基于FPGA的稀疏化卷积神经网络加速器
2021-07-26狄新凯杨海钢
狄新凯,杨海钢
(1.中国科学院空天信息创新研究院,北京100094;2.中国科学院大学,北京100049)
0 概述
近年来,卷积神经网络(Convolutional Neutral Network,CNN)模型[1-2]在计算机视觉、自动驾驶、自然语言处理等任务场景中得到广泛应用,但CNN 拓扑结构复杂、计算密集且参数规模大,这对硬件系统的计算能力造成极大的压力。研究人员通过分析CNN 算法特性,发现算法模型的权重参数和特征图参数均具有稀疏化特征。稀疏化特征说明算法在前向运算的过程中会出现大量“0”参与的无效运算操作。如果在计算系统中只运行非“0”元素参与的有效操作,那么算法模型的计算量就能大幅减少。然而,传统针对CNN 的并行加速器[3-5]或数据流优化[6]通常只适用于稠密矩阵运算,并不能在实际意义上减少操作数。因此,需要针对稀疏性做优化处理,以探索稀疏神经网络硬件加速器。
对于稀疏化的神经网络加速问题,学术界已有部分研究。文献[7-8]考虑权重数据的稀疏特征,所提方法的核心思想均是用特定的压缩格式来存储和传输权重,同时在电路中加入索引模块,利用压缩格式中的索引信息定位与非零权重相对应的特征值,进而只计算有效权重参与的运算操作。文献[9-10]考虑特征图数据的稀疏特征,所提方法的核心思想是在计算单元中加入判定模块,如果遇到值为0 的特征图点,则跳过该次运算。此外,也有相关研究同时利用特征图稀疏性和权重稀疏性来避免无效运算,如文献[11]利用笛卡尔乘作为基本的操作来实现卷积,然而在该计算流程中,每个计算单元都需要设计复杂的坐标索引模块,并且中间结果较多,对缓存造成了很大压力。文献[12-13]基于ASIC 为特征图和权重建立二进制掩码索引,然后通过对两者做“与”(AND)操作,选出有效值进行运算,但是此类方案需要额外线上动态地对特征值建立索引信息。文献[14-15]方法则是针对因特定结构化剪枝方式而造成的有规律的稀疏特征。此外,学术界大量工作集中在基于ASIC 对稀疏化全连接层做加速,关于稀疏化的卷积层加速研究较少。
本文研究稀疏神经网络卷积层的计算数据流,基于现场可编程门阵列(Field Programmable Gate Array,FPGA)器件设计新的加速器硬件系统。根据特征图数据和权重数据的数据特点,设计逻辑处理模块从两者中筛选出有效的数据参与运算。在此基础上,利用FPGA 器件特点研究逻辑处理模块并行操作的整体架构,并根据器件参数和模型参数的约束探索最佳设计参数。通过在Xilinx 软硬件平台上实现具体的稀疏化VGG 模型,验证本文方案的有效性和优越性。
1 卷积神经网络及其稀疏性分析
1.1 卷积神经网络
卷积神经网络是一种前馈网络,包含由卷积层和子采样层构成的特征抽取器以及由全连接层组成的分类器。在卷积层中,有多个卷积滤波器(卷积核)扫过该层的特征图像做卷积操作得到下一级特征图,如式(1)所示,卷积滤波器中的参数即为参与运算的权重。式(1)的基本变量和参数在表1 中做详细说明。
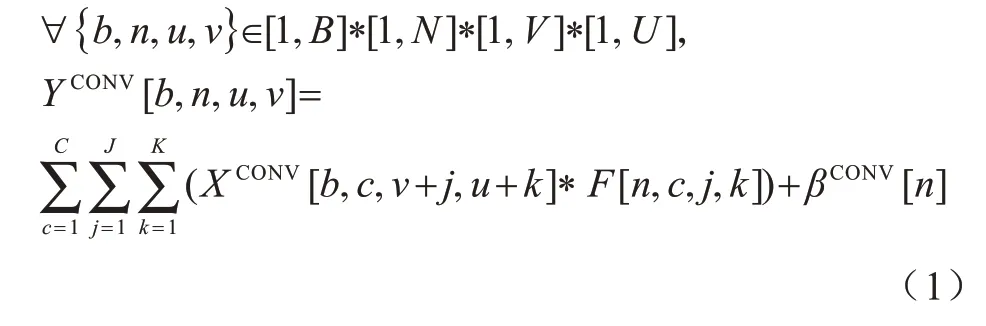

表1 卷积层参数定义Table 1 Definition of parameters in convolutional layer
实际上,子采样层和全连接层也可以看作是特殊的卷积层统一到式(1)的表述中,例如全连接层就是卷积滤波器大小等于上层特征图大小的卷积运算,每个卷积滤波器做卷积运算的结果对应全连接层的一个神经元。
1.2 算法模型参数的稀疏性分析
在本文中,CNN 网络的稀疏度定义为卷积滤波器矩阵以及特征图矩阵中零值的比例。一方面,利用特征图和权重参数的稀疏化特性可降低参数规模,进而减小系统存储压力;另一方面,设计硬件电路避免稀疏矩阵中“0”参与的运算,可降低运算代价,进而提高实时性。
神经网络中特征图和权重的稀疏性分析如图1所示。权重的稀疏性主要来源于剪枝优化技术,该技术被证实可以在保证神经网络精度的前提下有效地压缩模型。以文献[16-18]为代表的研究发现,训练时根据特定的规则将权重参数中不重要的值剪除(即置为0),不会损坏模型的识别精度。
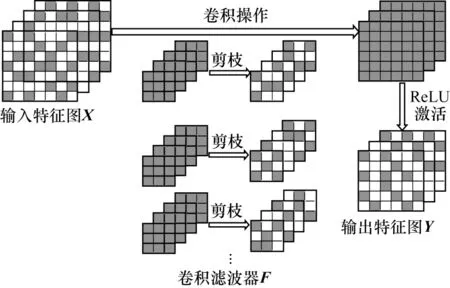
图1 权重剪枝优化及激活产生的稀疏性分析Fig.1 Analysis of sparsity by weight pruning optimization and activation
此外,特征图的稀疏性主要来源于激活函数ReLU,因为ReLU 将卷积操作的中间结果中非正值均置为0。以VGG16 网络为例,文献[17]实验结果表明,卷积层中特征图0 值点的比例最多可以达到80%,平均比例也在50%以上。与权重稀疏性不同,特征图的0 值点都是运行时获取且依赖于输入图像数据,而前者在训练后便成为可线下分析的静态数据。
2 加速器实现方案
2.1 卷积计算流程与权重压缩
在本文的设计中,神经网络卷积操作计算流程简化示意图如图2所示,共有N组C×K×K的卷积核在C×W×H的特征图上滑动(示意图中仅展示一组)。卷积层参数有输入特征图(Xc,w,h)和对应的权重滤波器(Fc,w,h)以及输出(Yn,w,h)。在每组运算中,先做C通道间向量-向量乘,得到K×K个中间结果后再进行累加,产生最终输出特征图点。

图2 卷积操作简化示意图Fig.2 Simplified schematic diagram of convolution operation
在数据稀疏的情况下,K×K个逻辑模块负责筛选出输入特征图和权重均为有效值的位置,然后传输给乘累加器(Multiplication Accumulator,MACC)。在基于FPGA 的设计中,通常采用片上DSP 来完成这项工作。图3为K=3时3×3个通道间向量-向量乘计算操作,其中每个方格代表1 对有效的特征图和权重数据,需要做1 次有效计算。在图3 中,假设每个逻辑模块后接了2 个DSP,则这组运算占用5 个cycle 时间。

图3 通道间向量-向量乘计算操作示意图Fig.3 Schematic diagram of vector-vector multiplication calculation operation among channels
对权重训练和剪枝后,使其成为固定的数据,在此基础上,可以在线下对权重进行分析并以压缩格式存储和传输。如图4所示,采用二维掩码Mask 的格式对权重进行索引,每组卷积核共有K×K个lbC位宽的权重索引数据。特征图数据是动态数据,需要线上实时产生,因此,处理方式为线上实时判断。

图4 权重数据及其Mask 索引Fig.4 Weight data and its Mask index
2.2 加速器整体架构设计
本文基于FPGA 器件设计稀疏神经网络加速器,其整体架构如图5所示。

图5 稀疏神经网络加速器整体架构Fig.5 Overall architecture of sparse CNN accelerator
在图5 中,特征图和权重通过FPGA 的AXI4 接口从片外传入片上缓存,然后片上缓存再将数据传入处理模块(Processing Unit,PU)。为利用FPGA的并行特性,多个PU 在输入特征图的横向尺寸W、纵向尺寸H和输出通道N方向做并行操作,因此,共有PW×PH×PN个PU 单元参与运算。每个处理模块承担C通道K×K尺寸的输入特征图与其对应的权重做卷积以及通道间累加的计算工作,从而产生某一输出通道的输出特征图点。由于输入特征图和权重的稀疏特性,PU 会主要通过逻辑单元来提取出有效的值参与运算。PU 单元得到的结果通过输出特征图缓存,并且同样通过AXI4 接口输出到片外。
2.3 处理单元设计
每个PU 需要进行有效数据提取和计算工作,图6 为处理单元PU 的具体结构。

图6 处理单元的具体结构Fig.6 Detailed structure of the processing unit
如上文所述,在本文设计的加速器中,每个PU单元实现C×K×K个乘加运算。首先,每个K×K尺寸的输入特征与其对应权重的运算操作分到K×K个计算单元中;然后,每个计算单元做C通道乘累加操作得到中间输出;最后,将所有中间输出通过加法树得到最终输出结果。
计算单元的设计是稀疏神经网络加速的核心,需要达到选取有效数据参与运算的目标。图6 右半部分为计算单元的结构图。对于特征图向量,由于通过比较器判断是否为有效值(非零值),因此输出值i为0 或者为1。本文设计未采用文献[13]为特征图数据建立二维掩码索引的方案,因为建立索引的工作除了必要的有效值判断,还要对索引数据进行存储、传输等操作。C通道的权重Mask 索引可以使用lbC位宽的定点数Ik,k来表示(右侧图中使用的索引为I2,2)。每判断一个特征图点,会有局部计数器来输出计数count。有效地址判定器模块获取i、I2,2和count 值并执行逻辑运算sign3=(I2,2>>count)&i。该运算的功能是判断权重和特征图点是否同时为有效值。逻辑计算的结果反馈给控制单元,控制单元会提取有效的输入值给后端的乘累加单元。在FPGA 器件中,乘累加单元采用片上DSP 资源来实现。计算单元的结果会输出到加法树做最后的累加。
需要注意的是,做计算单元内部的并行,计算单元后端可以占用多个DSP 模块,假设为α 个。因此,DSP 资源的占用量DDSP可以根据以上讨论做预估,如式(2)所示:

其中:PW×PH×PN是指PU 阵列中PU 的个数;K×K是指PU 内部计算单元的个数,该值是固定的且这些计算单元中的DSP 除了计算输入通道方向最后几个数,在多数情况下不会出现“闲置”状态;α值与模型数据的稀疏特征有关,该值的获取将在下文进行讨论。
2.4 片上缓存与BRAM 存储块划分
片上缓存采用的是FPGA 片上BRAM 资源,主要考虑存储块划分和数据复用这2 点。存储块划分借鉴了文献[19],核心思想是尽量将计算过程中需要并行获取的参数值放到不同的BRAM Bank 中。表2 是根据该思想对特征图矩阵和权重矩阵在各个维度上的划分情况,表中的数字是指该维度下需要并行获取的数据个数。例如输入特征图缓存的宽度方向,PU 每次需要同时获取(PW+K-1)个数参与运算,那么该维度的数据可以平均分配到(PW+K-1)个BRAM 单元中。

表2 BRAM 存储器划分情况Table 2 Partition of BRAM memory
数据复用主要是为了减轻片上-片外传输的带宽压力,在满足存储块上述划分规则的情况下将尽量多的数据缓存在片上。以权重参数为例,片上PU阵列每批次运算需要K×K×PN×α个BRAM 单元,当该批次运算计算完成后,依然希望这些数存储在片上,以便于在输入特征图窗口滑动到下个位置时再复用这些数据。因此,添加一个与K×K×PN×α相乘的参数χweight来表征复用情况。
综上所述,根据表2 以及数据复用的考虑预估出片上BRAM 资源的占用情况,如式(3)所示:

需要注意的是,式(3)中输出特征图的复用参数χout是根据χin和χweight来确定的。
2.5 设计参数分析
本文加速器系统的设计参数有PW、PH、PN和α,这些参数都与并行操作相关。由2.2 节和2.3 节可知,加速系统共有(PW×PH×PN)×(K×K)个计算单元并行操作。α的值则与算法模型参数的稀疏化特征有关:α越大,并行操作的计算单元之间需要等待的时间会越短,但是DSP 模块的闲置越严重;α越小则相反。可以通过小规模实验实现不同α参数下的处理模块来确定最佳的设计参数。假设某卷积层参数为<W=224,H=224,C=64,N=64>,本文在具有不同数量DSP 的3 个典型的Xilinx 器件上实现单个PU,可获取的计算性能(GOPS)的计算如式(4)所示:

其中:λ表示在C方向上权重和输入特征图的的稀疏程度,实践中一般为20%~50%;I和L分别表示对PU做流水线优化后的启动间隔(Initiation Interval,III)和启动延迟(Initiation Latency,IL),它们均通过实验获得;f表示频率,设置为200 MHz。
初步实验结果如图7所示,可以看出,在不同的稀疏度情况下,PU 中的每个计算单元α取1 或者3 可以达到最佳的性能。需要注意的是,对于不同的器件和不同算法模型,以及同一算法模型中的不同层,均可使用该方法预估最佳性能。

图7 不同α 参数下处理单元的计算性能Fig.7 Computational performance of processing unit under different α parameters
3 实验与结果分析
3.1 实验设置
本文实验在GPU 平台训练了VGG16[20]网络并使用文献[16]的方法进行剪枝和再训练,最终采用的神经网络卷积层参数稀疏情况如表3所示。在Xilinx 硬软件环境下实现卷积层前向推理的加速,硬件平台为Xilinx Zynq XC7Z045,软件环境为Vivado HLx(v2018.3)。对于功耗,本文使用Xilinx 的Xpower工具给出评估结果。根据前文中的分析,设计参数设置为:PW=2,PH=2,PN=8,α=3,χin=2,Zweight=2。

表3 VGG16 卷积层稀疏情况Table 3 Sparsity of convolutional layer of VGG16 %
3.2 结果分析
表4 统计了最终的实验结果中FPGA 内部资源的使用情况。从中可以看出:LUT 占用量达到了93%,这是因为PU 为了处理稀疏的数据而增加了逻辑单元模块,这些逻辑单元模块主要都是由LUT 来实现;同时DSP 的数目达到了占比最多,这是因为硬件单元充分考虑了并行。
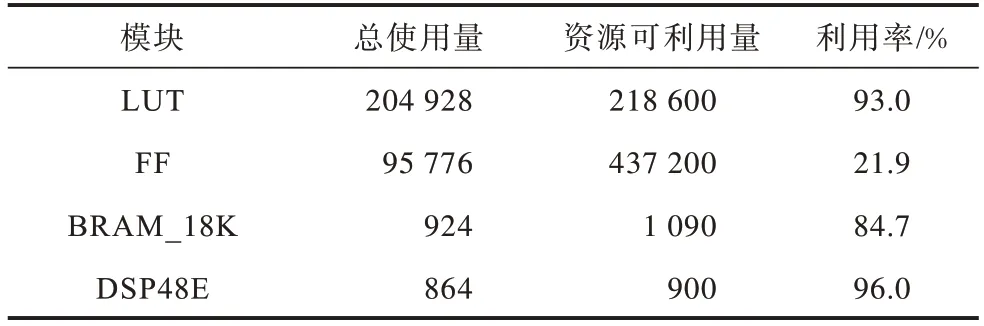
表4 实现VGG16 FPGA 的内部资源使用情况Table 4 Statistics of FPGA resource usage when implementing VGG16
计算性能和功耗比实验结果如表5所示,其中,本文设计的加速器对卷积层加速的总体性能为678.2 GOPS,性能功耗比为69.45 GOPS/W。此外,表5 也展示了本文方案与其他方案的比较结果,从中可以得出以下结论:

表5 性能与功耗指标实验结果及对比Table 5 Performance and energy efficiency experiment results and comparison
1)与稠密神经网络的FPGA 加速器的对比:与使用相同器件的文献[3]方案相比,本文计算性能和性能功耗比分别达到了它的2.9 倍和2.8 倍;与文献[4,6]方案相比,本文DSP 的使用量约为它们的60%,但却在计算性能指标上表现更优秀;与文献[5]方案相比,按每个DSP 可以达到的GOPS,计算性能基本一致,但是本文方案的性能功耗比较文献[5]方案低。
2)与稀疏神经网络的FPGA 加速器的对比:文献[7,14]均使用了ZCU102 平台,本文DSP 使用量分别是它们的75%和64%,计算性能指标上本文与它们相比分别有2.1 和1.3 倍的提升;在性能功耗比上则分别有5.3 和2.3 倍的提升。
4 结束语
本文提出一种针对神经网络模型的稀疏化卷积层FPGA 硬件加速器。设计稀疏数据处理单元避免无效计算,同时通过提高多个处理单元的并行度和探索最佳设计参数提高计算性能。在Xilinx 平台上的实验结果表明,本文设计能够有效提高稀疏化卷积层的实现性能和性能功耗比。下一步将对稀疏神经网络做软硬件协同优化:在软件方面,在剪枝过程就预先考虑硬件并行的需求,做面向硬件的平衡剪枝;在硬件方面,使用已有的并行、流水线等技术,将平衡剪枝后模型映射到FPGA 上。
