基于数据挖掘的燃煤机组厂级负荷经济调度
2021-08-03代邦武常玉清孙晓辉
郑 伟,姚 远,代邦武,常玉清,孙晓辉
(1.国网辽宁省电力有限公司电力科学研究院,辽宁 沈阳 110006;2.东北大学信息科学与工程学院,辽宁 沈阳 110819;3.大连天籁安全风险管理技术有限公司,辽宁 沈阳 110031)
现有发电系统中燃煤发电仍占主要份额,降低燃煤发电机组煤耗实现节能减排、提高厂级经济效益一直是发电企业面临的主要问题[1-3]。厂级负荷经济调度是解决这一问题的有效途径,其主要目标就是在满足电网负荷指令的前提下通过优化厂内各发电机组负荷,实现厂内机组平均煤耗最低[4-5]。
当前,大部分燃煤发电机组处于自动发电控制(AGC)模式下。传统AGC对发电机组采用单机控制的调度模式,即网级调度中心将发电指令直接发送至各机组[6]。这种调度模式下,电厂不能考虑内部机组的煤耗特性差异,厂内机组平均煤耗率不是最优状态,难以实现机组间的经济调度,限制了发电机组节能减排的潜力。因此,在新一轮的电力体制改革的背景下,“两个细则”明确提出了有条件的地区实施厂级负荷经济调度,即将总的负荷指令下发到厂,由电厂内部自行决定各机组负荷。相比于网级单机调度,厂级负荷经济调度获得的信息更全面,所涉及的机组更少,更有利于采用更加精准的煤耗模型来提高机组节能减排的能力。实行厂级调度的关键是构建厂级负荷经济调度目标函数,其核心是建立厂内机组准确的煤耗特性模型。
近年来,大量文献研究了燃煤机组的煤耗特性。文献[7]基于机组运行数据利用二次多项式函数拟合负荷与机组煤耗率关系,建立了机组煤耗特性模型,并应用于负荷经济调度。文献[8]考虑汽轮机进气阀突然开启时产生的阀点效应,对二次函数模型引入阀点效应修正项,更准确地表达了煤耗与负荷之间的关系,以此提出了基于动态煤耗模型的厂级负荷经济调度方法。文献[9]通过对现场数据分析,利用多因素权重分配方法建立负荷与供电煤耗率的实时离散模型,构建了更为合理的负荷经济调度模型。
上述文献主要采用典型负荷工况下的运行数据建立煤耗特性模型。随着风电、光电等新能源发电的并网,燃煤发电机组频繁承担电网调峰任务,大幅度变负荷运行已成为常态,机组很难保持在典型负荷工况下运行[10]。另一方面,由于设备改造、老化等性能变化,以及煤质、温度等环境变化,典型负荷工况下机组煤耗特性也会随之发生变化[11],相同负荷点煤耗率也分布在一定范围。随着电厂监控信息系统(SIS)广泛应用,燃煤发电机组积累了丰富历史运行数据以及大量实时运行数据,这些数据在一定程度上可以反映机组真实煤耗特性。随着目前大数据技术的迅速发展,数据挖掘技术,为机组建立准确的煤耗特性模型提供了新途径。
本文根据燃煤机组运行数据特点提出了基于数据挖掘技术的燃煤机组负荷厂级经济调度方法。选取历史运行数据中稳态工况数据,建立稳态数据库;针对机组的不同运行边界和运行条件划分工况,同时依据经验知识选取机组内部影响煤耗的相关变量,利用高斯过程回归算法建立各个工况煤耗特性模型;在此基础上构建负荷经济调度目标函数,利用基因遗传算法,求解获得各机组负荷最优值;最后通过仿真实例验证所提方法的有效性。
1 燃煤机组煤耗预测
1.1 稳态检测
在燃煤机组实际运行中,由于承担着电网调峰调频任务,机组的负荷总是不断地变化以满足整体电网的平衡。这导致机组运行在非设计工况或暂态工况,此时机组的热力学参数并不稳定,煤耗特性也随之发生变化,以此煤耗特性作为负荷分配的依据并不能实现厂级总体煤耗量最小的目标。因而有必要从历史运行数据库中筛选出机组稳定运行工况,研究稳态工况下机组的煤耗特性。
目前,燃煤发电机组稳态工况的判定没有统一方法,ASME PTC6[12]根据机组负荷、主蒸汽压力、主蒸汽温度、再热蒸汽温度、给水流量5个变量给出了燃煤机组稳态判定的方法,即在某一段时间内,机组上述5个变量的最大值与最小值之差同时处于预先设定的阈值内,则认为机组的运行工况是稳定的。具体阈值设定见表1。本文通过滑动窗口技术[13](sliding window technology)从机组历史运行数据库中筛选稳态工况数据。

表1 稳态工况参数检测阈值Tab.1 The thresholds of steady-state detection parameters
1.2 稳态工况划分
获得稳态工况数据后,需根据边界条件将稳态数据划分到合适的运行工况,以便更深层地研究每个工况下发电机组的煤耗特性。文献[14]指出影响机组煤耗特性外部变量主要有机组负荷、环境温度、煤质等。由于煤质因素难以准确量化分析,且在一段时间内煤质变化不大,因此本文外部变量只考虑机组负荷与环境温度。本文利用模糊C均值聚类算法(fuzzy C-means,FCM)对负荷指标进行聚类分析,获取机组实际运行中负荷类别,最优聚类数k可通过式(1)最小值确定。

式中,k为聚类数,mj为第j类的聚类中心,xij为第j类的第i个数据,Nj为第j类样本个数,xpq为第p类的第q个数据,Nl为第l类样本个数。
一般认为环境温度变化在5 ℃以内,可认为对机组的煤耗影响很小,因此本文根据实际环境温度范围,以5 ℃为间隔对环境温度进行等间隔划分,获取环境温度类别。通过组合负荷类别与温度类别最终实现对稳态数据的工况划分。与此同时,利用领域经验知识结合煤耗敏感性分析技术,选取与煤耗相关的机组内部变量用于煤耗建模[5,15]。本文选取内部变量为主蒸汽压力、主蒸汽温度、再热蒸汽温度、排烟温度、冷凝器真空、给水温度。
1.3 基于高斯过程回归模型的机组煤耗特性预测
本文以各工况下机组负荷、环境温度以及选取的机组内部变量为输入变量,供电煤耗率为输出变量,利用高斯过程模型方法建立不同工况下的机组煤耗特性预测模型。高斯过程模型原理为[16]:给定训练数据集D={(xi,yi),i=1,…,n},其中xi={xi1,…,xid}为d维输入变量,y为输出变量。若存在某种映射函数f,构成集合Q={f(x1),…,f(xn)},其中f(x)由均值函数m(x)和方差函数k(x,x’)决定,且服从于高斯分布,则该过程为高斯过程,定义为
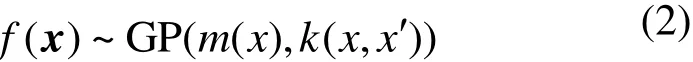
在实际生产中,引入均值为0、方差为σ2的白噪声ε,则有

为方便起见,取m(x)=0,则
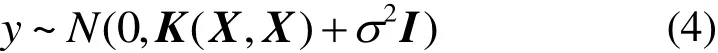
式中:X=(x1,…,xn),Ki,j=k(xi,xj);I为单位矩阵。
对于测试数据x*,其对应输出y*,则有
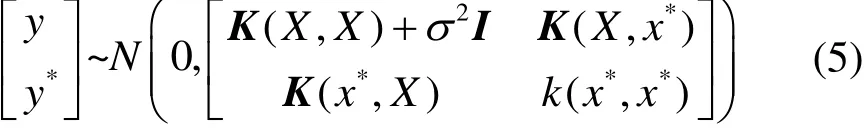
则预测值y*的表达式为
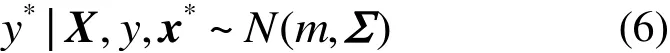
其中

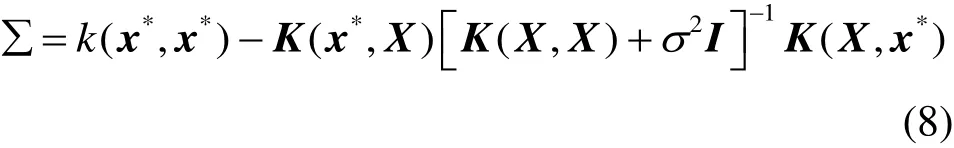
本文选择平方指数协方差函数作为核函数,其表达式为
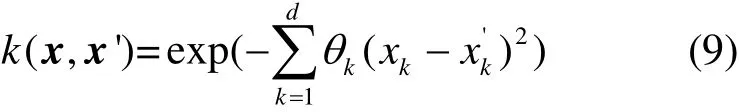
可利用极大似然估计求解超参数θk。
2 厂级负荷经济调度
2.1 目标函数
厂级负荷经济调度的目的是在满足电网指令与安全条件的前提下,通过优化厂内各机组负荷,使得厂内平均煤耗最小,从而获得较高的经济效益。因此,厂级负荷经济调度的目标函数可表示为
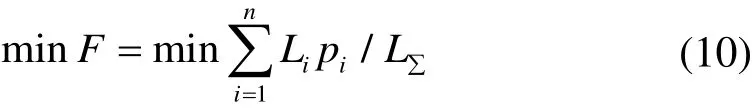
式中,Li为第i个机组负荷,pi为机组i负荷为Li时的煤耗率,L∑为电网下达到厂的总发电功率。
2.2 约束条件
1)功率平衡约束
电网不能储能,所以发电量与用电量须保持动态平衡,因而机组发电量必须满足电网调度指令的要求,即

2)机组出力限制
由于机组容量的约束以及机组安全运行的需要,各机组所带负荷需要满足
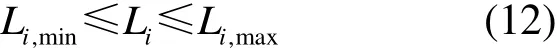
式中:Li,min表示机组i的负荷下限,通常由锅炉系统、汽轮机系统和发电机组可连续安全、平稳运行的最小出力决定;Li,max为机组i的负荷上限,由机组容量决定。
2.3 优化方法
遗传算法作为一种启发式智能优化方法已成为负荷经济调度的热门研究方法[2]。本文根据目标函数特点选取遗传算法优化求解经济调度问题。
3 案例分析
选取东北地区某电厂超临界3×350 MW燃煤纯凝发电机组为研究对象,验证本文方法的有效性,分析优化调度前后机组的节煤潜力。该机组采用HG-1110/25.4-HM2型超临界锅炉、中间一次再热系统。从电厂SIS中选取机组2019年4月前21天历史数据进行分析,数据采样间隔为1 min,共计获得3×30 240组运行数据样本。以机组A为例,利用1.1节的滑动窗口技术对历史运行数据筛选获取稳态运行数据,设定滑动窗口宽度为30,窗口滑动步长为1,通过筛选获得稳态运行数据15 163组。需要说明的是,随着新能源发电机组的并网,煤电机组经常承担调峰调频任务,机组负荷突破运行下限,处于低负荷运行状态,为了维持机组重要运行参数的稳定,减少负荷波动,负荷控制方式由自动改为手动。在实际的厂级负荷调度时,通常并不会使机组运行在低负荷状态,因而本文并未考虑低负荷运行状态的稳态数据。结合现场实际,本文将负荷值小于150 MW作为低负荷运行状态,选取大于150 MW的稳态数据作为经济调度的依据。图1为一段时间内的历史运行数据与筛选的稳态数据。
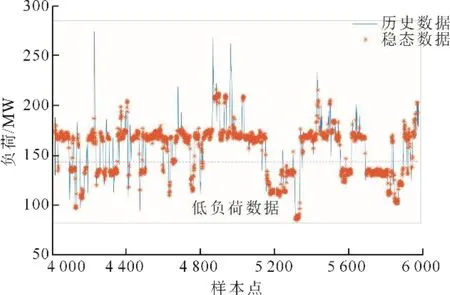
图1 稳态检测数据结果Fig.1 The results of steady-state detection
为了获得更准确的机组煤耗特性,需对稳态数据进行工况划分以研究每类工况下机组的煤耗特性。本文选取机组负荷与环境温度为工况划分指标。对于负荷指标,利用模糊C均值聚类算法对负荷进行聚类,并通过式(1)确定最优聚类数为5,负荷聚类划分结果如图2所示。

图2 负荷聚类划分结果Fig.2 The results for load clustering
对于环境温度指标,由于数据中温度变化范围为5~20 ℃,根据1.2节设定的划分规则,环境温度可分为[5, 10)、[10, 15)、[15, 20) 3个类别。因此,根据外部因素可获得15类稳态运行工况。15类稳态工况划分结果见表2。

表2 稳态工况划分Tab.2 The steady state working conditions division
在每一类稳态工况下,以负荷、环境温度以及所选内部变量为输入变量,机组供电煤耗率为输出变量,利用1.3节高斯过程回归算法建立各工况下煤耗率模型。以工况3为例,即负荷范围为[150.00,170.50] MW,温度范围为[15~20) ℃。将工况3数据分为训练集与测试集2个部分,在训练集基础上利用高斯过程回归算法建立机组煤耗率预测模型,并通过测试集数据以模型预测均方根误差(δRMSE)为指标检验所建模型预测效果。工况3下,模型预测均方根误差δRMSE=0.012 5,满足实际应用要求。为了体现数据挖掘方法的优越性,本文选取在160、210、260、280 MW典型负荷处数据建立典型负荷工况煤耗模型[5],并利用工况3测试数据验证。图3为2种煤耗模型预测值与实际测试值对比。从图3中可以看出,本文算法的预测效果优于典型负荷工况下模型的预测效果,体现了数据挖掘方法的优越性。
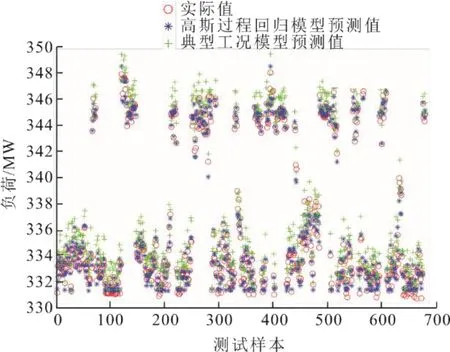
图3 2种模型煤耗率预测值与实际值对比Fig.3 Comparison of coal consumption rate between the predicted values of two models and the actual values
为了验证本文负荷经济调度方法的有效性,将经济调度后的厂级平均煤耗率与AGC单机平均分配的煤耗率进行对比,评估机组的节煤潜力。选取环境温度为[15~20)℃的工况,分别建立机组A、B、C煤耗率模型,并以此为基础根据式(10)构建优化目标函数,同时利用遗传算法进行求解,获得各机组负荷值与厂级平均煤耗率。表3为总负荷为500、700、850 MW时,通过经济调度后各机组所带负荷值与平均煤耗率,并与单机调度的煤耗率进行对比。通过表3可以看出,机组经济调度后的煤耗率低于经济调度前的煤耗率,按照电厂购煤平均煤价581元/t,在总负荷为500、700、850 MW时,平均1 kW·h的供电煤耗能够分别降低约0.04分、0.10分、0.07分左右,优化分配效果显著。因此,本文负荷经济调度方法使得机组的节煤能力得到提升,电厂的经济效益得到提高。

表3 机组负荷经济调度前后结果对比Tab.3 The operation results of the unit before and after economic load dispatch
为了进一步对比不同总负荷时,机组的节煤效果,图4给出了在不同负荷需求下经济调度方法与单机调度方法平均煤耗率以及相较于单机调度方法的节煤能力。由图4可见,负荷需求在机组最小或最大出力时,由于没有节煤空间,厂级经济调度与单机调度煤耗率基本相同,在此范围内,优化调度的煤耗率一直低于单机调度的煤耗率。特别地,当负荷需求在750~850 MW时,优化调度的节煤能力最好,最高可节煤1.77 g/(kW·h),进一步说明了本文方法的有效性。

图4 平均煤耗率与节煤能力Fig.4 The average coal consumption rate and coal saving capacity
4 结 论
随着数据测量、存储等技术的发展,燃煤发电机组积累了海量历史运行数据,针对这一特点,本文提出了基于数据挖掘技术的燃煤机组厂级负荷经济调度方法。该方法一方面利用数据挖掘技术处理历史运行数据,构建稳态运行工况,同时结合高斯过程回归模型构建机组煤耗特性模型;另一方面在所建煤耗模型的基础上,构建厂级负荷调度模型,利用遗传算法求解实现机组负荷经济调度。仿真实例表明,相较于单机调度本文方法能有效降低电厂平均煤耗率,提高电厂的节煤能力。
