基于LSTM的S7协议模糊测试用例生成方法
2021-07-26姜亚光李建彬闫靖晨刘曙元李坤昌
姜亚光,陈 曦,2,李建彬,闫靖晨,刘曙元,李坤昌
(1.中国软件评测中心,北京100044;2.北京大学软件与微电子学院,北京102600;3.华北电力大学控制与计算机工程学院,北京100026;4.国能信控互联技术有限公司,北京100039)
0 概述
随着互联网设备的全面普及,面向工业控制(工控)系统的网络威胁日益增多,并且呈高强度和批量化的态势[1-2],因此,人们开始关注保护关键基础设施和制造工厂的重要性。互连和互操作性的发展扩大了工控系统的脆弱性,特别是在广泛应用和传播的背景下,数据被暴露给外部网络,在通过发动各种攻击获取系统数据后,入侵者的行为可能会对现有的工业过程造成严重损害[3]。2010年6月,一种复杂的网络武器——震网(Stuxnet)病毒肆虐全球[4],与传统网络病毒不同的是,震网病毒的攻击对象是国家重要基础设施,其本质是一种直接破坏现实世界中工业基础设施的恶意攻击代码。据赛门铁克公司统计,全球约有4.5 万个网络被该病毒感染。目前,主流的工业控制系统有DCS、SCADA、PLC、远程终端设备等[5-6]。为实现系统中不同级设备间的数据通信,各类通信协议被不断革新,其中由Siemens 公司基于ISO 协议设计实现的S7 通信协议在工业领域具有极其广泛的应用[7-9]。因此,S7 协议的安全性测试成为研究热点[10]。
目前,研究者针对工控系统的安全防护已经开展了一些研究工作。文献[11]通过分析S7 协议的内容与帧格式,使客户能够自己编写程序并用自己的socket 程序通过以太网读写西门子S200 PLC 区数据。文献[12]介绍网络协议的识别方法和测试用例生成技术,根据启发式搜索算法和概率权重,提出一种基于参数权重的启发式模糊测试框架。文献[13]使用基于规则的状态机和有状态规则树来指导模糊测试数据的生成,提高了有状态网络协议模糊化的效率和覆盖率,同时提高了测试效率。总体而言,针对工控网络协议漏洞挖掘的研究仍处于探索阶段。
目前,模糊测试是最常用的软件漏洞挖掘方法,基于模糊测试的漏洞挖掘技术[14-16]可面向部分公有协议进行高效的漏洞挖掘,但由于该类技术针对性不强且内容覆盖率低,因此在私有协议领域尚未得到较好应用。考虑到知识获取难度大、描述建模成本高等因素的影响,研究者多采用专家分析方法人工编写测试脚本,此方式不仅费时费力,而且对研究人员专业能力要求较高,生成的测试用例通过率也无法得到有效保证。由此可见,传统的模糊测试方法已不能满足工控系统的安全性要求。
神经网络模型[17-19]善于从海量数据中挖掘规则和知识,因此,将神经网络技术与工业通信安全防护工作相结合,是保障工控系统安全的一种重要举措[20-21]。本文利用长短期记忆(Long Short-Term Memory,LSTM)[22]神经网络模型强大的数据学习能力和预测能力,提出一种基于LSTM 的测试用例生成方法,通过不断学习提取西门子S7 协议的特征,自动产生满足协议结构的测试用例。
1 S7 协议与模糊测试
1.1 S7 协议
1.1.1 S7 协议结构
西门子S7 协议的TCP/IP 实现依赖于面向块的ISO 传输服务,协议结构如图1所示。S7 协议不仅允许协议数据单元(Protocol Data Unit,PDU)由TCP 承载,而且协议还包含在TPKT 和ISO-COTP 协议中。ISO 通过TCP 通信在RFC1006 中定义,ISO-COTP 在基于ISO 8073 协议(RFC905)的RFC2126 中定义。ST 协议结构如图1所示。

图1 S7 协议结构Fig.1 Structure of S7 protocol
1.1.2 S7 协议漏洞
当工控协议栈的程序中有漏洞时,其相应报文中的数据与协议中的规约会出现不同,这会引起上位机获取异常数据,进而导致组态界面与实际运行状态存在差异,使得现场工作人员无法正常工作。在工控系统行业漏洞库平台检索S7 协议,截止至2019年11月15日检索到相关漏洞77 条,其中仅2019年就有5 个漏洞。因此,对于模糊测试,本文提出通过学习得到S7 协议报文作为测试数据,用于发现协议中不符合协议规约的情况。
1.2 模糊测试
模糊测试可以将非预期的输入传送到目标系统,同时监视该系统的异常情况进而发现软件的漏洞[23-24]。为提高测试用例的代码覆盖度,在进行模糊时需要考虑输入向量的特征,例如协议测试时需要通过网络协议解析获得协议特征,根据已获得的协议特征进一步生成测试用例。此外,在实时监控传输测试用例进行模糊测试的过程中,根据被测对象的状态可以及时检测出异常情况。模糊测试流程如图2所示。依据不同的产生模式,网络协议模糊测试方法主要有基于变异的方法和基于生成的方法[25]2 种。
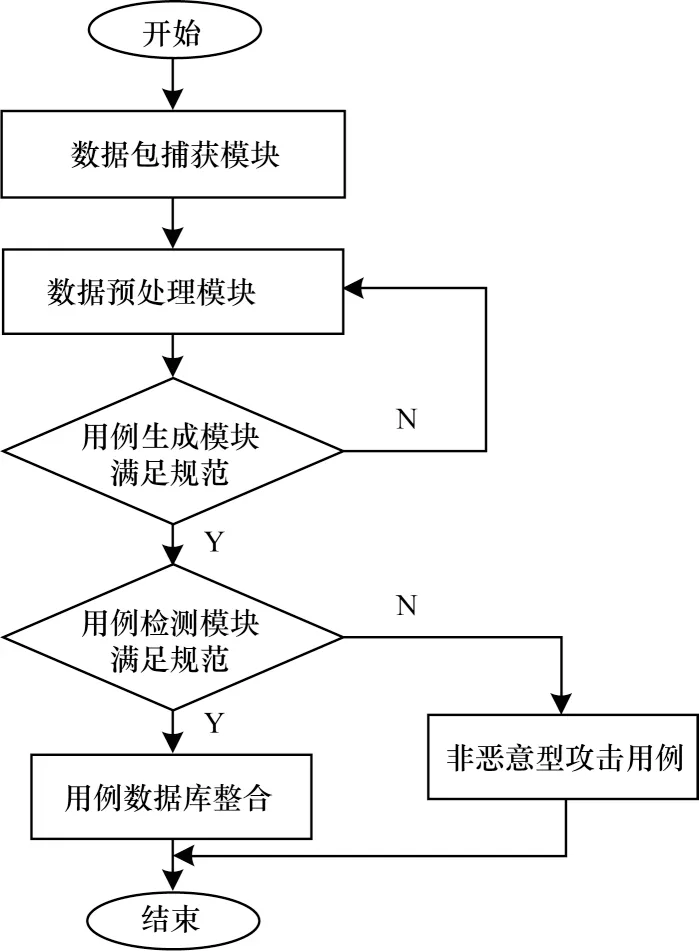
图2 模糊测试流程Fig.2 Procedure of fuzzy test
1.2.1 基于生成的模糊测试方法
基于生成的模糊测试方法需要根据已知网络协议的协议特征和测试用例生成策略,从而建立网络协议数据模型,并根据协议模型构造测试用例生成器,生成畸形的网络报文作为测试用例发送给被测对象。这种方法可以保证较高的测试用例接收率,但用例的异常程度不高,非法数据的覆盖程度相对较低,导致生成的用例在测试时效率低下,因此,为达到预计的测试效果,需要花费更多的时间和更多的用例数据进行测试。此外,这种基于生成的模糊测试方法一般需要根据协议特征来构建测试用例生成器,而满足这方面的需求不仅要做大量的网络协议相关的调研,而且还要求开发人员对关于网络协议的专业知识有相当的储备。
1.2.2 基于变异的模糊测试方法
基于变异的模糊测试方法首先捕获网络中正常通信的网络报文,然后依据制定的模糊策略将报文中的某些字段更改为非法的字段,在生成变异的测试用例后,再对被测对象进行模糊测试。该测试方法不要求提前对被测的网络协议进行深入了解学习,只需要针对特定的网络通信,截取通信过程中的数据包,根据指定的模糊策略对数据包进行模糊修改。这种测试方法能够给研究人员带来极大的便利。测试用例经过变异策略更改数据值之后都包含了一些不合法数据值,因此,该方法的不合法数据覆盖率较高,但是测试对象协议栈程序可能会拒绝接受包含不合法数据值的测试用例,最终导致基于变异的模糊测试方法生成的测试用例被接受的数量较少,降低了模糊测试的效率。
2 基于LSTM的S7协议模糊测试方法
2.1 LSTM 模型
LSTM 内部状态主要通过3 个不同作用的控制开关进行改变和更新,LSTM 模型结构如图3所示,其中一个开关的作用是保存长期状态c,另一个负责对即时状态向长期状态c 的传递,最后一个开关用于把控当前时刻的输出受长期状态c 的影响程度。门是神经网络中的一层全连接层,输入向量经过门之后输出0 到1 之间的实数向量,3 个开关都与门有关,分别对应遗忘门、输入门和输出门。以下公式表示了LSTM 的前向计算过程,通过加法和乘法运算修改信息用以更新当前状态。

图3 LSTM 模型结构Fig.3 Structure of LSTM model
若W表示权重,b表示偏置,δ(x)表示激活函数,则门函数表示为:

ft表示若遗忘门函数,Wf表示遗忘门函数侧权重,ht-1表示上一时刻LSTM 的输出值,bf表示遗忘门侧偏置,则遗忘门函数表示为:

若Wc表示单元状态的权重,xt表示t时刻的输入,bc表示单元状态的偏置值,则候选向量表示为:
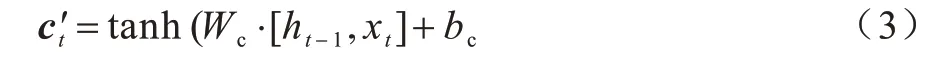
若ct表示更新状态,it表示输入门的向量值,ct-1表示上一时刻的状态,则更新状态为:

Sigmoid 门函数表示为:

若ht表示当前输出值,则:

2.2 模型构建
2.2.1 数据采集
本文在S7 模拟器传输过程中使用Wireshark 收集实验数据。S7 模拟器模拟测试基本情况如下:
一台装有WIN10 操作系统的笔记本,在该笔记本中安装S7 模拟器,以及虚拟环境下的WIN10 操作系统,同样安装S7 模拟器,打开笔记本上的S7 模拟器上的Server 服务器作为上位机,打开虚拟环境下的S7 模拟器中的Client 客户端作为下位机,例如PLC,然后在下位机上执行相应的控制操作,在笔记本上打开Wireshark 来实时抓取模拟器通信协议包,获取实验数据集。
模拟环境配置如下:1)WIN10(本机)S7 模拟器Server,IP地址为192.168.0.100;2)虚拟环境下的WIN10 S7 模拟器客户端,IP 地址为0.0.0.0;3)Wireshark_3.0.6,将IP 地址192.168.0.100 作为上位机,将IP 地址0.0.0.0作为下位机。
2.2.2 数据预处理
上述帧需要经过有效的预处理之后才能构造数据集,预处理过程主要包含3 步,分别是分析帧数据格式、数据进制转换和数据归一化处理。
1)分析帧数据的格式。使用网络抓包工具Wireshark 分析可知,S7 协议的数据帧是十六进制的字符串数据。
2)数据进制转换。笔者通过分析发现,十六进制的字母无法直接用于模糊测试用例的生成,即无法用作测试用例生成模型的输入,因此,将数据由十六进制转换为十进制数字来表示。此处主要考虑将一维十六进制转换为一维十进制。转换公式为H(data)→D(data)。
3)数据归一化。数据归一化过程包括去除数据中的无效数据、空缺数据和不完整数据的处理,将所得数据归一化。去冗操作主要是去除数据集databegin 中的空值,归一化处理主要是将数据归一化到0.0~0.5 之间。
2.2.3 构建方法
为实现对S7 协议的模糊测试,本文使用LSTM神经网络对S7 协议数据进行预测。该模型主要包括数据预处理模块、测试用例生成模型搭建模块和测试用例检测模块。
1)数据预处理模块主要包括数据格式分析、数据进制转换和数据归一化处理。程序实现时的伪代码如下:

2)测试用例生成模型搭建模块主要包括LSTM数据输入、前向计算和训练输出。在实现设计程序时,利用局部模糊来对S7 协议帧各字段进行模糊分析,其伪代码如下:

3)测试用例检测模块主要包括检测将特征值字段修改为边界值、字段置为空、变更字段长度引起溢出。程序实现时的伪代码如下:

通过上述3 个模块的实现,可以完成数据预处理且归一化,用处理过后的数据作为模型输入能够生成测试用例并检测出测试用例是否有效。
3 实验验证
实验的模型主要采用LSTM 来对S7 协议样本数据进行训练,进而生成更多的有效测试用例。在实验中,S7 协议中的特征值字段分为可变字段和不可变字段,对可变字段进行模糊,对不可变字段做固定值操作,进而局部模糊生成测试用例。
3.1 数据采集和预处理
本文根据S7 模拟器模拟实际上位机和下位机的通信过程,获取到138 481 条数据帧,这些数据帧类型很多,也存在重复问题。因此,对获取的样本集合进行分类、整合、去重,得到99 289 个有效的数据帧样本。在此基础上,对这些数据帧做进制转换处理,对转换后的十进制数据做归一化处理,得到0.0~0.5 之间的数作为模型的输入,形成23.03 MB 大小的训练数据集。
3.2 模型参数训练和硬件配置
LSTM 模型按Batch-size 为31 和61 形成2 组参数,其他设置为序列长度为2、1 层、4 个隐藏节点、0.01 学习率和100 轮次训练。
硬件配置为Intel®Core i7-8750 CPU,8 GB 内存的服务器。训练时间约为40 h。
3.3 测试用例集的生成
测试所用数据包括数据生成和数据帧组装两部分。通过LSTM 模型生成99 289 个模糊测试数据,然后和物理层到传输层的数据组装在一起,形成完整的测试数据帧。
3.4 测试用例执行
为保证生成数据有效,使用脚本语言Python 编写测试用例的执行脚本。本地服务端存放组装后的S7 协议数据帧,虚拟机模拟下位机,与上位机通信获取组装后的S7 协议数据帧。首先启动snap7 服务器端,启动服务,然后把生成的测试用例放入脚本中,再运行脚本程序,即可将测试用例发送到服务器上,如图4所示。

图4 测试用例发送至服务器的界面Fig.4 Interface of sending test cases to server
判定1 条测试用例是否有效,其原理是检测测试用例对应的协议控制操作是否会导致故障的发现,若发生故障,则测试用例有效,反之则无效。如图5所示,1 条有效的测试用例主要包括9 个特征值,分别为Type、Version、Header Length 等字段。实验考虑空指针、溢出和数值边界这3 种异常情况。
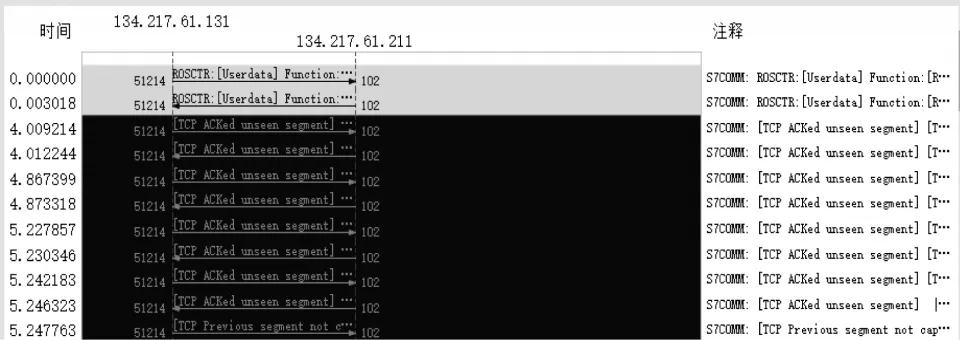
图5 判定1 条测试用例是否有效的界面Fig.5 Interface of judging validity of a test case
3.5 实验结果分析
本文所采用的算法为LSTM 算法,利用局部模糊来对S7 协议帧各字段进行模糊分析。由实验结果可知,模型生成的数据机构和训练集合中的数据帧很相似,可见循环神经网络模型对S7 协议结构学习有较好的结果。图6 为部分生成的测试数据结果。图中显示,LSTM 模型预测出的数据已经具备真实测试用例的特征,可根据特征进行测试用例的预测。与Peach 对特征字段关联性很小的方法相比,本文模型对特征字段关联性较大。实验结果显示本文方法所生成的测试用例代码覆盖度较高,验证了其有效性。

图6 部分测试数据预测结果Fig.6 Partial prediction results of test data
4 结束语
本文提出一种基于神经网络的S7 协议模糊测试用例生成方法。通过LSTM 神经网络模型学习S7 协议样本,得到协议的结构特征,预测生成符合结构特征的测试用例。仿真实验对不同字段进行局部模糊,结果表明,该模型生成了大量有效的测试用例,预测出的数据具备真实测试用例的特征,测试用例的代码覆盖度较高,从而验证了本文方法的有效性。然而本文所构建的模型数据来源类型单一,神经网络本身所带有的随机性导致用例生成时某些固定字段存在误差,并且脆弱性字段比较固定,而在实际应用中工控网络面临复杂的安全问题。因此,下一步将研究数据来源不同和字段值发生改变时如何生成更有效的测试用例,并进行对比实验。
