基于层次时空特征与多头注意力的恶意加密流量识别
2021-07-26蒋彤彤尹魏昕
蒋彤彤,尹魏昕,蔡 冰,张 琨
(1.南京理工大学计算机科学与工程学院,南京210094;2.国家计算机网络与信息安全管理中心江苏分中心网络安全处,南京210019;3.国家计算机网络与信息安全管理中心江苏分中心技术保障处,南京210019)
0 概述
近年来,信息安全问题日益成为国家、企业和个人所关注的热点,公众对个人隐私信息保护意识的提高促进了信息加密技术的发展,从2019年起互联网中HTTPS 加密流量占比已超过HTTP 流量。TLS、IPSec、SSH 等流量加密和认证技术一方面加强了信息通信的保密性和可靠性,另一方面越来越多的攻击者通过加密信道和流量加密技术隐藏自己的恶意行为[1],规避防火墙的检测,给网络安全监测带来了巨大考验。例如,木马、广告软件、勒索软件等恶意软件通过与命令和控制服务器之间的通信,即C&C 通信方式来接收与执行命令进行恶意活动。在传统情况下根据明文流量模式,C&C 服务器的域名、URL 等威胁情报信息可以被直接检测并及时制止[2],然而流量加密技术使得这些信息难以被正确解析提取,且解密将消耗大量计算资源。文献[3]指出,截至2020年,超过六成的企业将无法直接解密HTTPS 来识别隐藏在流量中的恶意软件。为避开解密并精确识别恶意加密软件流量,本文以HTTPS 加密协议流量为研究对象,利用网络流量的“网络流-数据包-字节”分层结构特征和动态时序性,提出一种基于层次时空特征与多头注意力(Hierarchical Spatiotemporal feature and Multi-Head Self-Attention,HST-MHSA)模型的恶意加密流量识别方法,并基于公开数据集CICAndMal2017 验证HST-MHSA 模型的有效性。
1 相关研究
目前,越来越多的恶意软件使用TLS 协议通过C&C 通道加密交换数据,传统基于端口或者DPI 的方法不再适用于识别此类威胁,因为流量加密时所有上层信息为不可见,加密技术改变了原本明文流量规则和可解析模式与特征。然而,加密技术的滥用对网络管理和安全带来了新的挑战,学术界和工业界将研究重点转移到基于机器学习的恶意加密流量监测研究方式上并取得了一些研究成果[4]。ANDERSON 等[5]经过深入分析提取流量元数据和TLS 头部大量特征进行恶意软件分类。LIU 等[6]提取了流行为、TLS 明文信息、证书这3 个维度的特征,结合在线随机森林模型实时区分恶意加密流量。YU 等[7]提取TLS 握手与验证阶段的特征,并引入层次聚类方法压缩数据运算,加快系统检测效率。BAZUHAIR 等[8]采用平均不纯度减少算法筛选出24 个流量特征,并加入柏林噪声增强特征图像,加强卷积神经网络(Convolutional Neural Network,CNN)模型的泛化能力。胡斌等[9]提出一种不依赖五元组信息的加密恶意流量检测方法,联合报文负载特征和流指纹特征来提高复杂环境下加密恶意流量的检测率。然而,这些方法多数依赖专家知识,将重点放在优化特征工程方面,需要花费大量的人力、时间等资源,且所提取的特征通常普适性较差。
深度学习技术作为一种端到端的学习框架,近年来在图像识别、自然语言处理等领域得到广泛应用,而流量识别领域的研究人员也开始基于深度学习模型自动提取流量特征。WANG 等[10]将流量转换为灰度图,并使用二维CNN 提取流量空间特征,但该方法仅利用了整条流量的前784 个字节,未充分结合流量的其他信息且缺乏对IP 地址的匿名化处理。王攀等[11]通过堆栈式自动编码器提取流量特征进行加密流量识别。程华等[12]将流量负载通过Word2vec 模型转换为句子向量,并利用CNN 实现恶意加密C&C流量识别。此外,ILIYASU 等[13]和GUO 等[14]利用半监督和无监督方法有效解决标签样本量不足时加密流量的识别问题。
为了避免繁琐的特征工程并且更好地表征加密流量的深层特性,本文在已有研究的基础上,结合CNN、循环神经网络(Recurrent Neural Network,RNN)和多头注意力机制[15]进一步挖掘流量分层的关键时空特征,从而更准确地识别恶意加密流量。
2 基于HST-MHSA 的恶意加密流量识别方法
本文提出的恶意加密流量识别方法主要包括流量预处理、网络流量分层表征、流量分类检测这3 个阶段,各阶段主要操作如下:
1)预处理阶段。筛选存在噪音的原始流量,转化为网络流量字节,并以十进制形式表示。
2)网络流量分层表征阶段。首先,在数据包层,利用词嵌入(Embedding)技术将字节转换为稠密向量表示并将其作为流量原始信息,同时利用双向长短时记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络提取流量前后的依赖信息,并将两者相融合以增强流量表征。然后,使用多尺寸卷积核的并行CNN 模型提取多视野的局部信息,整合得到数据包内部时空关联特征。接着,在流量会话层通过BiLSTM 捕捉多数据包之间的时序关系,并基于多头注意力机制改进重要数据包特征的提取能力,减轻噪音特征的影响。
3)流量分类检测。通过Softmax 分类器实现恶意加密流量识别。
HST-MHSA 模型总体框架如图1所示。
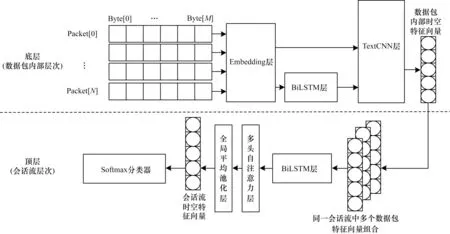
图1 HST-MHSA 模型总体框架Fig.1 Overall framework of HST-MHSA model
2.1 流量表示与预处理
数据包是网络流的基本传输单元,每个数据包由具有固定格式的数据包头部字节和有效荷载字节组成,因此网络流具有“网络流-数据包-字节”的分层结构。相比单向流,由通信双方数据包组成的会话流含有更多交互信息[10],因此本文选择会话作为流量分类粒度,会话表示如式(1)所示:

其中:pi为按时间ti排序的数据包;b为源S 和目的端D 可互换的五元组信息;为会话中各数据包的长度和;t为首数据包的开始时间;d=tn-t为会话持续时间。因此,原始流量可表示为F={Session1,Session2,…,Sessionm},m为会话流总数。
预处理阶段完成从原始网络流量pcap 文件向适合深度学习处理的字节序列csv 文件的转换,主要流程如图2所示。首先,根据式(1)进行原始网络流量切割,重组为多个会话流文件;接着,删除空流和重复文件,过滤非HTTPS 的流量以及数据包数目小于3 的无效会话;然后,去除MAC 地址、IP 地址等对分类结果产生干扰的特定信息;最后,根据网络流量传输的字节范围为[0,255]的特点,提取每条会话中前N个数据包的前M个字节,若超出长度则截断,否则补充256 并标记该会话。

图2 流量预处理流程Fig.2 Procedure of traffic preprocessing
2.2 基于LSTM 与CNN 的数据包时空特征提取
经过预处理后,每条会话表示为N×M个字节的一维形式。文献[16]采用One-hot 编码将每个数据包转换为二维图像,但生成的数据过于稀疏而导致模型训练速率低下。本文采用Embedding 方式,将每个数据包由M×1 的一维序列,转换为M×J的二维稠密向量,其中第i个字节表示为一维向量则M个字节表示为a1:M=a1⊕a2⊕…⊕aM,作为数据包原始信息编码。
数据包内部字节具有前后关联性,类似于句子中词语之间的关系,RNN 擅长捕获句子上下文特征,双向RNN 可以从前后两个方向捕捉前后顺序联系,避免后文信息的丢失。本文选用双向LSTM 挖掘数据包内部前后依赖信息,LSTM 基于RNN 引入选择性机制,可以避免RNN 梯度消失问题。在时间步t上基于3 种门结构完成对前一步的输出ht-1和当前输入xt的计算,分别为输入门it决定需要被保留的新输入信息,经过tanh 层的计算得出一个新的候选值˜,进一步得到细胞状态Ct,遗忘门ft决定是否保留数据,输出门ot决定输出的信息ht。更新当前隐藏状态需要将当前细胞状态向量Ct中每个元素经过tanh 函数并与输出门ot的值进行元素层面的乘积,具体计算如式(2)~式(7)所示:

通过将Embedding 处理后的数据包字节向量输入双向LSTM 层提取数据包内部全局依赖关系,作为数据包全局时序特征表示H=hforward⊕hbackward,与原始信息编码a1:M拼接得到数据包的时序拓展信息E=[eij],以增强数据包内部时序特征的表征能力。
利用TextCNN 模块[17]进一步提取数据包内部的局部空间特征。该模块的核心是多通道卷积和池化操作,采用多种尺寸的一维卷积核提取多视野的空间特征,并且卷积操作可以并行进行,大幅加快了模型的训练速度。通过第r个尺寸为d的卷积核对拓展数据包编码E进行卷积操作,如式(8)所示:

其中:F为Relu 函数;Wr和br分别为第r个卷积核和偏置;为卷积后的特征。本文选用的3 种卷积核尺寸分别为3、4、5,并对每个卷积操作后得到的特征图进行最大池化操作(如式(9)所示),以简化计算复杂度,抽取主要数据包的时空特征。

在合并多粒度局部特征后,为了减少参数规模,加快模型训练速度,使用全局最大池化替代文献[17]中的全连接层,最终输出数据包的内部时空特征向量。数据包层混合时空特征提取模型结构如图3所示。

图3 数据包层混合时空特征提取模型结构Fig.3 Structure of hybrid spatiotemporal feature extraction model for packet layer
2.3 基于多头注意力的会话层关键时序特征提取
网络流量传播过程中数据包具有明显的先后顺序关系,且前几个TLS 握手阶段的数据包对流量识别具有重要作用。因此,在经过底层模型处理得到多个独立数据包的时空特征向量后,使用BiLSTM层同时处理同一个会话中的N个数据包特征向量,捕获不同数据包之间的时间序列关系。然而,LSTM在长距离传播中损失较多信息且对特征重要度不敏感,因此采用多头注意力机制改进会话层对数据包重要特征的提取过程。多头注意力机制进行多次自注意力计算,自注意力是一般注意力的改进,利用查询(Q)=键(K)=值(V)的特征能充分捕捉序列内部数据的长距离依赖关系,并赋予不同属性不同权重。本文采用缩放点积注意力机制,多头注意力对Q、K、V使用不同的权重矩阵并行进行h次线性变换,得到不同的数据包向量注意力,最终合并输出全局特征,可以高效学习到不同的表示子空间中的关键信息,具体计算如式(10)~式(12)所示:
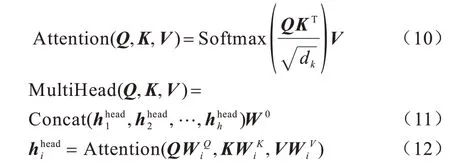
其中:dk为K矩阵的维度;Softmax 函数将Q与K进行点积运算并归一化的结果转换为概率分布,与矩阵V相乘得到注意力权重求和结果。
图4 为基于多头注意力机制的会话层关键时序特征提取模型结构。将多头注意力层输出的会话层全局特征经过全局平均池化处理得到会话流时空特征向量,输入到Softmax 分类器,进行恶意加密流量识别。

图4 基于多头注意力机制的会话层关键特征提取模型结构Fig.4 Structure of key feature extraction model based on multi-head attention mechanism for session layer
2.4 算法流程
本文提出的基于HST-MHSA 模型的恶意加密流量识别算法的具体步骤为:1)基于LSTM 和TextCNN 的数据包内的时空特征提取;2)基于多头注意力机制的会话层时序特征提取;3)Softmax 分类;4)模型训练与验证;5)模型测试与评估。
算法1基于HST-MHSA 模型的恶意加密流量识别算法


3 实验设置
3.1 实验环境
实验环境根据流量预处理节点及模型构建与训练阶段分别进行设置:1)在流量预处理阶段,实验运行在配置为Windows10 操作系统、Python2.7 环境的计算机上,利用开源Scapy 库进行流量提取;2)在模型构建与训练过程中,实验运行在配置为Windows10 操作系统、Python3.6 环境、CPU 为12 核i7-8700k、内存为32 GB 的计算机上,采用GTX1080Ti显卡加速,基于Tensorflow 2.1 完成模型的构建以及训练调优。
HST-MHSA 模型的参数设置如下:在Embedding层中,嵌入维度为128;在BiLSTM 层中,隐藏神经元个数为128,返回整个序列的输出,激活函数为tanh;在CNN 层中,卷积核尺寸分别为3、4、5,卷积核个数为128,步长为1,激活函数为Relu;在最大池化层中,池化的窗口大小为2;在多头注意力层中,并行头数量为2;在Softmax 层中,隐藏神经元个数分别为2和4;在EarlyStopping 层中,观察值设为验证集的loss 值,监控的最小变化量为0.01,迭代次数为10。对比实验采用同层同参数值。实验使用早停机制动态控制训练次数,若连续迭代10 次后验证集的loss值仍在上升则停止训练,避免过拟合的同时提高鲁棒性。通过十折交叉验证防止实验偶然性,采用交叉熵损失函数及Adam 优化算法,平均训练迭代次数为15,批大小为50,训练集、验证集和测试集的比例分别设置为8∶1∶1。
3.2 实验数据集
CICAndMal2017 数据集[18]是由加拿大网络安全研究所整理的数据集,收集了运行于智能手机上的恶意和良性应用程序的真实流量,格式为pcap。本文选取其中C&C 通信的3 种恶意应用流量以及com.asiandate、com.askfm、com.asos.app 等多种正常应用流量(统称为Benign),具体数据情况如表1所示。

表1 数据集选取情况Table 1 Dataset selection
经过数据分析发现,超过50%的会话流所含数据包数量(N)不超过21,数据包平均长度约为300 Byte,最小长度约为40 Byte,为缩减计算规模并保留流量头部关键信息,本文选取数据包数量为21,每个数据包长度(M)为100 Byte。
3.3 实验评价方法
为从多方面评价本文HST-MHSA 模型对恶意加密流量的分类效果,选取F1 值(F)、漏报率(Missed Alarm Rate,MAR)和误报率(False Alarm Rate,FAR)这3 个评价指标,计算过程中涉及精确率(P)和召回率(R)指标,具体计算公式如式(13)~式(17)所示:

其中,TTP表示正确预测为c 类的c 类加密流数量,TTN表示正确预测为非c 的非c 类加密流数量,FFP表示错误预测为c 类的非c 类加密流数量,FFN为错误预测为非c 类的c 类加密流数量。在二分类实验中,c 类指恶意类别,F1 值取加权平均值。
3.4 实验与结果分析
3.4.1 并行头数量确定实验与结果分析
在多头注意力层,超参数并行头数量会影响不同特征的关注度,合适的并行头数量能更准确地提取数据包关键时空特征,过多或过少并行头数量均有可能造成有效特征的缺失或被干扰,从而影响模型分类效果。本文设置并行头数量分别为1、2、4 和8,实验结果如图5所示。可以看出,当并行头数量为2 时的分类结果F1 值和漏报率均优于其他并行头数目,误报率也较低。当并行头数量为1,即单头自注意力时,HST-MHSA 模型对多维特征信息的挖掘能力差于多头注意力,但并行头数量过多可能会造成噪声信息的增加,反而不利于关键特征的提取。

图5 并行头数量对模型分类效果的影响Fig.5 The influence of the number of parallel heads on the effect of model classification
3.4.2 变体模型对比实验与结果分析
为评估HST-MHSA 模型关键模块的有效性,设计以下3 种变体模型,模型各层参数设置一致:
1)HST-MHSA_neLSTM:基于HST-MHSA 模型,去除了嵌入层和TextCNN 层之间的用于提取数据包内部前后依赖关系的BiLSTM 层。
2)HST-MH:基于HST-MHSA 模型,去除了多头注意力层。
3)HST-MHSA_GRU:基于HST-MHSA 模型,将两层LSTM 均替换为RNN 门控循环单元(Gated Recurrent Unit,GRU)。GRU 是LSTM 的变体,将LSTM 的遗忘门和输入门合并为更新门。
表2 给出了HST-MHSA 模型与变体模型的对比实验结果。可以看出:HST-MHSA_neLSTM 模型在数据包层缺少了对数据包内字节的全局时序特征的提取,底层特征表示向量误差较大,因此识别性能最差;HST-MHSA 模型在HST-MH 模型的基础上引入了多头注意力机制,可以捕捉到会话层更丰富且更关键的时序特征,因此识别性能更佳。

表2 变体模型对比实验结果Table 2 Experimental results of variant models
HST-MHSA_GRU 模型与HST-MHSA 模型的分类效果较佳,说明本文层次时空特征提取与分类模型的总体结构设计合理,尽管前者比后者简化了模型复杂度,但后者在漏报率、误报率和F1 值上均达到了最优,可见GRU 对加密流量的时序特征提取能力略逊于LSTM。当检测10 000 条加密流量时,HST-MHSA_GRU 模型比HST-MHSA 模型少识别3 500 条恶意加密流量,因此本文选择LSTM 作为流量时序特征提取网络。
3.4.3 识别模型性能对比实验与结果分析
为了进一步验证HST-MHSA 模型的有效性,本文基于3 种已有基准模型(H-BiLSTM、HABBiLSTM和HAST-Ⅱ)和3 种简化模型(1D-CNN、BiLSTM 和TextCNN)进行对比实验,实验结果如表3所示,其中:1D-CNN 模型[19]将流量前(N×M)个字节的一维序列同时输入串联的两层卷积层,提取局部空间特征;BiLSTM 模型将流量前(N×M)个字节整体经过嵌入层处理后,利用一层BiLSTM 提取会话流全局时序特征;TextCNN 使用3 种尺寸的卷积核提取前(N×M)个字节的会话流多视角空间特征;H-BiLSTM模型在数据包层和会话层均采用BiLSTM 提取时序特征;HABBiLSTM 模型[20]在H-BiLSTM 模型的基础上引入分层注意力机制,分别计算两层重要时序特征;HAST-Ⅱ模型[16]首先在数据包层将字节数据独热编码,利用卷积层提取空间特征,再在会话层采用双向LSTM 提取时序特征完成分类。

表3 7 种模型的识别性能对比实验结果Table 3 Experimental results of comparison among recognition performance of seven models %
由表3 可以看出,HST-MHSA 模型漏报率最低,相比HAST-Ⅱ和HABBiLSTM 模型分别降低了3.19和2.18 个百分点,F1 值达到93.49%,在所有模型中总体分类性能最好,比1D-CNN 模型和HAST-Ⅱ模型分别提高了16.77 和1.20 个百分点,而误报率仅次于HAST-Ⅱ模型,比后者高了0.85 个百分点,说明HSTMHSA 模型在数据包层的BiLSTM 和会话层的多头注意力机制的作用下提高了对于恶意加密流量的关注度和识别能力。通过进一步分析得出以下结论:
1)前3 种模型将流量字节视为整体处理,分类效果不佳,而后4种模型将流量分层处理,F1值均高于90%,说明分层网络模型充分利用了流量所具有的“网络流-数据包-字节”的结构特征,更有利于流量分类。
2)HAST-Ⅱ和HST-MHSA 模型混合使用CNN 和LSTM 共同挖掘流量的时空特征,相比其他单独使用LSTM 或CNN 的模型表现更好。
3)HABBiLSTM 和HST-MHSA 均引入了注意力机制,因此相比无注意力层的简化模型能获得更重要的流量特征信息,而多头注意力相比普通注意力能够捕获更多维的关键特征。
表4 给出了各模型的参数量及训练情况,可以看出HST-MHSA 模型较复杂,训练时间较长,但是特征提取能力强,可以较快达到拟合状态,仅需训练15 次即可停止训练。为更直观地看出模型训练情况,图6 给出了各模型前15 次训练的验证集准确率变化情况,可以看出HAST-Ⅱ和HST-MHSA 模型的初始验证集准确率高,拟合能力强,随着训练次数的增加,后者达到最高的准确率。

表4 各模型参数量及训练情况Table 4 The number of parameters and training situation of each model

图6 7 种模型前15 次训练过程中验证集的准确率变化情况Fig.6 Changes of the accuracy of the verification set during the first fifteen training sessions of seven models
HABBiLSTM、HAST-Ⅱ、HST-MHSA 这3 种分层模型进行加密流量四分类实验时,对各类加密流量识别的F1 值,如图7所示。HST-MHSA 模型总体识别效果最好,尤其是对数量最少的AndroidSpy.277流量识别的F1 值比HAST-Ⅱ模型高出2.05 个百分点,说明HST-MHSA 模型提高了对少数恶意加密流量的特征提取与识别能力。

图7 3 种模型的四分类实验结果Fig.7 Results of four classification experiment of three models
4 结束语
本文提出一种基于层次时空特征与多头注意力模型的恶意加密流量识别方法。在数据包层引入双向LSTM 通过层,通过融合多通道CNN 加强对流量底层时空特征的表征能力,并利用多头注意力机制改进双向LSTM 在会话层对多维度高判别性会话特征的提取能力。实验结果表明,该方法在F1 值、漏报率和误报率方面相比其他方法均有明显的性能提升,并且在一定程度上提高了对少数恶意加密流量的识别率,有效加强了恶意加密流量的识别效果。但本文仅从算法层面对不平衡数据分类效果进行改进,因此后续将考虑从数据层面出发,使用GAN 生成少数样本处理不平衡数据分类问题,并结合深度学习和集成学习技术实现大数据平台下的加密流量精细化分类。
