基于随机森林模型的乌江高陡岸坡滑坡地质灾害易发性评价
2021-07-26李德营严亮轩王明哲
杨 硕,李德营,严亮轩,黄 元,王明哲
(中国地质大学(武汉)工程学院,湖北 武汉 430074)
我国重庆长江支流乌江流域地形陡峻,地质环境复杂,是滑坡灾害高发区。重庆乌江河谷地区受河流底蚀作用,深切基岩,河谷紧束,在乌江河谷两岸形成高陡岸坡,滑坡地质灾害沿河谷地带多发。该地区滑坡多沿乌江河谷地带的高陡岸坡呈条带状分布,对河谷地区的居民区构成了严重威胁。因此,研究乌江河谷地区高陡岸坡滑坡地质灾害的发育特征,并开展滑坡地质灾害易发性评价,对保护当地社会经济发展具有重要意义。
滑坡地质灾害易发性评价是从空间尺度对滑坡发生的可能性进行预测,能有效支持国土空间规划。目前,国内外学者广泛采用的滑坡地质灾害易发性评价模型大致可以分为启发式模型、确定性模型和数理统计模型。其中,启发式模型主要依靠专家的专业知识和经验建立滑坡地质灾害易发性评价模型,其缺点是存在较大的主观性;确定性模型主要考虑滑坡物理力学过程,多通过计算灾害体的稳定性系数来进行滑坡地质灾害易发性评价,常用的模型有无限斜坡模型,但该模型多需要确定地下水水位和滑带土强度参数,难以适用于大区域滑坡地质灾害易发性区划;数理统计模型以工程地质类比法为基础,常用的模型有信息量模型、证据权法等。随着人工智能算法的不断成熟与发展,基于机器学习的滑坡地质灾害易发性评价模型的研究日趋活跃,常用的有决策树模型、支持向量机模型和神经网络模型等。这些评价模型能较好地适应滑坡复杂的非线性特征,但存在预测结果解释性较弱或过度拟合的问题。
为了提高模型的预测精度,减少过度拟合的问题,以随机森林模型为代表的决策树集成学习方法受到了广泛的关注,并在地质灾害领域得到了广泛应用。如Merghadi等以北非米拉盆地为例,比较了基于随机森林、梯度提升机、逻辑回归、神经网络和支持向量机5种滑坡地质灾害易发性评价模型的预测能力,结果发现随机森林模型具有更好的预测性能;Goetz等对比研究了传统统计方法和机器学习方法在滑坡地质灾害易发性评价中的预测效果,结果发现随机森林模型具有最佳的预测性能;Sun等以重庆市奉节县地质灾害易发性评价为例,通过贝叶斯优化算法建立了高精度的地质灾害易发性随机森林评估模型。
基于上述研究,本文选取重庆乌江龙溪-石朝门段高陡岸坡为研究区,该区段滑坡地质灾害密集,提取高程、坡度、斜坡结构、斜坡形态、冲沟、岩组分类、地质构造和道路评价指标因子信息,采用随机森林模型对研究区滑坡地质灾害易发性进行了评价与精度分析,并分析了各评价指标因子的贡献程度,以为该地区滑坡地质灾害风险评估以及未来该区域工程建设和居民选址提供科学依据。
1 随机森林模型
随机森林(Random Forest,RF)模型是决策树的一种集成方法,由Breiman首次提出,是Bagging集成方法中最具有代表性的算法。随机森林中每棵决策树都取决于独立采样的随机向量值,并且对森林中的所有树都具有相同的分布。采用RF模型进行分类预测时会建立k
个决策树,每个决策树都有一票投票权来选择最优分类,最后通过简单的表决方式预测最终分类。采用RF模型进行分类预测的流程如下(见图1):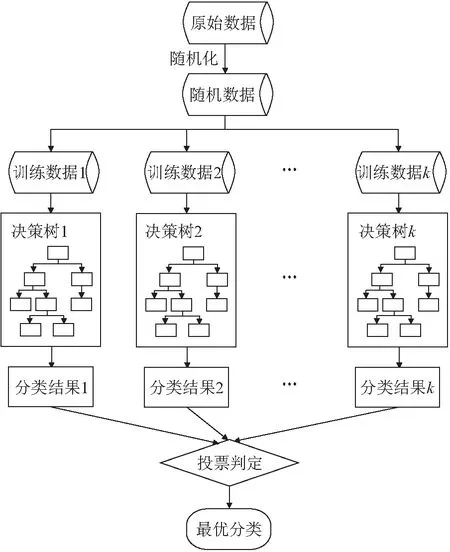
图1 随机森林(RF)模型分类预测流程图
(1) RF模型利用自主采样法从总样本里面随机有放回地抽取m
个样本作为一个初始训练数据集,由于自主采样法的有放回抽取,在每一个初始训练集中,仍然有近1/
3的数据未被采取,这些数据被称为袋外数据,用来对模型性能进行评估。(2) 运用上述方法总共抽取k
个初始训练数据集,每个初始训练数据集都会训练出一个不剪枝自由生长的决策树,形成k
个分类结果。(3) RF模型的输出结果为k
个决策树中平均概率值最高的类型,其概率值计算公式如下: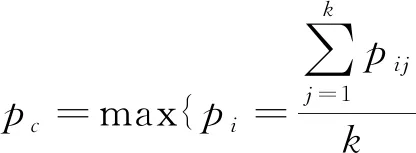
(1)
式中:I
为所有分类的集合;k
为决策树数量;p
为事件i
发生的概率;p
为第j
个决策树事件i
发生的概率;p
为最终选择的分类对应的概率值。2 研究区概况
本文选取重庆乌江龙溪-石朝门段高陡岸坡为研究区。研究区位于重庆市彭水和武隆两县交界处的乌江流域,沿乌江长约28.34 km,总面积为86 km。该地区地貌属构造剥蚀深切割中低山,地势总体乌江两岸南北高、中间低,地形陡峻,河谷呈“V”形,乌江水位高程为215 m。研究区地层从寒武系到第四系均有出露,以志留系和奥陶系为主,岩性主要为粉砂岩、页岩、泥岩、灰岩、白云岩。区内主体断裂与褶皱轴线方向一致,呈北北东向。
根据野外调查结果显示,滑坡沿乌江两岸呈带状分布,在乌江北岸主要为切层滑坡,南岸主要为顺层滑坡和堆积层滑坡。沿乌江高陡岸坡段共发育滑坡地质灾害30处,其中土质滑坡20处、岩质滑坡10处,小型滑坡23处、中型滑坡7处。典型的滑坡地质灾害点有西流坨顺层岩质滑坡和临江寺土质滑坡,见图3至图5。
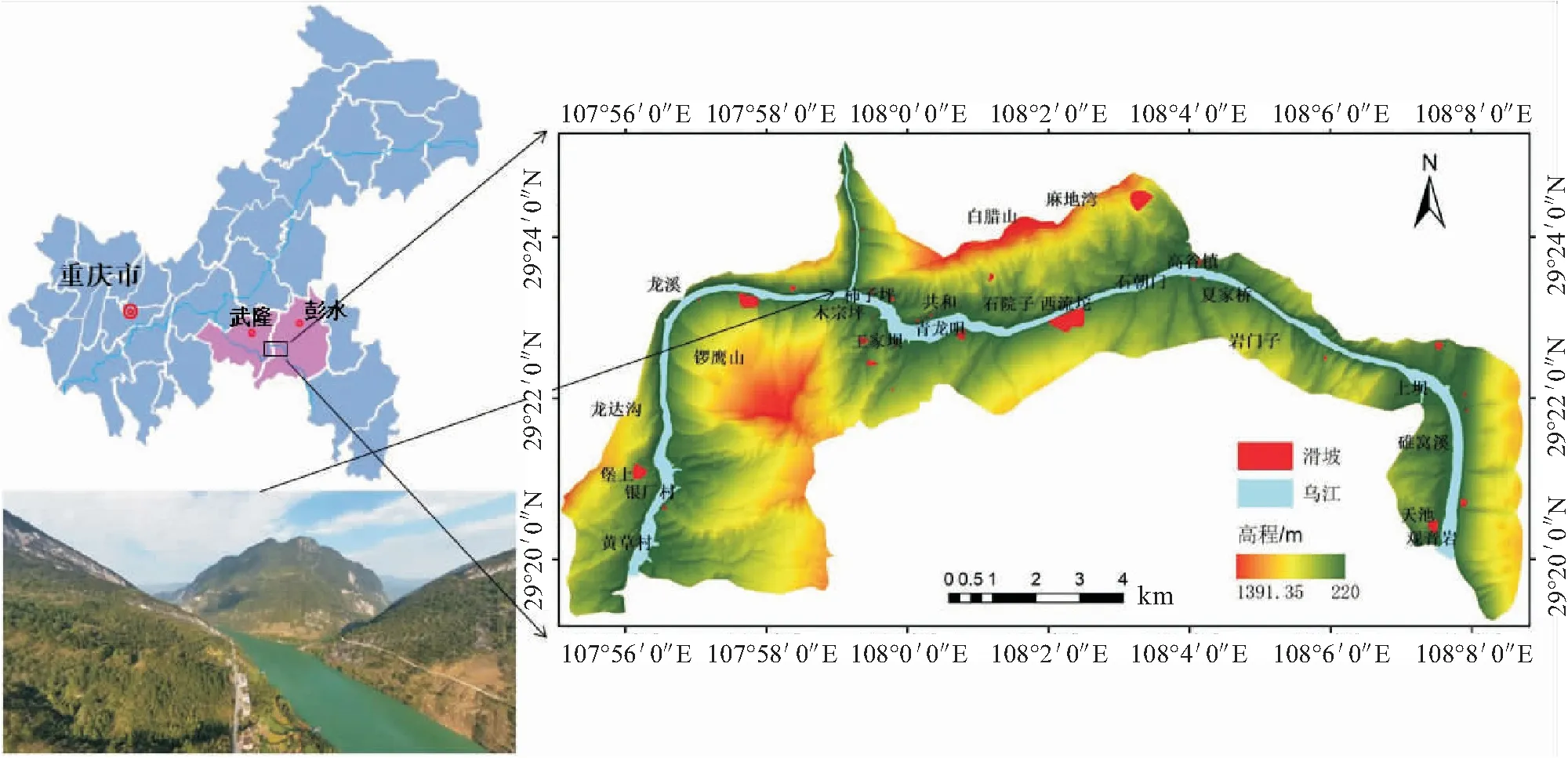
图2 研究区地理位置及滑坡分布图
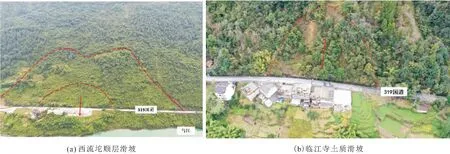
图3 研究区滑坡现场照片
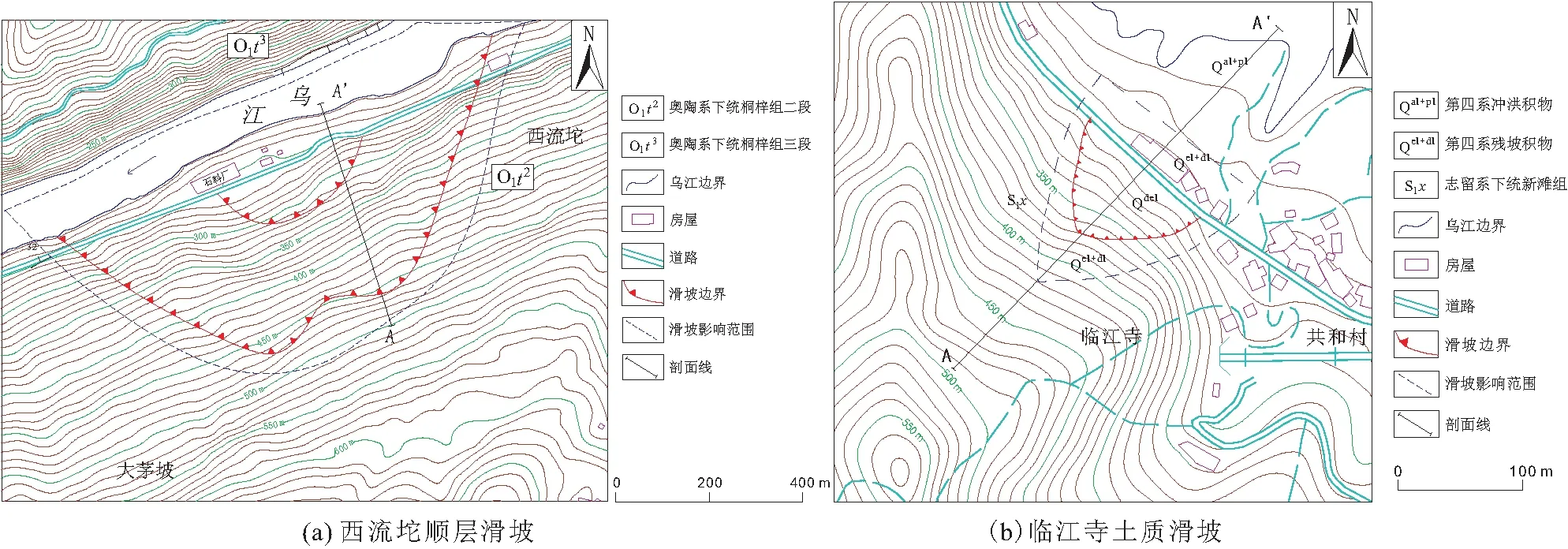
图4 研究区滑坡平面图
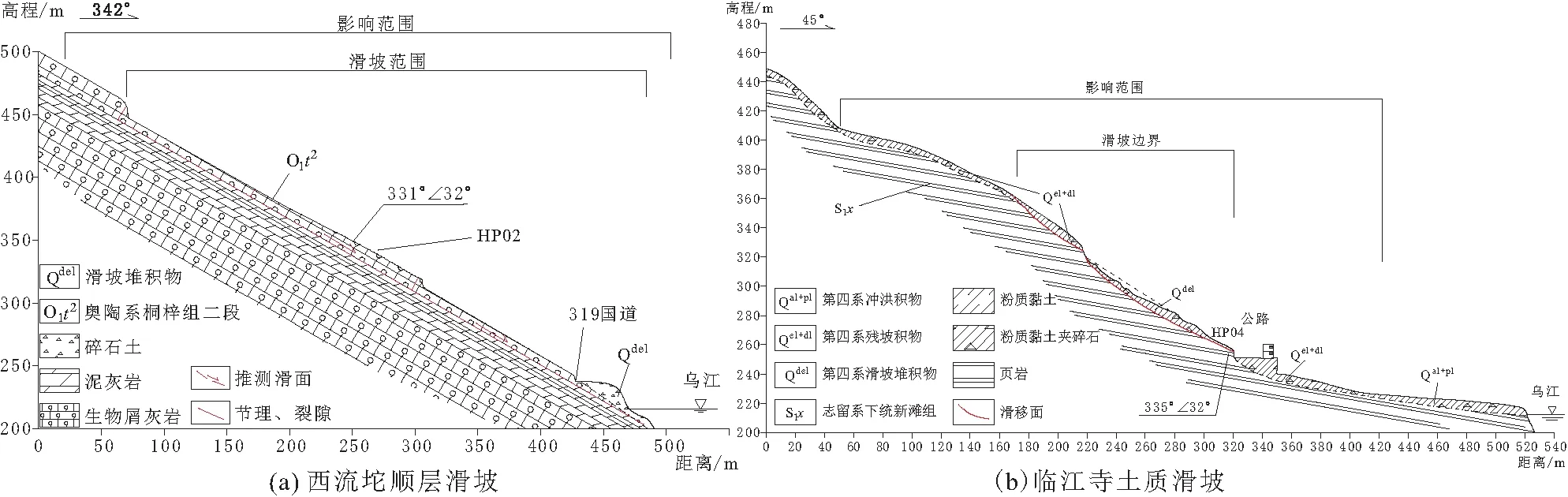
图5 研究区滑坡剖面图
3 研究区滑坡地质灾害易发性评价与精度分析
3.1 数据来源
基于野外地质灾害调查与收集的地质资料,用于研究区滑坡地质灾害易发性评价的主要数据有:①1∶5万地形图,用于提取高程、坡度等信息;②1∶5万高谷幅和火炉铺幅地质图,用于工程地质岩组分类和构造提取;③重庆市彭水县和武隆县1∶10万滑坡地质灾害分布和滑坡地质灾害易发性分区图;④1∶5万GF-2遥感影像滑坡地质灾害解译数据;⑤对研究区进行了1∶5万滑坡地质灾害风险调查以及利用光学影像对滑坡地质灾害进行了早期识别,查明了研究区有30处滑坡,并建立了滑坡地质灾害数据库。
3.2 评价指标因子选取
滑坡发生受坡体本身的基础地质条件和外界诱发因素所控制。根据研究区滑坡地质灾害发育的特征和地质环境条件,初步选取8个滑坡地质灾害易发性评价指标因子进行分析,具体为高程、坡度、岩组分类、斜坡结构、斜坡形态、冲沟、地质构造和道路。本文采用10 m×10 m的栅格,将研究区共划分为859 280个栅格。研究区高程分为200~420 m、420~640 m、640~900 m、900~1 391 m;坡度分为0°~10°、10°~25°、25°~35°、35°~45°、>45°;斜坡结构分为顺向坡、顺斜坡、横向坡、逆斜坡、逆向坡;斜坡形态根据剖面曲率分为凸形坡、平直坡、凹形坡;冲沟的缓冲距离分为0~100 m、100~200 m、200~300 m、>300 m;地质构造的缓冲距离分为0~250 m、250~500 m、500~750 m、750~1 000 m、>1 000 m;道路的缓冲距离根据灾害体大小和可能的运动距离取值,将其分为0~100 m、100~200 m、200~300 m,>300 m。此外,研究区工程地质岩组分为4大类7小类:①第四系松散岩组(Ⅰ),主要为残坡积、冲洪积、崩坡积碎块石、砂砾和黏性土;②层状碎屑岩岩组(Ⅱ),可分为3小类,即较软-软质薄层-中厚层状泥岩、页岩岩组(Ⅱ),较软-较坚硬中厚层状泥质粉砂岩、粉砂质泥岩岩组(Ⅱ),坚硬-较坚硬中厚层-厚层状粉砂岩、石英粉砂岩、细砂岩岩组(Ⅱ);③层状碳酸盐岩岩组(Ⅲ)可分为2小类,即较坚硬中厚层状含泥灰岩、泥灰岩、夹泥质条带灰岩、岩溶化灰岩及白云岩岩组(Ⅲ),坚硬中厚层-巨厚层状灰岩、微晶灰岩、生物碎屑灰岩、灰质白云岩岩组(Ⅲ);④层状碳酸盐岩夹碎屑岩组(Ⅳ),主要为软硬相间灰岩夹泥岩、页岩岩组。
各评价指标因子的具体分类,详见图6。
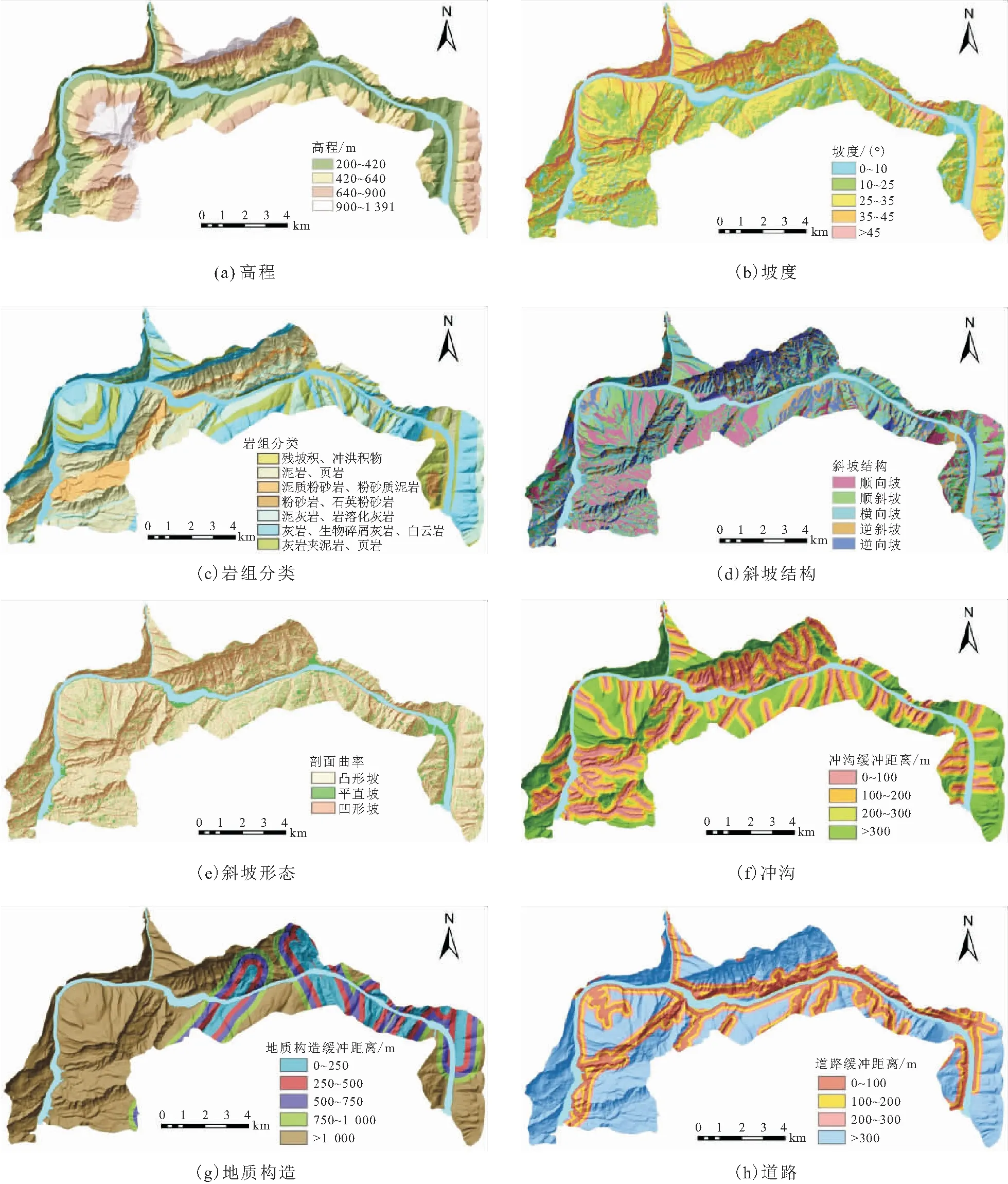
图6 研究区滑坡地质灾害易发性评价指标因子图
对研究区评价指标因子进行数据处理,得到由8个评价指标因子组成的矩阵A
,并对其进行Pearson相关性分析,其分析结果见表1。
表1 研究区滑坡地质灾害易发性评价指标因子的Pearson相关系数矩阵表
由表1可知,研究区高程与道路评价指标因子的相关系数为0.446>0.3,说明两者之间的相关性较高。由于道路工程中产生的切坡是该地区滑坡地质灾害诱发的重要因素,因此剔除高程评价指标因子,利用剩余的7个评价指标因子建立研究区滑坡地质灾害易发性评价指标体系。
3.3 滑坡地质灾害易发性评价结果与分析
选取研究区30处滑坡进行栅格处理,精度为10 m×10 m,共计有8 818个栅格,与经过Pearson相关性分析后的7个评价指标因子共同组成矩阵B
。在矩阵B
中随机选取70%的样本数据构建训练数据集,剩下的30%样本数据构建测试数据集,应用SPSS Modeler 18中的RF模型对训练数据集进行训练和建模,并对全区域滑坡地质灾害易发性进行评价,最后利用测试数据集对模型精度进行检验。3.3.1 滑坡地质灾害易发性分区
通过RF模型计算出研究区内所有栅格的滑坡发生概率,并基于K均值聚类模型,将研究区划分为5个滑坡易发区,即极低易发区(0,0.16]、低易发区(0.16,0.45]、中易发区(0.45,0.69]、高易发区(0.69,0.87]、极高易发区(0.87,1],进而得出研究区滑坡地质灾害易发性分区图(见图7),再对研究区滑坡地质灾害易发性进行分区统计(见图8),最后通过RF模型得到研究区滑坡地质灾害易发性评价指标因子的贡献程度雷达图,见图9。
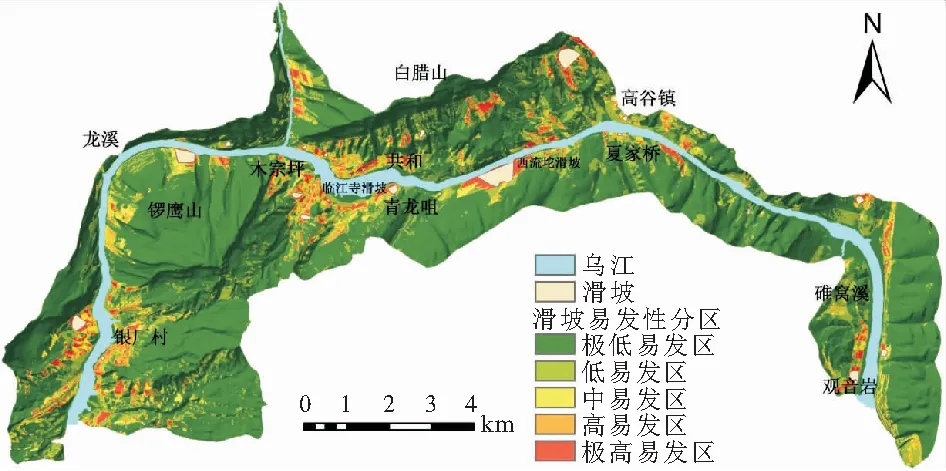
图7 研究区滑坡地质灾害易发性分区图
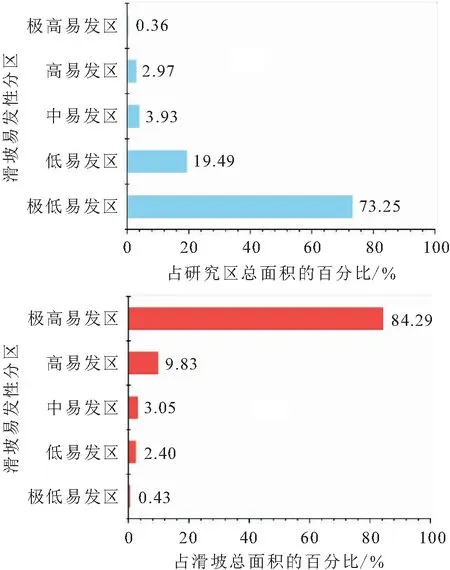
图8 研究区滑坡地质灾害易发性分区统计
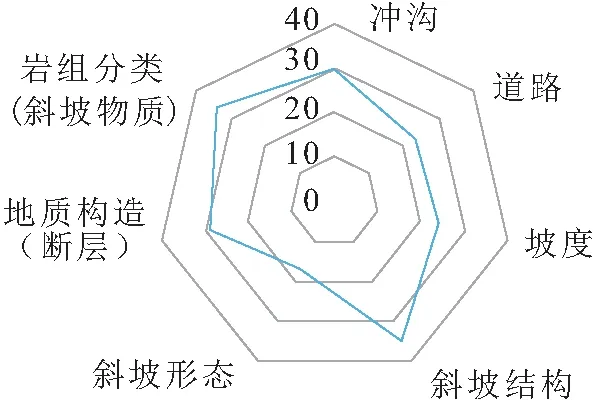
图9 研究区滑坡地质灾害易发性评价指标因子的贡献程度雷达图
根据上述研究区滑坡地质灾害易发性评价结果,可分析得出研究区滑坡地质灾害发育具有以下分布特征:
(1) 研究区滑坡极高和高易发区主要分布于乌江北岸的共和村以西沿线,乌江南岸的青龙咀至木棕坪一带和银厂村一带,其占研究区总面积的3.33%,其中滑坡极高和高易发区的面积占已知滑坡总面积的94.12%,其他区域滑坡分布较少(见图8)。
(2) 斜坡物质和斜坡结构对研究区滑坡地质灾害的发生起主要作用(见图9),滑坡极高和高易发区主要分布在志留系的泥岩、页岩、泥质粉砂岩层位中,其次为奥陶系泥质灰岩层位中;研究区滑坡极高和高易发区主要分布在顺向坡和顺斜坡中。
3.3.2 模型预测精度评估
本文采用混淆矩阵和ROC曲线对RF模型的预测精度进行评估。
(1) 混淆矩阵:由于滑坡样本和非滑坡样本数目的极度不平衡,仅采用统计方法来衡量预测模型判断滑坡和非滑坡的准确度,不能评估该模型的适用性。因此,本文采用混淆矩阵对RF模型的预测精度进行评估,得到研究区RF模型测试数据集的混合矩阵,见表2。

表2 研究区随机森林模型测试数据集的混淆矩阵
由表2可知,测试数据集中模型正确分类样本数为226 212个,而测试数据总样本数为253 746个,可得到RF模型预测的准确率(ACC值)为0.89(ACC指模型正确分类样本个数占总样本个数的比值),表明RF模型的预测精度较高。
(2) ROC曲线:整个研究区随机RF模型的ROC曲线见图10。AUC(Area Under Curve)被定义为ROC曲线下的面积,取值范围在0.5~1之间,AUC值越大,表明模型的预测精度越高。
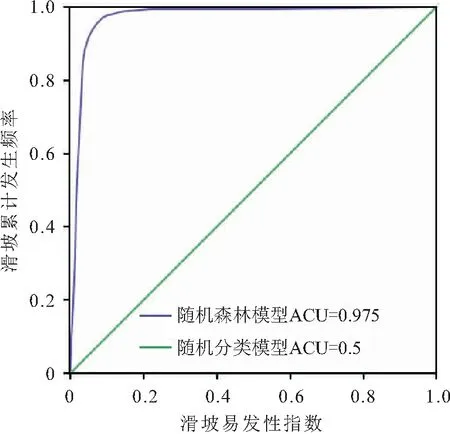
图10 研究区随机森林模型的ROC曲线和AUC值
由图10可见,RF模型的AUC值为0.975,表明应用RF模型对研究区滑坡地质灾害易发性进行预测的精度较高。
4 结 论
本文以重庆乌江龙溪-石朝门段高陡岸坡为研究区,基于随机森林模型开展了研究区滑坡地质灾害易发性评价,得到如下结论:
(1) 根据滑坡地质灾害现场调查结果,研究区94.12%的滑坡分布在极高和高易发区,表明随机森林模型的预测效果好。在评价指标因子中,斜坡物质和斜坡结构是影响研究区滑坡地质灾害发育的最主要因素。
(2) 通过混淆矩阵和ROC曲线对随机森林模型的预测精度进行评估,结果表明:随机森林模型预测的准确率(ACC值)为0.89,AUC值为0.975,说明随机森林模型评价方法的精确度较高,是一种滑坡地质灾害易发性评价的可靠方法。
