基于音频增强现实的博物馆交互式引导模型*
2021-07-28蔡子丽
蔡子丽
(武汉博物馆,武汉 430021)
0 引 言
随着信息技术的发展,越来越多的军事训练、教育、博物馆等行业开始尝试应用数字技术为用户提供更优质的服务,其中,上下文感知音频引导、虚拟现实(Virtual Reality,VR)、增强现实(Augmented Reality,AR)等交互式数字技术是目前用于提升用户体验的研究热点[1-2]。音频增强现实(Audio Augmented Reality,AAR)技术[3-4]作为增强现实技术的组成和延伸,通过给现场受训和用户人员耳边合成出带有距离、方位和高度感的音源,能明显增强沉浸感,也能最大限度地减少用户与环境交互所需的注意力,为用户提供隐式信息服务[5-6]。目前,这一技术正受到越来越多的关注,已逐步应用于电话会议、远程控制和视频游戏等领域[7-8],并开始推广至实景训练、路线引导类应用[9-11]。
在军事训练中,音频增强现实技术的使用主要体现支持真实场景下单人专项训练和多人协同训练。如街头巷战训练,音频增强现实系统会根据某一受训人员在复杂环境下犹豫不决、选择狙击位置能力弱的特征,在其四周不同巷子中分波次产生不同威胁等级的枪械声音或其他声响,促使受训人员迅速判断主要威胁,并通过声音位置的引导,循声前往正确的狙击位置。完整的音频增强现实技术必须包括三个方面:一是真实场景精确建模和人员实时定位;二是场景内人员特征描述;三是音源模拟和引导。以上三项内容对应了音频增强现实交互式引导模型的三个组成部分,即场景模型、访客模型和导航模型。博物馆导览场景具有明确的引导目标,同时具备参观人数多、人物行为特征数据易采集、导览模型验模结果易比较的特点,便于开展音频增强现实交互式导览模型的建模和验证。相关研究结果中物理环境建模方法可直接用于军事训练增强现实场景构建,基于语义的音频引导模型能较好地适配基于科目目标的训练引导任务,因此,博物馆实验背景下音频增强现实交互式引导模型研究对虚拟军事训练系统具有一定的普适性。
国外已有的博物馆音频导览系统主要利用射频识别(Radio Frequency Identification,RFID)、红外、摄像头等多种手段检测游客在博物馆建筑内的位置,进而根据游客位置信息提供增强现实音频服务[12-14]。该类应用系统在交互模式上比较单一,只能在固定位置播放预先设置的音频内容,无法根据用户的交互行为动态调整音频引导内容,难以满足大规模人群多样化应用需求。针对此问题,本文提出一种可用于博物馆导览的音频增强现实交互式引导模型,通过对场景、用户、导航过程三方面的定义实现音频信息的自适应推送,能够结合用户个人资料、行为特征、历史参观等信息匹配发现个人兴趣偏好,进而利用音频增强现实设备引导用户在参观博物馆展览时靠近其感兴趣的展品,同时支持跟踪用户行为,动态调整兴趣特征参数,达到提供个性化的音频信息服务的目标。
1 博物馆交互式引导模型
博物馆音频增强现实交互式引导模型由场景模型、访客模型和导航模型三部分组成。其中,场景模型主要描述了博物馆内环境信息,包含物理层、虚拟层和语义层,分别描述空间位置、区域划分和交互内容等要素;访客模型主要描述反映游客参观兴趣偏好的相关信息,包含静态先验模型和动态行为模型;导航模型通过建立访客兴趣特征来描述展品与访问者兴趣的匹配程度,并定义了自适应算法支持根据访客在参观过程中的行为轨迹动态调整访客兴趣特征,以便向用户推荐更符合其需求的音频内容。
1.1 场景模型
场景模型通过物理层、虚拟层和语义层三个层次来描述博物馆场景信息,如图1所示。
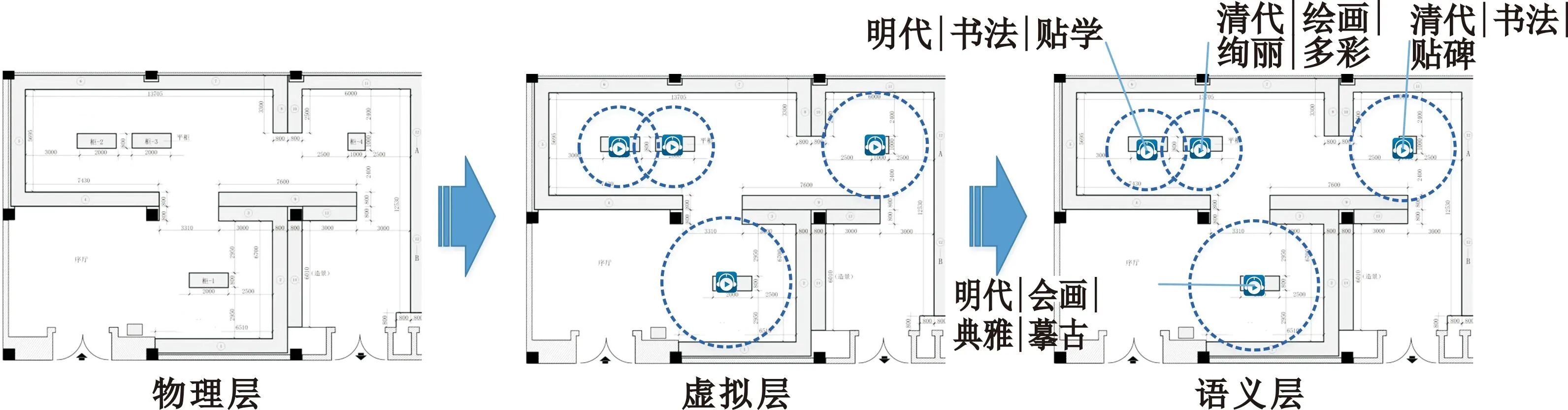
图1 场景模型层次图
物理层主要用于描述博物馆的物理环境,它包含了场馆和展品基于物理空间的所有位置信息,是后续进行虚拟层区域划分的基础。
虚拟层是基于物理层的扩展,将博物馆展览空间划分为多个基本区域的集合,一个基本区域与一个展品对应,每个基本区域在位置信息的基础上增加音频内容和交互规则信息。其中,交互规则主要规定了物理空间中交叉覆盖位置上各基本区域的层次关系,作为共享位置上音频导航的基本参数。实际应用中可根据博物馆展览需求对基本区域的基本属性进行配置,进而组合成不同类型的应用场景。
语义层通过一组语义标签来描述各基本区域内展品信息,每个展品对应的语义标签集合是后续进行用户兴趣匹配计算的基础。语义标签可基于展品相关文档资料,通过文档主题生成模型(Latent Dirichlet Allocation,LDA)[15]进行自动抽取。
1.2 访客模型
访客模型用于记录游客参观兴趣偏好的相关信息,作为导航模型中兴趣匹配计算的基础数据,包含基于其个人资料的静态先验模型和基于访客关于展品(移动、停止、聚焦)及音频内容(播放、停止、循环)等动作的动态行为模型。其中,先验模型主要用于设置访客初始兴趣偏好,行为模型主要用于推断访客动作所表达的意图,进而发现用户兴趣变化。
1.2.1 先验模型
访客的先验模型包括访客年龄、语言、对博物馆感兴趣的领域(包含博物馆类型、展品类型)等特征信息。当访客到达博物馆时,通过证件信息或面部识别信息确认用户身份,提取用户数据库中的模型数据即可用于设置访客初始兴趣偏好。
对于多次参观博物馆的访客,先验模型中的博物馆兴趣特征可基于观众之前参观博物馆过程中记录关注的展品及收听的音频内容等历史轨迹信息自动提取;对于首次参观博物馆或历史数据缺失的访客,也可以通过纸质或语音问卷的形式获取用户兴趣数据,进而建立先验特征。
1.2.2 行为模型
访客的行为模型首先定义姿势来推断访客在参观过程中所做动作表达的意图,部分姿势数据还可以用于推断访问者所在的区域,以及访问者所看到的展品。姿势是一种基于规则的动作序列描述模型,一组特定的动作序列表示访客一种意图。以否定姿势(表示不)为例,该姿势被描述为伸出食指从左到右的快速运动,为与普通摆动作区别以防止误识别,其识别规则为食指在单位时间段内摆动次数超过阈值,因此,在识别该姿势时,需要通过食指运动的偏航角显著程度辨别摆动动作,并计算次数以确定是否识别为否定姿势。计算过程如图2所示,其中I、t分别是初始偏航角(欧拉角)和时间;x是一个计数器,用于计算用户从一侧到另一侧改变食指方向的次数。
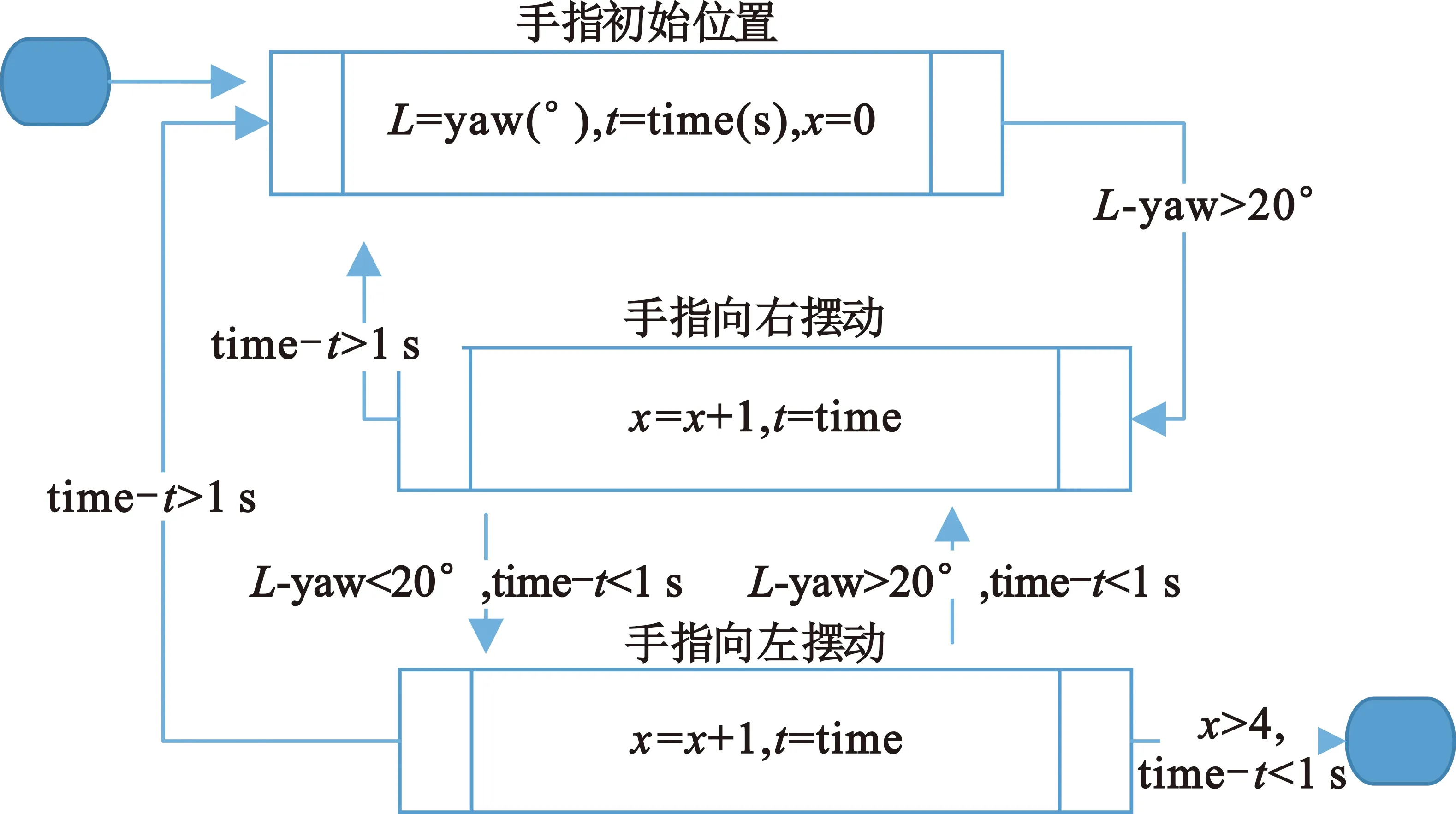
图2 否定响应动作捕捉计算流程
基于基本姿势模型,可以定义应用场景上下文,同一上下文中的姿势模型默认会成组出现,因此在规则设计时需要便于传感器区分,进而根据姿势对音频内容进行调整。对于博物馆导览应用场景我们定义了两种典型的上下文,即正常访问上下文和控制音量上下文。
(1)正常访问上下文
在这种上下文中,定义了三种姿势来控制音频内容。肯定姿势会播放与访客面前展品相关的基本区域音频内容;否定姿势会停止基本区域音频内容;循环姿势会将当前音频内容存放在播放列表中,在没有新指示的条件下反复播放。
(2)控制音量上下文
在这种上下文中,定义了两个姿势用于控制音量:手掌掌心向上抬升后静止1 s表示增大音量;手掌掌心向下滑静止1 s表示减小音量。
1.3 导航模型
导航模型首先根据访客先验模型对展品相关音频内容的语义标签进行打分(0~1的数字),反映其与访问者兴趣的匹配程度,据此为每位观众建立个性化的兴趣模型,然后在参观过程中根据观众的行为,动态计算展品及相关音频内容与观众兴趣的匹配程度,进而动态规划观众行程,通过音频导航引导观众,并确定推送展品相关音频的优先级。导航模型中最重要的是自适应过程,该过程通过不断计算每个展品音频内容与访问者兴趣相对应的分数来更新用户兴趣特征,计算过程如下:
任何得分超过给定阈值的音频内容都将被添加到对应用户的引导列表中;相对地,任何分数低于该阈值的音频内容都将从列表中删除。
设V作为访客,给定一个展品O,AZ表示O所在的基本区域,S表示AZ基本区域内的一个音频内容,Tags(O)=to1,to2,…,ton是描述展品O的语义标签,Tags(S)=ts1,ts2,…,tsn描述音频内容S的语义标签,Nto是展品语义标签的数量,Nts是音频内容语义标签的数量,则Score_interest(V,AZ)表示用户V对基本区域AZ的兴趣分数,Score_interest(V,O)表示用户V对展品O的兴趣分数,Score_interest(V,S)表示用户V对音频内容S的兴趣分数,Score_interest(V,t)表示用户V对标签t的兴趣分数,Score_interest0(V,t)表示用户V对标签t的初始兴趣分数。
通过分析用户填写的先验特征(第1.2节),可以自动确定初始标签兴趣评分Score_interest0(V,t)。假设展品和音频内容各占观众对基本区域AZ兴趣分数的50%,且分数的最小值和最大值分别设置为0和1,则Score_interest(V,AZ)可表示为
通过对生产、消费和进出口所需资本和劳动的分析,说明2007年我国的经济的比较优势是劳动力,我国出口了劳动密集型产品,而进口了资本密集型产品。
Score_interest(V,AZ)=

(1)
式中:用户V对一个展品的的兴趣得分Score_interest(V,O)定义为该展品所有相关语义标签兴趣分数的均值,音频内容兴趣分数Score_interest(V,S)定义为该音频内容相关语义标签兴趣分数的均值:
(2)
(3)
访客V对于某个展品兴趣分数的增加或减少是通过计算其在该展品前逗留的时间平均值和标准差来决定。假设访客在展品前逗留的时间符合正态分布,如果访客在某展品前逗留时间长度大于平均时长且距离超过一个标准差以上则增加访客对该展品的兴趣分数;反之,如果访客在某展品前逗留的时间小于平均时长且距离超过一个标准差以上则降低访客对该展品的兴趣分数。同时,定义绝对逗留时间阈值k,如果访客逗留时间超过给定阈值k,即使逗留的时间小于平均时长且距离超过一个标准差以上也不降低兴趣分数。
在用户参观期间,如当前基本区域内任意展品或音频内容兴趣分数增加,该展品或音频内容所对应语义标签的兴趣分数也增加,计算方法如下:

(4)
同样,如果当前基本区域内任意展品或音频内容兴趣分数减少,则对应标签的兴趣分数也相应减少:
(5)
[0,μ-f×σ]:兴趣分数低于阈值且在原有导航路线中的基本区域将从导航路线中移除。
[μ-f×σ,μ+f×σ]:兴趣分数在平均值附近的基本区域状态不变。
[μ+f×σ,1]:兴趣分数高于阈值且不在原有导航路线中的基本区域将添加到导航路线中。
2 实验评估
2.1 实验设计
为验证博物馆交互式引导模型的可用性,笔者基于武汉博物馆真实环境进行了实验测试。本次实验将武汉博物馆官方音频解说内容作为对比对象,实验参与者被分为两个不同的组,一组体验官方音频解说设备,一组体验基于博物馆交互式引导模型原型系统设备,采用了主客观结合的评价方法对系统效能进行分析。其中,客观评价通过设备日志采集数据,基于实验参与者在参观过程中穿过的基本区域数量,以及在每个基本区域上花费的时间进行分析;主观评价通过调查问卷分析参与者的主观感受。
2.1.1 实验场景模型设置
实验在《历代文物珍藏》厅内进行,在该展厅中挑选10件展品作为测试对象。对于每件展品设置两个圆形基本区域与之关联:外层基本区域称为扩展区域,在该类区域中播放展品相关引导音频内容;内层基本区域称为独占区域,在该类区域中播放展品相关描述音频内容。展厅基本区域布局如图3所示,其中红圈表示独占区域,蓝圈表示共享区域。

图3 展厅基本区域布局示意图
与展品相关引导音频内容是该展品内容背景音(如鎏金佛坐像的背景音为佛教音乐、玉卧牛的背景为田园自然声音等),展厅中扩展区域相交的共享区域中,参观者可以听到多个展品的引导音频,用于引导参与者发现其感兴趣的展品。展品相关描述音频内容与博物馆官方语音导览内容对应。基于各展品的介绍文档采用文档主题生成算法,对每个展品生成不少于5个语义标签,用于兴趣匹配计算。
2.1.2 实验访客模型设置
在开始之前,游客被要求填写一份初始问卷,需要填写性别、年龄、联系人、是否具有自助语音导览经验和武汉博物馆参观经历等基本信息,同时需要在所有语义标签中选择不少于10个感兴趣的标签,基于问卷反馈数据创建访客先验兴趣特征。
在博物馆天花板上设置多个深度摄像头,用于持续捕捉跟踪访客动作。原型系统根据姿势识别结果动态调整用户兴趣特征,向访客推送适当的音频内容。每个访客参观时间限定为10 min,然后由参观者填写一份包含25个问题的书面问卷。
本次实验共有18人参与体验,分别为9名女性和9名男性,年龄在25~63岁之间,平均年龄41岁。
2.2 实验结果与讨论
基于原型系统设备日志数据,笔者对每个参与者三项指标进行评估:在独占区域花费的总时间、在共享区域花费的总时间和访问的展品数量。为了比较官方语音导览和引导模型原型系统两者实验结果的差异性,对两组数据进行了方差分析。通过比较,体验两个系统的参与者在独占区花费的总时间存在显著差异(方差分析结果F=5 090,P=0.041)。同样,在共享区域花费的总时间也存在显著的差异(方差分析结果F=4.762,P=0.048),但访问的展品数量之间的差异并不显著(方差分析结果F=1.475,P=0.246)。
图4展示了访客平均耗时的实验结果,可以看到体验博物馆交互式引导模型设备的参与者在独占区域花费的平均持续时间约为7 min 15 s,而对于体验官方语音导览设备的参与者,这个时间不超过5 min 32 s。该结果说明博物馆交互式引导模型设备能吸引观众花更多的时间收听文物音频内容。同时,体验博物馆交互式引导模型设备的参与者在共享区域花费的平均时间为2 min 15 s。对比官方语音导览设备组该平均持续时间约为4 min 8 s。该结果可以解释为博物馆交互式引导模型设备能更方便地引导游客参观感兴趣的展品,减少无目的驻足时间。

图4 基本区域内用户平均耗时
问卷共有25个问题,主要对易用性、展品定位准确性及趣味性等三个方面来比较,其中易用性比较结果如表1所示。

表1 易用性评分结果
从反应性、满意度、理解性和易学性四个方面对两者的可用性进行了评价。通过总结这四个易用性标准可知,博物馆交互式引导模型在四个方面都占有优势。
其他相关结果如图5所示,可见所有体验博物馆交互式引导模型的参与者都能很容易地定位展品(甚至有66%的人感觉非常容易)。参与者发现,内容声音空间化对他们定位展品有很大帮助。同时,100%的测试者发现博物馆交互式引导模型设备很有趣,其中40%的人觉得非常有趣,只有50%的自助语音导览设备用户觉得它很有趣。

图5 主观评价实验结果
3 结 论
本文提出了一种用于博物馆参观的音频增强现实交互式引导模型,其目的是通过空间化音频内容和自适应机制,引导用户在参观博物馆展览时靠近其感兴趣的展品,并提供个性化的音频信息服务。该模型由场景模型、访客模型和导航模型三部分组成。以武汉博物馆为例研究,对原型系统及其特性进行了实验评估。评价结果表明,该系统具有良好的实用性,能更容易地定位展品,并增加观众对展品的兴趣,为博物馆导览提供了一种更为个性化、信息量大、趣味性强的方式。
