西藏地区野生植物图像识别系统的研究与设计
——以红景天属为例
2021-07-27方钇霖王兆伟
方钇霖,王兆伟
(西藏大学信息科学技术学院,西藏 拉萨 850000)
0 引言
青藏高原是世界上隆起最晚、面积最大、海拔最高的高原,因而被称为“世界屋脊”,被视为南极、北极之外的“地球第三极”。西藏高原位于青藏高原的主体区域,有分属寒带、温带、亚热带、热带的种类繁多的奇花异草,据粗略估计高等种子植物可达10,000种左右。
研究西藏地区野生植物的图像识别技术,对于西藏地区野生植物的分类及植物资源的保护与利用、探索植物间的亲缘关系、阐明植物的进化规律、农艺与园艺的实际应用等方面具有现实意义。如何有效的利用测试库内的植物图像准确地识别出训练库内所对应的植物图像数据库,以及同种植物的不同图像更换了测试库内原图像,系统也依然能识别出训练库内所对应的植物图像是一个非常值得研究的内容[2]。
本文以红景天属为例。西藏自治区景天科红景天属总共有32种,其中根出红景天、卵萼红景天、报春红景天、圣地红景天、粗茎红景天这5种未写明产地,故这五种不予以分析;以及柴胡红景天和紫胡红景天数据链接到的是亚查红景天和柴胡红景天,无法确定数据准确性,故这3种不予以分析;云南红景天、紫绿红景天、西川红景天、德钦红景天这4种红景天虽在西藏有分布,但不是产自西藏,故不予以分析;四裂红景天与大红红景天存在异议,在西藏产的都是大红红景天,故四裂红景天不予以分析;狭叶红景天存在变种,故不予以分析;故本文主要分析其余的18种。
1 系统的研究与设计
1.1 数据来源与PCA的基本理论
1.1.1 数据来源
本文分析所使用的18种西藏产红景天的图像、信息均是从《中国植物志》(www.iplant.cn/frps)分省名录中西藏自治区,景天科,红景天属所查找而来[3]。
1.1.2 PCA 的基本理论
想要用SDV(奇异值分解)一步一步了解PCA,首先用一个例子来说明什么是PCA。例:假如测量了6个同种植物的基因转录,基因1为样本变量1和基因2为样本变量2,如表1。

表1 六种植物样本的基因转录表
如果将测量的两个基因数据绘制在一个二维XY图上,如图1中的(1)。
那么接下来要计算GENE 1和GENE 2的平均测量数,然后通过平均值,计算数据的中心,从这一刻开始,将专注于图中发生的情况,不再需要原始数据。移动数据,使中心位于图形的原点(0,0)处,如图1中的(2)。需要绘制一条穿过原点的随机线,然后旋转线,直到它尽可能的拟合数据和仍然穿过原点的情形下,最终这条线拟合度最好,如图1中的(3)。这就是PCA的总体流程,流程图如图2。

图2 PCA 流程图
那么PCA是如何判定拟合度的高低的呢?在最开始的那条线(如图1中的(3)原始随机线)中,为了量化这条线拟合数据的程度PCA将数据投影到该线上。然后可以测量数据到线的距离并尝试找到使这些距离最小的线。使用勾股定理,b大则c小,反之亦然。因此PCA可以最小化与线之间的距离[4]。(如图3中(1))

图1 PCA 找最佳拟合线过程图
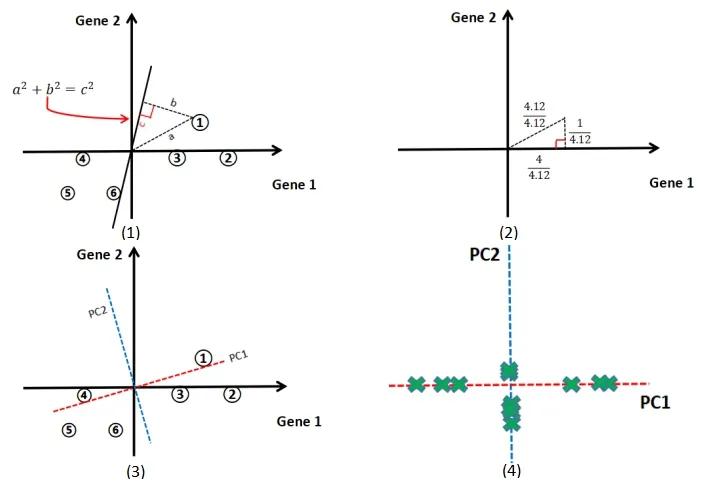
图3 PCA 最佳拟合线处理图
所以PCA找到拟合线是通过,最大化从投影点到原点的距离的平方和。将上述原理用数学公式表示,即设测量距离为d,则①、②、③、④、⑤、⑥的距离平方分别为,,,,,,然后将所有的这些开平方的距离求和就等于平方距离的总和(SSD),即:
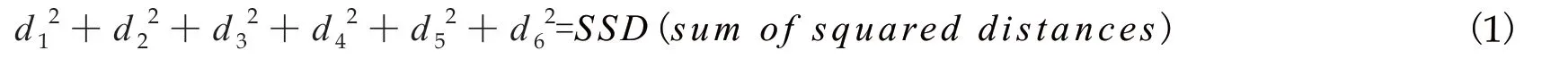
最终得到的图1中(3)的最佳拟合线,就是具有最大平方和(距离)的拟合线,即方差最大,此线叫主成分1(PC1),PC1的斜率是0.25,换言之沿着基因1轴右移4个单位,就沿基因2轴上升一个单位,这也意味着数据大部分沿着基因1分布(这就是PC1的变量们的线性组合)。
当你用SVD算PCA时PC1的配方被缩放,以使该长度等于1,如图3中(2)。这个单位长的向量由0.97个基因1和0.24个基因2组成,被称为PC1的奇异向量或特征向量。每个基因的比例称为载荷得分。PCA 把最佳拟合线距离的平方和称为PC1的特征值。而PC1特征值的平方根称为PC1的奇异值。这意味着PC2的配方为-1份基因1兑上4份基因2,PC2垂直于PC1,所以PC2的特征向量里,每单位向量因包含-0.242份基因1和0.97份基因2,和PC1正好相反。现在,想要绘制最终的PCA图只需要旋转所有内容,使PC1呈水平状态,如图3中(4),然后用投影点来定位PCA图的样本位置。在最后通过将特征值除以(样本量-1)来转换成围绕原点的差异。算出PC1和PC2的总差异比如是15+3=18,即说明PC1占PC总差异的0.83(15/18),即PC1所占的差异率为83%。
1.2 设计思路
设计思路概述:首先建立训练样本的数据集,然后对植物图像进行预处理,再让系统从植物的训练库中读取样本图像,将样本求平均向量,在计算每个样本与平均向量的向量差放入一个矩阵,然后求出特征值和特征向量,就可以计算出样本的协方差矩阵,然后选取特征向量降维,获取特征,最后将目标图像的特征值除以(训练集里总的样本数-1),求出每个样本与目标图像的差异率,再从训练后的样本库中提取差异率最低的样本数据。
所设计的植物图像识别系统,其步骤主要分为图像预处理-读取图像-提取特征-识别,具体流程如图4。

图4 植物图像识别流程图
STEP1:图像预处理——精确地进行图像对齐和图像裁剪,将需要训练和测试的图像处理成236×156像素,按照排序进行命名并放入到TrainDatebase文件夹,为后续实验提供可靠的并符合模型需求的图像数据;
STEP2:读取图像——读取目标植物图像库的路径,将其放入测试库;
STEP3:提取特征——先求出样本的平均向量,然后计算每个样本与平均向量的差向量,将得出的向量差合成一个N*N矩阵,并求解特征向量,计算协方差矩阵,最后求出目标植物图像的特征值,通过降维,提取特征;
STEP4:识别——系统整体采用PCA(主成分分析法)的方法提取目标植物图像的特征值将其除(样本数-1),求出其差异与样本库的差异进行求和,最后求出目标图像的差异率,再从样本库中提取差异率最低的图像。
1.3 GUI界面展示
与以符号为主的字符命令语言界面相比,以视觉感知为主的图形界面具有一定的文化和语言独立性,并可提高视觉目标搜索的效率。因此使用MATLAB自带的GUI设计功能设计了植物图像识别系统的图形界面,该界面由两个图像显示界面、两个静态文本界面和四个按钮组成,可以直观的实现人机交互的功能[5-6]。植物图像识别系统GUI界面如图5。
1.4 植物图像识别系统的测试
进入植物图像识别系统,点击训练样本库和测试库,训练成功后点击选择按钮选择要进行识别测试的图片,选择完成后点击识别按钮进行识别操作,可以看到在植物识别窗口的左下角会出现识别结果。如图5,即经检测,该测试图片与训练集中的1.jpg图片为同一类别,识别结果为矮生红景天。

图5 植物图像识别系统测试界面,其中测试图片和匹配图片皆为矮生红景天
2 结论
本文对基于PCA(主成分分析)的识别方法进行了介绍,并基于PCA设计出了一款植物图像识别系统,无需专业人士的人工干预即可使用该系统实现对景天科红景天属植物的识别。经实验测评,在同种植物不同角度图像的情况下,能够有效识别出该植物的属性。
由于学业水平的限制,本文仅简单地对部分景天科红景天属植物进行了简单研究,仍然存在一些不足需要进一步改进,今后将从以下几个方面进行改进:①进一步开展复杂情况下的植物识别研究,提升该系统的实用性;②进行田野考察,利用专业设备进一步扩充数据集的规模;③待数据集得到有效扩充后进行识别准确率、误差的分析,结合分析结果进一步改进识别算法,逐步提升系统可识别植物的数量。
