一种改进的缺失数据协同过滤图书自动推荐模型研究
2021-07-28杨玉枝
杨玉枝

摘 要:针对图书馆图书协同过滤自动推荐系统,因数据缺失对图书推荐结果产生影响。该文借助广东岭南职业技术学院图书馆50万条样本数据,通过对部分变量缺失数据进行插值,设计一种改进的缺失数据协同过滤图书自动推荐系统模型(xDeepFM-D)。试验结果表明,在模型训练150轮后,测试集总损失为0.072 8,AUC(Area Under roc Curve)为0.927 4。对比常见推荐系统模型xDeepFM、DeepFM、FM&DNN以及FM,AUC分别提升了0.17%、0.64%、1.27%、1.03%。xDeepFM-D模型为图书推荐系统提供了良好的应用条件。
关键词:协同过滤 推荐系统 缺失数据 数据插值
中图分类号:G250.76 文献标识码:A文章编号:1672-3791(2021)04(a)-0181-06
Research on an Improved Automatic Book Recommendation Model for Collaborative Filtering of Missing Data
YANG Yuzhi
(Guangdong Lingnan Institute of Technology Library, Guangzhou, Guangdong Province, 510663 China)
Abstract: For the library book collaborative filtering automatic recommendation system, the lack of data has an impact on the book recommendation results. Based on the 500 000 sample data from the library of Guangdong Lingnan Institute of Technology, this paper designs an improved automatic book recommendation system model (xDeepFM-D) for collaborative filtering of missing data by interpolating the missing data of some variables. The test results show that after 150 rounds of model training, the total test set loss is 0.072 8, and the AUC (Area Under roc Curve) is 0.927 4. Compared with the common recommendation system models xDeepFM, DeepFM, FM&DNN and FM, AUC increased by 0.17%, 0.64%, 1.27%, 1.03%, respectively. The xDeepFM-D model provides good application conditions for the book recommendation system.
Key Words: Collaborative filtering; Recommendation system; Missing data; Data interpolation.
图书馆在读者借书环节,若选择自动推荐系统,将会给读者选书带来极大的便利。不仅可以提高读者选书挑书的效率,还可以提高图书的借阅使用频次,较好地促进图书的流转使用率。传统的图书推荐系统中,在读者选书环节,系统给读者提供的推荐信息存在准确性低的缺点。分析其主要原因,传统推荐系统仅凭借读者注册时填写的兴趣爱好信息来判断图书推荐优先级,存在一定程度的不合理性。比如:读者在图书系统中注册个人信息资料时,并没认真填写个人兴趣信息一栏,填报信息的准确性不高;还有部分读者随着时间的推移,兴趣发生了改变,但信息填报系统并没有及时更新读者的个人信息。综合这些因素都会对图书推荐信息准确率产生较大影响。然而主流的协同过滤图书自动推荐系统比较依赖较完整的庞大数据,而数据缺失对协同过滤图书推荐系统会产生较大影响。因此,设计一种改进的缺失数据协同过滤图书自动推荐系统模型,具有重要意义。
1 相关研究
随着个性化推荐技术的发展[1-5],其在图书馆推荐中的应用逐渐成为了研究热点[6-10]。国内外很多學者也对其进行了研究[11-12],通过关联规则分析读者的借阅记录实现了图书馆藏图书的推荐、分析FP-growth关联规则算法在图书资源个性化推荐中的应用、分析读者在图书馆的日常借阅和检索行为构建了读者兴趣模型以及通过协同过滤算法实现了图书资源的个性推荐等。当前,图书馆的推荐系统大多数是基于内容的推荐技术和基于协同过滤的推荐技术,这些推荐系统虽然实现了读者大众数据的统计和分析,但是忽视了读者个性化信息的深层次特征。随着深度学习技术在计算机视觉CV和自然语言处理NLP等领域取得不错的效果,研究基于深度学习技术的推荐系统也成为当今的热门领域[13]。然而传统的图书自动推荐系统存在准确性低等缺点,因此该文着手研究基于深度学习技术的推荐系统,解决传统推荐系统的不足,为读者提供更加灵活的个性化图书推荐服务。
xDeepFM模型[11]已经在广告、餐饮、新闻等领域具有应用成功的案例,如在Criteo、大众点评和必应新闻等3个数据集上对上述模型进行评测,这3个数据集分别对应广告推荐、餐馆推荐和新闻推荐等不同的应用场景,所采用的评测指标为AUC和LogLoss。通过将xDeepFM与多种当前主流的深度推荐模型进行对比,在3个数据集上,xDeepFM模型在AUC和LogLoss上均超过了其他基准模型。这说明,结合显式和隐式的特征交互能够有效提高推荐系统的准确性。
尽管xDeepFM在广告推荐系统中具有较高的推荐准确性,但该模型仍较大地依赖较完整的庞大数据[13]。该数据结合图书馆图书静态数据和动态数据的特点,静态数据指用户特征等学生个人信息;而动态数据指书籍特征等,如标签、分类、关键词、历史借阅次数等。两种数据均存在一定程度的数据丢失,因此需要探索一种改进的缺失数据协同过滤图书推荐系统。
2 算法原理
2.1 插值方法回归
插值方法中的回归模型填充方法是基于线性回归理论为基础[14],采用对因变量和自变量中的原始数据进行回归建模,选取建模后的模型预测值作为模型缺失值的估计值。具体思想是,通过建立因变量Y对自变的回归模型,进一步达到预测因变量Y的缺失数据目的。对k个缺失值的填充值可表示为:
假如模型各变量之间的回归关系显著,采用该回归模型得到的估计值也会比较接近真实预测值。然而在对模型进行构造和对模型进行评估的步骤相对繁琐,需要对模型进行显著性评价,因此该模型的应用场景对于重要变量的缺失值填充比较有效。
由式(1)可知,对于相同的,经过建立回归模型后,得到的模型估计值是相同的,因此需要在回归估计中增加随机成分信息,回归方程可表示为:
在式(2)中,需要特别关注εk的处理,常用的构造随机成分信息的方法有多种,该文选用正态变异估计方法,选取模型变量期望为0,标准差为回归误差项均方的平方根,随机提取误差项。
2.2 插值方法EM
若研究的观测数据缺失类型为随机缺失[15],通过观测数据的边缘概率分布对未知参数进行极大似然估计。EM算法是受缺失数据思想的影响,当观测数据服从高斯正态分布时,观测数据的似然密度函数为:
(3)
式中,θ为待定参数(μ,σ),Y为已知观测数据,Z为缺失数据In。因此,缺失数据In基于已知观测数据和参数的条件概率分布密度函数为:
(4)
式中,μi、σi为第i次迭代后的参数估计值。
由式(3)和式(4)可以得到EM算法的期望:
(5)
将积分后得到的最大化,得到θi+1,将θi+1反带入式(5)中重新得到期望值,如此反复循环,直至‖θi+1-θi‖或‖Q(θi+1|θi,Y)-Q(θi|θi,Y)‖足够小为止。迭代结束后,即可求解出缺失数据下未知参数的最佳估计。
2.3 推荐模型xDeepFM-D
谷歌公司在2016年首次提出了模型Wide&Deep [16],该模型由单层Wide部分和多层Deep部分组成的混合模型。其中,Wide部分用于模型的“记忆功能”,而Deep部分用于模型的“泛化能力”。整个模型既具有逻辑回归和深度神经网络的优点,能够快速处理并记忆大量的历史数据行为特性,同时也具有较强的模型表达能力。
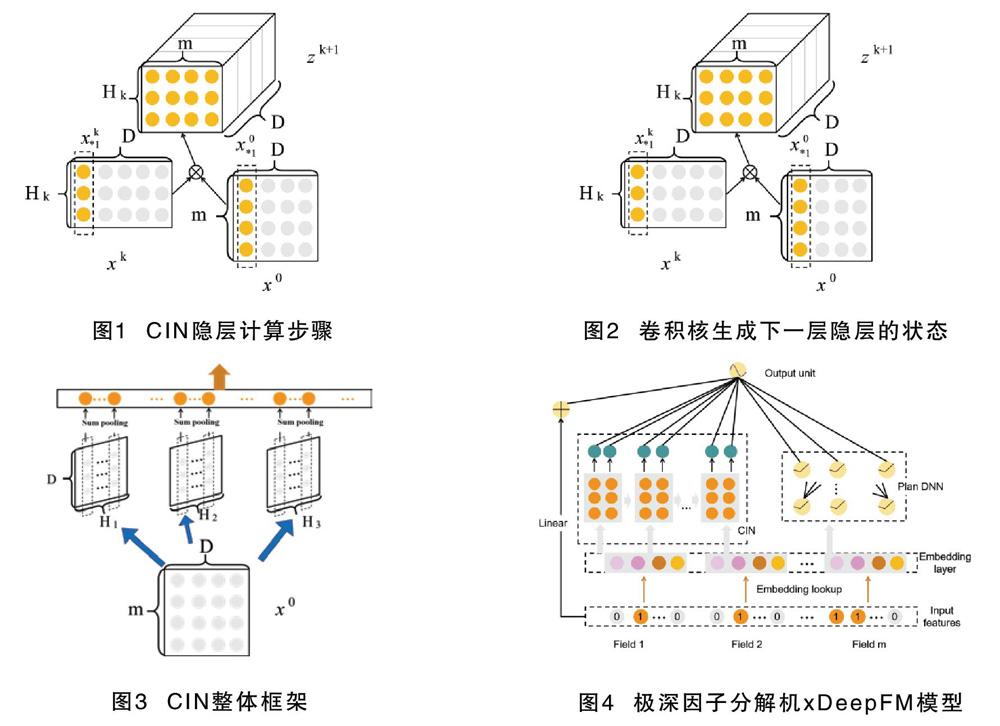
为实现自动学习显式的高阶特征交互,首先借鉴压缩交互网络(CIN,Compressed Interaction Network)的神经模型,每一层神经元均由上一层的隐层和原特征向量计算而来,具体公式:
(6)
其中,第k-1层隐层含有Hk-1条神经元向量,W为网络权重,隐层的计算可分两步:式(6)根据前一层隐层的状态xk和原特征矩阵X0,计算出一个三维张量的中间结果 ,具体变换过程见图1。
基于CIN隐层计算步骤介绍的中间结果基础上,采用Hk+1个尺寸为m.Hk的卷积核生成下一层隐层的状态,具体计算过程见图2。
该运算操作符合计算机视觉中最流行的卷积神经网络(CNN)计算法方法[17]。CNN卷积神经网络模型的神经元连接是非全连接的,同一层中某些神经元之间的连接的权重是共享的特点,极大地降低了网络模型的复杂度,减少了网络权值数量。CIN中单个神经元其相关的接受域是垂直于特征维度D的整个平面,而CNN中的接受域是当前神经元周围的局部小范围区域,CIN中经过卷积操作得到的特征图是一个向量,并非矩阵形式。
其最终学习出的特征交互的阶数是由网络的层数决定的,每一层隐层都通过一个池化操连接到输出层,从而保证了输出单元可以见到不同阶数的特征交互模式。与此同时,CIN的结构与循环神经网络(RNN)是很类似的[18-20]。RNN属于节点定向连接成环的神经网络,具有较好的记忆功能,利用记忆来处理任意时序的输入序列,对手写识别和语音识别具有优越性。网络特点是,每一层的状态是由前一层隐层的值与一个额外的输入数据计算所得。然而,CIN中不同层的参数是不同的,而RNN中是相同的。另外,RNN中每次额外的输入数据是不同的,而CIN中额外的輸入数据是固定的,始终设定为X0。
CIN框架搭建完成后,参考Wide&Deep和DeepFM等模型的设计,发现同时包含多种不同结构的成分可以提升模型的表达能力。因此,将CIN与线性回归单元、全连接神经网络单元组合在一起,得到最终的模型并命名为极深因子分解机xDeepFM,其结构见图4。
集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。为了提高模型的通用性,xDeepFM中不同的模块共享相同的输入数据。而在具体的应用场景下,不同的模块也可以接入各自不同的输入数据。例如,线性模块中依旧可以接入很多根据先验知识提取的交叉特征来提高记忆能力,而在CIN或者DNN中,为了减少模型的计算复杂度,可以只导入部分稀疏的特征子集。
3 算法实现
针对广东岭南职业技术学院图书馆,选取用户特征、书籍特征、过往行为统计特征作为模型输入,标签选取0代表未借这本书,1代表已借这本书。用户特征是指学生个人信息;书籍特征是指标签、分类、关键词、历史借阅次数等;过往行为统计特征是指分组统计特征,采用xDeepFM模型训练学习出适合高校图书馆有效可靠的推荐系统。
以借书与否作为模型因变量,共选取ID变量:表示图书登录号;Type变量:0表示图书,1表示光盘;Borrow变量:表示借书的日期,周一至周日分别用1~7表示;Return变量:表示还书的日期,周一至周日分别用1~7表示;Time变量:表示还书和借书之间时间差;Index变量:索书号,比如:20160242表示第20个字母和16个字母,以及242号,字母从1~26分别表示A~Z;Seedtime变量:种次号;Code变量:证号;Control变量:控制号;IP变量:借书站点;Level变量:年级;Name变量:专业名称,0是学生,1是教师;Overpayfor变量:0是不产生超期款,1是产生超期款。
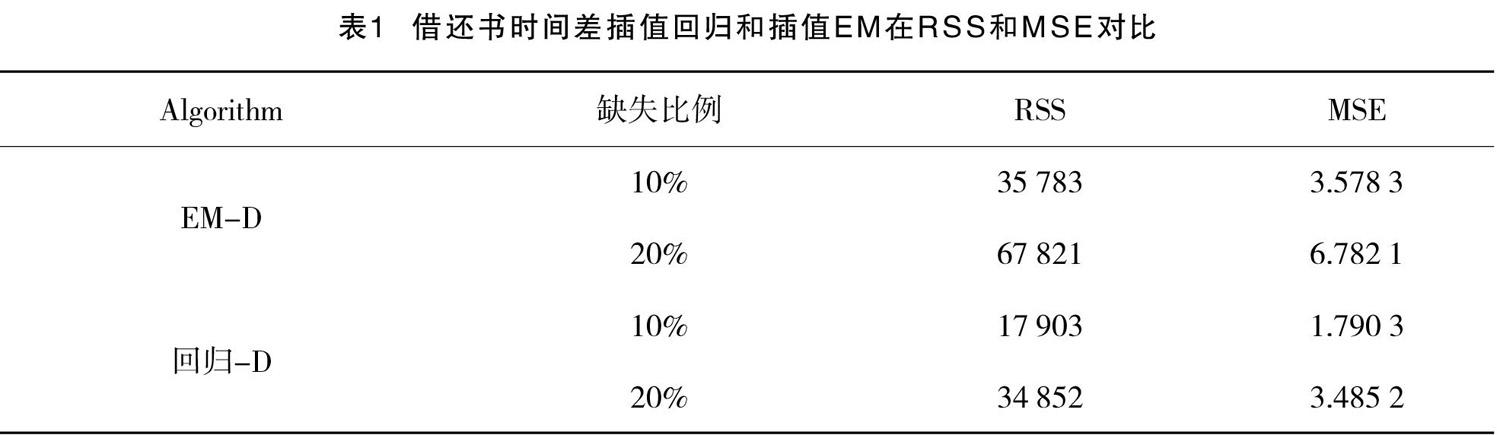
共选取13共自变量中,数据缺失比例严重的还书和借书之间时间差为例,采用插值回归(回归-D)和插值EM(EM-D)模型进行对比试验[21-25],随机选取10 000组未缺失的完整数据进行建模,其中分别以10%和20%的比例进行缺失处理。
样本集的残差平方和(Residual Sum of Squares, RSS)与均方误差(Mean Squared Error, MSE):
RSS(7)
MSE(8)
采用RSS和MSE,针对还书和借书之间时间差变量,对比两种插值模型的优劣,对比结果见表1。
通过表1可知,EM模型仅考虑了自身数据的特点,而真实情况是自变量之间是存在较强的相关性,采用回归模型更能符合图书馆数据的特点,而最终结果也表明,回归模型效果更优。
因此,该文采用插值回归和xDeepFM相结合的方案。首先,用插值回归对数据缺失严重的数据,进行插值回归;然后,用xDeepFM对图书馆数据进行推荐系统建模,该模型命名为xDeepFM-D模型。
该文基于Pytorch实现的xDeepFM-D模型,通过xDeepFM-D模型,预测出是否借书的概率,来判定是否推荐该图书,为图书馆图书推荐系统提供指南。模型共有样本519 646,选取的训练样本415 674,占总样本的80%,测试样本103 972,占总样本的20%,数据采用“random”方法随机打乱。数据预处理部分仅对数据缺失超过10%以上的变量采用插值回归模型进行插值处理,其余类别特征缺失,用-1代替,数值特征缺失,用0代替。模型DNN部分隐含层特征分别为[400,400,400],dropout随机失活比例0.9,模型训练部分,batchsize数量设定为50 000,迭代輪次选取150轮。
模型训练150轮后,测试集整体损失为0.072 8,AUC为0.927 4,模型取得了较好的预测效果,从图5中ROC曲线可知,插值回归模型对推荐系统整体模型效果有所提升,xDeepFM-D对比xDeepFM的ROC曲线,更接近(0,1)。
进一步对比各主流模型的测试结果,选取AUC和Logloss两组变量,对比结果见表2。
通过对比发现,xDeepFM-D测试集总损失为0.072 8,AUC为0.927 4。对比主流xDeepFM、DeepFM、FM&DNN以及FM模型,AUC指标分别提升了0.17%、0.64%、1.27%、1.03%。
4 结论
推荐模型通常应用在广告、餐饮以及新闻等领域的推荐系统,较少在图书推荐系统上的应用,选题角度具有新意。对高校图书推荐系统提供有力保障,传统的推荐系统仅借助读者注册时填写的兴趣爱好判断,无法较好地提高图书的流通率,xDeepFM-D模型通过对缺失数据的插值补充,结合图书推荐的特点,最终实现在图书推荐系统上的应用,使得图书推荐的准确率进一步提高,更好地满足图书馆的个性化需求。
参考文献
[1] 姚舜.关联规则算法在图书自动推荐系统中的应用[J].四川图书馆学报,2012(6):55-58.
[2] 纪文璐,王海龙,苏贵斌,等.基于关联规则算法的推荐方法研究综述[J].计算机工程与应用,2020,56(22):
33-41.
[3] 邓浩伟,杨书新,裴嘉琪,等.基于矩阵分解和Meanshift聚类的协同过滤推荐算法[J].计算机科学与应用,2020,10(4):649-658.
[4] 高雅平,詹华清.基于人工智能的图书馆建设研究[J].数字图书馆论坛,2020(11):20-26.
[5] 沈佳.基于深度学习的图书推荐系统研究[D].武汉理工大学,2018.
[6] 殷宏磊.基于深度学习的推荐系统研究与实现[D].电子科技大学,2019.
[7] 李丹,高茜基于深度学习推荐系统的研究与展望[J].齐鲁工业大学学报,2020,34(6):29-38.
[8] He X, Liao L, Zhang H, et al. Neural collaborative filtering[C]//Proceedings of the 26th International Conference on World Wide Web.International World Wide Web Conferences Steering Committee, 2017:173-182.
[9] Wang Xiang,He Xiangnang,Nie liqiang,et al.Item silk road: Recommending items from information domains to social users[C]//Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval.ACM,2017:185-194.
[10] 邝耿力.基于“图书足迹”的阅读推荐系统研究[J].四川图书馆学报,2020(2):38-43.
[11] 冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014(8):720-734.
[12] d goldberg,d nichols, Oki B M, et al. Using collaborative filtering to weave an information tapestry[J].Communications of the Acm,1992, 35(12):61-70.
[13] 张华洁.基于卷积神经网络和协同过滤的图书推荐系统[D].山西大学,2019.
[14] 陈朋.传感器网络数据插值算法研究[D].湖南大学,2011.
[15] 程诗奋,彭澎,张恒才,等.异质稀疏分布时空数据插值、重构与预测方法探讨[J].武汉大学学报:信息科学版,2020,45(12):1919-1929.
[16] heng-tze cheng, levent koc, jeremiah Harmsen, et al. Wide & Deep Learning for Recommender Systems[C]//Proceedings of the 1st workshop on Deep Learning for Recommender Systems. ACM,2016:7-10.
[17] 沈佳.基于深度學习的图书推荐系统研究[D].武汉理工大学,2018.
[18] 刘宁宁.基于深度因子分解机和循环神经网络的位置预测研究[D].重庆邮电大学,2020.
[19] 余梦梦,孙自强.基于FGx_Deep算法的深度推荐[J].计算机工程与设计,2020,41(11):3204-3211.
[20] BAGCI H, KARAGOZ P. Context-aware friend recommendation for location based social networks using random walk[C]//Proceedings of the 25th International Conference Companion on World Wide Web. Montréal. ACM, 2016:531-536.
[21] 古万荣,谢贤芬.面向非随机缺失数据的协同过滤评分方法[J].华南理工大学学报:自然科学版,2021,49(1):47-57.
[22] 王梦晗.推荐系统中数据缺失问题的研究[D].浙江大学,2019.
[23] 周明升,韩冬梅.一种改进的缺失数据协同过滤推荐算法[J].微型机与应用,2016,35(17):17-19.
[24] 杨彦荣,张莹.基于用户聚类的图书协同推荐算法研究[J].科技资讯,2020,18(9):198-199.
[25] 廖志平.数据挖掘在学校图书馆的应用[J].科技创新导报,2012,(12):211-213.
