基于统计感知的大数据处理与分析课程设计研究
2021-08-07何玉林尹剑飞黄哲学
何玉林,尹剑飞,黄哲学
(深圳大学计算机与软件学院,深圳 518060)
0 引言
在2015年8月份国务院下发的《促进大数据发展行动纲要》中明确指出[注]http://www.gov.cn/zhengce/content/2015-09/05/content_10137.htm:创新人才培养模式,建立健全多层次、多类型的大数据人才培养体系。在教育部公布的《2019年度普通高等学校本科专业备案和审批结果的通知》中显示[注]http://www.gov.cn/zhengce/zhengceku/2020-03/05/content_5487477.htm,截止到2019年10月份,全国高校新增设数据科学与大数据技术专业点196个。研究专门针对大数据专业人才培养的课程内容设计是非常必要的,对大数据战略的具体实施具有重要的现实意义和社会价值。
深圳大学计算机与软件学院于2017年启动大数据特色班的建设,2018年开始进行大数据特色班的招生与授课,其中《大数据处理与分析》被列特色班的核心课程。当前,国内数据科学与大数据专业开设与大数据处理和大数据分析相关课程的兄弟院校还有华中科技大学的《大数据分析与处理》、中国人民大学的《非结构化大数据分析》、山东大学的《大数据管理与分析》等。不同高校对课程内容的设计不尽相同,所采用的教材也不一样,因此,本文试图设计一套能够符合数据科学与大数据技术专业培养要求的、同时又能够体现深圳大学大数据系统计算技术研究特色的《大数据处理与分析》课程体系。
大数据作为统计学、数学和计算机三大学科的紧密整合,统计学在大数据的技术体系结构中占据重要的位置。因此,在充分借鉴兄弟院校课程设计经验的基础之上,结合深圳大学计算机与软件学院大数据所多年从事大数据系统计算技术相关领域研究取得的科研成果,我们给出了一套以大数据随机样本划分模型(Random Sample Partition,RSP)[1]为基础的《大数据处理与分析》课程设计方案,让大数据统计感知[2]的思想贯穿大数据存储处理、大数据预处理、大数据切分处理、大数据降维处理、大数据统计分析、大数据分类分析和大数据聚类分析七部分的教学内容。
1 课程教学内容设计
在介绍《大数据处理与分析》课程教学内容设计之前,首先明确该课程的教学目的是培养具备初级大数据计算技术运用能力的本科生,以前期课程《大数据计算原理和技术》和《数据挖掘导论》为基础,通过后续课程《大数据应用概论》和《统计抽样理论与方法》的学习强化对本课程知识点的进一步掌握和理解,使学生在日后的工作中能够对实际的大数据计算问题提出行之有效的解决方案。
大数据处理与分析应该包含两部分的内容:大数据处理强调数据层面的操作方法,大数据分析强调算法层面的训练模式。处理注重更深层次的数据挖掘,分析注重有针对性的算法训练。因此,我们设计如图1所示的《大数据处理与分析》课程教学内容体系。
(1)大数据存储处理:主要讲述分布式存储系统是如何对大规模数据集进行存储和管理的[3],包括数据分布、复制与一致性、容错机制和可扩展性。本部分内容引出Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)在处理大数据的分布式存储时没有考虑HDFS数据块之间的概率分布一致性;
(2)大数据预处理,主要讲述针对大数据的缺省值处理、异常点挖掘,以及属性一致性处理[4],即如何将经典的缺省值插补方法、异常点检测方法、连续值属性离散化方法、以及离散值属性连续化方法应用在数据分布式存储的场景中,当大数据被表示成批量的数据块时,数据块之间的概率分布一致性是如何影响上述对大数据的预处理操作的;
(3)大数据切分处理:主要讲述如何基于HDFS数据块获得与大数据保持概率分布一致性的RSP数据块[5],包括RSP的定义、RSP的判定、数据块分布一致性的判定[6]、大数据复杂性的定义,以及如何基于数据复杂性确定样本规模,本部分内容是本课程的核心重点,是开展后续大数据分析的基础;
(4)大数据降维处理:主要讲述分布式存储环境下如何对大规模数据进行特征选择和属性抽取。为了处理不同数据块对应的降维之后属性不一致问题,我们重点讲解在不同的RSP数据块上采用观测点策略[7]的降维处理机制,即将原始空间的多维数据转换为距离空间的一维数据;
(5)大数据统计分析:主要讲述如何对大数据进行概率密度函数估计的问题,因为概率密度函数是研究随机变量数学属性(期望、方差、信息熵等)的重要统计工具。基于大数据随机样本划分模型,重点讲解增量式的大数据概率密度函数估计方法[8]和集成式的大数据概率密度函数估计方法;
(6)大数据分类分析:主要讲述如何基于RSP数据块构建针对大数据的有监督学习模型[9],以神经网络和贝叶斯分类器两种典型的有监督学习模型为例,详细地讲解增量神经网络、增量贝叶斯分类器、集成神经网络、以及集成贝叶斯网络的构建方法,并对大数据有监督学习中涉及到的不平衡分类问题以及半监督学习问题进行简述;
(7)大数据聚类分析:主要讲述如何基于RSP数据块构建针对大数据的无监督学习模型,以K-means和高斯混合模型(Gaussian Mixture Model,GMM)两种典型的无监督学习模型为例,详细地探讨集成K-means和集成GMM的构建方法,并对一种新型的适用于大数据无监督学习问题的自动聚类算法I-nice进行详述。
上述七部分的教学内容全部围绕大数据的处理与分析展开,在课程教学开展过程中,为加深学生对理论知识的理解和掌握,每一部分的教学内容均对应专题实验以锻炼学习的实际操作能力。
2 课程应用案例介绍
《大数据处理与分析》课程准备了一个实际应用案例作为对学生理论学习的扩充以及课程学习成果的检验:电信用户通话记录分群。自2017年深圳大学计算机与软件学院大数据所与中国电信某省公司签署战略合作协议以来,我们收集了海量的电信用户数据,选取2020年05月01日至2020年06月30日约2TB的全省通话记录数据,训练一个能够将通话分为诈骗电话、骚扰电话、营销电话,以及正常电话四种类型的学习模型,用以对新的通话记录进行类型甄别,其中一条通话记录数据采用如图2所示的74个字段进行描述。
为了实现上述的电信通话记录分群任务,首先需要对获取的电信大数据进行如下的处理操作:
3 课程教学效果分析
本课程于2019-2020学年第一学期首次给深圳大学大数据特色班讲授,选课人数30人,每周4学时(2节理论课和2节实验课)。本学期针对该课程总共设置了5次课后实验、3次课堂测试、1次期中考试、和1次期末大作业,除去4人放弃本课程的学习之外,其余26人的成绩分布下图3所示:
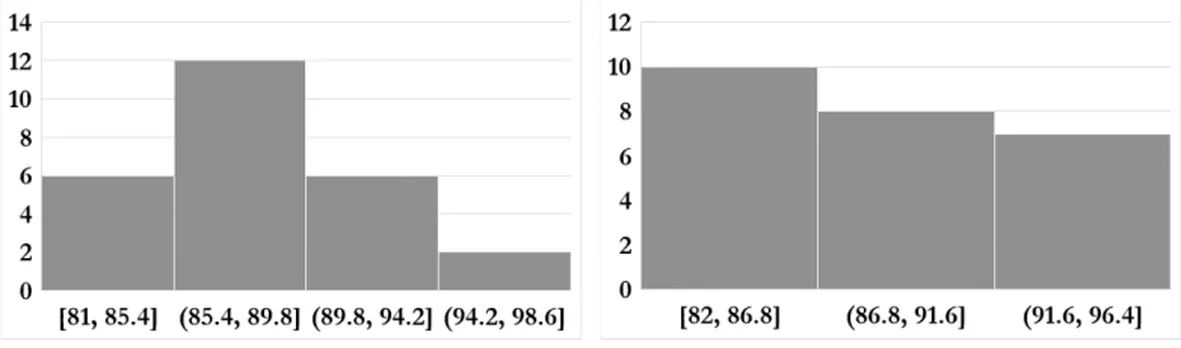
(a)实验一成绩分布(b)实验二成绩分布
从图3我们可以清楚地观察到大数据特色班的所有学生(放弃本课程学习的除外)都能够较好地完成课后实验、随堂测试、期中考试和期末大作业,这表明《大数据处理与分析》课程内容的设计是能够满足大数据特色班学生认知需求的,符合数据科学与大数据技术专业的培养要求。图4和图5分别给出了《大数据处理与分析》课程教学测评结果和测评结果分析情况,从图4中可看出大数据特色班的学生对本课程的教学满意度达到了98.45%,这表明学生在本课程的学习中确实做到了“学有所得、学以致用”,符合了学生对大数据系统计算技术知识的理解与要求。

图4 《大数据处理与分析》课程教学测评结果

图5 《大数据处理与分析》课程测评结果分析
4 结语
在当前《大数据处理与分析》课程体系结构尚不完善的情况下,对于如何开展本课程的本科教学工作,结合作者研究团队获得的关于大数据系统计算的最新研究成果,提出了一种以大数据统计感知思想为切入点、以大数据随机样本划分模型为基础的课程设计方案。同时,结合有针对性的应用案例将课程知识点与实际应用有机结合,在重视课程设计的理论性基础上,增强教学内容的实用性。该方案为今后大数据处理与分析课程的设计提供了一条具有较高可操作性的思路,具有较强的方法论借鉴意义。
