布料色卡图像检索的深度学习模型
2021-07-29崔梓晗魏昕怡邱桃荣邹凯
崔梓晗,魏昕怡,邱桃荣,邹凯
(南昌大学a.信息工程学院;b.际銮书院,江西 南昌 330031)
布料制品以及布料制品加工行业对人们的日常生活以及国家的发展都有着非常重要的作用。基于内容的色卡图像检索已经得到应用,但实际应用中由于不同用户所获得的色卡图像与样本库图像之间存在诸如不同旋转角度或不同分辨率等实际问题,而对这些色卡图像进行检索的准确率将会出现明显下降,检索效果难以满足实际需要。因此为满足布料生产和销售领域对布料色卡图像检索的需求,针对该领域存在的实际问题,研究对旋转和分辨率具有不变性的检索方法具有重要的应用价值[1-2]。
由于深度网络模型具有不依赖于复杂的特征工程、可充分挖掘图像的特征信息等特点,为了能有效地解决在箱包制造领域进行的布料色卡图像检索中所出现的上述问题,本文提出基于深度学习的布料色卡图像检索模型和检索方法,旨在能让具有不同旋转角度和不同分辨率的布料色卡图像具有较高的检索准确率和系统鲁棒性以及较好的检索时间性能。为寻求最佳的分类模型,本文较详细研究了AlexNet[3-5]、GoogleNet[6-8]、LeNet-5[9-10]3种目前先进和流行的深度学习网络,并对LeNet-5进行改进,以解决在利用LeNet-5原始模型时由于卷积核数量较少和网络层数偏少等导致LeNet-5对稍复杂图像识别准确率不高及检索效果不理想的问题。另外,为解决训练过程中可能会产生的过拟合问题,本文在进行对比分析时,结合稀疏化Dropout方法对图像样本数据库进行优化处理。
1 3种深度学习网络模型简介
1.1 AlexNet网络框架介绍
AlexNet训练了一个端对端(End to End)的卷积神经网络模型,实现对图像特征的提取和分类,网络结构一共8层,包含了5层卷积层和3层全连接层。网络结构如图1所示。
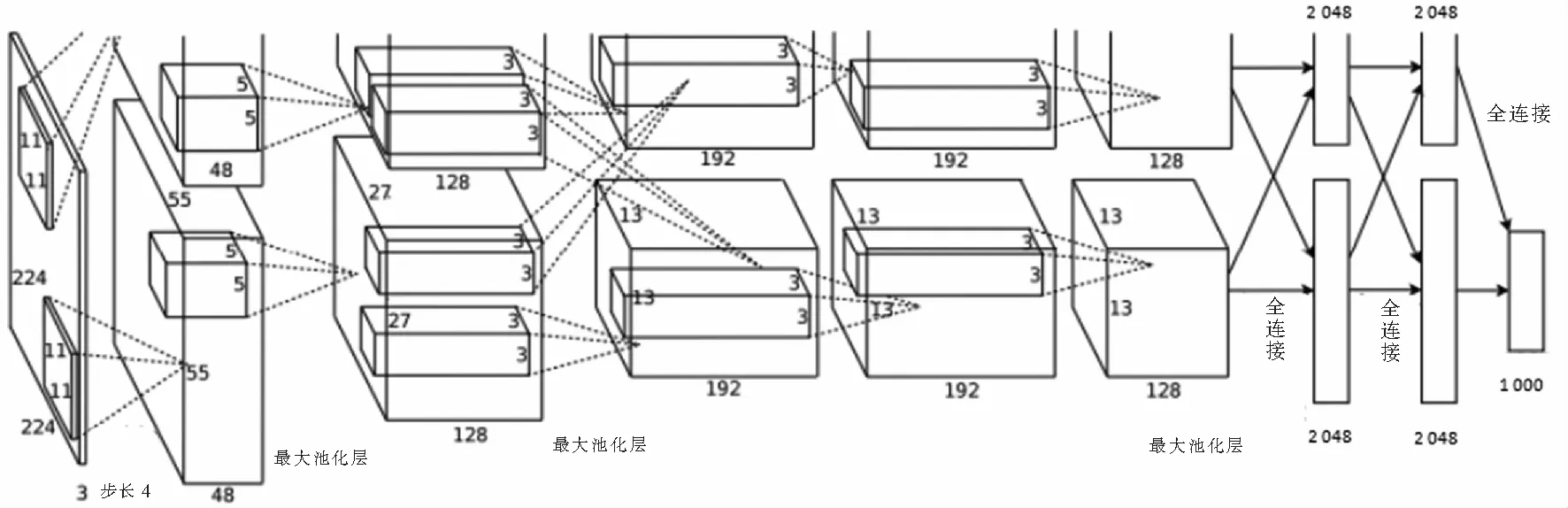
图1 AlexNet结构图Fig.1 AlexNet convolutional neural network
与传统的卷积神经网络结构相比,AlexNet进行了以下3点改进:1)AlexNet在层7和层8后加入了Dropout,Dropout通过随机丢弃一部分神经元,降低网络复杂度,以改善网络的过拟合问题;2)增加了LRN即局部响应归一化处理;3)使用了ReLU作为激活函数,代替了传统的tanh和sigmod函数,ReLU函数能够有效地增加函数的稀疏性,可以抑制过拟合问题的产生,并且减少参数相互依存的关系。
1.2 GoogLeNet网络框架介绍
GoogLeNet是在LeNet-5神经网络模型的基础上,通过加深网络模型的深度和宽度所构建的一种深度卷积神经网络模型。该网络加深了LeNet模型的深度,使带参数的层达到22个,独立成块的层总共有100多个。GoogLeNet通过设计Inception模块[11],引入了多尺度卷积提取多尺度局部特征。Inception模块的结构如图2所示。
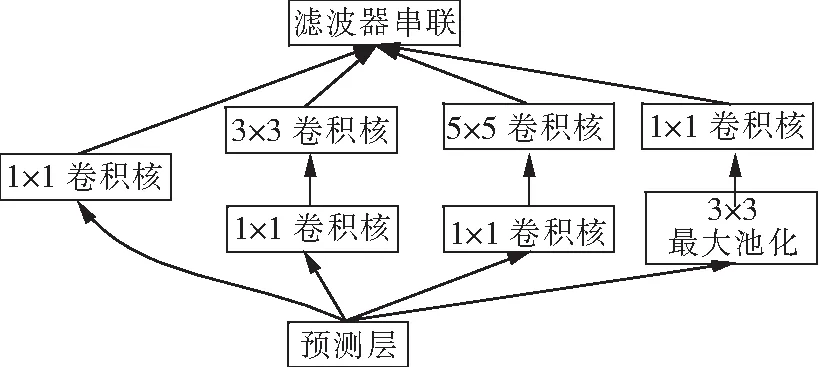
图2 Inception模型Fig.2 Model of Inception
1.3 LeNet-5结构简介
LeNet-5网络模型是Cun等提出的一个卷积神经网络。它是一种特殊的多层神经网络,训练方式跟其他神经网络一样都是通过反向传播进行训练,不同点是它的结构,其最大特点就是权值共享,这大大减少了参数结构,加快了学习训练的过程[12]。LeNet-5的结构如图3所示。
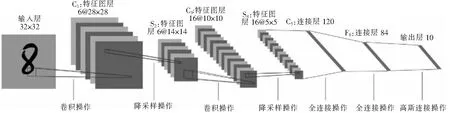
图3 LeNet-5结构图Fig.3 LeNet-5 convolutional neural network
LeNet-5网络模型除了输入层,共有7层带参数的层结构,包括5层卷积层和2层全连接层。输入时32×32的像素矩阵,每层卷积都是采用了5×5的卷积核对图像进行卷积操作,池化层则采用2×2的池化窗口对提取到的卷积层特征进行最大下采样池化。最后输出层由欧式径向基函数(euclidean radial basis function)单元组成,每类是一个单元,有84个输入。也就是说,每个输出径向基函数单元计算输入向量和参数向量之间的欧式距离。如果输入离参数向量越远,径向基函数的输出也就越大。
2 LeNet-5网络框架优化和稀疏化Dropout结构
2.1 LeNet-5网络框架优化
本文从两个方面对LeNet-5框架进行了改进和优化,分为网络框架优化和网络内部优化两个方面。网络框架的优化包含两种方向的优化:纵向优化和横向优化。首先将网络的输入改成224×224的像素矩阵,以便容纳更多的图像纹理信息。横向优化指的是将C1层和C3层的卷积核个数分别由原来的6个和16个增加至64个和128个。纵向优化指的是在现有C1、C3卷积层的基础上额外增加了C5、C7卷积层,增加了网络的深度,更好地提取图像的特征信息,C5、C7层的卷积核个数分别为256个和512个。由于LeNet-5网络设计的原始目的是用于手写数字的识别,相对于本文的纹理数据集图像而言,手写数字涵盖的特征信息较少,为了提高网络的识别效果,本文同时增加了LeNet-5网络的深度和每层卷积核的个数,使网络能够更好地提取纹理图像的特征。网络内部优化方案:1) 每两次卷积的输出之后对数据进行局部相应归一化处理,即增加LRN(local response normalization)层。2) 全连接层采用的maxout[13]激活函数来代替之前的欧式径向基函数。同时,我们将改进之后的模型命名为LeNet-M模型,LeNet-M的框架结构如图4所示。

图4 改进后的LeNet-M结构图Fig.4 Improued LeNet-M convolutional neural network
在传统的神经网络中采用的激活函数一般是sigmod、tanh、ReLu等,与这些激活函数相比,maxout函数具备一些上述激活函数不具备的性质:1)maxout激活函数不是一个固定的函数,没有固定的函数方程。2) maxout函数是一个可学习的激活函数,W参数是可以学习变化的。Maxout激活函数输出本层一个节点的表达式为:
(1)
其中:x∈Rd×n,W∈Rd×m×k,b∈Rm×k;d、m、n分别为上一层节点个数、本层节点个数和输入的样本个数;k为每个隐层节点对应了k个“隐含层”节点。这k个“隐含层”节点都是线性输出的,而maxout的每个节点就从这k个“隐含层”节点输出值中取最大值。3) maxout函数是一个分段线性函数。由于maxout函数是一个分段线性函数,所以maxout函数具有非常强的拟合能力,它可以拟合任意的凸函数。maxout网络不仅可以学习到隐层之间的关系,还可以学习到每个隐层单元的激活函数,它放弃了传统激活函数的设计,产生的表示不再是稀疏的,但是它的梯度是稀疏的,结合Dropout也可以将它稀疏化。maxout网络中的线性和最大化操作可以让Dropout的拟合模型的平均精度很高。
2.2 稀疏化Dropout结构
考虑本文所使用的两个标准纹理数据集和一个实际采集的色卡图像样本数据集中的样本数据量偏少,如果在这样不够多的数据集上训练,则训练得到的模型容易存在过拟合现象,这影响本文研究目标的实现。而Dropout正则化方法[13-14]能有效地防止过拟合的问题,该方法是在神经网络训练阶段,前向传播过程中以概率P=0.5随机删除掉部分节点。稀疏化Dropout结构的概念首次在文献[14]中被提出,即对模型的某一层施加稀疏性限制时,取这一层所有节点激活值的中值,将大于中值的节点定义为高激活值节点,小于中值的节点则定义为低激活值节点。高激活值节点表示网络对样本感兴趣的部分,也是主要的保留节点,而低激活值节点表示网络不感兴趣或者兴趣较弱的部分,所以本文选择随机删除部分低激活值的节点,而不再采用所有节点都以相等概率被删除的方式。
3 布料色卡图像检索模型
本文提出的基于深度学习网络模型分类器来实现布料色卡图像检索的模型,布料色卡图像检索模型如图5所示。
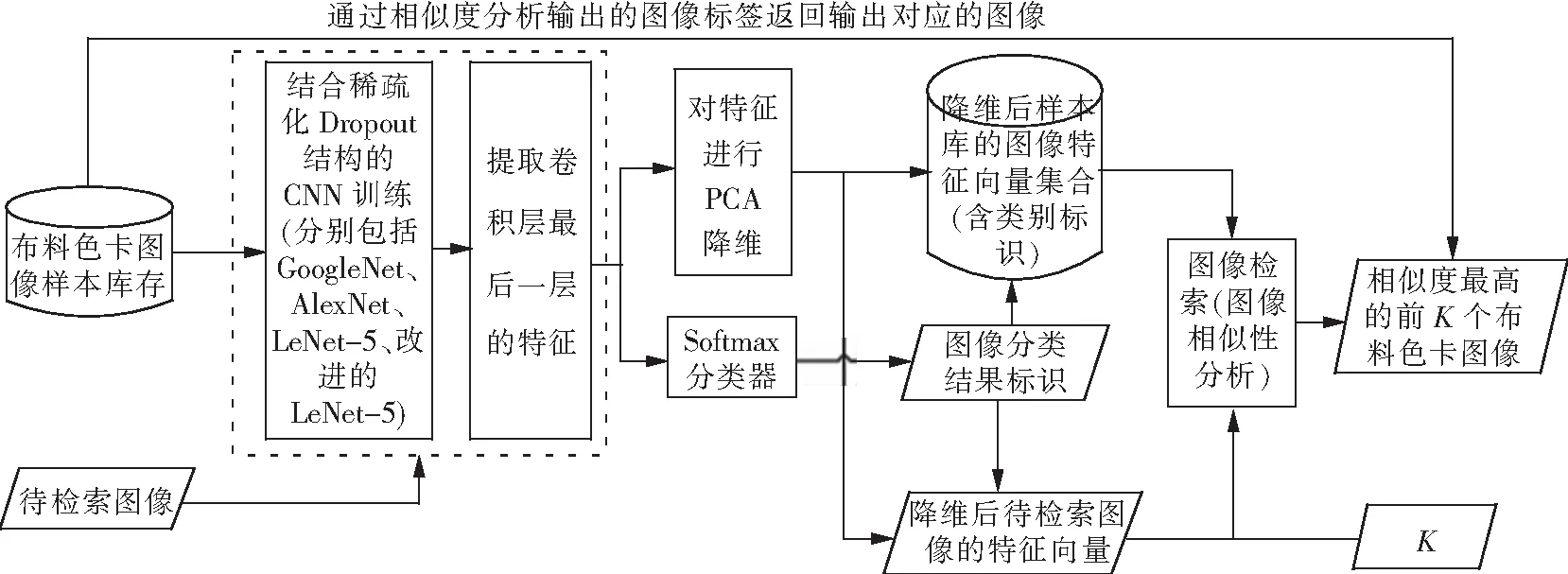
图5 布料色卡图像检索模型图Fig.5 Retrieval model of fabric image
模型的工作流程主要分为两部分:一是基于稀疏化Dropout结构的CNN训练的模型构建;二是图像检索。
第一流程涉及以下4个关键技术步骤。
1) 样本数据归一化处理:将布料色卡图像样本库中的所有图像全部归一化为224×224像素的图像,并作为深度学习网络模型中的输入数据。
2) 结合稀疏化Dropout结构的CNN训练进行模型构建。
3) 特征提取和特征降维。对经过训练构建的模型,首先,对最后一层的4 096维的特征进行提取与保存。本文采用了GoogLeNet、Alexnet、LeNet-5以及改进后的LeNet-5等4种不同的网络模型来分别提取最后一层的4 096维特征,构建布料色卡图像特征集合。其次,考虑所提取得到的图像特征维度过高,不仅占用较大的存储空间而且影响后续的检索系统效率。因此,本文将此特征进行PCA降维,对图像数据库中的图像降维之后得到的特征,根据其类别标识建立对应的图像特征向量集合。
4) 带有类标的降维后的图像特征向量集合构建。对步骤3)得到的每个样本的降维特征,结合基于Softmax函数的样本分类标识构建每个样本的特征向量,形成样本特征向量集合。
第二流程实现对色卡图像的检索。该流程包括以下关键环节。
1) 待检索图像的特征向量生成。首先,选取对未经任何处理的可以具有任意旋转角度或不同于样本图像分辨率的待检索的色卡图像作为上述构建模型的输入。其次,基于上述模型通过CNN提取待检索图像的4 096维的特征向量,然后将提取到的特征向量输入至Softmax分类器,得到分类器输出的分类结果标识,同时将该特征向量也进行PCA降维得到降维后的待检索图像特征向量,并结合预测分类标识构建待检索图像的特征向量。
2) 基于待检索图像特征向量进行图像检索。采用计算其欧式距离的方法,在样本特征向量集中与待检索图像特征向量按照事先设置的检索阈值K获取最相似的K张样本图像。N维空间里两个向量X(x1,x2,…,xn)与Y(y1,y2,…,yn)之间的欧氏距离计算公式为:
(2)
4 模型的对比测试与结果分析
4.1 图像样本数据简介和数据增强处理
布料色卡图像是从实际企业收集得到的真实布料色卡图像数据集,通过EPSON PERFETION V10全彩扫描器对每张布料色卡扫描得到共有接近1 500张图像。包括布料皮革包TC棉布、罗缎、桃皮绒印花布、夏布及各种中高档箱包面料。这些布料图像纹理多样,是最真实、客观的测试集。
Brodatz自然纹理库是由Brodatz在对纹理图像进行研究过程中收集整理而成的。该纹理库中的图像都是灰度图像,其中包含112种不同纹理的纹理图像,每幅图像大小为640×640像素。
UIUC纹理库中包含25类纹理,每种类型的纹理因不同的旋转角度、光照条件、视角方位、远近尺度采集了40张图像,每张图像的像素尺寸大小为640×480。UIUC中的纹理是现实生活中和自然界常见的纹理,非常客观真实,能够有效地检测识别算法的有效性。
为了避免上述模型存在过拟合问题,本文对图像样本进行增强处理。以布料色卡图像数据集增强为例,由于企业提供的色卡图像数量多,但是类别少,本实验只选取了100张类别区分较为明显的色卡图像,将这100张图像全部归一化为108×108分辨率大小的图像,然后对这100张图像每张图像进行数据增强。首先在原图像上随机截取25张42×42、48×48、56×56、64×64、72×72、80×80、88×88、96×96等8种不同的小于原图分辨率的图像,然后将原图进行放大从108×108开始,每隔16×16分辨率放大一次,一直到512×512,最后将100张原图进行旋转,每隔5°将原图像旋转一次,可以得到72张不同旋转角度的图像。最终每一类得到323张图像,总共32 300张图像的数据集。
4.2 对比的非深度学习方法选择和模型性能测试方法说明
本文用上述3种纹理图像样本集进行模型性能测试,采用十折交叉验证的方法进行。每种类型的样本集通过数据增强后,随机划分为10份,其中9份做训练集,余下的1份做测试集,记录实验结果。以上操作交替进行10次,然后取10次结果取平均值即为最终得到的实验结果。
为了验证所提出的模型的有效性,本文采用基于传统机器学习的方法在上述3种样本集上进行测试和结果分析。本文选取CLBP方法[15],该方法包含CLBP-C、CLBP-S、CLBP-M 3个描述子,将这3个描述子经过不同的串并联方式融合其直方图得到整张图像的特征,然后将这些特征分别采用逻辑回归(logistics regression,LR)、k最近邻(KNN,k-nearest neighbor)、支持向量机(support vector machine,SVM)、朴素贝叶斯模型(naive bayesian,NB)等分类器进行分类测试。文献[15]的实验表明,CLBP-S/M/C方式融合的特征直方图,能够取得一个最佳的识别效果,本文同样是采用了这样的特征融合方式。测试方法同样是十折交叉验证的方法,交替进行10次实验,实验结果取平均值即为最终得到的实验结果。
4.3 不同改进方法在3种纹理数据集上的对比实验分析
本文分别对LeNet-5网络在4个地方进行了改进,分别是每两次卷积输出之后对数据进行局部归一化处理(记为LeNet-5+LRN)、使用maxout激活函数代替原来的欧氏径向基函数(记为LeNet-5+Maxout)、采用了稀疏化的Dropout结构(记为LeNet-5+稀疏化Dropout)以及最后结合全部3种改进之后的LeNet-M模型。本文使用改进方法,分别在3个纹理数据集上进行了实验分析,实验结果如表1所示。

表1 不同改进方法在3种数据集上的实验结果Tab.1 Experimental results of different improved methods on three texture data sets %
可以看出,本文做出的每一种改进在3个纹理数据集上均较原网络结构有一个更好的识别效果。三者结合之后的LeNet-M模型较原网络结构的识别效果有了更加明显的提升。
4.4 8种不同分类方法在3种纹理数据集上的对比测试与结果分析
采用4种基于深度学习的方法,包括改进的LeNet-5和4种非深度学习方法,包括3种不同K值(本文实验了K值从1至10,其中当K值取3、4、5时测试结果最好)的KNN方法在3种纹理图像数据集进行对比测试结果如表2所示。

表2 8种不同分类模型的测试结果Tab.2 Classification results for three data sets %
可以看出,对3种数据集的分类效果最好的是GoogLeNet,它对3个数据集都有一个极好的分类效果,而本文提出的LeNet-M模型也有一个较好的分类效果,在对3个数据集的分类效果上几乎是跟AlexNet模型相媲美,在Brodatz数据集的识别上,甚至还优于AlexNet网络。
4.5 不同分辨率的图像的分类测试及结果分析
本实验对不同分辨率大小的图像也能够做到很好的适应性分类。表3是8种不同分类模型对Brodatz数据集的测试结果。Brodatz数据集的测试集,从330×330分辨率开始,每隔30×30分辨率截取一次,每张原始图像截取5张图像充当测试集,测试集共包含6种分辨率低于原始图像的图像以及4种分辨率高于原始图像的图像,每一类分辨率图像包含350张图像,将对每一类图像进行单独测试。Avg、δ分别表示该方法的准确率的平均值及方差。
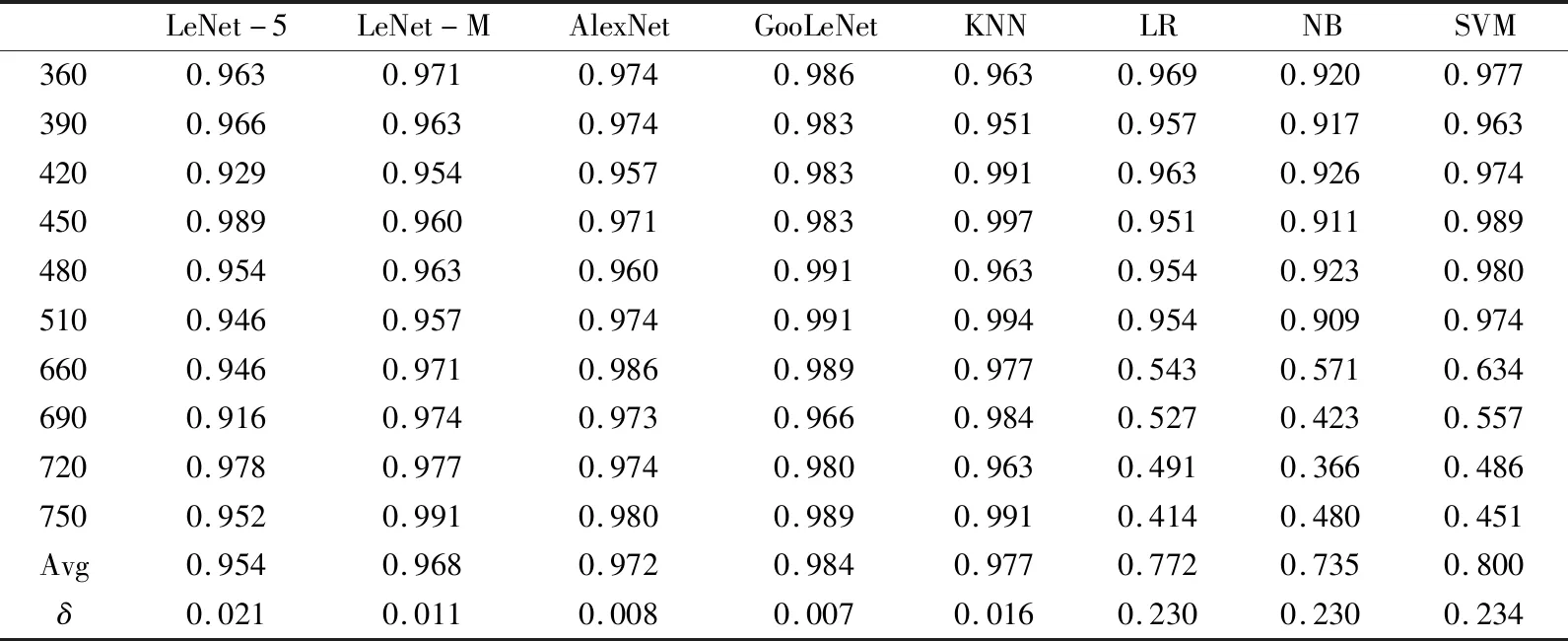
表3 对Brodatz数据集不同分辨率大小测试结果Tab.3 Test results for different resolution sizes of Brodatz
对于UIUC数据集,UIUC数据集原始图像均为640×480大小的图像,其训练集选取了一共6种分辨率低于原始图像以及5种分辨率高于原始图像的图像。而测试集则采用从270×270分辨率开始每隔30×30分辨率大小分别截取了270×270,…,580×580,610×610,共计9种不同大小分辨率图像,每种分辨率图像110张,共计990张测试图像。这些测试图像中包含3类比原始数据集图像大的图像以及6类比原始数据集图像小的图像。对UIUC测试结果如表4所示。
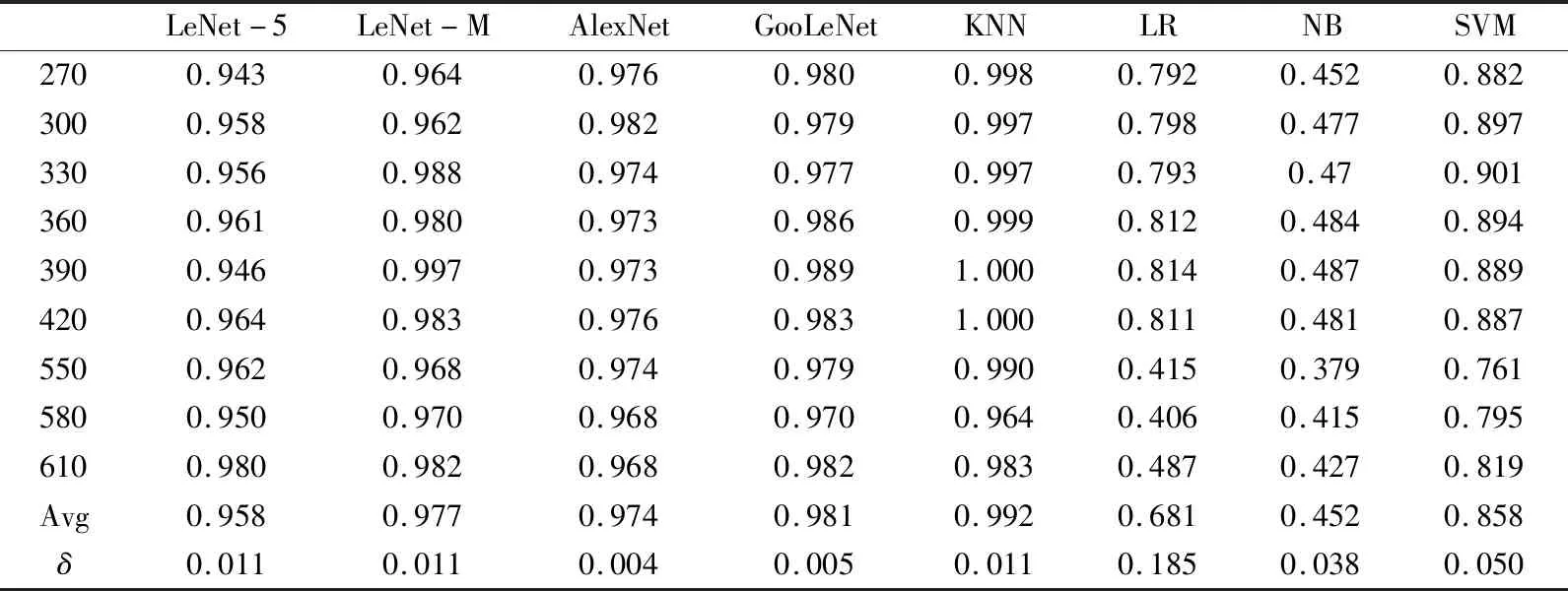
表4 对UIUC数据集不同分辨率大小测试结果Tab.4 Test results for different resolution sizes of UIUC
对于布料色卡图像数据集,由于该数据集是从实际企业收集得到的真实布料色卡图像数据集,因此色卡图像杂乱不规范,本文将所有得色卡图像归一化为108×108分辨率大小。色卡图像训练集包含5种低于原始图像分辨率以及5种高于原始图像分辨率的图像。对于低于原始图像分辨率的,从40×40分辨率开始,每隔10×10截取一次,每次5张图像;对于高于原始图像分辨率的,从120×20开始,每隔60×60分辨率截取一次,同样每次5张图像。对布料色卡图像测试结果如表5所示。

表5 对布料色卡图像数据集不同分辨率大小测试结果Tab.5 Test results for different resolution sizes of fabric image
综合表3~表5,通过Avg和δ两个值可以看出,深度学习模型与KNN算法在不同的分辨率图像的分类准确率均值很高,而且标准差很小,稳定性很好。同时,从上述表中的数据也表明,经过横向和纵向优化之后的LeNet-M网络,即使是在不同分辨率的泛化性能上,也比最初始的LeNet-5网络效果更好。对于不同分辨率纹理图像,LeNet-5、LeNet-M、AlexNet、GoogLeNet、KNN模型始终能够保持极佳的分类效果,而SVM、LR、NB等则识别效果较差,最高不超过60%的准确率。造成以上结果的原因可能是低于原图分辨率的图像都是原图裁剪出来的,完整地保存了每个区域中像素点的位置以及联系,与原图像一致,通过原图像训练好的模型对原图上截取的图像分类效果理所应当。然而图像放大和裁剪不一样,图像放大是通过线性插值的方法不断往图像中插入像素点,这样极大地破坏了原图中像素点之间的结构,导致获取到的CLBP特征产生极大的差异,从而致使分类效果不佳。
4.6 对不同旋转角度的测试及结果分析
本测试的训练纹理图像,选取每隔5°旋转一次,每一类的训练集中包含原始图像的旋转5°、10°、15°、…、360°等共计72张不同角度的旋转图像。72个旋转角度的图像(0°、5°、10°、15°、…、360°),每个旋转角度有990张图像,而测试集则采用训练集中没有的旋转角度的图像作为测试,选取14个旋转角度(12°、24°、36°、…、168°)的旋转图像作为测试。对Brodatz、UIUC、布料色卡图像数据集的测试结果分别见表6~表8所示。
从表6~表8的Avg和δ可以看出4个深度模型对不同旋转角度的测试图像,均能达到一个极佳的识别效果,而且稳定性很高,标准差基本上都在0.03以下,其中LeNet-M模型在不同的旋转角度的图像分类上,稳定性以及准确率都比LeNet-5模型的效果要好。而其他机器学习的分类算法,只有KNN算法对以上3个数据集的分类效果偏好,但是分类效果不稳定,对某些特定的角度分类准确率低于50%。然而LR、NB、SVM等分类算法对以上3个数据分类准确率极低,无法应用于商用。这是由于KNN、SVM、NB、LR等分类算法都是基于事先提取好的LBP特征,随着图像角度的变化,提取到的LBP特征也发生了极大的变化,因此造成这4个分类算法分类效果的不稳定。而产生KNN算法这样的不同于其他3个分类器的分类效果的原因可能是因为KNN的算法实现过程决定的。KNN算法过程是当输入测试样本是,先计算出训练样本中距离和测试样本最近的K个样本,这K个样本属于某个类别的样本数量最多的类别即为测试样本的类别[20]。因而KNN对相似性的图片分类本就具有非常好的泛化效果。
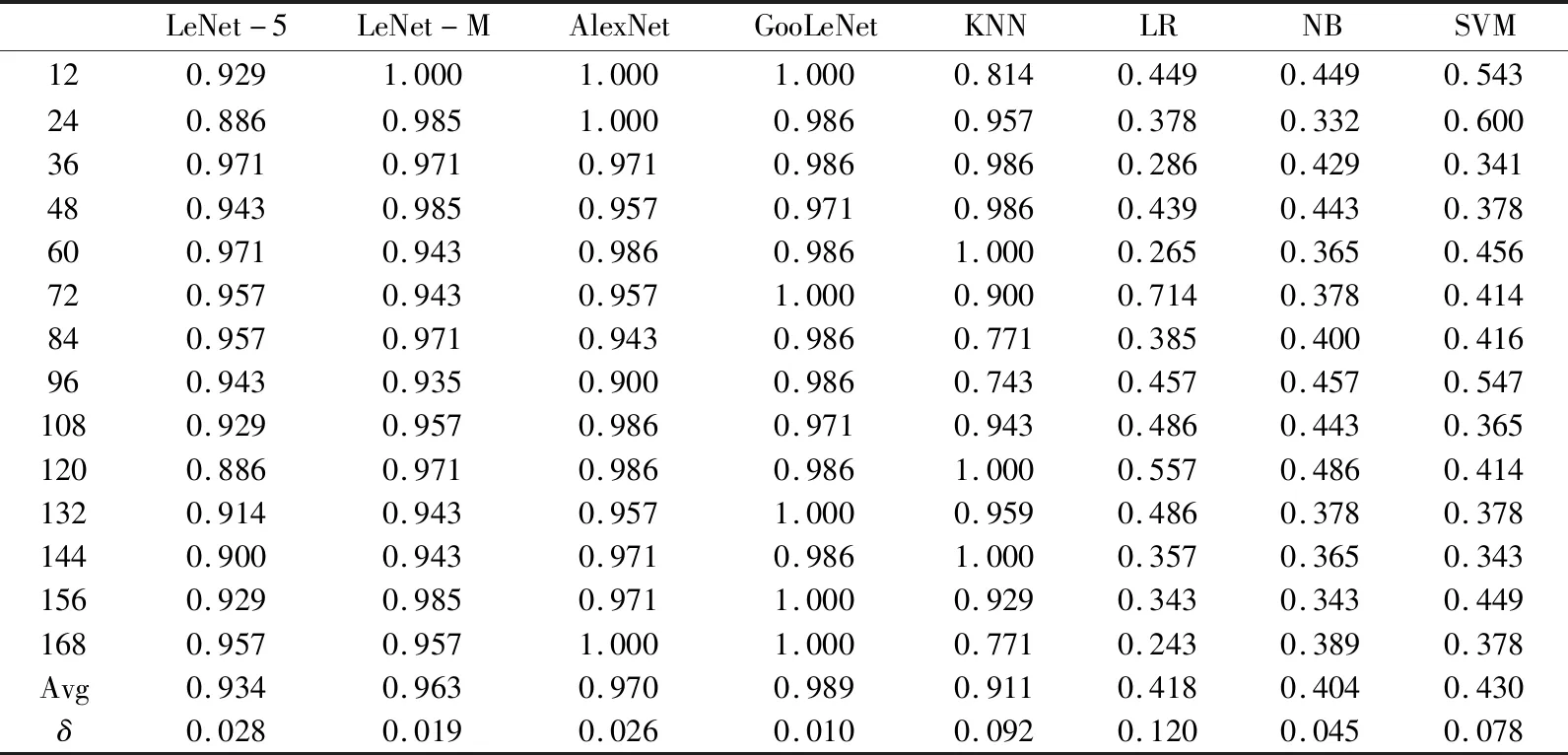
表6 对Brodatz数据集不同旋转角度测试结果Tab.6 Test results for different rotation angles of the Brodatz

表7 对布料色卡图像数据集不同旋转角度测试结果Tab.7 Test results for different rotation angles of the fabric image
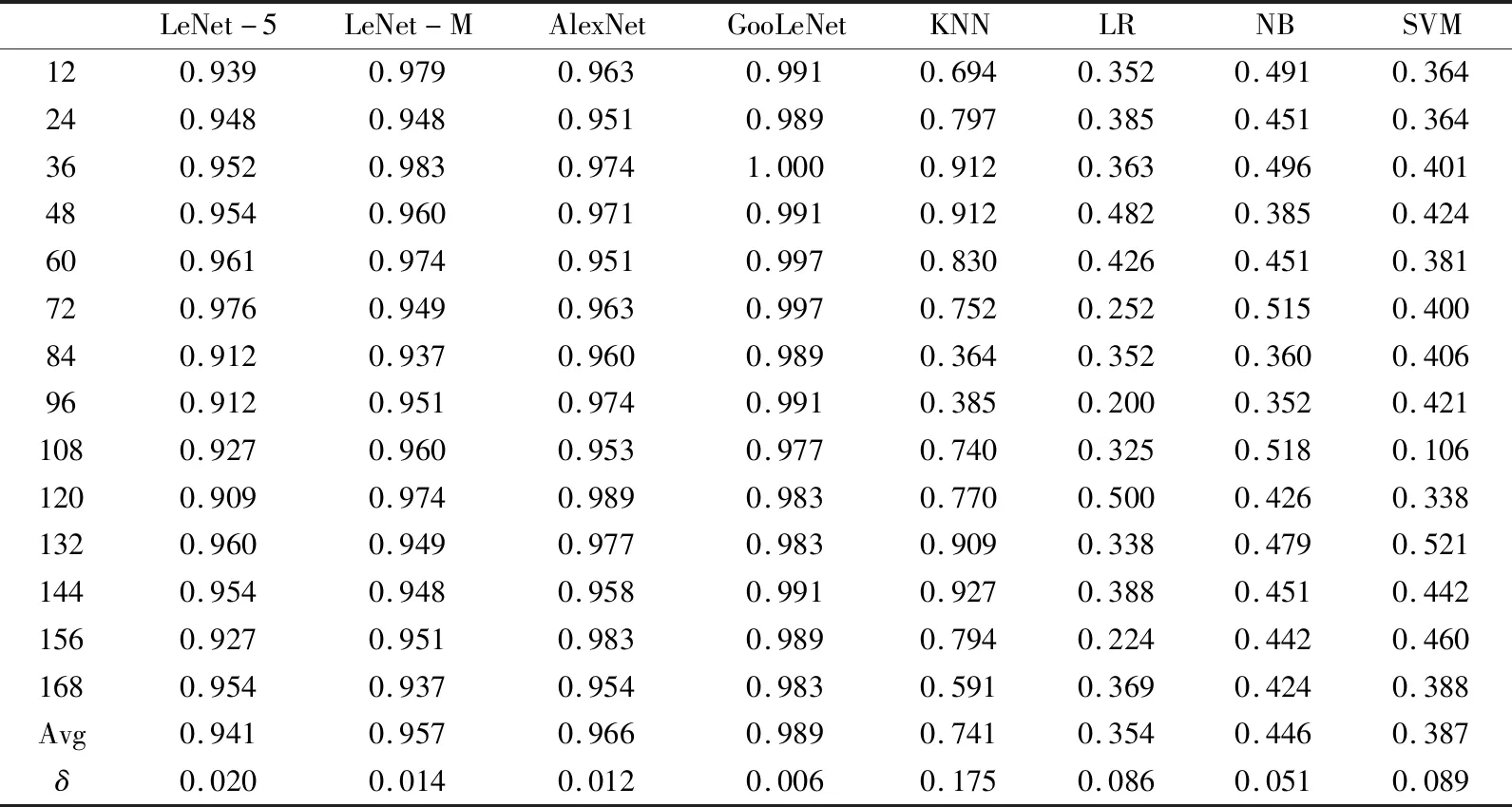
表8 对UIUC数据集不同旋转角度测试结果Tab.8 Test results for different rotation angles of the UIUC
4.7 布料色卡图像检索模型的测试和结果分析
上述测试结果表明,深度学习对不同旋转角度以及不同分辨率的图像都有很好的识别分类效果,然而一些基于人工设计特征的机器学习的分类方法对具有这俩类性质的图片识别性能却不稳定。本实验中用已经建立好的深度学习的分类模型来构建布料色卡图像的检索模型。为了更好地体现深度学习的分类模型在进行图像检索时的检索效果,本文同时还选取了4个深度学习模型,对布料色卡图像进行了检索,得到了相应的Top-5和Top-10结果。其中Top-k表示输入一张图片,给出数据库中与该图像相似度最高的k张图片,这k张图像中有任意一张图像成功匹配,则检索成功。对不同旋转角度和不同分辨率检索相关的具体实验结果如表9、表10所示。
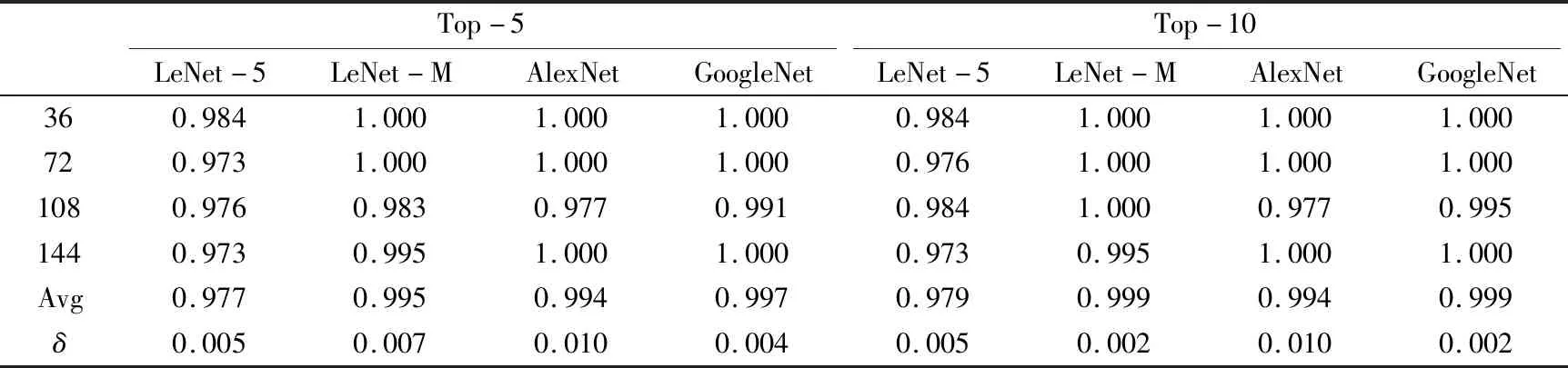
表9 对不同角度的布料色卡图像检索效果Tab.9 Image retrieval effect of fabric image at different angles

表10 对不同分辨率的布料色卡图像检索效果Tab.10 Image retrieval effect of fabric image with different resolutions
从表9、表10看出,4个深度学习分类模型在应用于布料色卡图像的检索上时表现出了十分优异的检索效果。实验证明基于深度学习的分类模型同样能够应用于布料色卡图像的分析检索上。与传统机器学习的检索方法对比,基于深度学习的方法对各类旋转角度以及不同分辨率的图片检索时,同样可以达到非常好的检索效果,完全能够满足日常生活中对布料图像查找检索的要求。
5 结束语
本文研究了基于深度神经网络的对于不同分辨率,旋转角度纹理图像的分类识别模型,并对Brodatz和UIUC两个标准纹理数据集以及来自一个真实领域采集的布料图像数据集进行了大量的对比测试和结果分析。从测试结果看,相比于传统的机器学习的方法,深度学习在处理同样的拥有不同旋转角度、不同分辨率图像的数据集时明显取得了更好的检索效果,并且深度学习的泛化性比大多数传统机器学习的方法要好得多。然而对于一些只涉及不同分辨率图像的检索时,KNN算法同样能够取得非常好的实验效果,而且在此类图像检索上使用KNN,能够大幅度提高检索效率,省去了大量的深度学习的训练时间。但KNN在对不同旋转角度的图像检索上的表现则有些不尽人意。实验结果也表明,经过改进后的LeNet-M模型结构比传统的LeNet-5在布料图像数据集和其他两个标准数据集上检索分类准确率有所提高,泛化性也更好,更加适用于色卡布料图像的检索需要。
后续拟按照LeNet-5网络结构的改进思路,来改进AlexNet网络模型和GoogLeNet网络模型等;另外,通过对数据集中增加不同来源的图像以及带有噪音的图像等,测试是否存在更好地适应布料图像分类和检索需要的网络结构。
