融合深度学习和视觉文本的视频描述方法
2021-07-29付燕,马钰,叶鸥
付 燕,马 钰,叶 鸥
(西安科技大学计算机科学与技术学院,西安 710054)
视频是人类社会活动中最常用的信息载体,其中蕴含了丰富的信息[1]。随着互联网技术的发展及数码设备的普及,视频数据增长迅速,对视频内容的文本描述已成为一项艰难的人工工作。因此,如何通过计算机自动提取视频所表达的信息,已成为视频描述领域的研究热点。视频描述是一种对视觉内容高层语义理解的任务,旨在实现对视觉内容的高层语义认知与自然表达,涉及计算机视觉、机器学习、自然语义理解等研究领域[2]。视频描述在视力缺陷人群的辅助、视频检索、智能人机交互及机器人开发等方面都有广阔的应用前景[3]。
早期视频描述主要分为基于模板[4-5]和基于检索[6]这2种方法。基于模板的方法先检测视频中的物体、属性以及物体关系等内容,然后利用预定义的句子模板生成视频的文本描述。但是这种方法受到句子模板的限制,生成的文本描述多样性受限。基于检索的方法采用信息检索的方式生成文本描述。虽然这种方法能够得到与人工描述密切相关的文本,但是所得到的语句依赖于数据库的文本集合,并且不能生成新的文本描述。
近年来,随着深度学习的发展,受益于卷积神经网络[7](convolutional neural networks,CNN)在计算机视觉领域的发展,以及循环神经网络(recurrent neural network,RNN)在自然语言领域的进步,基于CNN和RNN的组合方法已广泛用于视频描述中[8-14]。其中S2VT模型[10]受到学者们的广泛关注。该模型的训练过程是端到端的,而且可以处理变长输入输出并能学习输入序列中的任意时间结构。但是该模型忽略了视频序列间的时序信息。为解决这个问题,Zhang等[11]提出了一种任务驱动的动态融合方法,可以根据模型的状态自适应地选择不同的融合模式,提升了视频描述的准确性;文献[12]首次将注意力机制嵌入到视频的文本生成描述中,可使视频的文本生成模型在生成文字序列时,能够决定视频特征的权值,提高了模型的性能;Li等[13]提出了一种基于残余注意力的长短期记忆(long short-term memory,LSTM)网络方法。该模型不仅利用现有的注意力机制,还考虑了句子内部信息的重要性;文献[14]提出了一种基于共同注意力模型的递归神经网络。该模型整合了注意力机制对视觉和文本特征进行了编码,在一定程度上提升了视频描述的正确性。但实验中发现以上研究方法仍存在一些问题:①使用VGG(visual geometry group)等二维卷积神经网络提取视频特征时只包含的视频的空间信息,忽略了视频序列之间的运动信息,且在提取细节特征时精度不高;②使用的语言模型结构较为简单,网络的性能还有提升的空间;③对视频主题等对视频内容至关重要的视觉文本没有加以利用。
针对上述问题,提出一种融合深度网络和视觉文本的视频描述研究方法。为了增强视频的细节信息,本文将通道注意力和空间注意力引入3D残差模块形成全新的深度网络体系结构提取视频的时序信息和运动信息;除检测物体的存在及其相对方向外,视频主题是另一个重要信息,将其与模型结合使用以提高字幕生成系统的效率。
1 融合深度网络和视觉文本的视频描述模型
提出一种融合深度网络和视觉文本的视频描述模型。①首先在编码阶段,将注意力模块与3D深度残差网络相结合,通过通道和空间两个独立维度的注意力模块,提取视频特征;②解码阶段利用双层LSTM深度网络的时序性特征,输出表述视频高层语义的文本描述;③为有效利用视觉文本信息丰富视频文本生成的语义描述,利用基于神经网络的主题模型提取出视频中的主题作为辅助信息融合进模型中,实化视频文本的生成描述,该方法的总体思路如图1所示。
1.1 基于注意力3D残差网络的视频特征提取
在早期的序列学习任务中,所有的输入信息都被编码成为固定长度。随着输入序列长度不断增加,模型的效果越来越差[1]。注意力机制的引入能够提升模型在序列学习任务上的性能,使得机器在处理视频的时候赋予模型在视频关键区域获得更高的权重[15],为此,采用注意力机制来改进深度残差网络,该网络能够依据注意力机制来描述信息重要程度,加强特征映射表达能力,即关注重要特征和抑制不必要的特征,从而降低无关目标与噪声的影响,以提高模型生成文本描述的质量。
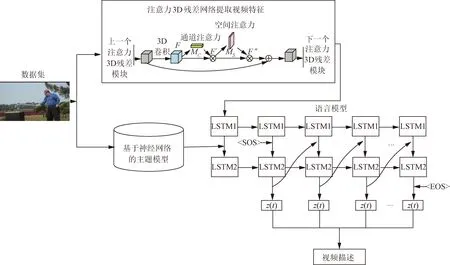
图1 融合深度网络和视觉文本的视频描述模型Fig.1 Video captioning model combining deep networks and visual texts
1.1.1 网络架构
注意力3D残差网络主体架构是由注意力模块和3D残差块相结合,构成注意力3D残差模块单元,这有利于堆叠成深度模型来提高网络性能。注意力3D残差网络是通过堆叠多个3D注意力残差模块构建的,使用ResNet-34作为基本的网络架构,避免了梯度消失的问题,还可以加速网络的收敛。3D ResNet-34网络采用32个卷积层即16个注意力3D残差模块堆叠,所以将模块数固定为16,每个3D注意力残差模块是通过向3D ResNets对应模块添加通道和空间注意力机制而生成的。3D卷积过程可以定义为

(1)
特征图3D卷积后依次通过通道注意力模块和空间注意力模块,最后以相加的方法输出,如图2所示。给定一个中间特征图F∈RC×H×W作为输入,其中C表示通道数,H和W分别表示特征图的高度和宽度,依次计算出一维通道注意图MC∈RC×1×1和二维空间注意图MS∈R1×H×W。注意力过程可以表示为[15]
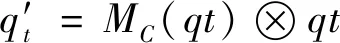
(2)
q″t=MS(q′t)⊗q′t
(3)
式中:⊗表示元素逐乘;q′t为通道注意力的输出;q″t为最终细化后的输出。为了进一步加速和稳定训练,在整个生成网络上创建额外的跳跃连接,将输入特征跳跃接入后续激活层,补偿特征损失。

图2 3D注意力残差网络整体架构Fig.2 The overall architecture of the 3D attention residual network
1.1.2 注意力模块
注意力模块是通过在通道和空间两个维度上进行建立的。由于特征映射间存在信息关联,可以得到相应的通道注意力映射。通过对中间特征图F∈RC×H×W中的每个通道信号进行加权来提高网络的学习能力,通道注意力集中在给定输入图像的有意义部分。为了更好地计算通道注意力,需要降低输入特征映射的空间维数,通过平均池化的方法联结空间信息,如图3所示。
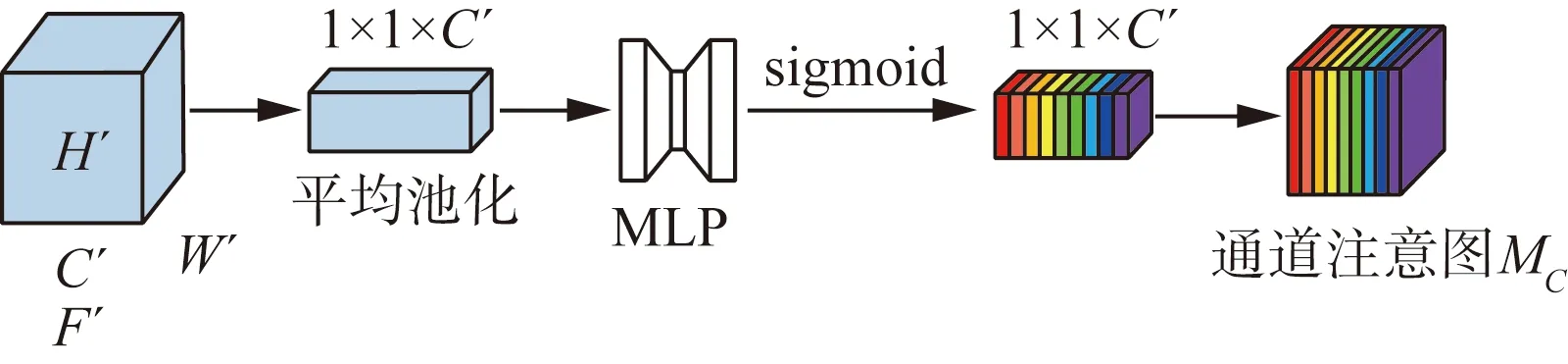
MLP表示多层感知器图3 通道注意力机制示意图Fig.3 The schematic diagram of channel attention mechanism
为有效捕获通道注意图,首先获得每个通道上平均像素值来表示该通道,将平均像素值送入一个两层的全连接层,最后通过一个sigmoid函数得到通道注意力映射。通道注意力公式为
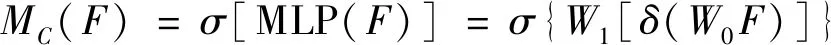
(5)
式(5)中:σ和δ分别表示sigmoid函数和ReLU函数;多层感知器(multi-layer perceptron,MLP)为两层的全连接网络;W0和W1为MLP的权重。
与通道注意力不同,空间注意力能注意到有效信息部分的位置。利用特征图内部空间之间的关系来推断空间注意力图,图4描绘了空间注意力图的特定计算过程。

图4 空间注意力机制示意图Fig.4 The schematic diagram of spatial attention mechanism
将通道注意力模块输出的特征图作为本模块的输入特征图,为有效计算空间注意力特征图,首先挤压特征图的通道信息以生成二维空间描述符,这是通过使用全局平均池化(Avgpool)实现的,然后使用卷积层来推断空间注意力图。空间注意力表达式为
MS(F)=σ{f7×7[Avgpool(F′)]}=
σ[f7×7(F′)]
(6)
式(6)中:σ表示sigmoid函数;f7×7为内核大小为7×7的卷积运算。
1.2 视觉文本的检测
为有效描述视频,需要从视频中提取尽可能多的信息,除检测视频中对象的存在,视频的主题也是重要信息之一。采用文献[16]的方法提取出视频中的主题作为视觉文本融合进模型中。文献[16]通过从图像中存在的各种语义相关对象中获取线索,将图像与主题向量相关联,建立基于神经网络的主题模型来处理提取的图像特征并生成主题向量,如图5所示。因此,将每个视频均匀采样10个视频帧,将其输入到在MSCOCO数据集上预训练好的基于神经网络的主题模型中,将其重复的词语删去并保留重复率高的主题词语作为视觉文本将其融入进模型中。
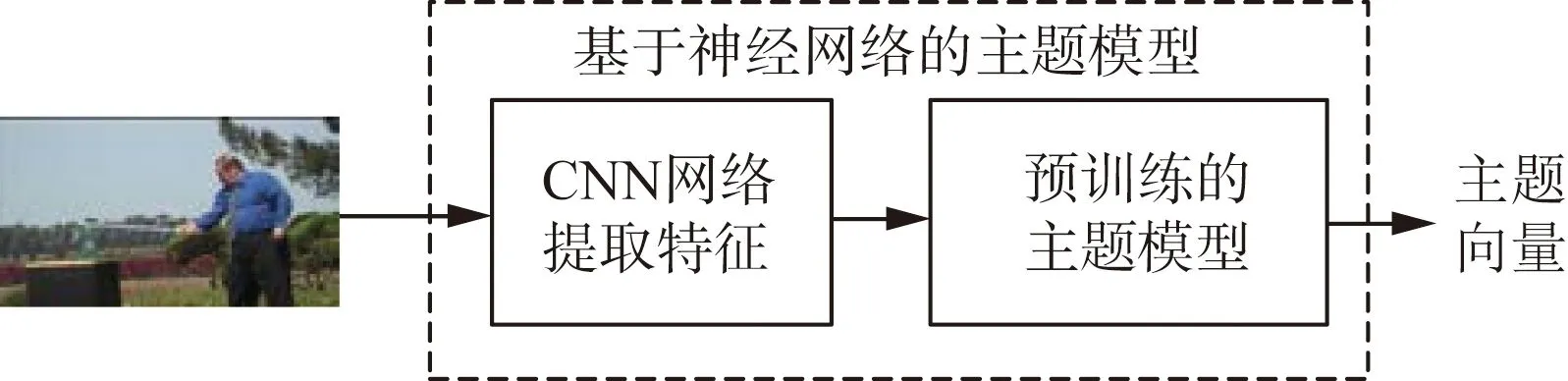
图5 视频中提取主题原理图Fig.5 Extract the theme schematic from the video
1.3 生成文本描述
大多数语言模型是以LSTM为基础进行解码的,将视频特征{x1,x2,…,xn}作为LSTM的输入。以第t帧为例,激活记忆单元,获得第t帧的LSTM单元各个状态的值,可表示为
it=σ(Wyiyi+Whiht-1+bi)
(7)
ft=σ(Wyfyi+Whfht-1+bf)
(8)
ot=σ(Wyoyi+Whoht-1+bo)
(9)
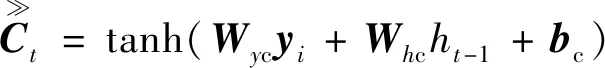
(10)
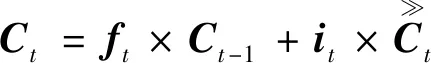
(11)
ht=ot×tanhCt
(12)

本文模型的解码器一共包含两层LSTM,第1层LSTM通过隐藏状态对视频的特征和词向量进行建模,其输出与视觉文本进行融合作为第2层LSTM的输入,第2层LSTM通过学习视频帧序列与词向量序列之间的映射关系,完成视觉特征和文本的关联建模。在解码阶段,将视频特征x={x1,x2,…,xn}输入到LSTM单元中,其输出经过softmax层(包含权重值ws和偏差bs)生成下一个时间节点上的单词y={y1,y2,…,ym},通过隐藏状态构造概率分布,其计算公式为
P(y1,y2,…,ym|x1,x2,…,xn)=
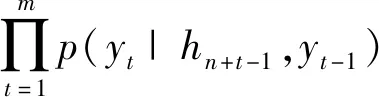
(13)
式(13)中:p(yt|hn+t-1,yt-1)为整个单词表在softmax层对应的输出概率,其中hn+t-1和yt-1是根据LSTM计算得出的。
使用“SOS”和“EOS”标记作为LSTM生成单词开始词和结束词,通过式(14)来调整模型参数。
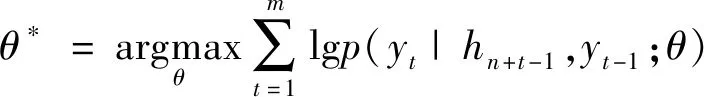
(14)
式(14)中:θ泛指LSTM内部参数。通过第2层LSTM的softmax函数选取模型每一时刻的输出中概率最大的词连接成为文本描述,作为输出结果。
2 实验结果与分析
为验证算法的准确性,所设计的实验包括基准数据集与监控场景下的视频语义描述。选择MSVD和MSR-VTT作为基准数据集来验证算法的准确性,通过将本文算法与文献[8]、S2VT[10]、TDDF(task driven dynamic fusion)[11]、Res-ATT[13]方法进行对比来验证。
2.1 数据集和参数设置
分别在煤矿井下监控和两个公共数据集上进行对比实验。将煤矿井下监控视频制作成大小统一的视频数据,人工对视频标注标签,每个视频时长在10 s,对每个视频生成3句场景描述的句子。目前在视频描述数据中公开的有MSR-VTT(microsoft research-video to text)数据库和MSVD(microsoft video description corpus)数据库。MSR-VTT数据集是从商业视频搜索引擎收集的,包含10 000个视频片段,被分为训练,验证和测试集3部分。MSVD包含1 970段YouTube视频片段,视频主要来自于日常场景,每个视频时长在10~25 s,每段视频被标注了大概40条英文句子。随机选择1 200个视频作为训练集,100个视频作为验证集,670个视频作为测试集。
使用ResNet-34作为基本的网络架构,输入为RGB通道彩色视频帧并随机裁剪成128×128的视频帧块,批量大小设定为16。使用pytorch训练模型,采用cuda 与cuDNN进行加速。实验采用AdaMax优化器训练3D注意力残差网络,在优化其中将模型中的β1和β2分别设置为0.9和0.999,开始学习率设置为0.001,随着训练过程不断降低学习率。
2.2 评价方法
选择目前主流的试验评价标准BLEU(bilingual evaluation understudy)[17]和METEOR(metric for evaluation of translation with explicit ordering )[18]。BLEU通常使用在机器翻译中,有多种变体,与人类判断有较好的相关性。该评价的思想是以独立于位置的方法,来衡量和候选短语n-gram之间的相似性。METEOR是基于召回率提出的,是对候选句子和参考句子之间位置对应关系的评估。基于召回率的标准与基于精度的标准相比,其结果与人工判断的结果具有较高的相关性。
2.3 实验结果与分析
2.3.1 在公共数据集下
表1为2个公共数据集下使用不同提取特征网络的比较结果。结果表明,使用单通道注意子模块的准确性要优于使用单个空间注意子模块,并且两者都比原始网络高。同时添加通道注意图和空间注意图可以进一步提高性能。这是因为注意力机制在长范围相关性上的优势,将注意力模块与深度残差网络相结合,对于输入的特征图而言,分别进行通道维度和空间维度的注意力模块操作,可以得到精细化的特征输出图。
从表2可以看出,在MSVD和MSR-VTT数据集中,模型在BLEU-4和METEOR评价标准上都得到了较高的分数,评价标准取得的分数越高,说明该模型越好。这是因为用于特征提取的3D注意力残差网络,通过一维通道注意力与二维空间注意力增强视频特征映射,包含了丰富的时序特征和运动特征,降低无关目标与噪声的影响,增加了相似视频的区分度。丰富的视频主题信息作为视频的重要组成部分,将其作为补充信息融入解码阶段,进一步优化了模型的描述效果。
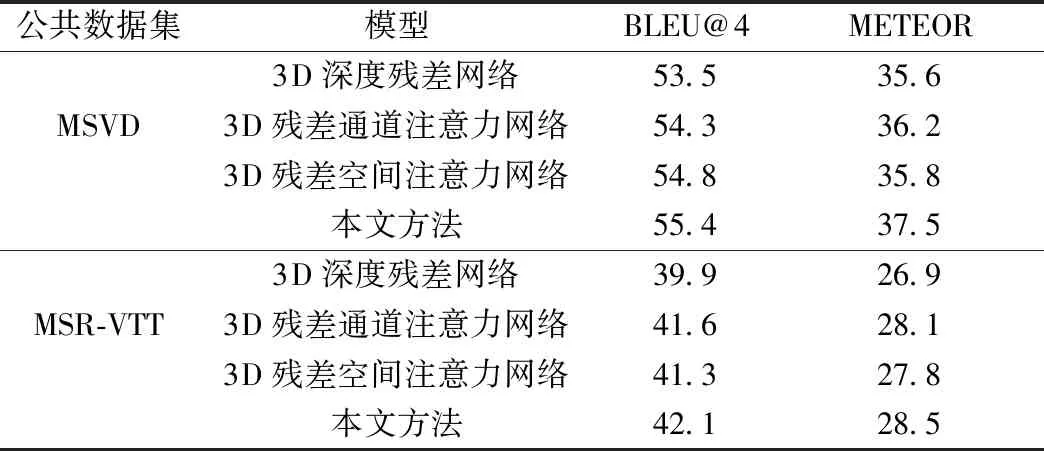
表1 MSVD、MSR-VTT下不同提取特征网络模型的对比Table 1 Comparison of different extracted feature network models under MSVD,MSR-VTT

表2 MSVD、MSR-VTT数据集实验结果比较Table 2 Comparison of experimental results of MSVD,MSR-VTT data set
本文模型对数据集的3组视频文本描述结果如图6所示。选取的视频主要来源于MSVD数据集。由图6可知,本文模型在公共数据集下除了能够比较准确描述出视频的内容外,还能在语法结构上突出语言的丰富性,这体现了本文模型较好的语言效果。

图6 公共数据集下的视频描述Fig.6 The video description under the public data set
2.3.2 在煤矿监控视频数据集下
在提取煤矿井下视频特征时,分别使用3D残差网络、3D残差通道注意力网络、3D残差空间注意力网络和本文模型相比。从表3可以看出,在煤矿井下监控视频中,本文模型较传统的3D深度残差网络模型,在BLEU评价指标下提升了2.1%,METEOR指标提升了2%。这是因为将注意力模块与深度残差网络相结合,对于输入的特征图而言,分别进行通道维度和空间维度的注意力模块操作,最终得到精细化的特征输出图,该模块不会改变特征图的大小,但是能够自适应调整通道上特征的权重和捕获空间维度上像素之间的相关性,从而降低无关目标与噪声的影响,更有利于从煤矿视频中提取特征。
从表4可知,在BLEU评价指标下,本文模型较S2VT方法提升6.4%,较文献[8]方法提升了3.9%。此外,在METEOR评价指标上也存在着显著的提升。由实验结果可知,本文方法在煤矿井下监控视频中更具竞争力,各指标都有一定的提升。

表3 煤矿数据集下不同提取特征网络模型的对比Table 3 Comparison of different extracted feature network models under coal mine data sets
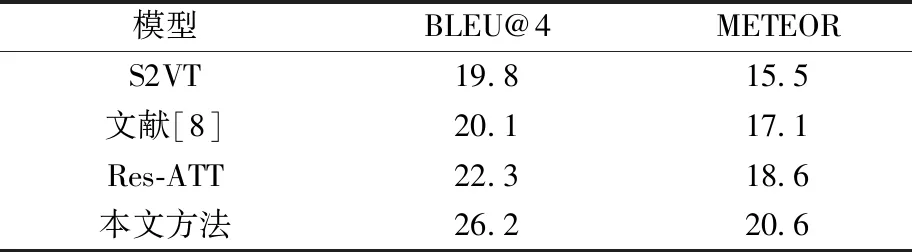
表4 煤矿井下监控视频实验结果比较Table 4 Comparison of experimental results of monitoring video in coal mine
从图7可以看出,煤矿井下监控视频通常含有字幕信息,这对于准确描述视频信息起着至关重要的作用。生成的描述结果表明,本文模型能够较准确地描述视频中物体之间的关系。本文方法通过对语言模型进行补充,将LSTM语言模型和视频提取的字幕相组合生成描述,极大丰富了视频的语义,为以后检索煤矿井下监控视频提供了一定的帮助。

图7 煤矿井下监控视频描述Fig.7 Video description of underground monitoring in coal mine
3 结论
将深度网络和视觉文本融合起来对视频进行试述,得到以下结论。
(1)本文方法在提取视频特征时,提出一种新的网络体系:注意力3D残差网络,该网络通过一维通道注意力与二维空间注意力增强视频特征映射,降低无关目标与噪声的影响,提高模型生成描述的质量。分别在煤矿井下监控视频集和两个公共数据集进行实验,结果表明,使用注意力3D残差网络描述视频比较传统的3D深度残差网络模型更好。
(2)为有效利用视觉文本信息丰富视频生成的语义描述,利用基于神经网络的主题模型将代表视频主题的词语作为辅助信息融合进模型中,通过本文方法与之前4个基线模型进行对比,结果显示了本文模型在BLEU和METEOR这两个指标上的得分都有所提高,能够更加准确的利用自然语言描述视频高层语义信息。
