
[(wkj-wcj)xij]2}
(12)
求解式(12),得到组合权重
(13)

1.2.2 模糊评价和灰色评价
模糊评价基于模糊数学的线性变换原理和最大隶属度原则,其评价过程如下:先确定指标的评价等级,一般划分为3~5个等级;再分别确定各指标的隶属度向量,获得模糊评判矩阵;然后对模糊评判矩阵和已求得的组合权值进行线性变化运算,可得到模糊评价向量;最后根据最大隶属度原则确定评价等级,流程如图2所示。
根据模糊数学理论,5级制能对被评价对象作出较准确的描述,因此划分风光资源指标的评价等级为V={v1,v2,v3,v4,v5},对应评语为{差,较差,一般,较好,好}。模糊评价的关键在于隶属度函数的构造,基于风光资源的分布特点,本文采用如下高斯函数构造隶属度函数:
(14)
式中,x为指标的原始数据。
评价等级的隶属度函数和分级界限如图4所示。
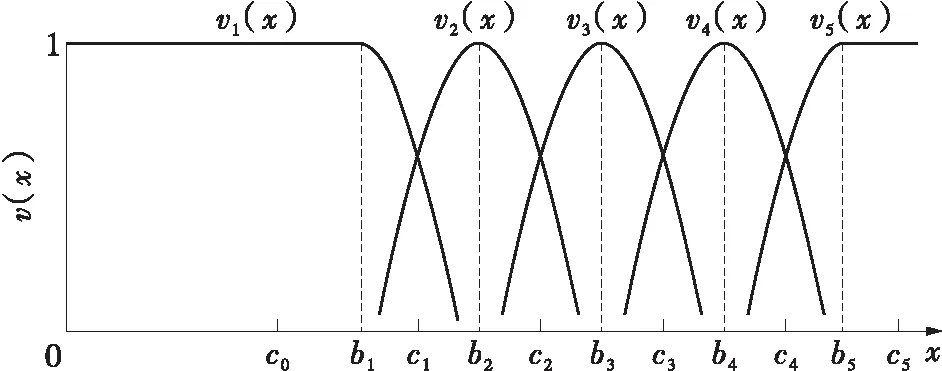
图4 等级隶属度函数与分级界限
确定隶属度函数形式后,指标分级界限与隶属度函数参数存在如下关系:
(15)
式中,cjh、σjh和bjh分别为第j个指标第h个等级的分级界限、隶属度函数的方差及中间值。因此只要确定指标分级界限,隶属度函数就唯一确定。规定各等级的隶属度函数的方差相等,则分级界限计算公式如下:
(16)
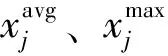
灰色系统是表示部分信息明确、部分信息不明确的贫信息系统。灰色评价的思想来源于灰色系统理论,利用已知信息确定未知信息,对样本量没有严格的要求。灰色评价的关键在于灰色关联度分析,利用各评价对象序列的曲线形状与最优序列的曲线形状之间的关联度大小对被评价对象进行比较,关联度越大,说明曲线形状越接近最优序列,灰色评价的流程如图2所示。
最优序列一般选取各指标的最佳值,设为x0={x01,x02,…,x0m},则xi与x0关于第j项指标的关联系数为
ξi(j)=
(17)
式中,ρ为分辨系数,ρ∈[0,1],一般取0.5。
第i个方案与最优序列的加权关联度为
(18)
加权关联度可表征各地区总风光资源水平。
1.3 我国风光资源评估结果及分析
1.3.1 指标权重计算结果分析
基于上述的风光资源评价指标体系及权重计算方法,对2017年我国30个省的风光气象数据进行分析,数据来源于中国气象数据网。基于熵权-复相关系数-序关系分析的主客观组合权重法得到各指标权重,结果如表1所示,其中一级指标的总权重为其所有二级指标的主客观权重之和。从表中可知,复相关系数法确定的组合客观权重可减小指标间信息重复的影响,如指标有效风速时数通过复相关系数法有效降低了客观权重。由式(1)可知,指标平均风速是评价风电资源的主要因素,但其客观权重较低,通过主客观组合权重可提升其权重。从最终的主客观组合权重可以看出,基于最小二乘优化的权重组合方式可以平衡主客观权重,使评价结果更加科学合理。
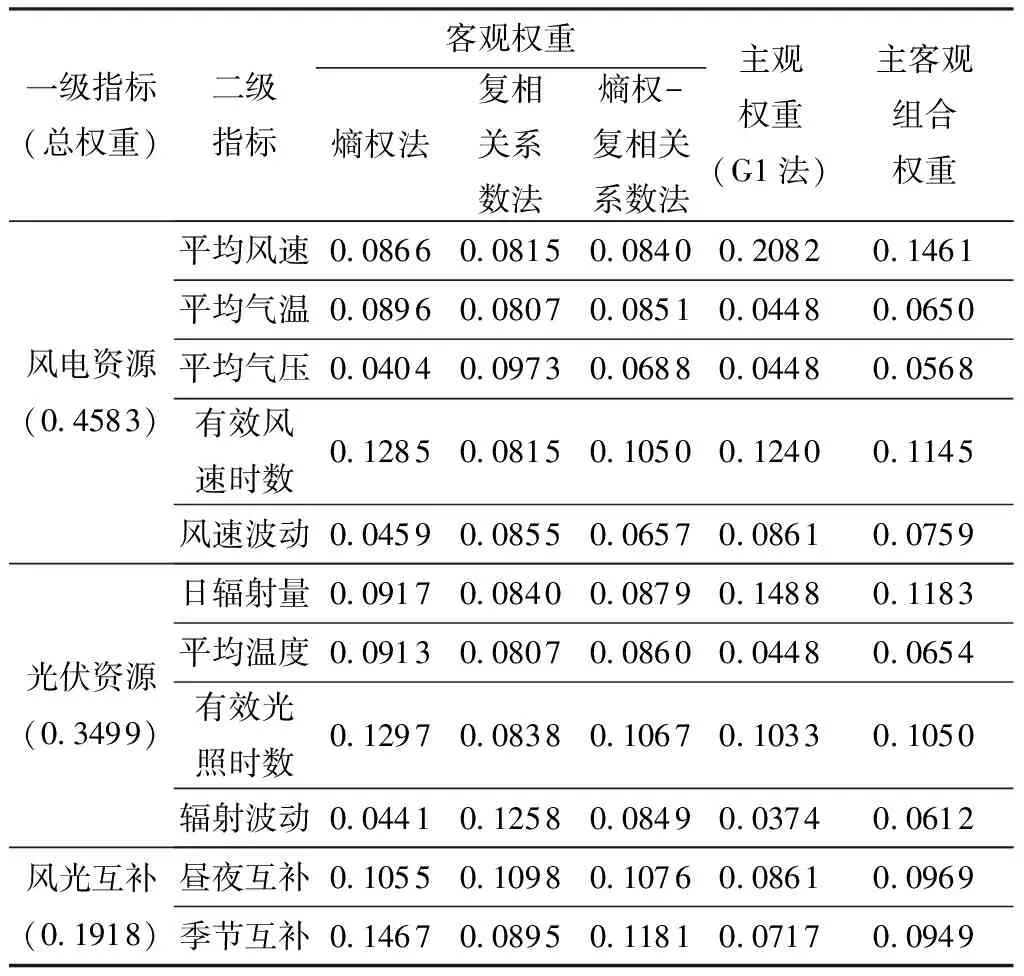
表1 风光资源评价指标权重
1.3.2 模糊评价结果分析
根据已求得的主客观组合权重,一级指标的权重记为A,风电资源、光伏资源和风光互补的二级指标权重分别记为A1、A2和A3。然后根据隶属度函数确定各二级指标的隶属度值,记为V1、V2和V3,分别是评价风电资源、光伏资源和风光互补的单因素隶属度评价矩阵。采用加权平均型的模糊算子进行模糊评价,即
(19)
式中:B1、B2、B3和C分别为风电资源、光伏资源、风光互补及总风光资源的模糊评价向量。
以北京为例,根据式(14)计算隶属度V1、V2和V3,代入式(19)得到:
B1=[0.148 9 0.938 9 0.622 2 0.585 6 0.141 9],
B2=[0.051 7 0.363 0 0.848 9 0.831 4 0.416 9],
B3=[0.310 2 0.785 8 0.766 4 0.370 9 0.078 6],
C=[0.145 8 0.546 1 0.874 3 0.647 2 0.226 0]。
根据最大隶属度原则可判断北京风电资源、光伏资源、风光互补及总风光资源的模糊评价等级分别为较差、一般、较差和一般。依次对其余省份进行模糊评价,得到我国30个省的总风光资源模糊评价等级,如图5所示。由图中可知,总风光资源评价等级是好的有内蒙古、海南,差的有重庆,评价等级集中在较差、一般和较好上,属于差和好等级的省份较少,结果符合正态分布,说明评价模型较为客观。风电资源、光伏资源、风光互补评价等级结果与总风光资源的结果类似,具体评价等级如表2所示。
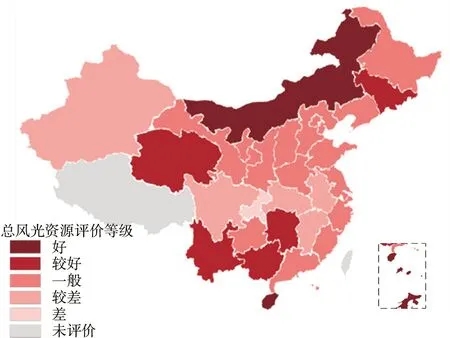
图5 中国30个省的风光资源模糊评价等级

表2 我国不同地区的风光资源模糊评价结果
1.3.3 灰色评价结果分析
先根据各指标标准化后的最优值确定最优序列,即越大越优型取1,越小越优型取0;然后计算各省各指标与最优序列的关联系数ξN×M;最后将前面求得的主客观组合权重代入式(18),得到各省的加权关联度,以此对各省的风光资源水平进行评价,结果见图6。从图中可知:云南、内蒙古与最优序列的关联度最大,说明其风光资源总体水平最好;湖北、安徽的关联度最小,说明其风光资源总体水平最差;从灰色评价结果可以清晰看出各省风光资源水平的大小。
图6 中国30个省的风光资源灰色评价结果
从图5、图6可以看出:对于大多数省份来说,两种评价方法的结果基本相同,但个别省份的结果有差异,如云南的模糊评价等级为较好,灰色评价的关联度却最高,这是由于模糊评价是通过划分等级来评价,灰色评价是通过和最优序列的关联度来评价,两种评价方法的思想不同,个别评价对象的结果会有差异,特别是在模糊评价相邻等级的评价对象上。
2 独立微电网的电源优化配置模型
在独立微电网的电源优化配置过程中,需要考虑两个基本问题:微电网场景模型和电源容量优化模型的建立。对于微电网的场景模型,当前国内外研究大多是基于历史数据或典型日场景来建立的,电源配置结果只是针对历史场景的最优配置,对风光出力的随机场景的适用性无法保证。因此,本文采用基于GAN的随机场景模拟生成法和基于K-中心点的场景聚类消减的场景分析方法,从历史场景中学习特征并生成新的场景,再聚类出典型场景,以解决考虑风光出力随机性的微电网电源容量优化配置问题。
关于电源容量优化模型的研究较为成熟,本文建立典型的考虑经济性、供电可靠性、环保性的多目标优化模型。
2.1 基于场景分析法的微电网场景模型
2.1.1 基于GAN的风光场景模拟生成法
GAN自2014年被提出后,已广泛运用在图像生成、场景生成、视频预测等领域[20],其数据无需服从特定分布,可自动学习真实数据的分布,可用于考虑风光出力随机性的风光场景模拟生成中[21]。
GAN通过神经网络自动学习特征,理论上可以逼近任何分布,其由两个深度学习模型组成,包括生成模型G和判别模型D,框架如图7所示。
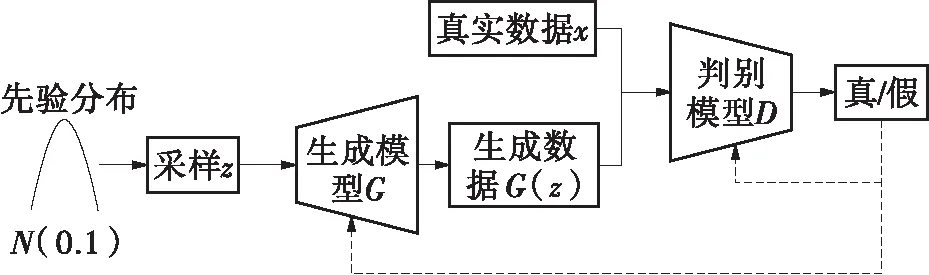
图7 GAN框架结构
生成模型G从已知分布采样生成数据G(z),其分布记作pg(z),该分布应该尽量逼近真实数据的分布pdata(x)。判别模型D的输入包括真实数据x和生成数据G(z),输出是一个概率值(0~1),该值越大,代表输入数据是真实数据的概率越大。
生成模型G和判别模型D实质上是两个对抗的神经网络,形成二人零和博弈,是一个极小极大化问题,其目标函数表示为
Ez~pg(z)[ln(1-D(G(z)))]
(20)
式中,第一项Ex~pdata(x)[lnD(x)]表示对真实数据进行判别,第二项Ez~pg(z)[ln(1-D(G(z)))]表示对生成数据进行判别。
判别模型D的目的是使式(20)最大,第一项最大时,D(x)→1,表示真实数据为真的概率接近1;第二项最大时,D(G(z))→0,表示生成数据为真的概率接近0。生成模型G的目的是使式(20)最小,其中第一项为常数,因为生成模型不影响真实数据;第二项最小时,D(G(z))→1,表示生成数据为真的概率接近1。两者互相博弈对抗,经过足够的训练,达到纳什平衡,判别模型的输出为0.5,无法判断是真实数据还是生成数据,则认为生成模型可以以假乱真。
2.1.2 基于改进K- 中心点聚类的场景消减
K- 均值聚类算法是典型的基于划分的无监督聚类算法,由于其利用簇内数据点的均值作为下一次更新的聚类中心,所以收敛速度较快,但对孤立点比较敏感,会造成鲁棒性和准确性不好的问题。K-中心点聚类可以克服对孤立点敏感的缺陷,具有较强的准确性和鲁棒性,但其时间复杂度为O(n2),对于数据集较多的聚类,时间代价太大。文献[22- 23]对K- 均值和K- 中心点聚类算法进行了对比,验证了K- 中心点聚类算法在含孤立点的情况下具有更强的鲁棒性,因此K- 中心点聚类算法更适用于解决本文所研究的随机性较强的风光场景聚类问题。基于中心点划分(PAM)算法是一种典型的K- 中心点聚类算法,本文采用PAM算法对聚类中心进行更新,并通过改进初始聚类中心[24]来减少计算时间,实现风光场景的快速消减,其步骤如下:
2)根据到聚类中心序号差最小的原则,分配每个场景到距离最近的聚类中心。
3)更新聚类中心。根据使目标函数式(21)最小原则,参考PAM算法,用本簇中的非聚类中心场景依次替代聚类中心,以替代后让式(21)变小最多的场景作为新的聚类中心。
(21)
式中,d(ui,uj)表示场景ui与uj的欧几里得距离。
4)根据步骤2)重新分配每个场景到新的聚类中心,若式(21)变小程度小于设定值或迭代次数达到上限,则转步骤5),否则返回步骤3)。
5)根据聚类后每个簇内场景的个数除以总的场景数得到每个聚类场景的概率。
2.2 独立微电网的电源容量优化模型
本文建立考虑经济性、供电可靠性和环保性的多目标函数,并基于场景分析法考虑风光随机性,用停电惩罚成本表示供电可靠性、能量浪费惩罚成本表示环保性,即通过引入惩罚因子将多目标问题变为单目标问题。
2.2.1 目标函数
同时考虑经济性、供电可靠性和环保性的目标函数表达式如下:
minC=min(Cinvest+Closs+Cwaste)
(22)
式中,Cinvest为年投资成本,Closs为年停电惩罚成本,Cwaste为年能量浪费惩罚成本。
考虑经济性时,一般是考虑全寿命周期内的成本现值,本文对规划周期进行等年值计算,用年投资成本Cinvest表示,其表达式为
Cinvest=Cinitial+CO&M
(23)
年等值初始投资成本Cinitial由各设备的初始投资成本乘以投资成本资金年回收系数得到,即
Cinitial=(NPVIPV+NWTIWT+NbatIbat)γ
(24)
式中,NPV、NWT和Nbat分别为光伏阵列、风力发电机和储能装置的配置台数;IPV、IWT和Ibat分别为单台光伏阵列、风力发电机和储能装置的初始安装成本;γ为投资成本资金年回收系数,代表已知现值(发生在第一年初)和Y个等年值(发生在第1,2,…,Y年末)之间的等效关系,其计算公式参见文献[17]。
年运行维护成本CO&M由各设备的维护运行费用构成,其表达式为
(25)
式中,KPV、KWT、Kbat分别为各设备运行单位能量的运行维护成本;PPV(t)、PWT(t)、Pbat(t)分别为各设备在第t个调度时段的功率,储能电池功率Pbat(t)在充电时为正,在放电时为负;T为总的调度时段的个数;Δt为调度时段时间间隔。
考虑供电可靠性时,对于独立微电网,仅靠内部电源供电时,会出现部分负荷因得不到满足而被切断。为了保证可靠供电,进行电源配置优化时,在目标函数中引入年停电惩罚成本,即
(26)
式中:Kloss为惩罚因子,表示单位发电量不足的惩罚成本,其值越大,表示该项的惩罚作用越大;Ploss(t)为第t个调度时段的功率缺额,
Ploss(t)=Pload(t)-[PPV(t)+PWT(t)-Pbat(t)]
(27)
Pload(t)为第t个调度时段的负荷功率。
为了避免因过高弃风光率造成的能量浪费,在目标函数中加入考虑环保性的年能量浪费惩罚成本:
(28)
式中:Kwaste为惩罚因子,表示单位能量浪费的惩罚成本;Pwaste(t)为第t个调度时段的功率盈余,
Pwaste(t)=NPVPPV1max(t)+NWTPWT1max(t)-
PPV(t)-PWT(t)
(29)
PPV1max(t)、PWT1max(t)分别为第t个调度时段单台光伏阵列、单个风力发电机由当地光照等自然条件决定的最大发电功率。
2.2.2 约束条件
约束条件包括各电源的功率上下限约束和储能电池电量约束,且在考虑储能电池约束时要同时满足电力供需平衡和尽可能减少弃风光率。
(1)功率上下限约束为
0≤PPV(t)≤NPVPPV1max(t)
(30)
0≤PWT(t)≤NWTPWT1max(t)
(31)
-Pbat1NdisNbat≤Pbat(t)≤Pbat1NchNbat
(32)
式中:Pbat1Ndis为单个储能电池的额定放电功率,其值为单个储能电池的额定功率乘以放电效率;Pbat1Nch为单个储能电池的额定充电功率,其值为单个储能电池的额定功率除以充电效率。
(2)储能电池电量约束为
E(t)=E(t-1)(1-δΔt)+ΔtPbat(t)
(33)
SOC,minNbatEbat1N≤E(t)≤SOC,maxNbatEbat1N
(34)
式中,E(t)为储能电池系统在第t个调度时段结束时的剩余电量,δ为储能电池每小时的自放电率,Ebat1N为单个储能电池的额定容量,SOC,max、SOC,min分别为储能电池剩余电量百分比的上、下限。
2.2.3 模型线性化及求解
本文计及储能电池的运行费用时,用Pbat(t)表示储能电池功率,充电为正,放电为负。这可使约束条件不含布尔量和正数变量相乘的情况,且是线性的,但也使目标函数式(25)中含有绝对值项且是非线性的,因此需要对式(25)的绝对值项进行线性化,可以通过对需要绝对值的变量分离出正数和负数部分,即增加两个非负变量,本文把储能电池的功率Pbat(t)分为充电功率Pbatch(t)和放电功率Pbatdis(t),要满足约束:
(35)
(36)
Pbat(t)=Pbatch(t)-Pbatdis(t)
(37)
且将目标函数式(25)中的绝对值项改为
约束条件中式(32)变为
(38)
本文采用优化软件GAMS进行建模求解,该软件允许模型的描述独立于求解算法,建模过程简单,并可调用多种求解器进行求解。本文调用专门求解线性规划问题的CPLEX求解器,对所建立的线性规划模型进行求解。
本文建立的基于风光资源特性的独立微电网电源配置方法的流程图如图8所示。
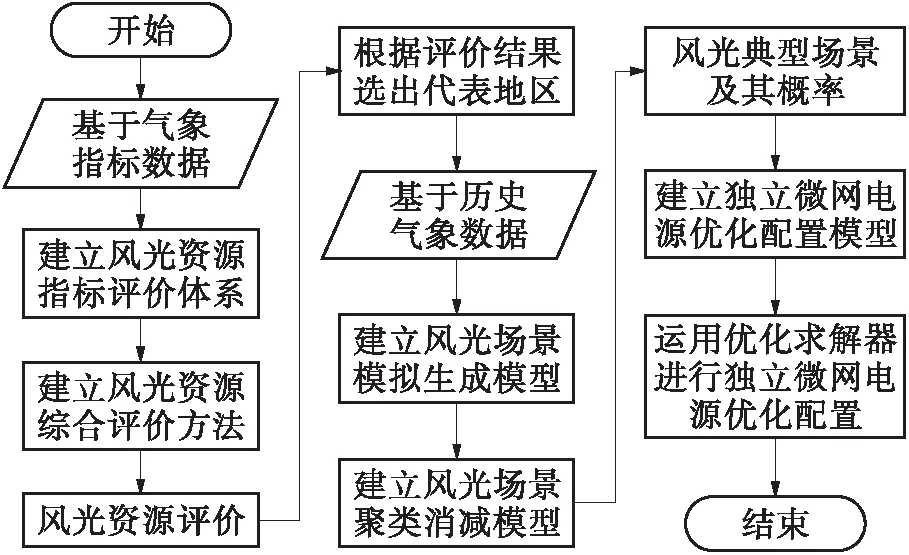
图8 本文独立微电网电源优化配置方法的流程图
3 算例分析
3.1 算例条件
调度时段时间间隔Δt取1 h,故年总调度时段T为8 760;设备使用寿命及项目规划期Y均为20,投资成本资金年回收系数γ取0.060 2。储能电池的额定容量Ebat1N为6 kW·h,充电和放电效率为0.88,自放电率δ为0.01,剩余电量百分比的上下限SOC,max、SOC,min分别为0.9和0.2。为了保证负荷供电需求并降低弃风光率,惩罚因子Kloss和Kwaste都应取一个很大的正数。各发电设备和储能电池参数如表3所示,采用的典型年负荷曲线如图9所示。
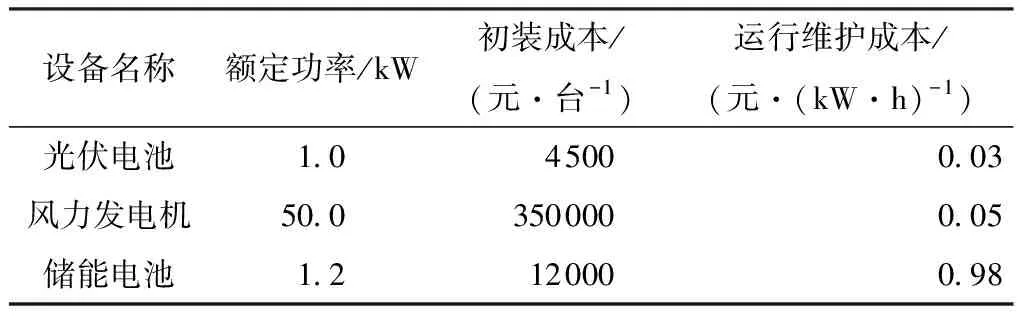
表3 发电设备和储能电池参数
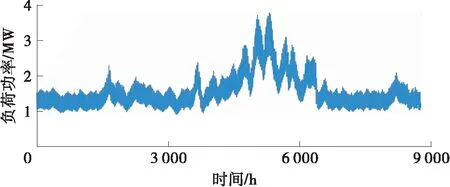
图9 独立微电网典型的年负荷曲线
3.2 基于典型场景的电源配置结果
根据典型年的风速、辐射强度等气象数据,参考文献[17]计算风光出力。以每个月选取一天24 h的风光出力作为一个场景,从典型年中选取10 000个场景作为训练集,用GAN算法模拟生成1 000个场景,采用改进的K- 中心点聚类算法削减至10个场景。最后根据所建立的电源容量优化模型进行求解,以内蒙古为例,得到的电源配置结果如表4所示。
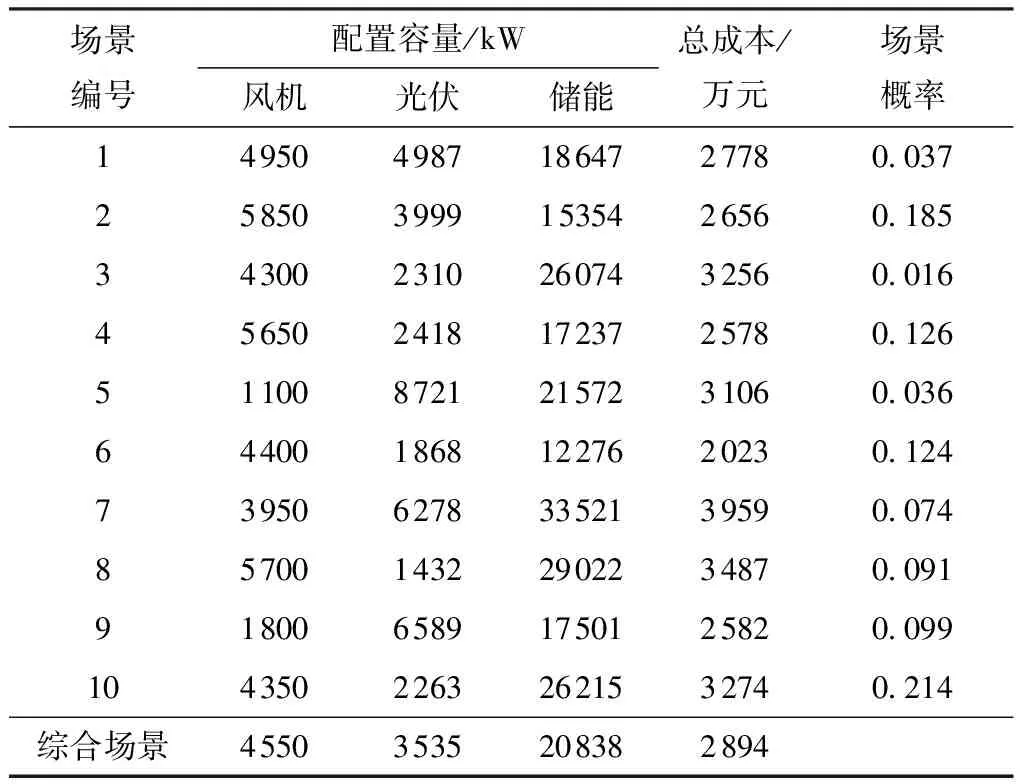
表4 内蒙古不同场景的电源配置结果
根据每个场景配置结果和场景概率加权得到综合场景的配置结果。内蒙古综合场景的风光配置容量分别为4 550、3 535 kW,占比分别为56%、44%。从表4可以看出,大部分场景风机的配置容量都比光伏多,这是因为内蒙古地区的风力资源较为丰富,并且风机夜晚也能发电,与负荷匹配的有效时间更长。以概率最高的场景10为例,选6月、12月典型日电源发电功率配置结果,其风机、光伏、储能的功率曲线如图10所示。
为了验证本文提出的基于CPLEX求解电源优化配置方法的准确性和快速性优势,将CLPEX算法与遗传算法(GA)[17]、内点法(IPM)[25]进行对比。其中,GA为随机搜索算法,其收敛到全局最优解的概率和运算时间均随着种群的增加而增加,由于本文考虑了12个月的典型日数据,为了同时保证速度和质量,设定GA的种群数量为300,并运行20次,每次的初始解都相同,选最优的一次解;IPM是在可行解空间中有选择地进行迭代,并考虑可行解的边界,适用于求解规模较大的最优化问题。基于场景10,采用上述这3种算法进行优化配置,结果如表5所示。
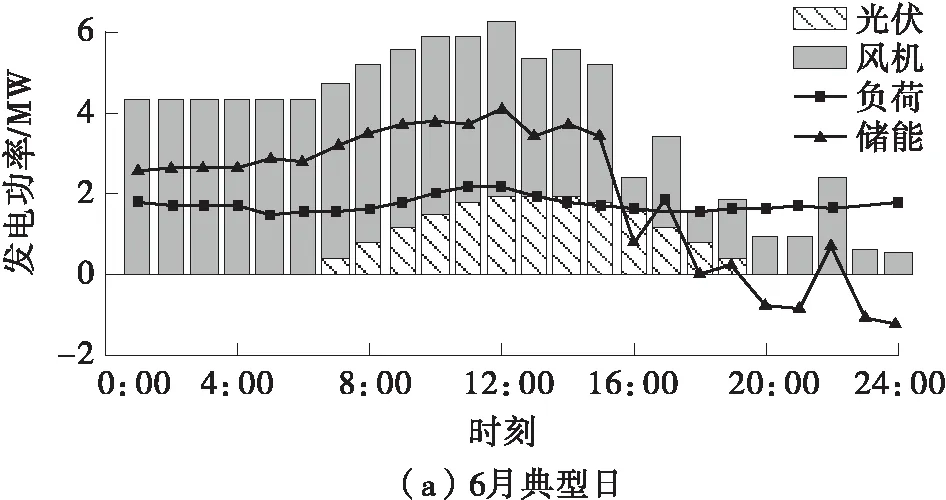
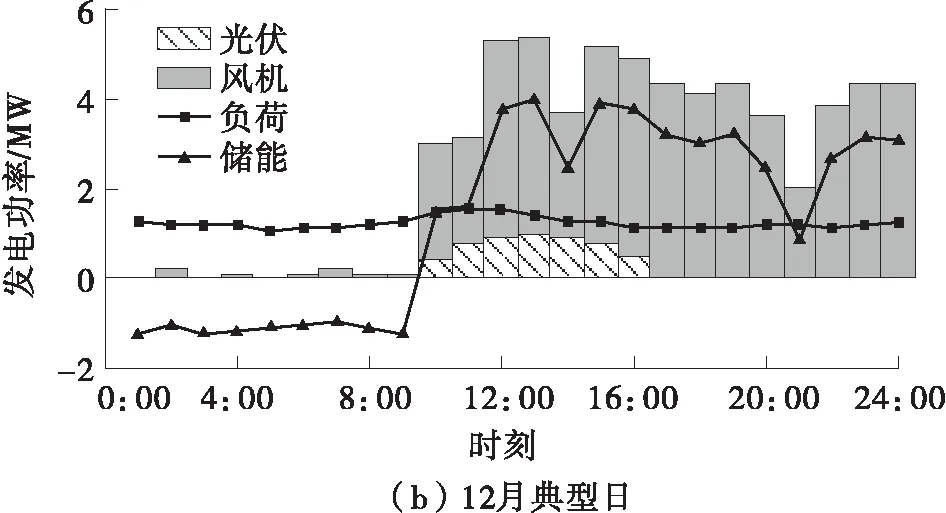
图10 内蒙古电源发电功率配置结果
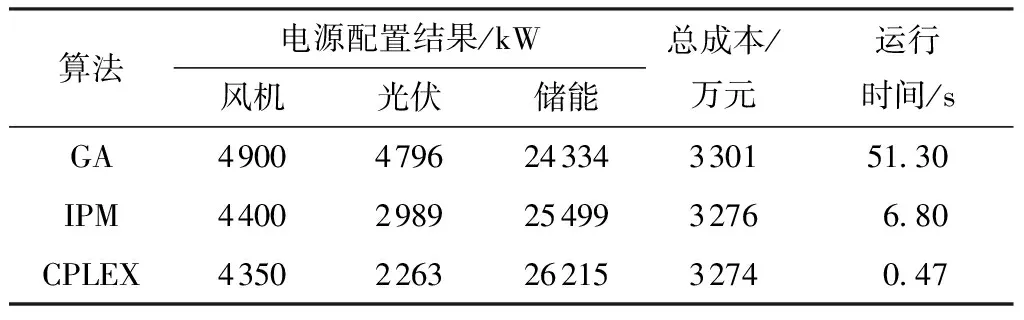
表5 3种算法的优化配置结果
从表5可以看出:采用GA算法得到的电源配置结果的费用比CPLEX算法多,且运行时间是CPLEX算法的几百倍,说明GA算法收敛的速度较慢且收敛到全局最优解的概率较低;而IPM算法的费用很接近CPLEX,但运行时间是CPLEX十几倍。因此可以看到,CPLEX算法在解的准确性和快速性上都有较好的优势。
3.3 风光资源指标对电源配置的影响
为了体现所选的代表地区对不同情况的覆盖,根据模糊评价等级及灰色关联度选出内蒙古、海南、甘肃、北京、湖北作为代表地区,涵盖了模糊评价结果各类指标的不同等级,且灰色关联度的分布尽量均匀。图11为代表地区的风电资源、光伏资源、风光互补及总风光资源水平的模糊评价等级的雷达图。从图中可以看出,内蒙古的4个指标都是较高的,海南是风光互补好、光伏资源一般,甘肃是风电资源一般、光伏资源好,北京的4个指标都是中等的,湖北的4个指标都是较低的。
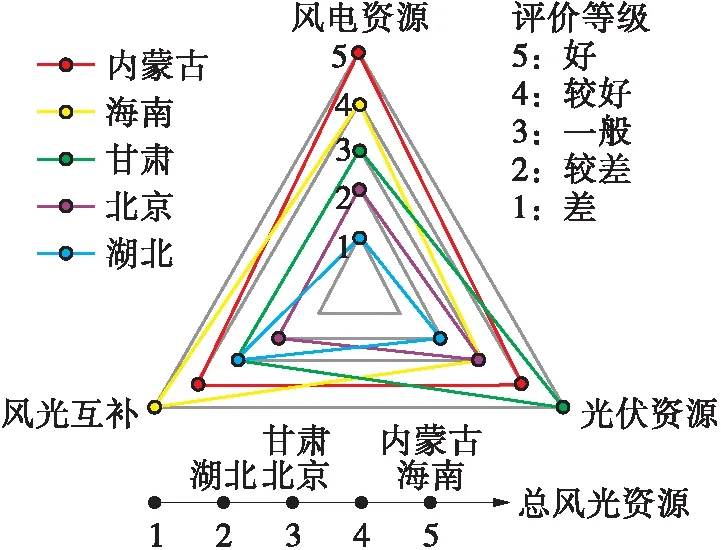
图11 风光资源指标模糊评价等级雷达图
对代表地区依次进行基于风光场景的电源容量配置优化,以综合场景的配置方案代表每个地区的最终配置结果,如表6所示,其中风光比例为风光发电机组配置容量的占比。
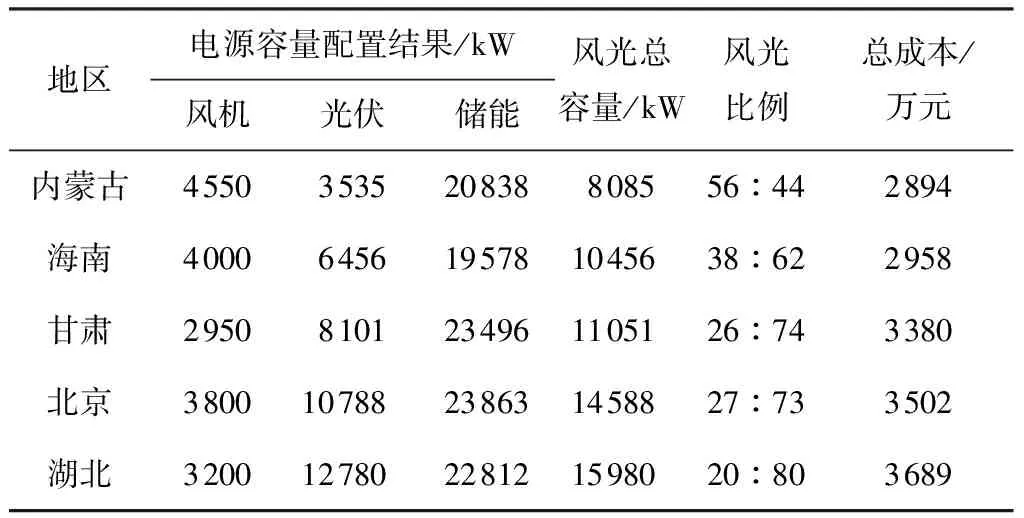
表6 代表地区的电源配置结果
从图11和表6可以看出:
(1)总风光资源评价等级越高的地区,其风光发电机组配置的总容量越低,总成本也越低。原因在于,总风光水平越高,单位容量风机或光伏出力越大,在满足相同负荷需求时,配置较小的容量即可满足电力平衡,因此总成本也越低。
(2)风电资源指标评价等级越高的地区,其风机配置容量占比越高。风电资源指标评价等级与风机配置容量占比有相关关系,而光伏资源指标评价等级与光伏配置容量占比没有明显的相关关系。原因在于,当前风机单位容量的初装成本比光伏低,且风机的有效发电时间和负荷更匹配,造成风机发电的成本更低,因此风电资源指标对配置结果的影响较大。但随着光伏技术的进步,其发电成本下降潜力较大,以后光伏资源指标对配置容量结果的影响会越来越明显。
(3)风光互补指标评价等级越高的地区,储能配置容量越低。原因在于,风光互补指标越高,风机平衡光伏因日特性和季节特性引起的出力波动的效果越好,对储能平衡发电峰谷的需求越小,储能配置容量越低。
从灰色评价结果可以得到关于总体配置情况的结论:代表地区与最优序列的关联度越高,其风光发电机组配置的总容量越低,总成本越低,如表7所示。灰色评价得到的结论与模糊评价得到的结论一样,这验证了评价模型及电源配置优化模型的有效性和合理性。
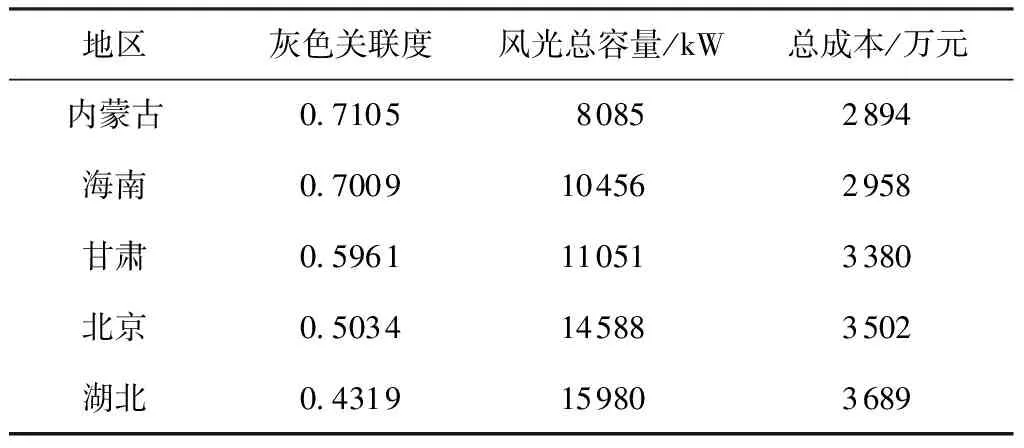
表7 灰色关联度与风光总容量及总成本的关系
根据上述分析,为了更加清晰地表示风电资源指标评价等级与风机配置容量占比的关系,对我国不同风电资源指标评价等级的其他省份进行电源配置,其风机配置容量占比如图12所示。从图中可知,风电资源指标评价等级越高,风机配置容量占比越高,这与前面的分析结果一致。根据图12可得到我国风电资源指标评价的5个等级(差、较差、一般、较好、好)对应的风机配置容量占比区间分别为[20%,25%]、[25%,30%]、[30%,35%]、[35%,45%]、[45%,60%]。
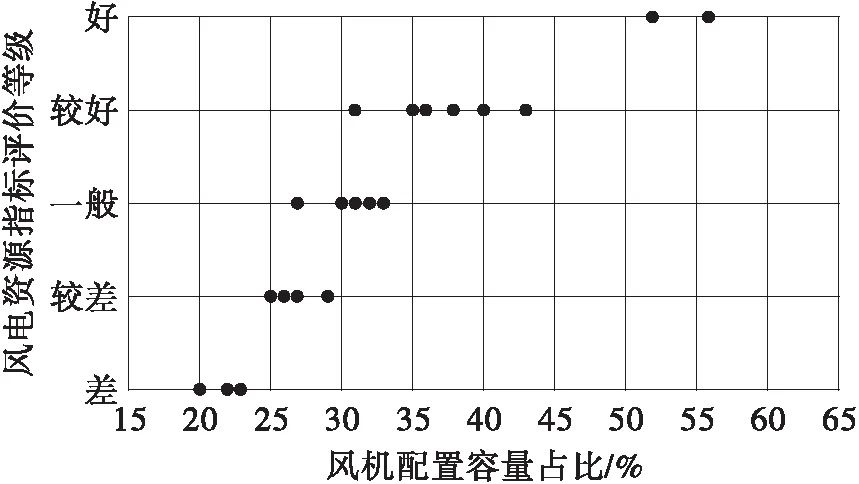
图12 风电资源指标评价等级与风机配置容量占比图
4 结论
为了使电源容量配置更加符合实际,需要根据实际风光资源情况来进行微电网的电源容量配置,本文提出了基于风光资源特性的独立微电网的电源优化配置方法。该方法构建的风光资源指标体系能合理地评价不同地区的风光资源特性;提出的基于熵权-复相关系数-序关系分析的主客观组合权重法,同时考虑了客观和主观权重,通过基于最小二乘法的组合方式,可以获得更加科学合理的评价指标权重;模糊评价可以获得各地区各类指标的评价等级,全面评价各地区的风光资源水平,而灰色评价可直观获得各地区风光资源的排序;基于GAN场景模拟生成和改进K- 中心点场景聚类削减的场景分析法,能有效考虑不同风光出力的随机场景,使得电源配置更加合理;对我国代表地区进行算例分析,得到的不同地区的电源配置方案符合当地风光资源特性,验证了所提指标评价体系、评价方法以及电源优化配置模型的合理性;分析风光资源指标对电源配置的影响,获得我国风电资源指标评价等级与风机配置容量占比的对应关系,可作为参考。本文所提出的基于风光资源特性的电源优化配置方法可用于指导独立微电网的电源规划。
