基于改进GA-Elman的无线智能传播损耗预测方法
2021-07-26郑娟毅苏海龙殷帅帅刘遥遥
郑娟毅,崔 卓,苏海龙,殷帅帅,刘遥遥
(西安邮电大学通信与信息工程学院,西安710121)
0 概述
2019年为5G 元年,很多通信企业为推动5G 在国内与海外的部署而努力[1]。在5G 网络的部署过程中,需要合理地选定基站部署位置以满足客户的通信需求,而无线信道评估对网络部署和链路预算尤其重要。目前,研究者对于无线信道测量主要分大尺度[2]和小尺度[3]两种特性进行研究。前者考虑无线电波的路径传播损耗,后者研究信号在传输过程中时域、频域和空域的参数变化以及基带调制等问题。本文从大尺度特性这一角度展开研究。
5G 网络可使人们能够以极低的延迟和极高的数据传输速率在大范围的场景中访问和共享信息[4]。然而,5G 移动通信系统的网络规划面临严峻挑战,需要更高效、精准的无线信道传播损耗预测模型。传统的信道传播损耗预测模型分为经验模型、确定性模型[5]和随机模型[6]。经验模型基于广泛的测量数据得到,其通过函数来描述传播环境的主要特征,经典经验模型有Okumura、SPM 和Hata[7]。经验模型所需特征少,当环境发生变化时,需要进行参数的重新拟合,否则其准确度可能很差[8]。确定性模型需要通过大量的计算和数据校准来保证精确度[9],这会导致计算复杂度较高,并使模型过分依赖传播场景的精准信息。随机模型利用一定的概率分布来描述信道参数,以相对较低的精度来适应各种场景。5G 通信系统中的各种技术[10]与传统通信系统相比具有明显不同的传播特性,如大规模MIMO 通信、V2V 通信、HST 通信、mmWave 通信等[11]。5G 信道建模具有需要考虑的频率范围宽、带宽大、天线数量多、场景多样、测量数据量巨大等特性,而对测量数据进行处理是一个十分耗时的过程,并且需要很强的计算能力[12]。
近年来,大数据研究取得了较多成果。文献[13]提出利用大数据理论来构建信道传播模型的思路具有合理性,文献[14]则利用少量实测数据证明了基于人工神经网络、支持向量机、随机森林等机器学习的路径损耗预测模型均优于传统的log-distance 模型。机器学习,特别是监督学习方法,可以模拟隐藏的非线性关系,能够很好地权衡模型的准确性与复杂性之间的关系。文献[15-16]证实了基于机器学习的模型比经验模型更准确,比确定性模型计算效率更高。
神经网络具有并行处理、自适应性、自学习性、鲁棒性等优点,常被用于解决非线性系统问题。Elman 神经网络与神经网络不同之处在于其具有局部记忆功能,但也不可避免地继承了神经网络的一些不足[17],例如容易陷入局部极小解甚至训练失败和隐藏神经元数量需要反复试错确定等。针对这些问题,研究者对Elman的连接权值阈值和网络结构单独进行优化,在改善网络性能方面取得了较好的效果。
本文提出一种通过遗传算法(Genetic Algorithm,GA)改进Elman 网络模型的无线智能传播损耗预测方法。利用自适应遗传算法同时对Elman 神经网络的权值、阈值和网络结构进行优化,解决Elman 神经网络连接权值、阈值和神经元难以确定的问题,从而避免陷入局部最优,提高神经网络的预测性能。
1 Elman 神经网络和遗传算法
1.1 Elman 神经网络
Elman 神经网络是一种具有局部记忆功能的反馈型递归神经网络,其为4 层结构网络,包含输入层、隐含层、承接层和输出层。输入层神经元接收外部信息,将信号传递给隐含层;隐含层通过激活函数对信号进行变换处理;承接层记忆隐含层前一时刻输出值,增强网络的内部反馈机制,从而使网络能够适应动态、时变的特性,并保证全局的稳定性[18];输出层输出结果。Elman 网络模型结构如图1所示。

图1 Elman 网络结构Fig.1 Structure of Elman network
假设系统有n个输入、m个输出,隐含层和承接层各具有r个神经元,w1~w3分别记作输入层到隐含层、承接层到隐含层、隐含层到输出层的连接权值,Elman网络的非线性状态空间描述表达式为:
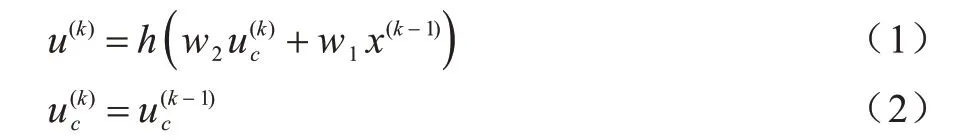
其中,h(·)表示隐含层的传递函数,通常为s 型函数[19],如式(3)所示。

输出向量y(k)表示为式(4),其中,g表示输出层传递函数。

在Elman 神经网络中使用人工神经网络算法对权值进行修正,网络误差表示表示为:

1.2 遗传算法
遗传算法(GA)是一种具有高度并行性、随机性和自适应性的全局搜索算法。研究者利用GA 较强的全局搜索能力来解决多目标优化、最优路线、特征选择和神经网络算法易陷入局部最优等问题。
遗传算法流程如图2所示,其主要由编码机制、适应度函数、遗传算子和控制参数组成。在使用遗传算法解决问题时,首先对可能解进行个体编码,确定初始种群,在计算适应度函数后输出满足终止条件的个体,算法结束,否则,系统将一系列遗传操作(如选择、交叉、突变等)应用于当前种群,形成新一代的种群。新的种群继承了上一代的优良特性,并优于上一代,因此,可以逐步发展为更好的解决方案。

图2 遗传算法流程Fig.2 Procedure of genetic algorithm
2 基于GA-Elman的无线传播损耗预测
传统的Elman 神经网络模型通常使用梯度下降法对连接权值阈值进行训练学习,容易陷入局部极小值。同时,神经网络的连接权值阈值和网络结构主要依赖于网络训练者的试错经验确定,并没有理论依据支撑,这都使神经网络很难具有全局性,易导致训练失败或者过拟合现象。遗传算法是一种自适应全局寻优算法,具有很好的全局搜索能力[20],可用于搜索不可微、多模和大规模的问题空间而不需要关于误差函数梯度的信息。使用遗传算法优化神经网络的连接权值和阈值时,应在误差函数中插入一个惩罚项,该惩罚项与是否可微无关,这可以降低神经网络的复杂度,提高其泛化能力,对于优化Elman 神经网络的连接权值阈值具有很大的潜力。同时,遗传算法还可以探索不同的优化拓扑结构,缓解隐含神经元数量难以确定的问题。
2.1 对GA-Elman 算法的优化思路
考虑以往单独从权值阈值方面或者仅从网络结构方面来优化神经网络的方法和现实应用环境的复杂性,本文构建一个改进的GA-Elman 神经网络算法。首先利用遗传算法对神经网络结构进行优化,然后在确定Elman 神经网络结构的前提下,推导出其中的连接权值阈值,从而得到最优的含有单层隐含层的Elman 神经网络。
在信道传输损耗预测模型的构建过程中,必然会应用到超大量的无线传输历史数据。在通常情况下,Elman 神经网络都是采用单隐含层的结构。当输入超大量数据时,为提高学习效率和收敛速度,常采用多隐含层的结构,每一层对前一层的抽象会表达得更加深入,深层的网络比浅层的网络具有更高的识别效率[21]。通过遗传算法对Elman 神经网络算法的优化,能够得到单层最优网络。假设单层隐含层包含神经元数量为n,则k层隐含层时设置的单层节点数为n/k,在运行速率一定的情况下,本文通过比较选取误差最小的隐含层数,构造GA-Elman 神经网络模型。
本文提出的优化训练过程本质是一种混合的同步训练过程,其效果优于单纯的Elman 训练。本文对Elman 算法的优化,是基于结构完全优化的同时也对连接权值阈值进行优化。
2.2 优化步骤
本文使用遗传算法同时优化Elman 网络结构和连接权值阈值,具体步骤如下:
步骤1对网络结构和连接权值阈值进行编码。
基于问题的复杂性,原有的二进制编码明显不合适,本文采用实数编码,简单直观。假设一个有R个输入、M个输出和N个隐含神经元的Elman 神经网络。该实数编码针对给定的网络结构条件。
1)对权值和阈值进行编码,编码长度为:

2)对网络结构进行编码,与权值阈值不同之处在于要在隐含层的神经元基因中加入一个利用随机函数生成的0/1 控制基因。当该控制基因的值为0时,对应的隐含层神经元对输出层不产生影响,反之,当控制基因的值为1 时,隐含神经元会对输出层产生影响。编码长度为:

步骤2对步骤1 的编码链进行解码,得到N个不同的神经网络。
步骤3根据给定的训练样本预先定义学习参数。
步骤4确定是否存在满足误差精度要求的神经网络。如果是,转到步骤9;否则,转到步骤5。
步骤5计算每个个体的适应度,根据个体的适应度值对个体进行排序,选择适应度值最高的个体直接留到下一代。适应度函数是用来评价个体优劣程度的函数,函数值越小,个体越优秀。具体公式如下:

其中,Yi为预测值为期望值,n为样本数目。
步骤6对当前种群进行遗传操作,将选择、交叉和变异操作应用于当前种群,产生新生代,并添加到下一代。
步骤7确定人口规模是否达到上限。如果是,转到步骤8;否则,转到步骤5。
步骤8确定遗传算法的迭代次数是否达到预先设定的限制。如果是,转到步骤9;否则,转到步骤4。
步骤9确定最优的初始Elman 神经网络,使用预先设定的参数继续训练。
步骤10如果精度满足误差函数的要求,或者Elman 算法的迭代次数达到预先设定的限制,则算法终止。
上述对Elman 网络的优化,意义在于设计出最优网络结构的Elman,从而提高其解决问题的能力,同时优化连接权值和阈值,增强训练速度等收敛性能,缩短训练时间,提高神经网络的运行效率。
3 仿真与评估
本节将GA-Elman 网络应用于无线通信中,并与仅优化连接权值阈值的GA-Elman 神经网络[22](记为GA-Elman)和标准Elman 神经网络(记为Elman)的预测结果进行对比。将本文利用遗传算法同时优化网络结构和权值阈值的Elman 神经网络记为Improved-GA-Elman。
3.1 评价标准
采用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差比(Average Absolute Error Ratio,MAPE)、平均绝对误差(Mean Absolute Error,MAE)和均方误差(Mean Square Error,MSE)作为预测结果是否准确的评价标准,分别用RRMSE、MMAPE、MMAE和MMSE表示,计算公式如下:

其中,Yi为预测值,为期望值,n为样本数目。
3.2 数据处理
仿真所选用的数据来源于华为云,其中包含4 000个小区约1 200 万条数据,本次实验从中随机抽取600 个小区,共计约196 万条数据,在每个小区中随机抽取400 条数据,共约24 万条数据作为测试集,将其余数据作为训练集。数据已经经过清洗,不包含损坏的数据。
本文首先对数据特征进行相关性分析,然后选取15 项特征,分别为自由空间的无线传播损耗、接收点和发射点之间的水平距离、接收点和发射点之间的三维空间距离、接收点和发射点之间的相对高度、小区发射机水平方向角、小区发射机垂直电下倾角、小区发射机垂直机械下倾角、发射机中心频率、小区发射机发射功率、发射点地物类型、接收点地物类型、阻挡物数量、最差阻挡物高度、最差阻挡物与发射点的水平距离和参考信号接收功率(Reference Signal Received Power,RSRP)。实验通过前14 项特征对第15 项RSRP 标签数据进行预测。
为防止因输入各特征量级差别太大导致网络的预测精度变差,对输入数据进行归一化处理,如式(13)所示,并且对预测结果进行反归一化处理,如式(14)所示。

其中,xmax、xmin表示样本数据中最大和最小值,Qi表示归一化后的数据。
3.3 仿真结果分析
通过仿真测试New-GA-Elman、GA-Elman 和Elman 是否满足5G 无线智能传播损耗预测并具有较好的预测精度。
3 种神经网络的输入为14 个特征,输出为对RSRP标签数据的预测结果。GA-Elman 与Elman 神经网络都是具有一层隐含层的网络结构,经过多次尝试可知,设定其隐含层神经元总数为7 个~9 个比较合适,本文实验设定取8 个。遗传算法初始种群为600,交叉概率0.35,变异概率0.09,遗传代数1 000 代。Improved-GAElman、GA-Elman、Elman 预测算法输出值以及期望值拟合与误差情况如图3~图6所示。

图3 Improved-GA-Elman 与Elman 预测结果对比(部分)Fig.3 Comparison of prediction results of Improved-GA-Elman and Elman(partial data)

图6 Improved-GA-Elman 与GA-Elman 预测误差对比(部分)Fig.6 Comparison of prediction errors of Improved-GA-Elman and GA-Elman(partial data)

图5 Improved-GA-Elman 与GA-Elman 预测结果对比(部分)Fig.5 Comparison of prediction results of Improved-GA-Elman and GA-Elman(partial data)
从图4 和图6 可以看出,Improved-GA-Elman 神经网络的预测精度明显高于GA-Elman 和Elman。为进行更清晰的对比,列出不同预测方法的MAE、MAPE、MSE 和RMSE 指标,如表1所示,可以看出Improved-GA-Elman 神经网络的预测精度明显优于GA-Elman 和Elman 网络。

图4 Improved-GA-Elman 与Elman 预测误差对比(部分)Fig.4 Comparison of prediction errors of Improved-GA-Elman and Elman(partial data)

表1 预测误差指标对比Table 1 Comparison of prediction error indicators
根据中国移动测试要求:当RSRP 大于-85 dBm时,属于信号极好点;当RSRP在-85 dBm~-95 dBm范围内时,属于信号好点;当RSRP 在-95 dBm~-105 dBm 范围内时,属于信号中点;当RSRP在-105 dBm~-115 dBm 范围内时,属于信号差点;当RSRP 小于-115 dB 时,属于信号极差点。其中,每个级别相差10 dBm。因此,当预测结果与真实值相差在±5 dBm 之间时,说明预测结果相当准确,基本不会造成对无线网络规划的错误指导。从表2 可以看出,Improved-GA-Elman 有92.76%的预测样本相对误差≤5 dBm,说明本文提出的基于改进GA-Elman的无线智能传播损耗预测方法对无线通信建设具有较好的指导作用。

表2 预测误差在真实值±5 dBm 之间的预测样本统计Table 2 Prediction sample statistics with prediction errors between true value ±5 dBm
4 结束语
针对Elman 神经网络易陷入局部极小值、训练速度慢和隐藏神经元数量难以确定的问题,本文通过引入遗传算法,设计一种基于网络结构和连接权值阈值联合优化的无线信道损耗预测方法。利用遗传算法的全局搜索和Elman 神经网络的局部搜索能力,使网络结构和连接权值阈值得到精确调整,在此基础上进行无线信道传播损耗预测。实验结果表明,该方法能够精准预测平均接收信号功率(RSRP),可对网络建设起到指导作用。下一步将从提高预测效率、降低时间消耗和利用大数据平台建立实时动态无线传播模型的角度出发对本文方法进行优化,并使其能够适用于一些特殊场景(如高铁、飞机、隧道等场景)。
