基于数据挖掘技术的高维数据降维处理
2021-08-07胡聪刘翠玲洪德华宫政
胡聪,刘翠玲,洪德华,宫政
(国网安徽省电力有限公司信息通信分公司,合肥 230041)
0 引言
随着国家“互联网+”行动计划、云计算和大数据战略深入推进,在“十三五”期间,国家电网公司建成规模庞大的信息化系统,企业进入全面的数字化转型阶段,信息系统的稳定运行以及日常的风险及时预警处置直接关系到电网的稳定运行[1-2]。
电网企业信息系统在运行过程中产生大量的日志信息,这些数据类型多样、产生速度快、其中的某些数据可能包含着与系统的运行状态相关的信息,信息系统中的数据具有典型的大数据特征[3-4]。一个应用系统的运行数据包含程序运行周期内发生的事件的相关信息,包括事件类型、发生时间、发生该事件的对象等[5-6]。对电力大数据的分析可以直观地展现电网的运行状态,利用流形学习方法对高维的电力大数据进行降维处理,可以解决高维电力大数据可视化的图元密集和图形重叠的问题,将数据清晰地展现,以便于直观的分析数据的价值[7-8]。
1 现状分析
目前电力企业已经全面开展数据价值挖掘工作,针对电力信息系统数据格式特点,围绕数据采集、数据处理、模型创建等方面开展相关的技术研究和应用,对海量信息进行分析处理,深层挖掘信息的潜在价值,并取得了一定成效[9-10]。随着信息化建设和应用不断深入,用户对高维数据价值挖掘的需求持续增长,用户范围从信息系统管理部门扩展到全业务,数据挖掘不能再只是面向单个信息系统,需要全面掌握数据状态,及时发现故障隐患,提高电力信息系统的智能化运维水平。
电力企业积累了海量的高维数据,为大数据挖掘工作奠定了基础。但电力企业信息系统主要从专业角度出发开展系统高维数据格式管理,信息系统中的数据内容、频度仅考虑了各专业当前自身业务需求,未考虑后期大规模数据分析应用和跨业务领域的需求,存在系统间高维数据标准不一致,以及数据缺失等数据质量问题,给日志数据价值挖掘带来困难。电力企业信息系统业务在逐步加宽,其业务支撑系统的复杂性也显著增加,当前支撑系统运维管理和监控系统只是从系统底层指标判断系统的运行状态,为其提供系统监控和服务,缺少对系统整体性能的评价和系统健康评价标准。
2 数据降维
通过对海量电网高维数据进行降维处理,将相似的文本收敛到可处理的量级,同时结合相关的半监督学习以及隔离森林算法对降维数据文件进行分类,设计数据分类模型算法。
2.1 总体架构
将多源异构数据进行初步整理,针对其中的多源模糊冲突信息,基于不精确推理理论的隔离森林异常检测分类技术,流形学习中的t-分布随机邻域嵌入(t-SNE)的非线性降维算法,在保持局部几何特征的前提下,对高维度的电网的大数据进行降维处理。由于t-SNE算法具有对非线性和高维度数据处理的能力,因此适应智能电网的多类型数据的融合分析处理的需求,为高维电网大数据可视化提供了良好的思路。基于t-SNE算法的高维数据处理架构如图1所示。
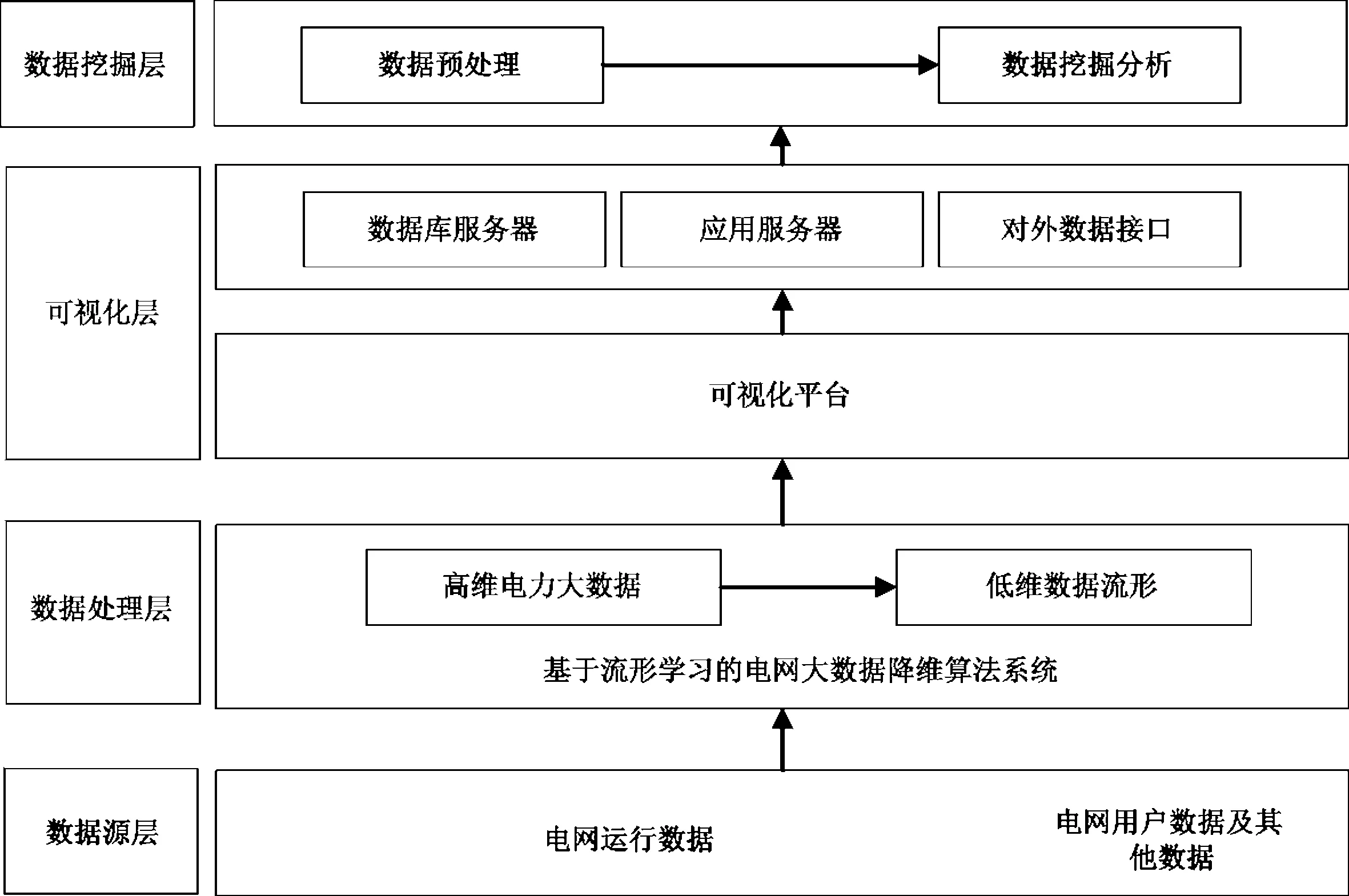
图1 高维数据处理架构
电力信息系统在运行过程中产生大量的高维数据信息,这些数据类型多样、产生速度快,其中的某些数据可能包含着与系统的运行相关的信息,电网运行数据具有典型的大数据特征。由于在电力信息系统的信息具有多源异构的特点,针对数据的异构性和多源性,分别对异构数据的信息抽取融合、多源数据融合冲突的融合,数据降维过程图如图2所示。

图2 数据降维过程图
2.2 日志时间关联挖掘
对融合的高维数据信息提取频繁序列模式,从日志信息中发现高维数据之间的关联性,构建日志信息序列,利用滑动窗口的特性,将序列分为时间上等宽的子序列,当活动时间窗口进入到下一时间间隔时,从中挖掘宽度为i的候选集,构建宽度为i的频繁集,再构建i+1的候选集,直到新的频繁序列为空。高维数据间的因果关系用因果矩阵表示,结合因果矩阵研究,形成基于滑动时间窗的高维数据日志关联挖掘模型。高维数据日志关联挖掘模型如图3所示。
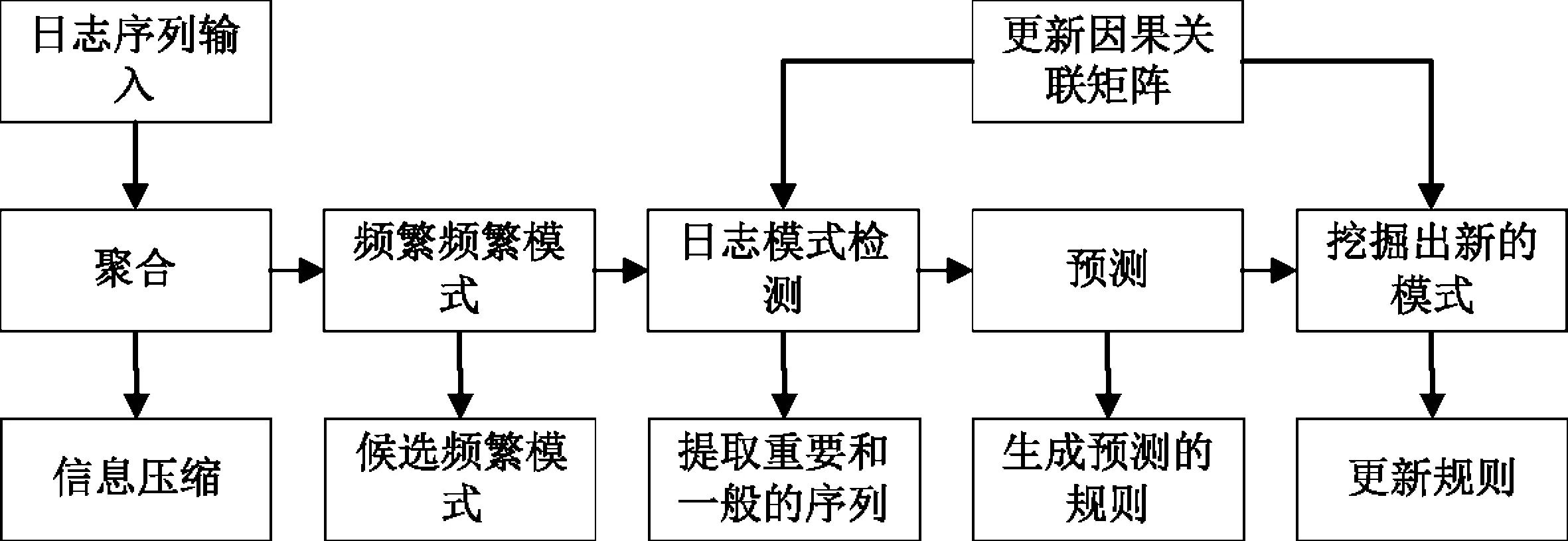
图3 高维数据日志关联挖掘模型
基于滑动窗口的高维数据日志关联挖掘模型,其阶段1即为日志数据聚合过程,按照时间序列将日志信息进行排序并标准格式化;阶段2是利用时间滑动窗口进行频繁模式的挖掘;阶段3是事件模式检测,从上一阶段挖掘到频繁序列模式集合之后,对集合中的序列进行关联性分析;阶段4是关联规则的预测阶段,这一阶段对关联规则进行预测生成预测规则;阶段5将挖掘出的新的关联模式补充道因果关系矩阵,并更新因果关联矩阵。经过这五个阶段挖掘得到的高维日志关联模式即为关联模式挖掘的结果。
2.3 算法设计
基于深度学习以及半监督学习的日志分析方法显得尤为重要,具有现实意义。以t-SNE模型为基础,对海量电网数据进行聚类处理,将相似的高维数据收敛到可处理的量级,同时结合相关的半监督学习以及深度学习对日志文件进行分类。高维数据异常检测分类流程如图4所示。
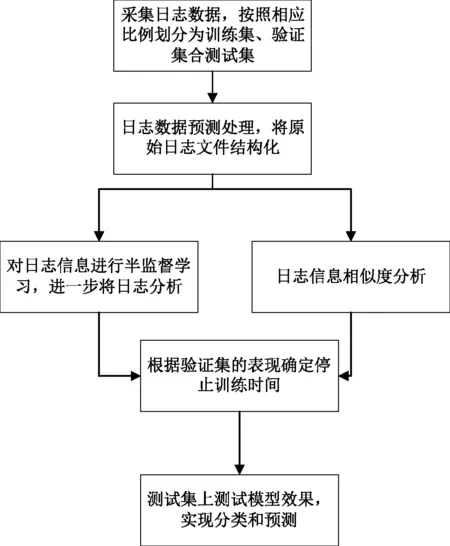
图4 高维数据异常检测分类流程
t-SNE向量:日志的量级较大,先对日志进行聚类处理,将相似的文本收敛到可以处理的量级,对所有重要子系统的日志进行文本清洗,同时引入词频和逆文档频率的建模方法对文档信息进行数学建模,得到一个语料库。然后将清洗后的日志信息在语料库中映射得到其对应的TF-IDF向量。
语义空间可视化:采用Skip-gram模型预测上下文目标词,从而最大化整个语料库∑(w,c)∈D∑wj∈ClogP(w|wj)。w为字典中的任意词;c为w的上下文词;D为从调度语料中抽取出的字典。模型每次从目标词的上下文选择n个词,并将其词向量映射到对应的TF-IDF向量作为模型的输入。接着使用Skip-gram模型来训练电网运行数据向量,并根据词向量构成句子向量进行文本分类衡量词向量的质量,优化训练词向量的迭代次数、维度以及调整训练模型及预料的大小。经过优化后的t-SNE向量作为LSTM模型的输入,并在二维语义空间进行语义化表示。
信息的半监督学习:首先对有标记的训练集学习生成一个随机森林,然后对未标记的训练集进行学习标注,标记过程中,样本的预测结果越一致表面置信度越高,最后取出置信度最小的M个样本,并把这类样本剔除,接着重新训练这颗随机森林,直到未标记训练集里的置信值都在置信阈值之内。
信息相似度分析:采用Jaccard算法来计算日志信息的相似度,Jaccard算法简洁高效,每检测万条日志文本的平均耗时大概在300ms左右,使用Jaccard距离进行预处理,将相似度相差较大的筛选出去,接着再使用编辑距离进行判断,从而实现对日志的聚类收敛,以及给所有数据赋值唯一的id。
信息分类:由于传统的单向LSTM只能获取前向信息,而无法做到对后续信息的获取以及预测。
3 实验验证
本文选取公共数据集进行实验验证,实验平台的深度学习框架:PyTorch 1.3 稳定版,开发工具:Visual Studio Code,编程语言:Python 3.6。作为对比,本文使用SVM,KNN和普通LSTM模型对故障进行检测,检测结果如表1所示。
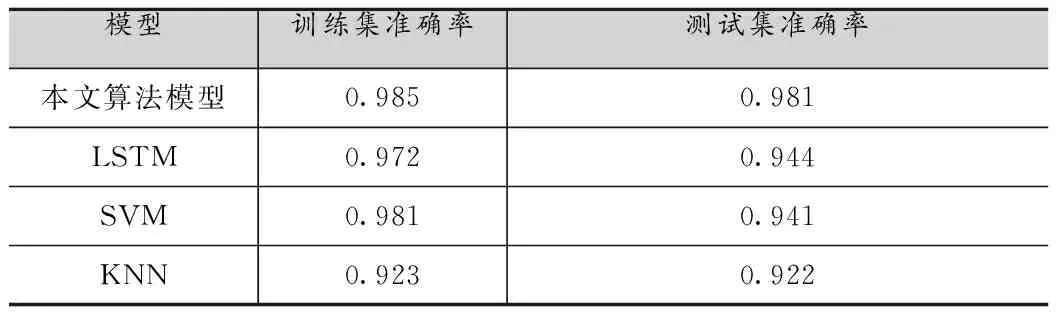
表1 不同模型准确率对比
综合来说,本文设计的基于t-SNE算法模型相比传统机器学习模型拥有更高的降维准确率。SVM作为经典的分类模型,其在训练集上表现出良好的效果,但是测试集上准确率显著下降,存在明显的过拟合现象。KNN分类器因为没有显式的训练过程,在训练集和测试集上的诊断效果均较为一般,LSTM在训练集和测试集上表现较为稳定,表明深度学习模型能够学习到数据中的时序变化信息。除此之外,随着数据的积累,模型的准确率能够进一步提高。
4 结语
为了解决当前电力降维处理难题,本文提出了采用数据挖掘的高维数据降维处理方法模型,给出了数据处理系统架构,阐述了基于日志时间的降维关联挖掘方法,设计了基于隔离森林的数据降维检测算法,通过实验验证了模型的可行性。
