旅游无效评论特征研究初探*
2021-08-01孟令坤郭建楠
刘 逸 ,孟令坤 ,李 想 ,郭建楠
(1.中山大学 旅游学院,广东 广州 510275;2.天普大学 旅游与酒店管理系,美国 费城PA19122;3.罗切斯特大学 西蒙商学院,美国 纽约州罗彻斯特城NY14620)
0 引言
随着互联网技术的成熟与普及,消费者可以随时随地在互联网上分享自己的经历、观点和意见,在这个过程中,产生了大量的关于商品或服务的直观信息,这些信息中有一些将可能成为消费者进行决策的有效参考源,也就是所谓的“网络口碑”(eWOM)[1]。中国互联网络信息中心(CNNIC)发布的《2015年中国网络购物市场研究报告》显示,有高达77.5%的网购用户认为网络口碑是影响其购买决策的最主要因素。在当今社会,网络口碑已经悄然在消费者作出决策的过程中扮演着极其重要的角色。
消费者日常接触的大部分商品为搜寻品(search good),其具体属性(如汽车的配置,家具的尺寸材质)在购买之前就可以被较为直观地判断。与此不同的是,旅游产品是一种体验品(experience good),游客需要经过消费之后才会对其产品属性有准确的认知,从而判断其质量[2]。因此潜在游客会更加依赖口碑推荐信息帮助最小化感知风险,例如亲友、旅行社推荐或在网络搜集他人评论等方式[3]。而在这些方式中,以旅游在线评论为代表的网络口碑使用最为广泛,影响最为深远。国内外学者对旅游在线评论做了大量的研究,主要分为三方面的内容:一是在线评论对旅游目的地形象的塑造作用[4-7];二是在线评论对旅游者消费决策的影响机制,识别关键因素[8-9];三是在线评论与旅游者之间的关系,例如旅游者阅读和撰写评论的动机,以及旅游评论的有效性[10-12]。
伴随着研究的深入,学者们逐渐意识到旅游在线评论并不全是真实有效的,海量的数据里可能潜藏着为数不少的无效评论(review spam)。根据2011年《泰晤士报》(The Times)的报道,热门旅游点评网站Tripadvisor就被指控有多达27 000条无效评论[13]。无效评论的泛滥引起了学者的关注。Mayzlin等发现当酒店的附近有竞争对手时,它所拥有的无效和消极评论会比附近没有竞争对手的酒店多,这意味着某些酒店为了在竞争过程中取得优势会故意撰写无效评论来中伤对手酒店[14]。无效评论在餐饮业中也相当常见,商家更愿意通过诋毁竞争对手来赢得更多消费者的青睐,而不是提高自身的菜品和服务质量[15]。2018年9月,《泰晤士报》再次援引一项调查结果,称Tripadvisor上1/3的用户评论无效,酒店和餐厅的评论存在恶意诽谤和购买假评论的现象[16]。尽管Tripadvisor回应时拒绝接受这一结果,但这些事件无疑反映出无效评论是个日益严重的全球性问题。对于旅游行业来说,无效评论的出现极大地误导了消费者的出行决策,他们可能会因为质量低下的旅游目的地拥有大量无效的良好口碑而做出出行的决定,也可能会由于恶意竞争导致的大量差评而错过某些高质量的景点。但是目前对于无效评论的研究还有很多问题需要解决,首先,已有研究的对象主要集中在淘宝、Amazon等电商网站上的无效评论[17],较少涉及和关注旅游点评网站上的无效评论。其次,尽管在学界和实践中已经尝试性地提出检测无效评论的数学模型[18],但此类模型更多的是检测酒店和餐饮评论[19],并没有专门识别旅游目的地无效评论的方法。总的来说,无效评论已经成为干扰商家和用户做出准确判断的因素之一,未来可能有愈演愈烈的趋势。如何更好地甄别这些评论的存在方式与产生机制,是旅游大数据、电子商务、市场营销等领域需要解决的重点问题。
基于此,本文选择中国四个著名旅游目的地(喀纳斯、洛阳、黄山、阳朔)的景区和酒店评论数据为样本,尝试通过人工判读的方式获取其中的无效旅游评论的内容,对比景区与酒店无效评论表现差异并进行文本分析,最终探索出旅游无效评论的具体特征,以期为后续旅游目的地无效评论检测方法的研究提供可参考的依据。
1 旅游无效评论的研究进展
1.1 无效评论的定义与分类
无效评论的研究最初源于对垃圾网页(web spam)和垃圾邮件(email spam)的研究。垃圾网页是指在网页中添加了与主题内容不相关或相关性不强的词语,导致内容混乱,无效信息众多,但这些人为添加的词语能够欺骗网络搜索引擎,从而提高了被搜索到的可能[20]。垃圾邮件则是指那些未经主动请求而发送给用户的、以广告宣传为主要目的的电子邮件[21]。这两类研究可以认为是无效评论研究的前身,因为在智能手机终端盛行之前,互联网上社交媒体的主要内容还不是类似旅游评论这种UGC(用户产生数据,User Generated Content)。但是垃圾网页、垃圾邮件与无效评论具有相似的特征:由无效的、不相关的文本内容构成,没有提供读者所需要的有价值的信息,而仅为了吸引关注或者获得搜索。
受到上述研究的启发,Jindal等首次对无效评论的类型做出了区分:他们把无效评论分为了不真实的评论(False Review)、不相关的评论(Uncorrelated Review)以及非评论(Non-Review)三种类型[22]。不真实的评论是指包含错误观点的评论,它的目的是故意误导读者来提高或削弱某个产品的声誉。不相关的评论是指只关注品牌、生产者或销售者而忽视产品本身的评论,这些评论往往带有偏见。非评论则是指不包含观点的评论,例如广告、乱码文本等[23]。Liu等人在分析亚马逊评论后,首次提出了观点欺诈问题,并对欺诈者的动机和技巧进行了推理和猜想[24]。随后,Hu等以图书在线评论为证据,验证了部分图书评论中确实存在商家故意操纵而导致的无效评论问题[25]。部分国内学者使用“虚假评论”(fake review)这一术语,孟美任等提出了自己对于虚假评论的见解,她们把“虚”“假”分开定义,把“虚”定义为滥发却不含任何价值的评论,而“假”则定义为包含不真实内容的评论[26]。总之,无效评论仍是一个非常新颖的领域,目前对于无效评论暂时还没有一个权威的定义,对于是否只有这三种无效评论类型也并没有统一的认识[27]。王伟军等就认为大量的网络在线商品存在评分与评论内容不一致的现象,它会使消费者陷入一种模糊、矛盾的心理感知状态,极大地影响了评论的真实性和有效性[28]。但是这种评分与评论内容存在偏差的现象并没有受到研究者的重视,国内外学者大多没有将其作为一种无效评论类型进行研究。
1.2 检测无效评论的方法与技术
目前网络评论基本处于一种缺乏有效监管的状态,无效评论的泛滥已经成为一个不容忽视的问题。Luca等在分析著名餐厅点评网站Yelp后,认为其网站上高达16%的评论都是无效评论[15]。而我国的淘宝、京东等电商网站也承认其电子商务平台上存在数量相当庞大的无效评论,且呈现出愈显愈烈的态势[27]。为此,学者在检测无效评论的方法与技术的研究上进行了大量的探索和尝试。目前的研究方向主要集中在两个方面:一是对无效评论特征的研究,二是对检测无效评论的技术进行创新。
在无效评论特征方面,研究的主流可以分为三个路径:第一是评论自身的特征,第二是基于评论者的行为进行研究,第三是对评论本身、评论者和评论对象进行综合分析。评论自身的特征包括文本特征、情感特征以及元数据特征等多个角度。Zhang发现与词汇的主观性相比,由浅层句法特征如专有名词、数词、情态动词、感叹词、以wh开头的单词、形容词比较级和最高级等词语构建的模型在预测网络评论的效用上更为显著[29]。赵军和王红从网络评论的情感特征入手,先以自然语言分析技术判断出文本的情感极性,再通过用户情感与大众情感的偏离程度来识别无效评论,发现偏离程度越大则评论无效的可能性越大[30]。Kim 等则认为元数据特征对在线评论效用的评价最为有效,特别是评论篇幅、评论得分、评论文本按曲折变化形式得到的TF-IDF得分等因素显得尤为关键[31]。
由于目前学术界对于什么特征能够准确判断出无效评论仍然没有达成定论,部分学者开始了对评论者行为的研究。Lim 等从用户评分行为出发,基于经验构建了检测无效评论制造者的数学模型,希望通过定位无效评论者的方法来寻找无效评论[32]。Wang等改进了寻找无效评论者的方法,他们提出了评论图(review graph)的概念来定义评论、评论者、被评论商店间的关系和指标,以节点增强方法进行迭代计算来筛选出无效评论者[33]。除了对无效评论与无效评论者各自的研究之外,也有学者把研究的焦点放在了评论、评论者和评论对象的结合上。Dellarocas对用户的评分行为进行了聚类分析,把评分存在不公正行为的评论以及由信誉等级低的评论者所发表的评论都视作无效评论[34]。李霄等也尝试结合评论、评论者和被评论的商品三个因素来检测垃圾评论,使用支持向量机模型(SVM)对垃圾评论进行了二分类,且识别的准确率提高到了78.16%[35]。
检测无效评论的技术主要包括监督学习、半监督学习和无监督学习三类。监督学习本质是一种分类分析的方法,在目前无效评论的研究中最为常见。它需要人工标注出无效数据集,然后使用SVM、支持向量回归(SVR)、决策树等方法对无效评论数据进行训练,从而构建统计模型来检测无效评论。Jindal等就对从Amazon上抓取的580万条评论进行了无效样本的训练学习,首次构建出评论、评论者和被评论商品的统计模型,并利用相似性算法和逻辑回归算法检索同种类型的无效评论[23]。Li等为了达到更好的数据训练效果,提出了使用半监督算法Co-Training来识别无效评论,大大提高了数据的准确率和召回率[36]。同时,也有学者对分类分析方法产生疑问,他们认为人工标注的主观性可能会对数据结果造成影响,于是开始了对无监督学习的探索。宋海霞等从评论者的角度出发,提出了一种基于评论者行为特征的自适应聚类方法来检测无效评论,并且在准确率方面也达到了69.05%[37]。但是以上技术都存在一个较大的局限性,就是基于建模的方式获取的数学模型存在着黑箱效应(black box)。我们只能知道结果,而不能知道为何得到这样的结果。我们可以判别无效评论的比率,但无从知道具体的无效评论的分布特征和规律,因此难以对无效评论产生的机制做分析,例如宋海霞等就对该类进行了研究[37]。
1.3 旅游的无效评论
旅游领域的无效评论研究始于对旅游在线评论可靠性的研究,学者们主要关注评论可靠性以及读者信任度的影响因素。Sparks等从评论的整体效用感知出发,注意到旅游者更容易相信那些易于理解的网络评论,同时也会对有互动的评论给予更高的信任[38]。Ayeh等对661个旅游者进行了问卷调查,发现评论来源的可靠性和感知的同质性是决定旅游者信任在线评论的两个重要因素[39]。Liu等则着重强调评论者的个人信息与评论可信度之间的关系,他们认为评论者个人信息披露得越多,评论者的名声越好,旅游者相信该评论的可能性也越大[40]。Zhang 等对33 099条专家评论和35 828条普通评论进行了分析和数学建模,得出了评论者的权威性也会影响评论阅读者对评论的信任度的结论[41]。但是,旅游者对评论的信任与否是一种主观感受,而旅游评论是否无效则是一个客观判断,因此这些研究都只停留在评论可靠性这一层面,还没能深入到旅游评论的真实性问题。
关于旅游无效评论的研究出现在2014年,学者们在研究网络无效评论时,把与旅游产业相关的点评网站如Tripadvisor、Expedia和Yelp 等作为数据采集的样本。Mayzlin等对比了Tripadvisor和Expedia上的酒店评论,发现Tripadvisor上的酒店当附近有竞争对手时,它们往往会有更多的一星和两星的负面评论,而这些评论很可能就来源于其附近的竞争对手故意造假[14]。Luca等发现餐饮点评Yelp上也存在与酒店点评相类似的情况:当一个餐厅面临越强烈的竞争时,它就越容易收到负面的无效评论[15]。Choi等站在旅游行业的角度,研究权力和刺激两个因素如何影响个体撰写无效评论的动机,他们的研究表明无权力的个体在有金钱的刺激下会更愿意撰写无效评论,而有权力的个体不会受到刺激的影响[42]。
1.4 小结
从上述文献回顾可以看出,当前关于无效评论特别是以旅游目的地尺度为对象的研究是一个尚未成熟的研究话题,主要体现在三个方面。第一,学界对于无效评论的定义与类型尚未有较为统一的认识。尽管Jindal等提出的三种无效评论类型得到了学者的普遍认可,但是他们并未能关注到评分与评论内容存在偏差这一无效评论类型。第二,目前对于无效评论研究的侧重点在于探讨甄别无效评论的技术,而尚未充分揭示无效评论存在的特征和产生规律。研究者都是采用“自上而下”的研究思路,先提出了检测无效评论的方法,再分析无效评论的特征。笔者认为,在研究的初期,需要考虑“自下而上”的研究思路,即先以人工检索的方法,甄别无效评论的特征,分析其产生的机制和规律。然后再将这些数据和结论反哺到检索模型的构建,这或许可以成为创新无效评论检索方法的另一路径。第三,现有研究的焦点在于网络在线商品特别是实用型商品的无效评论,虽然对酒店业和餐饮业也有所涉及,但对旅游行业探讨较少,也尚未有研究从旅游目的地视角研究无效评论。Ott等利用Amazon Mechanical Turk构造了包含800篇无效评论的语料库,许多研究者以此作为机器学习的训练材料[43]。但是旅游产品作为一种享用型商品,相关评论的用词特征、写作风格与实用型商品的评论差异巨大[44],以这个语料库为基准检索旅游无效评论可能会造成严重的误差。因此,探索旅游领域中无效评论的基本特征与规律,具有较好的科学价值与意义。
2 研究设计
本节将介绍人工阅读的主要内容和筛选流程,并解释样本数据选取的原因和无效评论的基本分布情况。
2.1 研究方法
在对无效评论的研究中,由于目前仍然缺少一个行之有效且得到普遍认可的无效评论检测方法,学者对无效评论的判断大多是基于人工的经验[23,43,45,46]。这些研究成果验证了人工识别无效评论的可行性,因此本研究在判断无效评论的过程中,也选择采用人工判读的方法分析目标旅游评论数据,定位出其中的无效评论,并对结果进行校验。现有研究主要从评论内容、评论行为、评论关系对无效评论进行特征识别和分析[47],因此本文从评论内容、评论与对象的关系、评论者信息三个方面筛选评论,具体判断内容如图1所示,主要涉及评论情感倾向、语法使用、信息真实度和匹配度等内容。
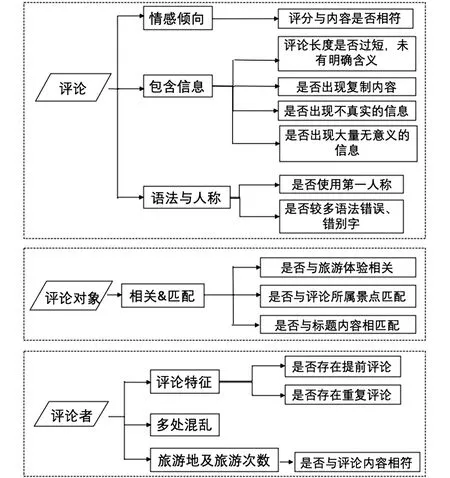
图1 人工判读主要内容
在得到准确的旅游无效评论数据集后,本研究将利用内容分析法(Content Analysis)更深入地分析,使用ROST CM6和Gephi软件处理所得数据,最终得出旅游无效评论的特征结果。
2.2 研究数据选取与处理
本研究的目的是探索旅游情境下无效评论的特征,考虑到旅游目的地的复杂性和多样性,本研究在自然型和人文型目的地中各选择了两个代表,黄山和喀纳斯属于自然型旅游目的地,洛阳和阳朔属于人文型旅游目的地。针对每一个旅游目的地,将同时阅读景区和酒店的评论,通过与酒店评论的对比,突出景区评论的差异和特征。
景区和酒店数据来自2018年至2019年游客发布在携程网上的短评论,基于python语言,使用网络爬虫工具获取。获取评论数据后对数据进行了去重工作,删除了评论中的重复项,最终得到24 460条景区评论,190 503条酒店评论,共244 974条短评论。评论分布情况如表1所示。

表1 旅游短评论分布情况
将上文提到的人工判读主要关注内容与旅游目的地的特征相结合,采用如图2所示的筛选思维流程解读旅游评论。共招募4名志愿者分别对上述四个目的地的酒店和景区评论数据进行独立地人工判读,判读前向志愿者发放筛选思维流程以及判读标准,并详细讲解,确保志愿者理解判读要求,针对志愿者难以判断的评论会引入第三方判读,然后集中讨论确定无效评论类型,全部判读完成后进行二次校验,确保判读的准确性。志愿者依次判断和筛选标题、评论内容、评论对象以及评论者信息,其中评论内容和对象的筛选信息量最大,包括判断评论主体、情感是否出现矛盾之处,信息是否真实准确等,针对评论者则主要判断其是否重复评论以及个人信息与评论内容是否匹配等关键信息。
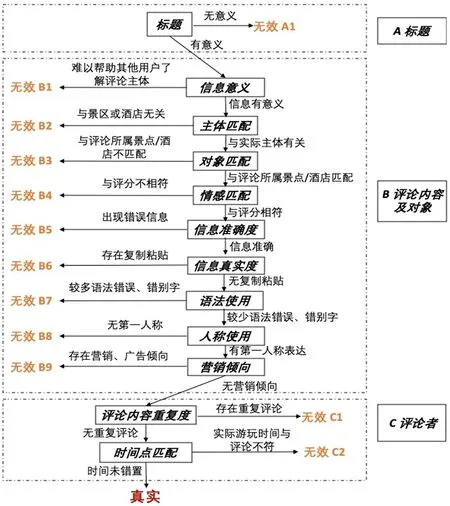
图2 无效评论筛选流程
最终检索出旅游无效评论共7 012 条,其中景区无效评论有3 046条,酒店无效评论有3 954条。需要注意的是,在筛选过程中,存在单条无效评论呈现出多种无效评论表现的情况,这里的无效评论数是指出现无效评论表现的评论。
总结无效评论的筛选原因,并将所有无效评论归类(部分评论存在多种无效表现),得到以下结果,见表2。
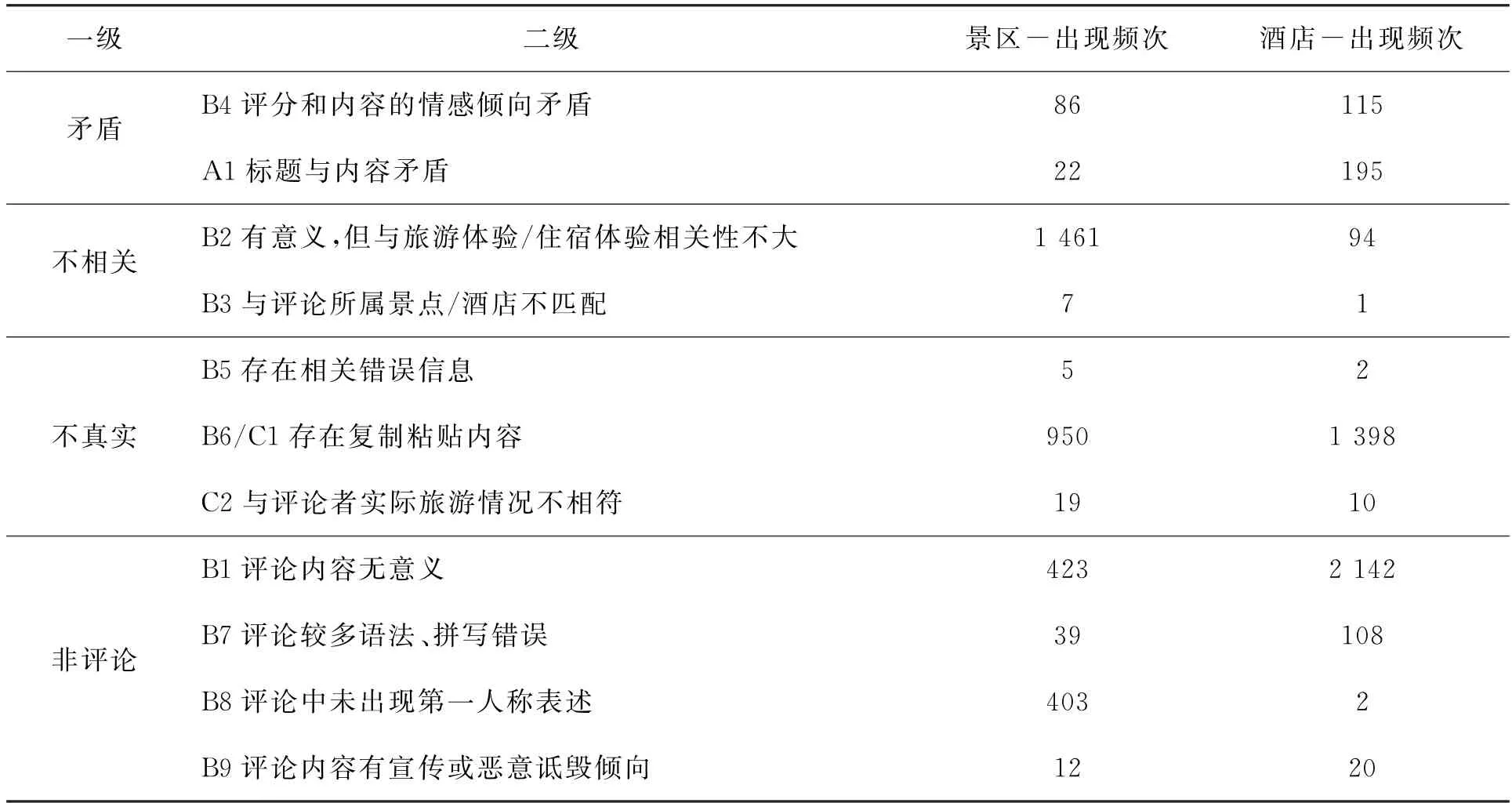
表2 无效评论表现
确定了旅游无效评论数据集后,本研究拟从评论的基本特征以及评论的文本特征两个角度进行分析。首先按照Jindal等提出的方法对旅游无效评论进行初步分类,对比景区与酒店无效评论的差异,探求相应的分类特征。在文本特征分析层面,本研究一方面关注评论的整体篇幅与词性,另一方面则使用ROST CM6软件提取无效评论高频词的共现矩阵[48],然后利用社会网络分析工具Gephi进行聚类分析,并将无效评论的语义网络进行可视化处理。Gephi分析图以共现高频词为节点,节点大小与节点度的大小成正比,同一聚类的节点拥有相同的颜色;节点间的连线则表示共现高频词之间的联系,连线的粗密则代表边的权重大小。
3 研究结果
经过上述处理,得到检测出来的旅游无效评论的基本数据特征,展开对比分析,并进一步分析无效评论的文本特征。
3.1 无效评论的类型与分布
首先统计无效评论的分布情况,从图3可以看出,景区与酒店的无效评论表现并不相同。在B1(评论内容无意义)、B2(有意义,但与旅游体验/住宿体验相关性不大)、B8(评论中未出现第一人称表述)、C1(评论者存在重复评论)几个无效评论表现中两者差异明显。酒店无效评论更多集中在无意义的评论内容(52.44%)和重复性评论(32.73%),而景区无效评论则呈现更加复杂多元的无效评论表现,其中与旅游体验/住宿体验相关性不大的无效评论出现频次较高(42.63%),B1、C1的相对频次也较高。
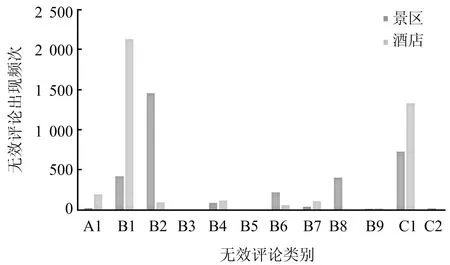
图3 旅游景区和酒店无效评论分布情况
本文对旅游目的地无效评论的分类方法基本沿用Jindal 等在2007 年提出的理论[22],把无效评论大致划分为不真实的评论、不相关的评论以及非评论三种。但是在判读大量旅游目的地评论时,注意到还存在这三种类型之外的无效评论形态,即第四种类型的无效评论。这种评论的特征表现为评论内容中存在自相矛盾之处,主要体现在两个方面。一是情感倾向与其评分存在严重偏差,如评论中存在大量的负面词汇,但是评分却是偏向正面的4分,这种偏差会干扰后来阅读者的判断,对于关注评分的旅游者而言,他们通过快速浏览评分来获取信息,因此就会认为这是一条正面的评论;而关注评论内容的旅游者会通读每一条评论的内容并从中提取出评论者的情感倾向,因此他们会把该评论视作负面;而对于同时结合评分和评论内容的旅游者而言,他们无法做出有效的判断,最终对其出行决策造成影响。二是评论标题与内容的主题矛盾,标题是旅游者查看评论时第一眼看到的重要信息,一定程度上决定旅游者是否会继续阅读评论的具体内容,如果标题内容与实际评论内容的含义或情感倾向存在矛盾和偏差,同样会使旅游者错失信息,影响旅游者做出有效判断,因此,本文把该类型评论也纳入无效评论的范畴中,得出的旅游目的地无效评论类型如表3所示。
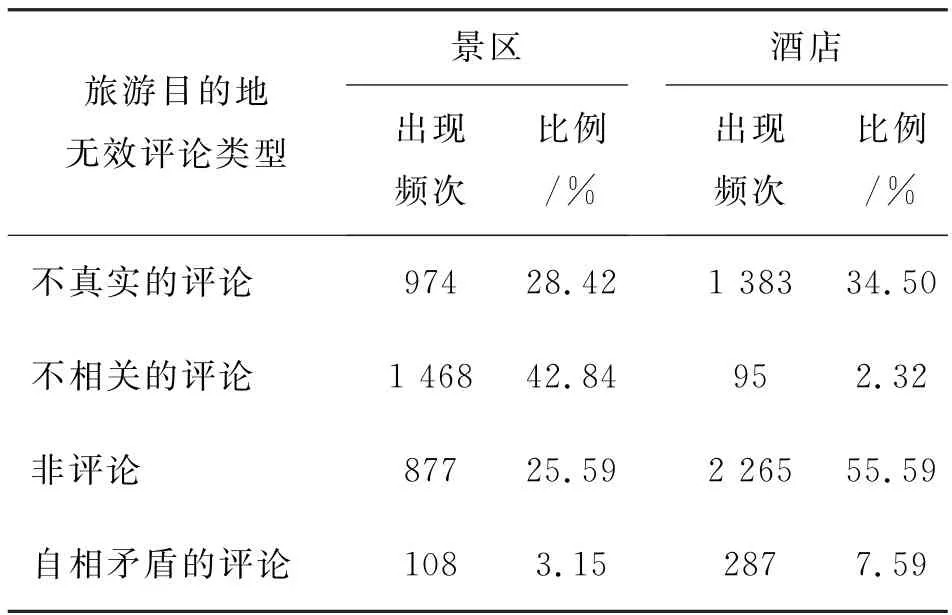
表3 景区与酒店无效评论类型
在已有的研究中,学者的关注点大多集中在寻找不真实的评论或非评论,他们认为评论者撰写无效评论的动机大多是受利益驱动,因此无效评论一般是以不真实的评论或非评论的形式出现。但是从表3可以看出,在检测出来的旅游目的地景区无效评论中,这两类评论的出现比例之和为54.01%,仍有42.84%的无效评论存在不相关现象。在不真实的评论类型中,评论的内容大多存在复制粘贴的现象,例如一句话重复出现,或评论中掺杂类似景区介绍的文字,使阅读者容易受到误导。而非评论中无意义评论和无第一人称出现评论都较多,无意义评论中出现明显的“凑字数”倾向,如使用毫无逻辑的词语堆砌、单一重复词汇、颜文字等,无第一人称的评论多为景区的客观介绍或相关诗词等。景区无效评论中不相关评论出现比例最高,大部分评论者把一些与目的地毫无关系的信息添加到了评论中,如App、优惠门票、购票网站、取票流程等。自相矛盾的评论中,情感倾向与评分存在严重偏差的评论出现比例较高,且正面倾向明显,通过阅读评论可以发现,这可能与人们在社交网络上的积极表达倾向有关。
通过对比景区和酒店的无效评论分布差异,可以发现,酒店无效评论集中在不真实和非评论中,而景区无效评论则相对均匀地分布在不真实、不相关、非相关三种类型之中,其中不相关的评论占比最高(42.84%)。
3.2 无效评论的文本特征
3.2.1 篇幅
评论长度是一个预测评论有效性的重要因素,学者一般认为评论的长度越长,则评论的有用性越高,两者存在显著的正相关关系[44]。过短的评论一般会被认为是“灌水”的评论,具体表现为评论的长度刚好达到评论网站限制的最小值;而长评论由于篇幅较长,一般包含更多信息,因此更偏于是真实有效的评论。但是检测出来的所有景区无效评论平均中文字符数达到53,字数最多的一条无效评论包含791 个中文字符。如前文所述,景区无效评论中存在许多缺乏情感表达的介绍类文字,包含景区的大量信息,字数往往较多。由此可见,在旅游景区尺度下,评论长度不能作为检测旅游景区无效评论的唯一标准,以评论长度作为识别无效评论的依据可能会造成误判。
3.2.2 高频词与语义网络
在分析了宏观的文本特征后,本部分将聚焦于更微观的高频词与语义网络分析。首先对景区评论文本进行预处理,具体包括分词、去除停用词以及特殊字符,本次研究使用Jieba中文分词工具,并添加了TSE 模型[48]中建立的旅游情感词库,保留旅游评论中的景点名称、食物名称、特殊评价等专有性词语。停用词(Stop Words)可以分为两类:第一类是应用广泛的词语;第二类是介词、连接词、数字等。特殊字符包括单位符号、制表符等。
然后利用ROST CM 提取出景区无效评论中的高频词的共现矩阵,利用Excel转换成相邻矩阵导入Gephi软件,对语义网络进行可视化操作。在删除了一些无意义的节点与连线后,得到包含53 个节点、101 条边以及5个子类的无向聚类分析图,如图4所示。从聚类分析图可以看出,各子类可以分为两种类型:一是以“安徽省”“洛阳市”“龙门石窟”等地方名称类和景点名称类词语为核心的子类。这些子类中出现了“景区”“地方”“位于”等词语,是景区基本介绍类的文字中经常使用的词语,体现出复制粘贴、缺乏评论者个人情感表达的无效评论,这类评论内容信息是真实的,但无法帮助潜在消费者作出消费决策。二是以“身份证”“购票”“优惠”“导游”等词语为中心的子类,这些词语都与直接的旅游体验相关性不强,而与旅游衍生服务,如导游讲解服务、购票服务、排队服务、取票服务等关系紧密,是围绕着在线旅游消费网站而给出的评论,无法给潜在消费者提供景区游玩体验上的参考,该子类代表着无效的不相关评论。评论者在阐述经历时会使用多人称切换的叙事手法,在讲述自身经历的同时也会评述旅游景区。这种叙事模式能增强故事的真实性,强化读者阅读的体验性。该聚类分析结果表明,本研究检测出的旅游景区无效评论从本质上来说大多是真实的,不是评论者故意伪造的经历,包含的错误信息较少,它们无效的点更多在于其与评论的对象不相关,或无法提供可参考的旅游体验相关信息,“无效性”特征突出,而“虚假性”特征不明显。
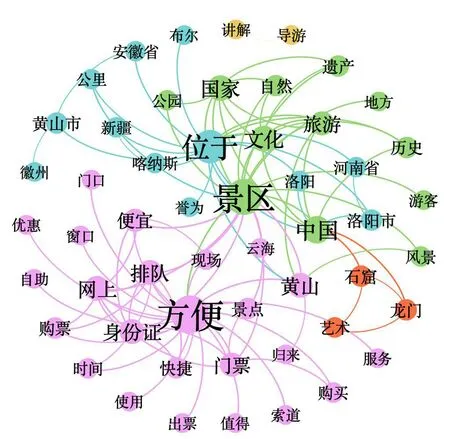
图4 景区无效评论聚类分析图
4 结论与建议
为了较为准确地探究无效评论产生的基本方式与特征,本文以人工判读的方法识别出旅游景区的无效评论,并与酒店无效评论进行对比和特征分析。通过基本特征和文本特征两个角度的分析,本文得出了以下三个结论。第一,在评论的类型方面,旅游景区的无效评论与酒店的无效评论在特征上存在显著的差异,旅游景区的主要类型是不相关的评论,而酒店业的无效评论中经常出现不真实评论以及非评论。从无效评论的表现可以看出,旅游景区的无效评论主要来自评论者对评论主体的错置,评价购票程序和网站等旅游服务而不是旅游体验和景点特征,以及对景区介绍的复制粘贴,并非来自虚假评论或者广告。它们的内容通常较为真实,可信度较高,无效的点仅在于评论的对象不相关以及不涉及评论者个人情感。另外,本研究还发现旅游景区的无效评论中还存在除不真实的评论、不相关的评论以及非评论之外的第四种评论,即情感倾向与评分存在严重偏差的评论,这种评论的成因也与评论者自身的随意或知识局限有较大关系。第二,在评论的文本特征方面,评论长度无法作为判断旅游景区无效评论的唯一依据,旅游景区无效评论的篇幅长短不一,并非篇幅越长的评论就越真实。第三,基于语义网络图可以发现,景区的无效评论中地名类词语、景点名称类词语、旅游服务相关词语为高频词语,代表着不相关和非评论两类无效评论。
本文的贡献在于拓展了旅游社交媒体与旅游评论的研究视角,初步揭示了旅游景区无效评论的存在方式与特征,是对旅游UGC数据挖掘的一次富有意义的探索。通过人工判读的方法,本文较为准确地揭示了旅游景区无效评论的专有特征,为进一步开发旅游无效评论的甄别模型提供理论支撑和特征识别的方向。对旅游行业而言,本文的启示在于提醒管理者不要照搬对待一般商品的无效评论的方式来处理旅游无效评论,需要考虑旅游产业特有的因素,例如词汇和情感表达。同时要严格自律,不要参与无效评论的制造,保持旅游UGC 当前的信度。在无效评论管理方面,对于目前存在的不相关评论,可以调整奖励机制,不以评论文字长短,而是以评论质量确定奖励标准,建立情感联结,鼓励消费者积极表达自我感受,并定期选择优秀评论奖励积分或代金券等,或者邀请撰写者进一步修正其评论,实现评论的优化管理。针对重复性评论,可以修改评论机制,整合同一消费者的多次订单,避免因不必要的评论环节,引起消费者反感从而发表重复的无效评论。对与评论对象不匹配的评论,可在发表评论的网站页面增设评论对象的提示信息,避免消费者产生混淆。
基于本文的研究发现,对旅游景区无效评论甄别模型的建设提出以下三点建议:第一,甄别旅游无效评论时需要加入旅游景区无效评论的专有因素,如情感表达、句中/句间重复性表达等,作为未来机器学习模型识别的重要特征;第二,旅游景区无效评论中最多的评论类型往往是不相关的评论,在构建算法时应该予以考虑,更多地从不相关评论具备的特征和出现的原因入手来制定检测规则,例如对评论对象关键词的检索和匹配设置;第三,继续开展人工判读工作,挖掘各类景区无效评论的特征,不能只依靠计算机算法的升级来带动旅游景区无效评论检测方法的改进。
