基于深度强化学习的机械臂自适应阀门旋拧方法研究
2021-07-25李新茂刘满禄王基生周祺杰
李新茂,刘满禄,王基生,周祺杰
(1.西南科技大学 制造科学与工程学院,绵阳 621000;2.西南科技大学 信息工程学院,绵阳 621000;3.中国科学技术大学信息科学技术学院,合肥 230026)
0 引言
在以核应急处理处置、核退役等为代表的危险环境作业中,采用机器人进行远程作业已经被国际社会广泛认可[1]。针对危险环境下的阀门旋拧作业,传统的示教或编程的控制方法的任务适应性差;人工远程操作亦存在误操作风险。
针对阀门旋拧作业,国内外学者已经提出了不同的研究策略。使用传统控制方法,令人形机器人能够执行阀门旋拧任务[2~4]。Ahmadzadeh S R[5]等人在阀门旋拧阶段基于力/运动混合控制策略,并采用一种反应决策系统来克服操作过程中的干扰和不确定因素。邢宏军[6]通过设计专门夹持器并采用基于阻抗控制的主动柔顺控制方法克服了阀门旋拧任务中的旋拧侧向力问题和轴向位移问题。Fares J等人[7]提出了一种从示例学习的框架,用于检索时变刚度轮廓,使机器人在阀门操作任务中具有较好的反应。各学者提出的以上方法能够完成特定的作业任务,但是存在一些问题:1)适应性差,无法自适应地应对未知环境可能存在多类型阀门;2)需要针对性设计专门的夹持装置,才能够有效开展工作;3)针对典型问题的建模较为复杂。
深度强化学习(Deep Reinforcement Learning,DRL)具有很好的环境适应性和自我优化的特点,在其他应用研究中已经取得了一定的成果,如抓取、开门、折叠衣物[8~11]等等。研究表明,通过分析任务、分解基本动作,利用DRL能够很好地学习拟合复杂的最优控制策略。因此,本文主要针对阀门旋拧作业任务,提出了一种基于DRL的机械臂控制方法。在已经通过遥操作或视觉引导完成机械臂对阀门夹持的基础上,讨论机械臂如何自适应地完成未知尺寸阀门手轮的旋拧作业。
1 阀门旋拧问题分析
阀门作为常用的开关控制器,规格尺寸多样,如图1所示。在以核应急处理处置、核退役等为代表的危险环境作业中,可能需要对多种规格尺寸的阀门手轮进行旋拧作业,这对机械臂控制的适应性要求极高。本文直接将上述情况视为旋拧未知规格尺寸的阀门手轮。其中,夹持方式为使用二指夹持器夹持阀门轮缘,虽然这种方法会导致运动规划困难,但能够保证机械臂的环境适应能力。另外,默认机械臂夹持器已夹持住阀门轮缘,主要研究机械臂旋拧阀门问题。

图1 不同规格尺寸的阀门手轮
2 阀门旋拧算法
为了实现对未知规格尺寸阀门手轮的旋拧操作,本文基于马尔科夫决策过程(Markov Decision Processes,MDP)[12]建立阀门旋拧操作模型。采用深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)[13],学习阀门旋拧的技能。
2.1 阀门旋拧的马尔科夫决策过程
为降低算法复杂程度,采用跟踪贴于阀门轮缘上标签运动间接实现阀门旋拧的策略。并通过“Eye-in-Hand”手眼系统获取标签相对于夹持器的坐标信息。而由于机械臂在旋拧阀门的过程中,夹持器与阀门轮缘是相对静止的,因此需要对标签同时进行位置跟踪和姿态跟踪。
1)状态空间
阀门旋拧过程的状态空间S定义如下。

其中D描述位置跟踪状态,L描述姿态跟踪状态。
位置跟踪状态D式(2)由夹持器中心点P(xp,yp)与标签点F(xf,yf)之间的距离表示,如图3所示。由于实际情况下夹持器中心P与标签点F相对静止,因此降低标签点信息更新率的方法,以实现D值的变化。即当夹持器到达上一次更新得到的标签点信息,再更新标签点信息。

姿态跟踪状态L表示方法如下所述。如图2所示,选取与点P相对位姿不变的一点M,与点P和点F构成三角形。其中边PM和边PF是常量,因此边MF的长度变化可以用于描述姿态跟踪状态L(式(3))。

图2 环境信息描述

其中,l为边MF的实时长度,l0为边MF的初始长度。
3)动作空间
本文默认阀门为水平放置,故动作空间为A={αx,αy,ω},其中αx表示沿x轴方向运动,αy表示沿y轴方向运动,ω表示以夹持器中心为旋转轴做旋转运动。
4)奖惩函数
奖惩函数式(4)的设计主要依据位置与姿态的跟踪状态,并通过参数λ,η调节D值和L值之间的数量级关系。另外,通过添加阶梯函数φ(D,L)式(5)对阀门旋拧运动进行额外奖励,加快模型训练的收敛速度。

其中,单位为毫米。
2.2 阀门旋拧过程中的模型训练
本文基于DDPG实现对阀门旋拧策略模型的学习训练。基于DDPG的训练目标为寻找最优网络参数θ,使得阀门旋拧策略μ最优,如图3所示。

图3 DDPG算法结构图
该算法在状态st时,根据策略μ选取动作at式(6),并在动作执行后,返回新的状态和奖励(rt,st+1)。策略网络μ会将(st,at,rt,st+1)存入记忆池(Replay Memory,RM),作为训练行为网络的数据集。记忆池的使用,可以减少算法的不稳定性。

其中,μ为策略函数,θ为策略参数,s为当前状态。即状态为s时,相同策略的动作是唯一确定的。
网络训练时,会从RM中随机采样N个数据,作为行为策略网络μ、行为价值网络Q的一个mini-batch训练数据,mini-batch中的单个数据记为(si,ai,ri,si+1)。
首先依据式(7)计算行为价值网络Q的梯度,并更新该网络。
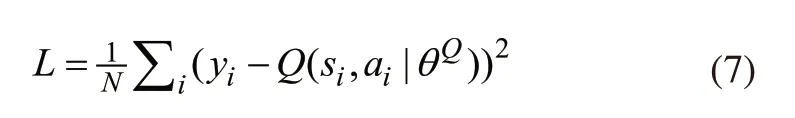
接下来,使用mini-batch数据,依据式(8)计算行为策略网络μ的策略梯度,并更新该网络。

目标网络是行为网络的拷贝,采用滑动平均的方法对μ'和Q'进行更新如式(9)所示。由于其更新缓慢低幅,能够使训练模型计算的值函数Q在一定程度上减少波动,令计算更稳定。
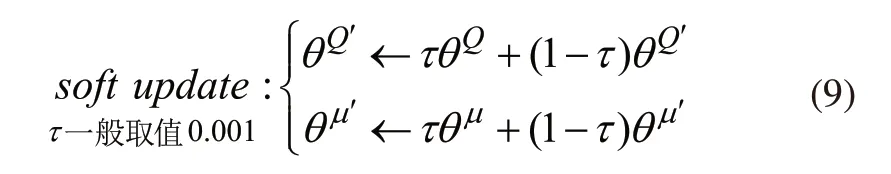
为了加快收敛速度,并避免机械臂发生剧烈抖动或反方向旋拧,在训练时作如下设计:一次标签更新循环中,若规定步数内D大于设定阈值,则令夹持器回到本次循环起始位置,继续训练。
算法流程如下:


3 实验仿真
3.1 仿真环境构建
仿真环境基于V-rep仿真平台建立,如图4所示。使用带有RG2夹持器的UR5机械臂,动力学引擎为bullet2.83。所提出算法基于Tensorflow框架,部分参数如表1所示。
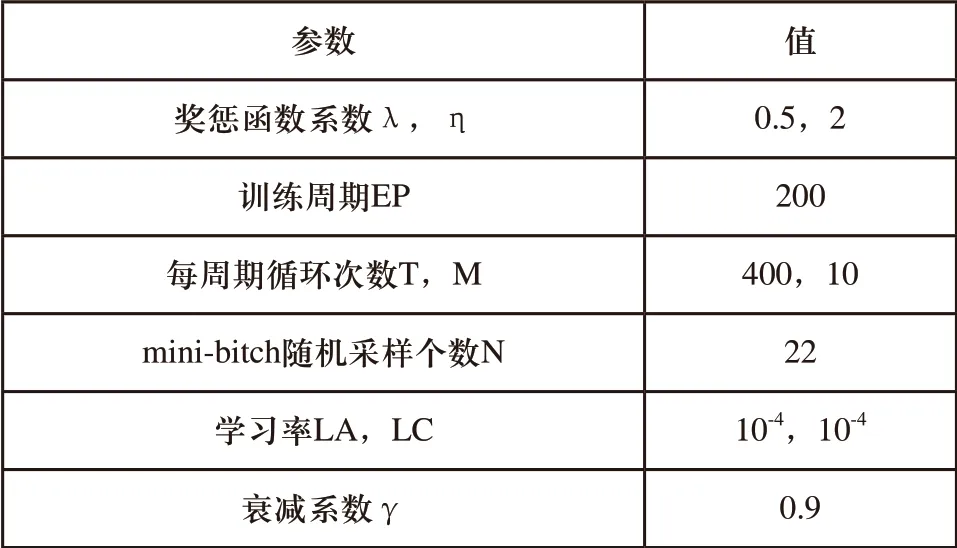
表1 网络参数设计

图4 仿真环境
3.2 训练结果
训练过程中所面对的阀门手轮直径为300mm。所提出算法在训练过程中累积奖励R的变化如图5所示。前10个回合即可快速收敛,在10~80个回合中存在震荡。第80个回合后,累积奖励R开始收敛。在第135回合左右,出现剧烈波动,但很快又重新收敛。

图5 训练中累积奖励R变化过程
3.3 测试结果
考虑阀门手轮的尺寸、规格多样性,以及仿真环境中UR5机械臂的工作空间,针对直径分别为300mm以及200mm、400mm、500mm的阀门手轮进行测试。
基于300mm直径阀门手轮的测试结果如图6~图8及表2所示。其实际轨迹与理论轨迹基本重合,姿态跟踪状态L最大不超过2mm,因此所提出算法具有较好的运动性能。

图6 300mm直径旋拧轨迹

图7 300mm直径旋拧轨迹径向误差

图8 300mm直径旋拧轨迹姿态跟踪状态L
基于直径为200mm,400mm,500mm的阀门手轮的测试结果如表2所示。虽然所提出算法是基于单一尺寸规格的阀门手轮进行训练,但在阀门手轮尺寸未知的情况下仍然可以旋拧其他尺寸规格的阀门手轮,表明所提出算法具有较好的适应性。

表2 实验仿真测试结果
4 结语
针对典型危险环境作业,本文提出了基于深度强化学习算法的机械臂自适应阀门旋拧方法。详细分析了阀门旋拧问题,考虑旋拧过程中机械臂与阀门手轮的相对状态,设计了阀门旋拧操作的马尔科夫过程。使用DDPG算法寻求最优阀门旋拧策略。仿真实验表明,所提出方法运动性能良好,能够在阀门手轮尺寸未知的情况下实现对多种阀门手轮的旋拧操作。对在危险环境中利用机械臂开展阀门旋拧作业,有很高的实用价值。
