在线机器学习在智能钻井中的应用
2021-07-25罗海峰王涛
罗海峰 王涛

摘要:随着国家对互联网、人工智能、机器学习等前沿计算机技术的推广,以及计算机技术所带来的高效能力,提供的先进决策方法,为智能钻井提供了新的解决方案。相较传统的离线学习的方法,在线机器学习在分析钻井过程中具有更强的适应性、更好的解析能力和纠错能力。本文简述了在线学习在钻井工程的应用。
关键词:机器学习;离线学习;在线学习;智能钻井
中图分类号:TP311文献标识码:A
文章编号:1009-3044(2021)16-0188-02
开放科学(资源服务)标识码(OSID)
Application of Online Machine Learning in Intelligent Drilling
LUO Hai-feng, WANG Tao
(School of Computer Science, Southwest Petroleum University, Chengdu 610500,China)
Abstract: With the country's promotion of cutting-edge computer technologies such as the Internet, artificial intelligence, and machine learning, as well as the efficient capabilities and advanced decision-making methods brought by computer technology, new solutions are provided for intelligent drilling. Compared with the traditional offline learning method, online machine learning has stronger adaptability, better analytical ability and error correction ability in the analysis and drilling process. This article briefly describes the application of online learning in drilling engineering.
Key words: Machine learning; Offline learning; Online learning; Intelligent drilling
1概述
随着对油气资源需求的增长,石油勘探开发的速度不断提高,钻井新技术迅速推广,对智能化钻井的需求不断增加[1]。智能钻井从空间环境来看主要分为井下工具的智能化、井上智能钻井系统和高效的信息传输通道,当前钻井过程中将井下信息传递到地面已经具备完善的钻井装备和解决方案,但是如何有效利用获取的钻井信息,是智能钻井当前需要解决的关键问题之一。机器学习的强大的高维非线性映射能力和大数据处理能力为钻井数据分析利用提供了有效的解决途径,减少现场作业人员,提供一定的决策支持能力,大幅提高作业效率和安全性。
传统作业方法中,通过建立数理方程对钻井参数分析,实现井眼监测、卡钻监测、井涌预测和机械钻速预测等。相比传统方法,基于机器学习的钻井参数分析具有更可靠的分析精度,并且可以更全面的考虑多种特征因素对分析结果的影响。但是,由于新开钻井地质和工程条件的差异,以及现场工况的复杂性导致离线模型的适用性会随实际开采情况变化,不再具有稳定的分析预测效率。在线模型具有的实时校正和在线更新的能力,因此,在某些工況下是更符合智能钻井的需求。
2基于离线学习的智能钻井
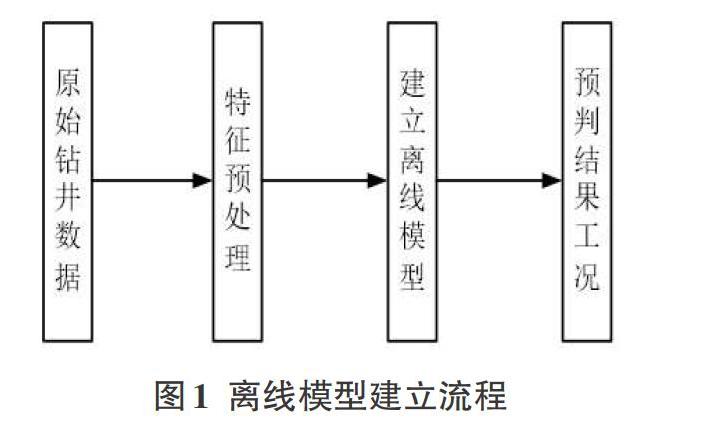
2.1 离线模型建立流程
基于离线模型的智能钻井参数分析中,主要过程如图1所示,获取的钻测井数据包括深度、钻压、转速、钩载、排量、钻井液密度、转盘扭矩、转盘扭矩变异系数、钻头尺寸、钻头型号和地层等相关信息,经过数据预处理剔除无效数据,提取有效特征因素,构建离线机器学习模型,将离线模型用于新井工况检预测。
2.2 离线随机森林
随机森林可以理解为基于自助采样法和决策树的一种提升方法,如图2所示,通过自助采样法有放回随机选取m个子样本使用决策树训练基础模型,在训练决策树时选择k个属性建立基模型,一般情况下k=log2d(d表示样本中的属性个数),这样做的目的是提供一定的样本扰动性和属性扰动性,使得基础模型尽可能有较大差异,具有多样性的同时个体模型不会太差,最终的集成树效果有提升。
机器学习在智能钻机中典型应用之一是岩性识别。文献[5]集中探讨了不同机器学习方法在岩性预测上的性能表现。
基于离线方法建立模型的方式中,一个重要假设是我们已经获取了全部可能的样本。在利用堪萨斯大学[2]提供的钻井数据集中,使用传统离线方式建立预测模型,将数据集随机打乱并按照1:4的比例划分为训练集和测试集,采用随机森林算法实现岩性分类,模型的效果能够达到85%。但是当我们模拟现场钻井过程,数据是按照顺序流的方式到来,由于未学习过的样本模型是不能识别的,只能对学习过的样本识别,模型准确率仅有47.65%,所以此时训练出的模型是不适用此类工况环境的。
3基于在线学习的智能钻井
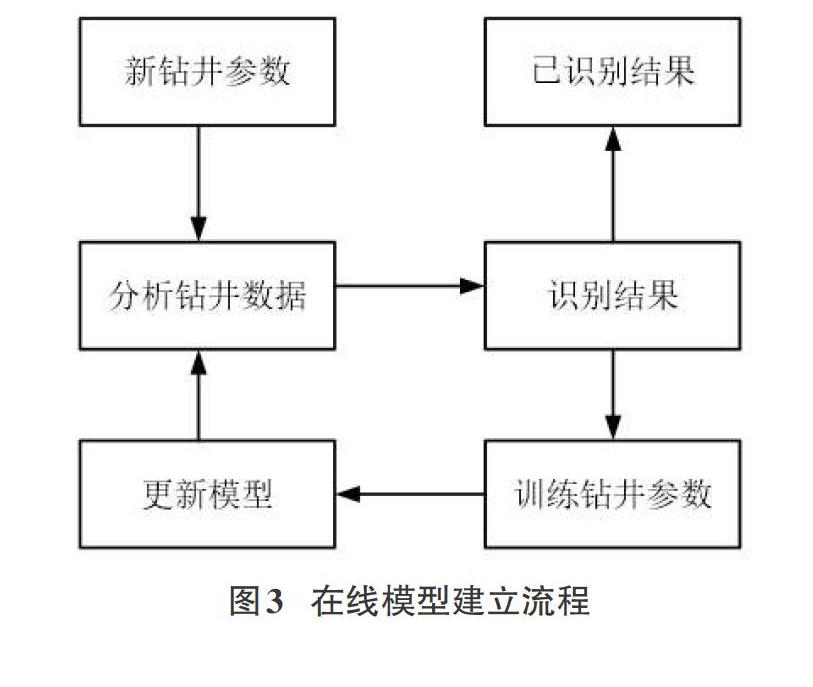
3.1在线模型建立流程
同离线模型相比在线模型的建立过程中主要的不同点在于模型的更新过程,通过有效的更新模型使得模型更加适用于这类随时间变化随工况变化的存在概念漂移的数据。如图3所示,为了使模型能够适用概念漂移在新样本到达时,首先基于上一轮的模型对新样本进行预测分析,再基于新样本对模型更新,学习新样本的数据特征。
3.2在線随机森林
在线随机森林[3]中一种有效的模型更新方法是每个决策树模型可以在线分裂,分裂的条件是预测的数量和叶子节点的Gini指数达到设定的阈值。这种方法不会改变整个森林的结构。如图4所示,基于决策树更新的方式流程图。
在线机器学习在Shai[4]等人首次设计出一种高效的在线SVM求解算法后由此掀起了在线学习在机器学习领域的研究和应用高潮,并在近年持续成为热点研究问题。钻井工程中在线学习还未得到相关的研究。
基于在线方法建立模型的方式中,我们同样将测井数据集[2]模拟实际开采过程数据流的到达方式,在线随机森林相比离线随机森林能够有效地提高模型对未知新样本的识别能力,模型分类效果达到62%。
4结束语
在线学习算法相对离线机器学习对新样本的处理能力有效提高,但是在我们的应用中,模型效果还不足以用于实际开采工作中给出具有指导性决策支持,下一步可行的方案是在获取大量可靠数据后首先建立传统的离线模型,将离线模型融合到在线模型中,提高在线模型效率。
参考文献:
[1] 王茜,张菲菲,李紫璇,等.基于钻井模型与人工智能相耦合的实时智能钻井监测技术[J].石油钻采工艺,2020,42(1):6-15.
[2] Xie Y X,ZhuCY,ZhouW,etal.Evaluation of machine learning methods for formation lithology identification:a comparison of tuning processes and model performances[J].Journal of Petroleum Science and Engineering,2018,160:182-193.
[3] http://www.kgs.ku.edu/PRS/petroDB.html
[4] SaffariA,LeistnerC,SantnerJ,etal.On-line random forests[C]//2009 IEEE 12th International Conference on Computer VisionWorkshops,ICCVWorkshops.September27 - October4,2009,Kyoto,Japan.IEEE,2009:1393-1400.
[5] Shalev-ShwartzS,SingerY,SrebroN.Pegasos:primal estimated sub-GrAdientSOlver for SVM[C]//Proceedings of the 24thinternational conference on Machine learning - ICML '07.June20-24,2007.Corvalis,Oregon.NewYork:ACM Press,2007:807-814.
【通联编辑:梁书】
