基于改进YOLO v3模型的奶牛发情行为识别研究
2021-07-30王少华何东健
王少华 何东健
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100;2.农业农村部农业物联网重点实验室, 陕西杨凌 712100)
0 引言
目前,我国奶牛养殖场多以传统养殖方式为主,近年来随着牛奶消费需求的增加,奶牛养殖规模和数量快速增长,奶牛场劳动力成本与经济效益之间的矛盾日益突出,因此迫切需要自动化的奶牛养殖管理方法。评估奶牛发情状况是奶牛养殖的重要环节,奶牛发情期短,错过或漏识别会给奶牛场造成经济损失。传统的奶牛发情评估主要依靠人工进行观察,需要投入大量的时间和精力,因此,研究奶牛发情行为的自动识别方法具有重要意义。
随着计算机视觉技术的发展,不少研究者提出了基于视频图像分析识别奶牛发情的方法[1-8]。近年来,深度学习理论和方法得到了极大发展,研究者基于深度学习进行了许多精准养殖方面的研究[9-20]。JIANG等[9]在YOLO v3网络中加入由均值滤波算法和带泄露修正线性单元(Leaky ReLU)构成的过滤层(Filter layer),优化训练过程,提出了一种基于FYOLO的奶牛关键部位识别方法,识别准确率为99.18%。ZHANG等[10]以视频帧和光流场变化作为网络输入,提出了一种Two-Steam的卷积神经网络模型,用于自动识别视频监控中的猪只行为,识别准确率为98.99%。何东健等[13]通过优化锚点框和改进网络结构提出了一种基于改进YOLO v3模型的挤奶奶牛个体识别方法,识别准确率为95.91%,该方法可实现复杂环境下奶牛个体的精准识别。在奶牛发情行为识别方面,PARK等[16]将采集的牛只在不同状态和行为时的叫声输入卷积神经网络,训练网络通过声音识别牛只包括发情在内的不同行为和状态,识别准确率为96.20%,但该声音采集方法对环境要求较高,不适用于奶牛场复杂的养殖环境。刘忠超等[17]受LeNet-5启发,构建了一种多层卷积神经网络,并使用奶牛行为图像样本训练模型,提出了一种基于卷积神经网络的奶牛发情行为识别模型,模型识别准确率为98.25%,但该模型只能用于识别已获取的奶牛行为图像。王少华等[18]采用改进的GMM检测运动奶牛目标,基于训练好的AlexNet识别被检测奶牛目标的行为,提出了一种基于机器视觉的奶牛发情行为自动识别方法,识别准确率为100%,召回率为88.24%,但该方法识别速度较慢。作为一种自主特征学习方法,深度学习具有自动获取图像多层次、多维度特征信息的能力,有效克服了人工提取特征向量的局限性,在农业领域具有广阔的应用前景。以YOLO v3模型为代表的端到端的目标检测方法,具有识别速度快、识别准确率高、模型抗干扰能力强等优点,具备在复杂环境下识别奶牛发情行为的潜力。
针对复杂环境下奶牛发情行为检测精度和速度亟待提高的问题,本文提出一种基于改进YOLO v3模型的奶牛发情行为识别方法。在获取奶牛行为图像的基础上,利用LabelImg开源工具对图像中的爬跨行为进行标注,构建奶牛发情行为样本数据集;根据样本集数据特点,从锚点框尺寸优化、特征提取网络改进、边界框损失函数优化3方面对YOLO v3模型进行改进,并基于TensorFlow和高性能GPU计算平台实现对改进后模型的训练;最后,利用优选的模型,在测试集上对模型性能进行评估与分析。
1 材料与方法
1.1 数据来源
本研究供试视频采集自陕西省宝鸡市扶风县西北农林科技大学畜牧实验基地的奶牛养殖场,通过调研发现,奶牛发情爬跨行为主要发生在养殖场的奶牛活动区,故本研究选择对奶牛活动区进行视频采集。奶牛活动区长30 m,宽18 m,在奶牛活动区的对角线位置各安装了2个分辨率为200万像素的监控摄像机(YW7100HR09-SC62-TA12型,深圳亿维锐创科技有限公司),摄像机安装高度3.3 m,向下倾斜15.5°,安装好的摄像机及视野图像如图1所示。视频采用场边俯视的角度记录了56头具备发情能力的成年泌乳奶牛的活动情况,视频记录时间为2016年12月至2017年4月,共采集到奶牛活动视频3 600段,每段视频长10 min,视频分辨率为1 920像素(水平)×1 080像素(垂直),帧率25 f/s。
1.2 图像预处理
奶牛场复杂的养殖环境以及视频图像生成、传输过程受到干扰,使采集到的视频图像中存在噪声而降低图像质量。为提高后期奶牛发情行为的识别效率,对采集到的视频图像进行降噪和图像增强操作。
分析本文视频图像噪声产生原因可知,噪声类型主要为系统加性高斯噪声,故可选用高斯滤波或双边滤波来去除。考虑到高斯滤波用加权平均的方法去除噪声,会使图像边缘处出现模糊,而双边滤波使用与空间距离或灰度距离相关的高斯函数相乘作为滤波因子,在滤除噪声的同时尽可能地考虑了图像的边缘信息,因此,本研究选用双边滤波滤除图像噪声。
由于本文视频采集跨度时间长,当夜晚环境亮度降低时,拍摄到的视频图像对比度会下降,导致奶牛轮廓与背景区分不明显。本文使用分段线性函数对图像进行对比度拉伸,通过对比度拉伸可以有目的地增强奶牛像素,使视频图像中的奶牛轮廓更加清晰,对比度拉伸计算公式为
(1)
式中x——输入像素f(x)——输出图像
a1、a2——感兴趣目标灰度区间上、下限阈值,本文a1=50,a2=150
a′1、a′2——感兴趣目标灰度区间新映射区间上、下限阈值,本文a′1=40,a′2=200
其中,a1、a2、a′1和a′2由预备试验确定。
1.3 供试样本集构建
观看奶牛活动区监控视频,人工筛选出具有爬跨行为的视频片段96段,每段长度 15~80 s不等,利用视频帧分解技术,每5帧取1帧,得到视频图像13 655幅,其中,每幅图像中既包含有爬跨行为奶牛,也包含有其他行为奶牛,如站立、游走、躺卧等。由于各视频段图像数量并不均等,为避免因样本量差异对模型训练结果产生影响,将各视频段图像统一调整为50幅,最终构成样本集图像共有4 800幅。为扩大样本量,提高数据泛性,根据奶牛爬跨行为在活动区出现位置的不确定性以及活动区光照变化的特点,采用对样本图像水平翻转、±15°旋转、随机亮度增强(降低)的方法进行数据增强,最终得到增强后的图像14 400幅,作为模型的样本增强数据集,经增强后的图像样例如图2所示。
按照训练、验证、测试之比为7∶2∶1,对样本增强数据集进行随机划分后,训练集样本10 800幅、验证集样本2 880幅、测试集样本1 440幅,各类样本集间无数据重叠。采用开源工具LabelImg对训练集、验证集样本进行标注,标记对象为奶牛爬跨行为,标记标签为“mounting”,标记文件保存为PascalVOC格式,名称与图像名一一对应。
2 YOLO v3模型构建与改进
2.1 YOLO v3模型
2.1.1特征提取网络
YOLO v3模型[21]使用Darknet-53作为其特征提取网络。Darknet-53共有53层卷积层,每个卷积层由1×1 和 3×3的卷积核构成,其余为残差层,均位于卷积层之后,其网络结构如图3所示。Darknet-53引入残差(Residual)结构,可以很好地控制梯度的传播,使构建的网络更深,特征学习能力更强大。YOLO v3模型的第75层到105层为特征融合层,使用上采样和多尺度特征融合方法,加强网络对小目标的检测精度。ImageNet数据集[22]下,YOLO v3模型特征提取网络与其他网络的性能对比试验结果表明[21],Darknet-53 比Darknet-19[23]速度有所下降,但精度提升,Darknet-53性能优于ResNet-101[24],且速度提高了1.3倍,和ResNet-152[24]性能相当,但速度提高了1.1倍。
2.1.2边界框分类与预测
YOLO v3模型基于锚点框尺寸微调实现对边界框的预测,其中9种锚点框尺寸由COCO数据集上聚类得到,并分别分配给3种不同的特征图,用于构建模型对不同大小目标的检测能力。锚点框尺寸与特征图对应关系如表1所示。

表1 锚点框尺寸与特征图对应关系
YOLO v3模型采用直接预测相对位置的方法对边界框进行预测,它将输入图像划分为S×S个网格,每个网格单元负责检查中心位于其内的边界框和置信度,网格单元的具体信息可以表示为(tx,ty,tw,th,C),其中tx、ty表示边界框的坐标偏移量,tw、th表示尺度缩放,C为预测结果置信度。YOLO v3使用tx、ty、tw、th作为学习信息,使用预设的锚点框尺寸经线性回归微调(平移加尺度缩放)实现边界框的预测。模型边界框预测的输出值(tx,ty,tw,th)为4组偏移量,bx、by、bw、bh的计算公式为
(2)
式中σ——Sigmoid激活函数
(cx,cy)——网格单元左上角坐标
tx、ty——边界框中心坐标偏移量
tw、th——边界框宽和高的缩放尺度
pw、ph——锚点框宽和高在特征图上的特征映射
(bx,by)——边界框中心坐标
bw、bh——边界框宽和高
2.2 YOLO v3模型改进
2.2.1锚点框聚类与优化
YOLO v3模型的锚点框尺寸由其在COCO数据集上聚类得到,与本文需要检测的奶牛爬跨行为目标尺寸并不一致,为提高模型训练效果,需设置新的锚点框尺寸。使用K-means算法在已标注的样本集上聚类,得到新的锚点框尺寸为46×47、61×109、76×73、94×150、114×90、136×194、140×118、191×155、232×262。
使用新的锚点框尺寸测试发现,模型训练效果一般,分析原因为:由于本文使用的样本数据均为奶牛视频图像,样本类型单一,且样本中标注框尺寸分布集中,导致聚类产生的锚点框尺寸也过于集中,无法体现出YOLO v3模型的多尺度检测的输出优势,且本文标注框尺寸多大于锚点框,增加了训练开销。为改善训练效果,使用线性扩展法对锚点框尺寸进行优化,本文使用线性尺度缩放的办法将锚点框尺寸向两边拉伸,线性拉伸表达式为
(3)
式中α——最小框缩小倍数,经预试验确定α=0.5
β——最大框扩大倍数,经预试验确定β=1.5
w——扩展前锚点框宽度
w′——扩展后锚点框宽度
wmin、wmax——扩展前锚点框宽度最小值、最大值
w′min、w′max——扩展后锚点框宽度最小值、最大值
h——扩展前锚点框高度
h′——扩展后锚点框高度
优化后的锚点框尺寸为23×23、49×87、75×72、106×170、141×111、180×257、187×157、276×224、348×393。可以看出,优化后的锚点框尺寸分布更为分散,经测试,使用优化后的锚点框训练模型拟合速度更快。最后,将新的锚点框尺寸按感受野大、中、小分为3组,分别替代表1中3种特征图对应的锚点框。
2.2.2特征提取网络的改进
本文模型以奶牛发情爬跨行为作为检测目标,由于奶牛个体偏大、个体间差距小,且各行为之间关联,较一般的目标更难区分,为使模型取得更好的识别效果,需对特征提取网络进行改进。DenseNet[25]网络结构更深,对大目标检测能力更强,受其启发本文引入DenseBlock结构与YOLO v3模型特征提取网络融合,以提高网络大目标检测性能。
对于卷积神经网络H,假设输入图像为m0,经过L层神经网络,每一层都实现了一个非线性变换Hi,Hi可以是多种函数操作的组合,如:批量归一化、修正线性单元ReLU、上下采样或卷积等。传统前馈卷积神经网络将第i层的输出作为i+1层的输入,可以表示为
mi=Hi(mi-1)
(4)
式中mi——第i层输出的特征映射
ResNet中增加了从输入到输出的残差(Residual)结构,可以表示为
mi=Hi(mi-1)+xi-1
(5)
使用ResNet的主要优势是梯度可以经恒等映射到达前面的层,但ResNet处理恒等映射和非线性输出的方式是叠加,这在一定程度上破坏了网络中的信息流。
为进一步优化信息流的传播,HUANG等[25]在设计DenseNet网络时提出DenseBlock结构,如图4所示,引入从任何层到后续层的直接连接,这样第i层得到了之前所有层的特征映射m0、m1、…、mi-1作为输入
mi=Hi([m0,m1,…,mi-1])
(6)
在YOLO v3特征提取网络后增加2个DenseBlock结构,达到加深网络的目的,增加的DenseBlock结构由4组1×1和3×3卷积层和1层过渡层(Transition layer)组成。其中,1×1卷积用于降低输入特征通道数,3×3卷积用于新的特征提取,每层的输入均是前面所有层的输出经特征通道拼接而来,过渡层的主要目的是特征融合和改变输出特征通道数。使用DenseBlock结构来增加网络深度而不使用残差结构的原因是DenseBlock结构具有更少的参数量。例如,对于通道数为2 048的输入特征图像,使用残差结构需要1×1和3×3卷积数量分别为1 024个和2 048个,而使用DenseBlock结构需要1×1和3×3卷积数量分别为192个和48个,此外,随着网络结构的加深,模型的训练更加困难,研究表明[27],在没有预训练的前提下,DenseBlock更易训练,这主要源于该结构密集连接的方式。改进后,YOLO v3的特征提取网络如图5所示。
对于改进后的特征提取网络,若输入图像尺寸为512像素×512像素,则由DenseBlock结构输出的最小特征图尺寸为4像素×4像素,是输入图像的128倍下采样,由于下采样倍数高,特征图感受野更大,模型对大目标检测能力更强。改进后的YOLO v3模型使用上采样构造特征金字塔进行多尺度特征融合,实现高低层特征信息共享,以提高模型不同尺度特征图的上下文语义。
2.2.3边界框损失函数优化
YOLO v3模型的损失函数由坐标误差、分类误差和置信度误差3部分构成,其中坐标误差使用均方差(Mean squared error, MSE)来度量,但MSE对目标尺度不具有不变性。预测框与真实框的交并比(Intersection over union, IoU)与MSE相比,具有尺度上的鲁棒性,但IoU作为损失函数,存在预测框与真实框不重合时梯度为0,损失函数无法优化的问题。为使IoU适合作为损失函数,本文对IoU的计算方法做出调整,提出FIoU作为边界框回归损失函数,其计算公式为
(7)
式中IIoU——预测框与真实框的交并比
Ac——预测框与真实框的最小闭合区域面积
U——Ac中不属于预测框和真实框的面积
FIoU也具有尺度上的鲁棒性,由式(7)可知,两框不重叠时依然可以计算出FIoU,解决了两框不重合梯度为0的问题。若将其作为边界框损失函数,则表示形式为
LIoU=1-FIoU
(8)
式中LIoU——使用FIoU作为度量的边界框损失函数
使用LIoU作为边界框损失函数,需同时在损失函数中加入两框距离的度量,为边界框的回归提供移动方向。受YOLO v1[26]模型启发,使用两框的中心距离Dc作为两框距离的度量,其计算公式为
Dc=(x-x′)2+(y-y′)2
(9)
式中 (x,y)——真实框的中心坐标
(x′,y′)——预测框的中心坐标
Dc——预测框与真实框的中心距离
最终的边界框损失函数表达式为
L=η1Dc+η2LIoU
(10)
式中L——使用FIoU和Dc作为度量的边界框损失函数
η1、η2——平衡两种度量之间数值差距的权重系数,经预试验确定η1=10,η2=0.5
3 试验结果与分析
3.1 试验平台
本文模型训练及验证在CPU为Intel Core i9-9900KF,内存为32 GB,操作系统为Windows 10的服务器上进行,使用TensorFlow在GPU上并行计算完成,试验使用的GPU配置为Nvidia GeForceRTX 2080Ti,显存为2 GB,并行计算环境为CUDA 10.0和cudnn 7.6.5。试验编程语言为Python 3.6.2。
3.2 奶牛发情行为识别训练
训练集样本10 800幅,验证集样本2 880幅。训练使用的样本批尺寸(batchsize)为9,每2次迭代更新1次权重,训练过程采用小批量梯度下降(Mini-batch gradient descent, MBGD)方法进行优化,等效批尺寸为18。训练共100个迭代周期(epoch),每个周期迭代10 800/9次,共计迭代1.2×105次。训练的初始学习率设为0.001,学习率调整采用epoch-decay策略,每训练完1个周期,学习率减小为原来的0.9,最终将学习率调整到0.000 01。
图6为训练过程损失值变化曲线,由图可以看出,模型在前5个周期迭代中损失值迅速下降,表明模型快速拟合,从第6个周期到第50个周期,损失值开始缓慢减小,在训练迭代90个周期后,损失值稳定在 5~6之间,只有轻微振荡,表明模型拟合结束。
为了防止因迭代次数过多而产生过拟合,在训练迭代75个周期后,每迭代1个周期输出1次权值模型,共产生25个模型。采用识别准确率P、识别召回率R、准确率和召回率综合评价指标F1、平均精度均值(Mean average precision, mAP)作为模型性能评价指标。
在目标检测中每个类别都可以根据准确率P和召回率R绘制P-R曲线,平均精度(Average precision, AP)是P-R曲线与坐标轴所围面积,而mAP是所有类别平均精度的平均值。本文的目标检测类别为1,因此AP也等于mAP。
3.3 最优模型的确定
为更好地对模型性能进行评估,需明确各评价指标优先级。本文奶牛发情行为识别试验中,采用的评价指标优先级由大到小依次为F1、mAP、P、R。模型训练过程中,各指标随迭代周期的变化曲线如图7所示。
由图7可知,在前80个周期的训练过程中,各项指标变化幅度较大,但总体趋势是增长的;在后20个周期的训练中,各项指标逐渐趋于稳定,在小范围内振荡。周期为97时,F1有最大值,为98.75%;周期为83时,mAP最大值为98.10%;周期为97时,准确率P最大值为99.57%;周期为82时,召回率R最大值为97.96%。
综合考虑F1和其他3项指标,本文最终选用第97个周期迭代完成后保存的模型作为奶牛发情行为识别模型,此时模型具有最高的F1和准确率,也具有较高的mAP和召回率。
3.4 识别结果分析
用筛选出的模型在测试集上进行试验,测试集包含1 440幅图像,模型共识别出1 406幅图像中的奶牛爬跨行为,经人工确认,其中正确识别1 394幅,错误识别12幅,识别准确率为99.15%,有34幅图像中的爬跨行为未被模型识别,识别召回率为97.62%,未被识别的主要原因为存在遮挡的爬跨行为以及少量夜间发生的爬跨行为,其中存在遮挡的爬跨行为28幅,夜间爬跨行为6幅。
对奶牛躯干的定位及检测精度,最终会影响模型的识别准确率,因此,首先对模型的奶牛躯干定位及检测精准程度进行分析。评价目标检测的效果时需先区分前景和背景,本文模型中发情奶牛躯干为目标检测的前景,图像帧的其他区域为背景。使用前景误检率Vff、背景误检率Vbf作为模型检测准确度的评价指标。
(11)
式中Ap——预测框区域面积
Ab——奶牛躯干最小外接矩形面积
S——预测框与奶牛躯干最小外接矩形相交区域面积
从试验结果中选取200幅具有有效牛身信息的识别结果进行统计,并与YOLO v3、Faster R-CNN[27]进行对比,如表2所示。由表2可知,本文模型前景检测的误检率为13.28%,低于YOLO v3的15.44%和Faster R-CNN的14.67%;背景误检率为21.55%,较YOLO v3 降低了2.12个百分点,较Faster R-CNN 降低了1.24个百分点。前景误检率实际上表达了模型对奶牛躯干特征提取的准确性,试验结果中本文模型的前景误检率和背景误检率均低于YOLO v3和Faster R-CNN,表明本文模型对奶牛躯干和非奶牛躯干特征具有更强的区分能力,模型提取到的特征更为准确。

表2 本文模型与其他模型的奶牛躯干检测准确率
为进一步评价本文模型的识别效果,使用识别准确率P、识别召回率R以及单帧识别时间作为评价指标,并与其他模型进行对比,结果如表3所示。
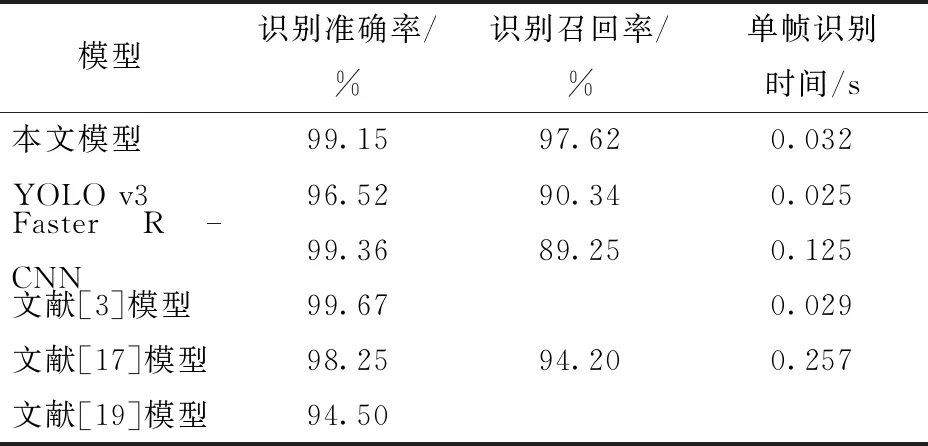
表3 本文模型与其他模型对奶牛爬跨行为的识别效果
由表3可知,本文模型比YOLO v3模型识别准确率提高了2.63个百分点,比YOLO v3模型召回率提高了7.28个百分点;与Faster R-CNN相比,本文模型识别准确率虽然降低了0.21个百分点,但召回率提高了8.37个百分点,单帧识别时间减少了0.093 s。在识别对象相同或相似的情况下,本文模型比文献[3]模型识别准确率降低了0.52个百分点,但本文模型具有较强的迁移性,比文献[17]的模型准确率提高了0.90个百分点,单帧识别时间减少了0.225 s,本文模型比文献[19]模型准确率提高了4.65个百分点。从识别速度上看,本文模型平均帧率为31 f/s,满足对奶牛发情行为识别的实时性需求。
3.5 模型性能分析
本文模型未识别的34幅图像中有28幅为奶牛发情行为存在遮挡的图像。遮挡会降低模型识别召回率的原因为:遮挡减少了模型可获取的发情爬跨行为特征,遮挡严重时模型无法提取到足够的特征信息来识别奶牛发情行为,从而发生了漏识别。图8为存在不同程度遮挡的奶牛发情行为识别结果,图8a、8b中存在部分遮挡的发情行为也能被很好识别出来,图8c为重度遮挡的发情行为,模型无法识别出发情行为。
为了对本文模型的抗遮挡能力进行定量评估,构建存在遮挡的奶牛发情行为样本集,样本集共有120幅存在不同程度遮挡的奶牛发情爬跨行为图像,使用样本集对本文模型进行测试,并与YOLO v3、Faster R-CNN进行对比,使用F1作为评价指标,测试结果为:本文模型为90.23%,YOLO v3为86.56%,Faster R-CNN为88.67%。本文模型抗遮挡能力比YOLO v3模型提高了3.67个百分点,比Faster R-CNN提高了1.56个百分点。进一步分析测试结果可知,由于奶牛发生爬跨行为时头部和背脊出现上扬,当图像中包含爬跨牛只头部和背脊信息,且爬跨行为被遮挡面积不超过40%时,则奶牛发情行为能较好地被本文模型所识别。
统计资料显示,奶牛夜间发情概率为60%~70%,本文模型对夜间奶牛发情也具有较好的识别效果,但仍有少量夜间发情行为未能被模型识别,测试集共有奶牛夜间发情行为图像530幅,其中有6幅图像未被识别,本文模型识别夜间发情行为的准确率为98.87%。图9为奶牛夜间发情行为识别结果,由图可知,图9a~9d中模型均能准确识别发生了奶牛爬跨行为,图9e、9f中模型未识别出爬跨行为。对比分析可知,出现这一情况主要是由于夜晚奶牛场光线较暗以及低亮度环境下相机记录的图像不清晰导致。后期可考虑在奶牛活动区加装照明设备或更换具有红外摄像功能的相机。
试验结果表明,本文模型具有较强的多尺度目标检测能力。这主要得益于特征提取网络的加深和多尺度特征融合的网络结构,本文模型通过加深特征提取网络,模型对大目标的检测性能得以提升,通过多尺度特征融合,模型增强了对不同尺度目标的检测能力。图10a为大目标尺寸的奶牛爬跨行为,图10b为目标尺寸偏小的奶牛爬跨行为,由图可知,模型均能准确识别出奶牛爬跨行为。
为进一步评价本文模型对不同尺寸目标的检测性能,构建多尺寸目标测试集,测试集共有450幅图像,其中小尺寸(宽:0~290像素,高:0~150像素)目标102幅,中等尺寸(宽:290像素~660像素,高:150像素~380像素)目标189幅,大尺寸(宽:660像素~1 000像素,高:380像素~540像素)目标159幅。使用测试集对本文模型进行测试,与YOLO v3、Faster R-CNN进行对比,以F1作为评价指标,测试结果如表4所示。
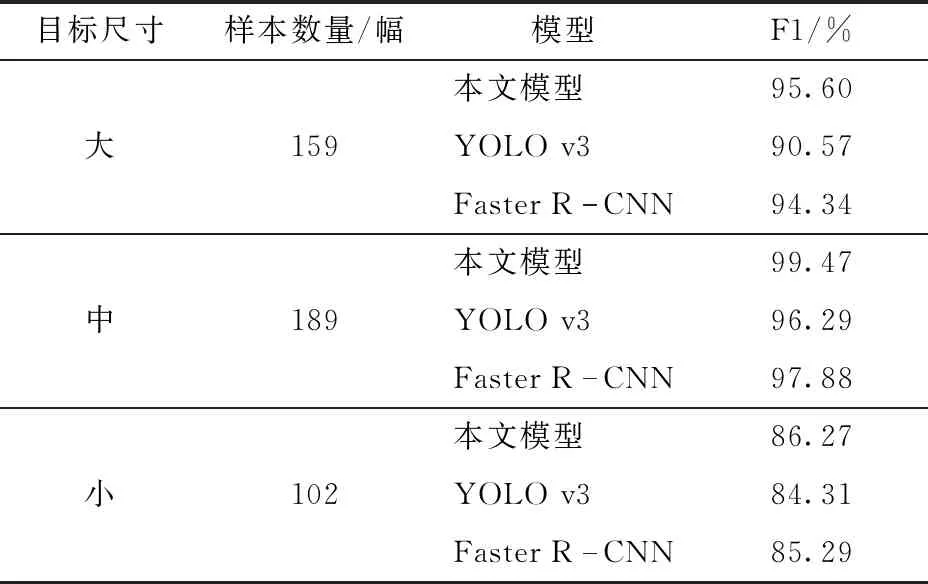
表4 不同尺寸目标的奶牛发情行为识别结果对比
由表4可知,本文模型多尺度目标检测性能优于YOLO v3、Faster R-CNN,尤其是在大尺寸目标检测方面,本文模型比YOLO v3提高了5.03个百分点,比Faster R-CNN提高了1.26个百分点。本文模型识别中等尺寸目标的F1为99.47%,高于Faster R-CNN的96.29%和YOLO v3的97.88%。本文模型识别小尺寸目标的F1为86.27%,分别比YOLO v3和Faster R-CNN提高了1.96个百分点和0.98个百分点。3种模型对小尺寸目标识别的F1都偏低,这是由于小尺寸目标距离摄像机较远,目标可用于提取的特征减少,模型无法获得足够的特征来识别发情行为,从而导致结果的F1偏低。为克服这一问题,进一步提高奶牛发情行为识别准确率,在后期研究中可考虑使用顶视角度采集奶牛活动视频。
4 结论
(1)根据奶牛发情行为数据集特点,对YOLO v3模型锚点框尺寸进行重新聚类和优化,同时引入DenseBlock改进特征提取网络,并使用由FIoU和两框中心距离Dc作为度量方法的边界框损失函数,提出了一种基于改进YOLO v3模型的奶牛发情行为识别方法。
(2)在测试集上的试验表明,改进后的模型识别准确率为99.15%、召回率为97.62%,比YOLO v3模型识别准确率提高了2.63个百分点、识别召回率提高了7.28个百分点,模型识别的平均帧率为31 f/s,能够满足实际养殖环境下奶牛发情行为的实时识别,与现有识别对象相同或相似的模型相比,本文模型具有较高的识别精度和较快的识别速度。
