一种新型的Flink电子商务实时推荐系统
2021-07-24牛少彰史成洁
马 腾,牛少彰,史成洁
(1.北京邮电大学 计算机学院,北京 100876;2.中科院信息工程研究所,北京 100093)
0 引言
随着分布式计算和数据库技术的发展,互联网进入了大数据时代。大数据时代为人们提供了丰富的信息,同时,也在各个领域带来了巨大的机遇和挑战。解决信息过载的问题,从大量数据中提取有用的知识一直以来都广受研究者们的关注。其中,推荐系统通过为用户提供个性化服务,被认为是当前解决信息过载问题最有效的工具之一,已被广泛应用在电商网站、影视资源服务商、社交网络等各个领域。传统推荐算法主要有基于内容的推荐、协同过滤推荐、混合推荐等多种算法。交替最小二乘法(Alternating-Least-Squares,ALS)作为协同过滤推荐算法的一个分支,由于解决了协同过滤算法 中数据稀疏性的问题,在推荐系统中被广泛使用。
另一方面,现实中生成的大量数据普遍以流式无结构化或半结构化的形式存在,例如用户点击Web页面产生的行为日志等。这些数据都具有变化迅速,数据量大的特点。例如用户过了今天可能就不会对某件商品感兴趣了。而传统的推荐系统通常会在一个规定的时间间隔内更新模型,如几个小时或者数天,这就无法满足对实时性的需求。并且由于用户对某件商品的兴趣会随着时间减弱,因此传统的推荐算法的预测质量也会随之下降。
本文针对以上问题,设计了一种基于 Flink的电商实时推荐系统。该系统共分为4个模块:数据加载模块、商品特征向量计算模块、日志采集模块、实时推荐模块。数据加载模块将用户对商品的历史评分数据导入数据库中。商品特征向量计算模块通过用户对商品的历史评分数据得到每个商品的特征向量。日志采集模块将实时采集到的用户评分数据同时进行缓存和输入到实时推荐模块中。实时推荐模块得到用户实时的评分数据,结合商品特征向量,通过实时推荐算法得到推荐商品列表,为用户做出推荐。
1 相关工作
从20世纪90年代中期开始,对推荐系统的研究吸引了越来越多的研究人员。经典的推荐算法可以划分为协同过滤推荐和基于内容的推荐。协同过滤推荐根据用户对项目的行为数据为用户产生推荐;而基于内容的推荐算法通过对项目内在语义的分析,为用户推荐与感兴趣项目相似的项目。然而,每种推荐算法都有各自的缺陷。两种算法都需要面对冷启动的问题,即如何对新用户进行推荐或如何推荐新产品给用户。此外,协同过滤算法还有打分稀疏性的问题和算法可扩展性问题,而基于内容的推荐算法不可避免地受到信息获取技术的约束。因此,很多研究人员为了解决推荐算法的局限性,将协同过滤和基于内容的推荐两种算法的优点相结合,提出了各种混合推荐算法。其中包括将不同算法的推荐结果线性组合、在不同的场景中使用更可信的推荐结果以及在协同过滤算法中加入基于内容的算法等。
最近,针对大数据和实时性的推荐系统受到了更多的关注。文献[1]提出了一种关键字感知推荐系统,该系统旨在使用Apache Hadoop处理大型数据集。该系统背后的主要思想是利用从用户和项目的文本数据中提取的关键字,以提高性能并缓解冷启动问题。文献[2]提出了一种称为APRA的大数据近似并行推荐算法,该算法是基于Apache Spark开发的,可有效处理大规模数据。文献[3]提出一种自适应分布式数据流环境的SGD算法,通过点对点网络控制模型训练过程,对矩阵分解模型实时增量更新,避免引入参数服务器带来的性能瓶颈。文献[4]提出了一种简单但高效的推荐算法,该算法利用用户的个人资料属性将其划分为多个集群。对于每个群集,设想一个虚拟意见领袖代表整个群集,这样可以显著减小原始用户项目矩阵的维数,然后设计加权斜率One-VU方法并将其应用于虚拟意见领袖-项目矩阵以获得推荐结果。文献[5]提出了疾病诊断和治疗推荐系统DDTRS,引入了密度峰值聚类分析算法来进行疾病症状聚类,通过Apriori算法分别进行疾病诊断规则和疾病治疗规则的关联分析,并在Spark云平台实现了解决方案。文献[6]提出了一种基于联合训练方法的推荐算法,称为ECoRec,该算法可以驱动两个或更多推荐算法彼此同意自己的预测来产生最终的预测。文献[7]提出了一种具有遗传算法的最近邻人工免疫系统NNAISGA,通过进行快速数据插补以减少稀疏性。文献[8]提出了用于预测大时间序列的不同可扩展方法,还开发了处理任意预测范围的方法。文献[9]提出了GRS用户群推荐系统,可以帮助用户群根据他们的喜好和需求找到合适的项目。文献[10]提出了一种有效的并行算法 ConSimMR,用于使用 MapReduce构造相似矩阵。文献[11]提出了一种推荐算法,这种算法可建立独立于个人用户兴趣的集体偏好模型,并且不需要复杂的评分系统。
本文首先基于“最近一段时间用户的兴趣是相似的”设计了一种实时推荐算法,可以满足瞬时的推荐需求,并在准确性方面具有优越性。然后在Flink上对该算法进行实现,并设计了电商推荐系统。
2 背景知识
ALS算法:当数据中没有显性特征时,就需要根据已有的偏好数据,去发掘出隐藏的特征,即隐语义模型(LFM)。协同过滤算法非常依赖历史数据,而一般的推荐系统中,偏好数据又往往是稀疏的,这就需要对原始数据做降维处理。假设用户物品评分矩阵为 R,现在有 m个用户,n个物品,目标是找到两个矩阵P和Q,使这两个矩阵的乘积近似等于R,即将用户物品评分矩阵R分解成两个低维矩阵相乘:

分解之后的矩阵就代表了用户和项目的k个隐藏特征。矩阵分解得到的预测评分矩阵ˆR,与原评分矩阵R在已知的评分项上可能会有误差,这个误差用平方损失函数来衡量,并且加入正则化项,以防过拟合:

Flink:Apache Flink是一个分布式处理框架,用于对无界和有界数据流进行有状态的计算。Flink作为新一代的流处理引擎,可以处理毫秒级的实时请求,并且支持流批一体的数据处理。在实际生产中的人工智能使用场景中,Flink在包括特征工程,在线学习,在线预测等方面都有一些独特优势。
3 实时推荐算法
实时计算与离线计算应用于推荐系统上最大的不同在于实时计算推荐结果应该反映最近一段时间用户的偏好,而离线计算推荐结果则是根据用户从第一次评分起的所有评分记录来计算用户总体的偏好。
用户对物品的偏好随着时间的推移总是会改变的。比如一个用户u在某时刻对商品p给予了极高的评分,那么在近期一段时间,u极有可能很喜欢与商品p类似的其他商品;而如果用户u在某时刻对商品 q给予了极低的评分,那么在近期一段时间,u极有可能不喜欢与商品 q类似的其他商品。所以对于实时推荐,当用户对一个商品进行了评价后,用户会希望推荐结果基于最近几次评分进行一定的更新,使得推荐结果匹配用户近期的偏好,满足用户近期的口味。
如果实时推荐系统采用离线推荐算法,由于算法运行时间巨大,不具有实时得到新的推荐结果的能力;并且由于用户做出实时评分之后对整个评分表的影响只是增加一条记录,使得算法运行后的推荐结果与用户做出本次评分前后没有多少差别,从而给用户推荐结果总是不变的感觉,影响用户体验。所以本文的实时推荐算法主要实现两个目标:1.用户实时评分之后,系统可以明显的更新推荐结果;2.减少推荐过程中的计算量,满足响应时间上的实时要求。
当用户u对商品p进行一次评分,将触发一次对用户u的推荐结果的更新。对于用户u来说,他与商品p最相似的n个商品之间的推荐优先级将发生变化,最终选取与商品p最相似的K个商品作为候选商品。这些商品将根据用户u最近的若干次评分计算出对用户u的推荐优先级,然后与上次对用户u的实时推荐结果进行基于推荐优先级的合并、替换得到更新后的推荐结果。
首先,获取用户u按时间顺序最近的K个评分,记为RK;获取商品 p的最相似的K个商品集合,记为S;然后,对于每个商品q∊S,计算其推荐优先级Euq,计算公式为:

其中:Rr表示用户 u对商品 r的评分;sim(q,r)表示计算得到的商品q与商品r特征向量之间的相似度,设定最小相似度为0.6,当商品q和商品 r相似度低于 0.6的阈值,则视为两者不相关并忽略;表示q与RK中商品相似度大于最小阈值的个数;表示RK中与商品 q相似的、且本身评分较高(大于等于6)的商品个数;recount表示RK中与商品q相似的、且本身评分较低(小于6)的商品个数。


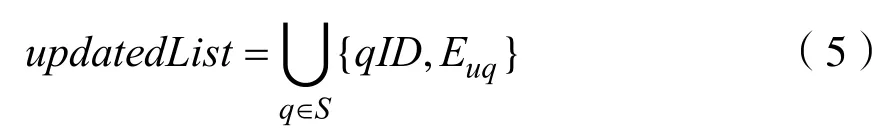
上一次为用户u的实时推荐结果列表Rec也是一个大小为K的<商品m的ID,m的推荐优先级>列表:

将 updatedList与上一次实时推荐结果 Rec进行合并、替换形成新的推荐结果NewRec:

其中,i表示updatedList与Rec的商品集合中的每个商品,topK是一个函数,表示从中选出推荐优先级最大的 K个商品。最终,NewRec即为经过用户u对商品p评分后触发的实时推荐得到的最新推荐结果。
4 推荐系统架构
本文基于 Flink实现的推荐系统分为 4个模块:数据加载模块、商品特征向量计算模块、日志采集模块、实时推荐模块。系统架构如图1所示。
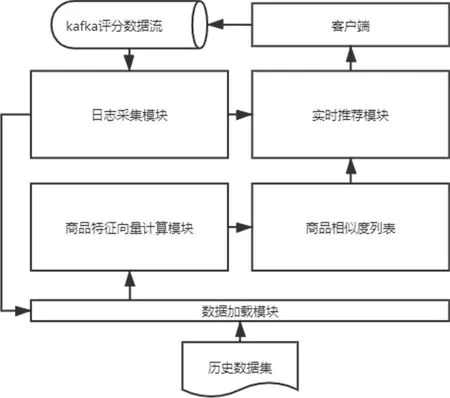
图1 基于Flink的推荐系统Fig.1 recommender system based on Flink
数据加载模块负责将历史数据和日志采集模块采集到的实时评分流数据加载到推荐系统用到的mysql数据库中的Rating数据表中。Rating数据表有4个字段:用户id,商品id,评分,时间戳。
商品特征向量计算模块使用 ALS算法对数据库中的Rating数据表进行矩阵分解得到每个商品的特征向量,然后计算得到每件商品的相似商品列表,存入mysql中。由于此模块涉及到对整个数据集使用ALS算法,耗时较长,且用户的一次评分对整个数据集的影响较小,所以不必实时更新相似列表,只需每隔一段时间进行一次计算。
日志采集模块负责用flume拉取客户端埋点生成的日志信息,并通过kafka streaming程序对日志信息进行清洗,通过日志前缀过滤出评分信息,并挑选出推荐系统用到的4个字段,以数据流的形式输入到 kafka中,供数据加载模块和实时推荐模块使用。
实时推荐模块在从kafka中收到用户的一条实时评分时,按照前文第3章提出的实时推荐算法为用户生成实时的推荐列表,返回到客户端做出推荐。
主要的计算流程为:Flink程序加载商品相似度列表作为一条广播流,与订阅 kafka实时评分topic生成的评分流连接,当一条实时评分数据
5 实验及结果
本文在renttherunway数据集上进行了实验。renttherunway包含了105508位用户对5850个服装类商品的192544次评分。为了方便实时推荐系统的评价,本文挑选了100位拥有11次评分及以上的用户,并将他们的评分按照时间顺序排序,把每个人的最晚5次评分作为历史评分数据,保存在redis中,第6次评分作为每个用户触发实时推荐的评分,后5此评分作为测试集,来评价本文实时推荐系统。
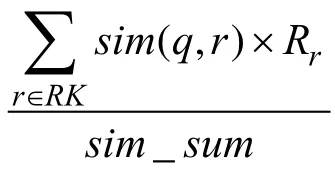

在不同的参数下,实时推荐模型中基础评分与ALS算法的RMSE对比如图2。
通过图2可以看出实时推荐模型中基础评分的RMSE与ALS相似,在隐特征个数为20,正则化系数是1.0时,使RMSE最小约为 1.82,可以保持一个较高的准确度。

图2 不同参数下的RMSEFig.2 RMSE under different parameters
实验2 对于实时推荐算法来说,一个很关键的评价标准就是用户在每一次评分之后,推荐列表是否有明显的变化,如果每次用户得到的推荐列表都大同小异,则会大大影响用户体验。针对这个标准,本文比较了100位用户进行两次实时评分之后得到的推荐列表,100位用户平均两次列表中不一样商品的占比达到了98%。用户可以很明显的感受到实时推荐结果在随着他们的评分在不断变化。
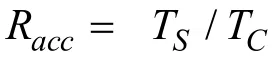


图3 ALS 算法耗时与加速比Fig.3 ALS time-consuming and speedup

图4 相似度计算耗时与加速比Fig.4 similarity calculation time-consuming and speedup
6 结论
由于现实中生成的大量数据普遍以流式无结构化或半结构化的形式存在,这些数据都具有变化迅速,数据量大的特点,并且用户对推荐列表的实时变化有较高的需求,本文设计了一种实时推荐算法,可以满足推荐系统的实时推荐需求,并基于Flink设计了一个电商实时推荐系统。最终实验证明在准确度、推荐列表的变化率、可扩展度上都具有一定的优势。但在离线相似度计算这部分在数据量较大时耗时较久,是未来可以优化的部分。
